あなたのポケットにアーティストの相棒:SnapFusionは、拡散モデルのパワーをモバイルデバイスにもたらすAIアプローチです
SnapFusion is an artist's partner in your pocket that brings the power of diffusion models to mobile devices through an AI approach.


拡散モデル。AI領域の進歩に注目している場合、この用語については多く聞いたことがあるでしょう。それらは生成型AI手法の革命を可能にした鍵でした。我々は今や、テキストプロンプトを使用して数秒で写真のような逼真的な画像を生成するモデルを持っています。それらは、コンテンツ生成、画像編集、スーパーレゾリューション、ビデオ合成、3Dアセット生成を革新しました。
しかし、この印象的なパフォーマンスには高いコンピューテーション要件が伴います。つまり、それらを完全に活用するには本当に高性能のGPUが必要です。はい、それらをローカルコンピュータで実行する試みもありますが、それでも高性能なものが必要です。一方、クラウドプロバイダを使用することも代替解決策となりますが、その場合はプライバシーを危険にさらす可能性があります。
そして、考えなければならないのは、移動中に使用することです。ほとんどの人々は、コンピュータよりもスマートフォンで時間を過ごしています。拡散モデルをモバイルデバイスで使用したい場合、デバイス自体の限られたハードウェアパワーにとって要求が高すぎるため、うまくいく可能性はほぼありません。
拡散モデルは次の大きな流行ですが、実用的なアプリケーションに適用する前にその複雑さに対処する必要があります。モバイルデバイスでの推論の高速化に焦点を当てた複数の試みが行われていますが、シームレスなユーザーエクスペリエンスや定量的な生成品質を達成していませんでした。それは今までの話であり、新しいプレイヤーがフィールドに登場しているのです。SnapFusionと名付けられたこのプレイヤーです。
SnapFusionは、モバイルデバイスで2秒以下で画像を生成する最初のテキストから画像への拡散モデルです。UNetアーキテクチャを最適化し、ノイズ除去ステップ数を減らすことで推論速度を向上させています。さらに、進化するトレーニングフレームワークを使用し、データ蒸留パイプラインを導入し、ステップ蒸留中に学習目標を強化しています。
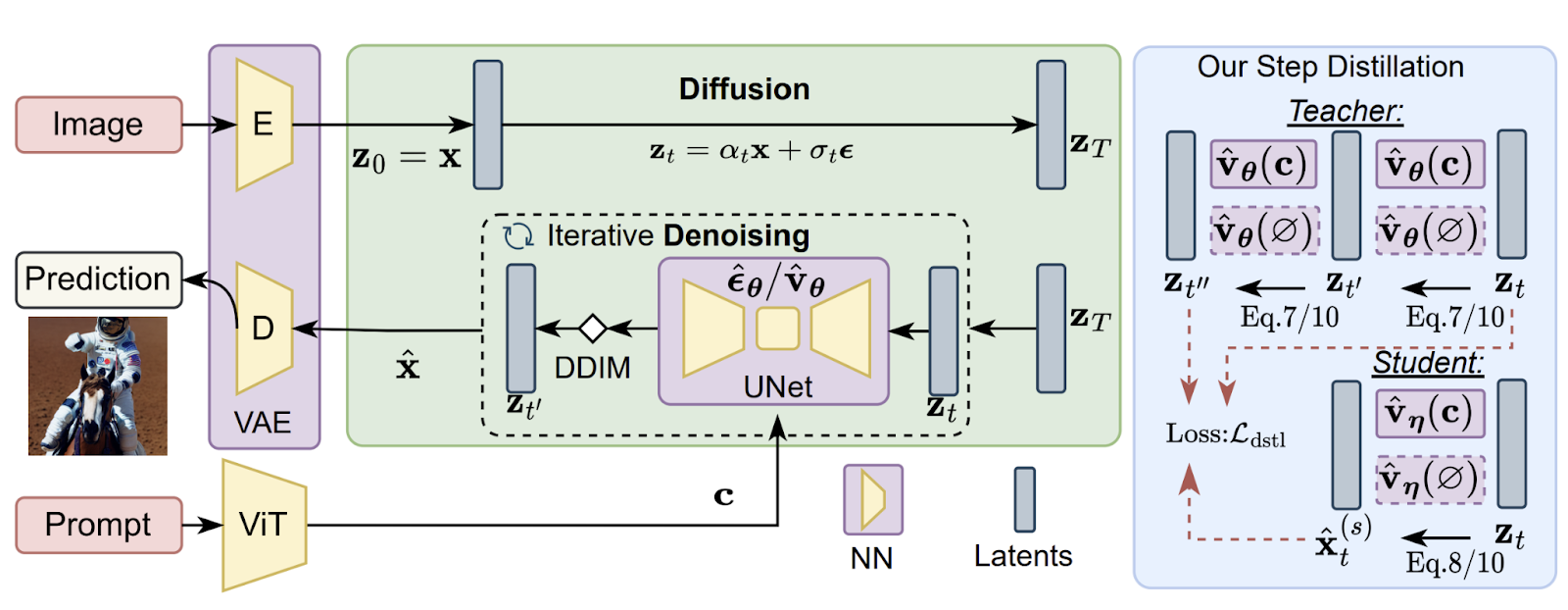
SnapFusionの構造に変更を加える前に、SD-v1.5のアーキテクチャの冗長性を調査して、効率的なニューラルネットワークを得ることが最初に行われました。しかし、SDに従来のプルーニングやアーキテクチャサーチ技術を適用することは、高いトレーニングコストのために困難でした。アーキテクチャの変更は性能の低下につながる可能性があり、大規模な計算リソースを必要とする厳密な微調整が必要となります。そのため、その道は閉ざされ、彼らは、事前にトレーニングされたUNetモデルのパフォーマンスを維持しながら効果を徐々に向上させる代替方法を開発する必要がありました。
推論速度を向上させるために、SnapFusionは、条件付き拡散モデルのボトルネックであるUNetアーキテクチャを最適化することに焦点を当てています。既存の作品は主にトレーニング後の最適化に焦点を当てていますが、SnapFusionはアーキテクチャの冗長性を特定し、元のStable Diffusionモデルを上回る進化するトレーニングフレームワークを提案することで、推論速度を大幅に向上させています。また、イメージデコーダーを圧縮して高速化するためのデータ蒸留パイプラインを導入しています。
SnapFusionには、各クロスアテンションとResNetブロックを一定の確率で実行する確率的フォワード伝播が適用される堅牢なトレーニングフェーズが含まれています。この堅牢なトレーニング拡張機能により、ネットワークがアーキテクチャの変化に対して耐性があることが保証され、各ブロックの正確な評価と安定したアーキテクチャの進化が可能になります。
効率的なイメージデコーダーは、チャネル削減によって得られたデコーダーを使用して合成データを使用して蒸留パイプラインを介して達成されます。この圧縮デコーダは、SD-v1.5のものよりもはるかに少ないパラメータを持ち、より速くなっています。蒸留プロセスには、テキストプロンプトを使用してSD-v1.5のUNetから潜在表現を取得することで、効率的なデコーダーから1つ、SD-v1.5から1つの画像を生成することが含まれます。
提案されたステップ蒸留アプローチには、バニラ蒸留損失目的が含まれており、これは、生徒のUNetの予測と教師のUNetのノイズのある潜在表現との不一致を最小化することを目的としています。さらに、CFG-aware蒸留損失目的が導入され、CLIPスコアを改善します。CFGガイドされた予測は、教師モデルと生徒モデルの両方で使用され、CFGスケールはトレーニング中にFIDスコアとCLIPスコアのトレードオフを提供するためにランダムにサンプリングされます。

改善されたステップ蒸留とネットワークアーキテクチャの開発のおかげで、SnapFusionは、モバイルデバイス上のテキストプロンプトから512×512の画像を2秒未満で生成することができます。生成された画像は、最先端のStable Diffusionモデルと同様の品質を示しています。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles






