Snowflake上でストリーミング半構造化データ分析プラットフォームを構築する方法
'Snowflakeでストリーミング半構造化データ分析プラットフォームを構築する方法'

イントロダクション
Snowflakeは、大量のデータに対して分析を実行するのに最適なSaaS(サービスとしてのソフトウェア)です。このプラットフォームは非常に使いやすく、ビジネスユーザーや分析チームなど、ますます増え続けるデータセットから価値を得るために適しています。この記事では、ヘルスケアデータのためのストリーミングセミストラクチャドアナリティクスプラットフォームをSnowflake上に作成するためのコンポーネントについて説明します。また、このフェーズでのいくつかの重要な考慮事項も説明します。
コンテキスト
ヘルスケア業界全体でサポートされているさまざまなデータ形式がありますが、私たちは最新のセミストラクチャード形式であるFHIR(高速ヘルスケア相互運用リソース)を、分析プラットフォームの構築に使用することを考えます。この形式は通常、1つのJSONドキュメント内にすべての患者中心の情報が埋め込まれています。この形式には、すべての入院エンカウンターや検査結果など、さまざまな情報が含まれています。分析チームは、クエリ可能なデータレイクを提供されると、どれだけの患者ががんと診断されたかなどの貴重な情報を抽出することができます。すべてのJSONファイルがAWS S3(または他のパブリッククラウドストレージ)に15分ごとに異なるAWSサービスまたはエンドAPIエンドポイントを介してプッシュされるという仮定で進めましょう。
アーキテクチャ設計
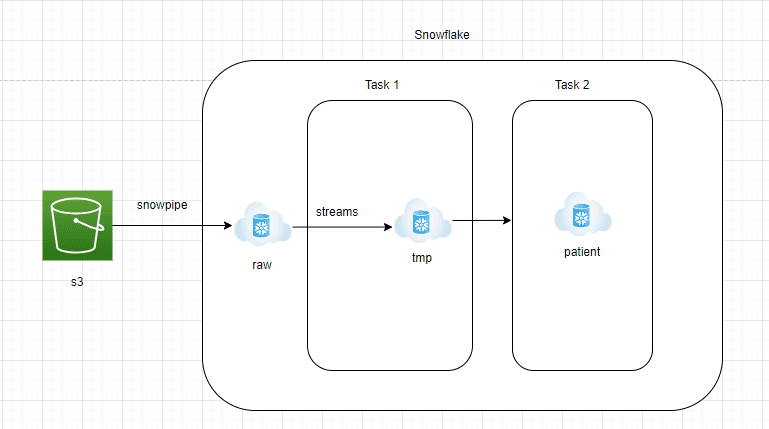
アーキテクチャコンポーネント
AWS S3からSnowflakeのRAWゾーンへ:
- データはAWS S3から連続的にSnowflakeのRAWゾーンにストリーミングする必要があります。
- Snowflakeは、S3からJSONファイルを連続的に読み取ることができるSnowpipe管理サービスを提供しています。
- SnowflakeのRAWゾーンには、ネイティブ形式でJSONデータを保持するためのvariant列を持つテーブルを作成する必要があります。
SnowflakeのRAWゾーンからストリームへ:
- ストリームは、新しい入力JSONドキュメントをSnowflakeのRAWゾーンにキャプチャできる変更データキャプチャサービスです。
- ストリームは、SnowflakeのRAWゾーンテーブルを指し示し、append=trueに設定する必要があります。
- ストリームは通常のテーブルと同様に、簡単にクエリを実行できます。
Snowflakeタスク1:
- Snowflakeタスクは、スケジューラに似たオブジェクトです。クエリやストアドプロシージャをcronジョブの表記を使用してスケジュール実行することができます。
- このアーキテクチャでは、タスク1を作成してストリームからデータを取得し、ステージングテーブルに取り込みます。このレイヤーは切り捨てられて再ロードされます。
- これは、新しいJSONドキュメントが毎15分ごとに処理されることを保証するために行われます。
Snowflakeタスク2:
- このレイヤーは、元のJSONドキュメントを分析チームが簡単にクエリできるレポートテーブルに変換します。
- JSONドキュメントを構造化形式に変換するには、Snowflakeのlateral flatten機能を使用できます。
- lateral flattenは、ネストされた配列要素を展開し、’:’表記を使用して簡単に抽出できる使いやすい関数です。
重要な考慮事項
- Snowpipeは、いくつかの大きなファイルで使用することが推奨されます。小さいファイルが外部ストレージにある場合、コストが高くなる可能性があります。
- 本番環境では、ストリームがステールになった場合にデータを回復できないため、自動化されたプロセスを作成してストリームを監視するようにしてください。
- 単一のJSONドキュメントの最大許容サイズは、Snowflakeにロードできる圧縮された16MBです。これらのサイズ制限を超える巨大なJSONドキュメントがある場合は、Snowflakeに取り込む前に分割するプロセスがあることを確認してください。
結論
セミストラクチャードデータの管理は常に課題です。JSONドキュメント内に埋め込まれた要素のネスト構造のためです。最終的なレポートレイヤーを設計する前に、入力データのボリュームが段階的かつ指数関数的に増加することを考慮してください。この記事では、セミストラクチャードデータを使用したストリーミングパイプラインを構築するのがどれほど簡単であるかを示すことを目的としています。
Milind Chaudhariは、従来のツールやモダンなツールを使用してデータレイク/レイクハウスを構築するための10年の実務経験を持つ経験豊富なデータエンジニア/データアーキテクトです。彼はデータストリーミングアーキテクチャに非常に情熱を持っており、PacktおよびO’Reillyの技術レビュアーでもあります。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
