Boto3 vs AWS Wrangler PythonによるS3操作の簡素化
Simplify S3 operations with Boto3 vs AWS Wrangler in Python.
AWS S3 開発の比較分析

はじめに
このチュートリアルでは、Pythonを使用してAWS S3の開発に探求し、2つの強力なライブラリboto3とawswranglerを比較して探求します。
もし
「AWS S3バケットとのやり取りに最適なPythonツールは何ですか?」
「最も効率的な方法でS3操作を行う方法は?」
と思ったことがあるなら、ここに来たね。
この記事では、AWS S3バケットで必要な一連の一般的な操作、つまり:
- オブジェクトのリストアップ、
- オブジェクトの存在を確認する、
- オブジェクトのダウンロード、
- オブジェクトのアップロード、
- オブジェクトの削除、
- オブジェクトの書き込み、
- オブジェクトの読み込み(標準的な方法またはSQLを使用して)
をカバーし、2つのライブラリを比較して、各操作の類似点、相違点、および最適な使用ケースを特定します。最後に、特定のS3タスクに適したライブラリがどちらかを明確に理解することができます。
さらに、最後まで読んでくれた人のために、フレンドリーなSQLクエリを使用してS3からデータを読み取るためにboto3とawswranglerをどうやって活用するかも探求します。
それでは、AWS S3とやり取りするための最高のツールを発見し、Pythonを使用して両方のライブラリを使用してこれらの操作を効率的に実行する方法を学びましょう。
前提条件&データ
このチュートリアルで使用されるパッケージバージョンは次のとおりです:
boto3==1.26.80awswrangler==2.19.0
また、ランダムに生成されたaccount_balancesデータを含む3つの初期ファイルがcoding-tutorialsという名前のS3バケットにアップロードされています:
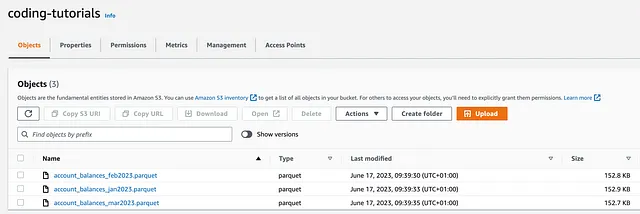
接続を確立するためのいくつかの方法が存在することに注意してくださいが、この場合はboto3のsetup_default_session()を使用します:
# CONNECTING TO S3 BUCKETimport osimport ioimport boto3import awswrangler as wrimport pandas as pdboto3.setup_default_session(aws_access_key_id = 'your_access_key', aws_secret_access_key = 'your_secret_access_key')bucket = 'coding-tutorials'このメソッドは便利であり、セッションが設定された後、boto3とawswranglerの両方で共有できるため、以降の秘密を渡す必要はありません。
比較分析
さて、いくつかの一般的な操作を実行しながら、boto3とawswranglerを比較して、最適なツールを見つけましょう。
以下のようにboto3を使用してオブジェクトをリストアップできます:
boto3.client('s3').list_objects()boto3.resource('s3').Bucket().objects.all()
print('--BOTO3--') # BOTO3 - 優先方法client = boto3.client('s3')for obj in client.list_objects(Bucket=bucket)['Contents']: print('ファイル名:', obj['Key'], 'サイズ:', round(obj['Size']/ (1024*1024), 2), 'MB') print('----') # BOTO3 - 代替方法resource = boto3.resource('s3')for obj in resource.Bucket(bucket).objects.all(): print('ファイル名:', obj.key, 'サイズ:', round(obj.size/ (1024*1024), 2), 'MB')client と resource クラスの両方がそれなりの仕事をしているにもかかわらず、より優雅で、ネストされた JSON として低レベルメタデータ [ 簡単にアクセス可能な ] の大量を提供するので、client クラスが優先されるべきです(その中に size オブジェクトがあります)。
一方、 awswrangler はオブジェクトをリストするための単一のメソッドしか提供していません:
wr.s3.list_objects()
これはハイレベルなメソッドであり、オブジェクトに関する低レベルのメタデータは返されないため、ファイル size を見つけるためには、次のように呼び出す必要があります:
wr.s3.size_objects
print('--AWS_WRANGLER--') # AWS WRANGLERfor obj in wr.s3.list_objects("s3://coding-tutorials/"): print('ファイル名:', obj.replace('s3://coding-tutorials/', '')) print('----') for obj, size in wr.s3.size_objects("s3://coding-tutorials/").items(): print('ファイル名:', obj.replace('s3://coding-tutorials/', '') , 'サイズ:', round(size/ (1024*1024), 2), 'MB')上記のコードは以下を返します:
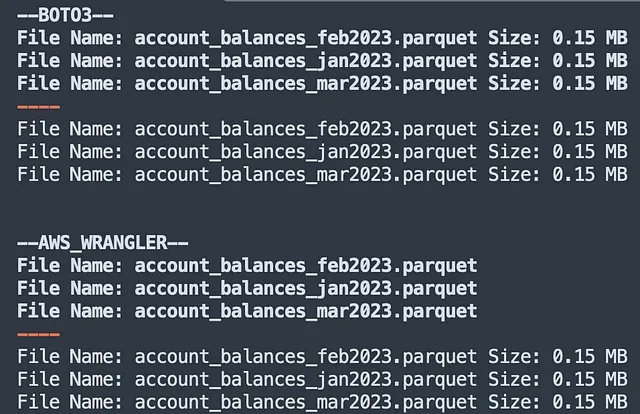
比較 → Boto3 勝利
awswrangler はより簡単に使用できますが、S3 オブジェクトのリストを表示する際には boto3 が勝ちます。実際、低レベルな実装により、そのクラスの1つを使用して多数のオブジェクトメタデータを取得できます。このような情報は、プログラムで S3 バケットにアクセスする場合に非常に役立ちます。
# 2 オブジェクトの存在を確認する
オブジェクトの存在を確認できるようになると、S3 にオブジェクトがすでに存在するかどうかに応じて追加の操作をトリガーすることができます。
boto3 を使用する場合、次のようにしてチェックを実行できます:
boto3.client('s3').head_object()
object_key = 'account_balances_jan2023.parquet'# BOTO3print('--BOTO3--') client = boto3.client('s3')try: client.head_object(Bucket=bucket, Key = object_key) print(f"オブジェクトはバケット {bucket} に存在します。")except client.exceptions.NoSuchKey: print(f"オブジェクトはバケット {bucket} に存在しません。")一方、 awswrangler は専用のメソッドを提供しています:
wr.s3.does_object_exist()
# AWS WRANGLERprint('--AWS_WRANGLER--') try: wr.s3.does_object_exist(f's3://{bucket}/{object_key}') print(f"オブジェクトはバケット {bucket} に存在します。")except: print(f"オブジェクトはバケット {bucket} に存在しません。")上記のコードは以下を返します:
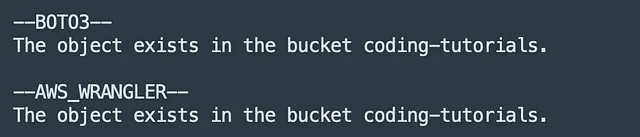
比較 → AWSWrangler 勝利
boto3 のメソッド名 [ head_object() ] はあまり直感的ではないと認めましょう。
専用のメソッドを持つことは、この試合に勝利するawswranglerの利点であることは間違いありません。
# 3 オブジェクトのダウンロード
ローカルにオブジェクトをダウンロードするには、以下の方法を使用して、boto3とawswranglerの両方で非常に簡単です。
boto3.client('s3').download_file()またはwr.s3.download()
唯一の違いは、download_file()が入力変数としてbucket、object_key、local_fileを取るのに対し、download()はS3のpathとlocal_fileのみを必要とすることです:
object_key = 'account_balances_jan2023.parquet'# BOTO3client = boto3.client('s3')client.download_file(bucket, object_key, 'tmp/account_balances_jan2023_v2.parquet')# AWS WRANGLERwr.s3.download(path=f's3://{bucket}/{object_key}', local_file='tmp/account_balances_jan2023_v3.parquet')コードが実行されると、同じオブジェクトの両バージョンが、tmp/フォルダー内に実際にローカルにダウンロードされます:

比較 → 引き分け
ファイルのダウンロードに関しては、2つのライブラリが同等であると考えることができるため、引き分けと呼びましょう。
# 4 オブジェクトのアップロード
ローカル環境からS3にファイルをアップロードする場合、同じ理由が適用されます。使用できるメソッドは次のとおりです:
boto3.client('s3').upload_file()またはwr.s3.upload()
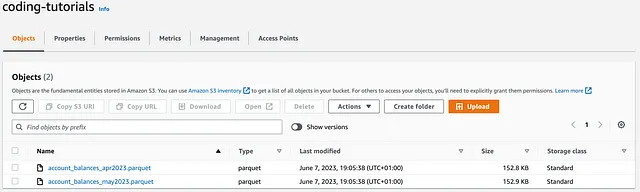
object_key_1 = 'account_balances_apr2023.parquet'object_key_2 = 'account_balances_may2023.parquet'file_path_1 = os.path.dirname(os.path.realpath(object_key_1)) + '/' + object_key_1file_path_2 = os.path.dirname(os.path.realpath(object_key_2)) + '/' + object_key_2# BOTO3client = boto3.client('s3')client.upload_file(file_path_1, bucket, object_key_1)# AWS WRANGLERwr.s3.upload(local_file=file_path_2, path=f's3://{bucket}/{object_key_2}')コードを実行すると、2つの新しいaccount_balancesオブジェクト(2023年4月と5月の)がcoding-tutorialsバケットにアップロードされます:
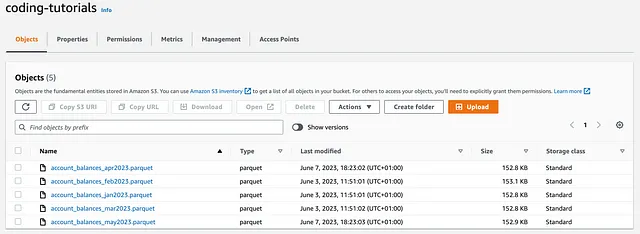
比較 → 引き分け
これは別の引き分けです。これまでのところ、2つのライブラリには完全な同等性があります!
# 5 オブジェクトの削除
次のオブジェクトを削除したいと仮定しましょう:
#SINGLE OBJECTobject_key = ‘account_balances_jan2023.parquet’#MULTIPLE OBJECTSobject_keys = [‘account_balances_jan2023.parquet’, ‘account_balances_feb2023.parquet’, ‘account_balances_mar2023.parquet’]boto3は、オブジェクトを1つずつ削除するか、次のメソッドを使用して一括で削除することができます:
boto3.client('s3').delete_object()boto3.client('s3').delete_objects()
両方のメソッドは、オブジェクトが正常に削除されたかどうかを確認するために使用できるResponseMetadataを含むresponseを返します。たとえば:
- 1つのオブジェクトを削除する場合、
HTTPStatusCode==204は、操作が正常に完了したことを示します(S3バケットでオブジェクトが見つかった場合)。 - 複数のオブジェクトを削除する場合、
Deletedリストが返され、正常に削除されたアイテムの名前が表示されます。
# BOTO3print('--BOTO3--')client = boto3.client('s3')# 単一オブジェクトの削除response = client.delete_object(Bucket=bucket, Key=object_key)deletion_date = response['ResponseMetadata']['HTTPHeaders']['date']if response['ResponseMetadata']['HTTPStatusCode'] == 204: print(f'オブジェクト{object_key}は{deletion_date}に削除されました。')else: print(f'オブジェクトは削除できませんでした。')# 複数オブジェクトの削除objects = [{'Key': key} for key in object_keys]response = client.delete_objects(Bucket=bucket, Delete={'Objects': objects})deletion_date = response['ResponseMetadata']['HTTPHeaders']['date']if len(object_keys) == len(response['Deleted']): print(f'全てのオブジェクトは{deletion_date}に削除されました。')else: print(f'オブジェクトは削除できませんでした。')一方、awswranglerは、単一および一括削除に使用できるメソッドを提供しています:
wr.s3.delete_objects()
object_keysは、辞書に変換する前にリスト内包表記として再帰的にメソッドに渡すことができるため、この構文を使用することは本当に楽しいことです。
# AWS WRANGLERprint('--AWS_WRANGLER--')# 単一オブジェクトの削除wr.s3.delete_objects(path=f's3://{bucket}/{object_key}')# 複数オブジェクトの削除try: wr.s3.delete_objects(path=[f's3://{bucket}/{key}' for key in object_keys]) print('すべてのオブジェクトが正常に削除されました。')except: print(f'オブジェクトは削除できませんでした。')上記のコードを実行すると、S3のオブジェクトが削除され、以下が返されます:

比較 → Boto3 Wins
これはトリッキーです:複数のオブジェクトを削除する際にawswranglerはよりシンプルな構文を持っている一方、オブジェクトをプログラムで削除する際にboto3は非常に有用なログを返します。
プロダクション環境では、ほとんどのメタデータよりも低レベルのメタデータが優れているため、boto3がこの課題に勝ち、現在2-1でリードしています。
# 6 W riting Objects
S3にファイルを書き込む場合、boto3にはそのような操作を実行するための out-of-the-boxメソッドがありません。
例えば、boto3を使用して新しいparquetファイルを作成する場合、まずオブジェクトをローカルディスクに永続化する必要があります(pandasのto_parquet()メソッドを使用)その後、upload_fileobj()メソッドを使用してS3にアップロードする必要があります。
upload_file()(ポイント4で説明)とは異なり、upload_fileobj()メソッドは、必要に応じて複数のスレッドでマルチパートアップロードを実行する管理された転送です:
object_key_1 = 'account_balances_june2023.parquet'# GENERATOR.PYスクリプトを実行するdf.to_parquet(object_key_1)# BOTO3client = boto3.client('s3')# ParquetファイルをS3にアップロードwith open(object_key_1, 'rb') as file: client.upload_fileobj(file, bucket, object_key_1)一方、awswranglerライブラリの主な利点の1つ(pandasと共に使用する場合)は、ローカルディスクに保存せずに直接S3バケットにオブジェクトを書き込むことができることです。
さらに、awswranglerは、ユーザーが:
snappy、gzip、zstdのような特定の圧縮アルゴリズムを適用する;dataset=Trueの場合、modeパラメータを使用して既存のファイルにappendまたはoverwriteする;partitions_colパラメータを使用して、1つ以上のパーティション列を指定する。
object_key_2 = 'account_balances_july2023.parquet'# AWS WRANGLER wr.s3.to_parquet(df=df, path=f's3://{bucket}/{object_key_2}', compression = 'gzip', partition_cols = ['COMPANY_CODE'], dataset=True)上記のコードを実行すると、account_balances_june2023 を単一のparquetファイルとして書き込み、account_balances_july2023 をCOMPANY_CODE で既にパーティション分割された4つのファイルを含むフォルダとして書き込みます:
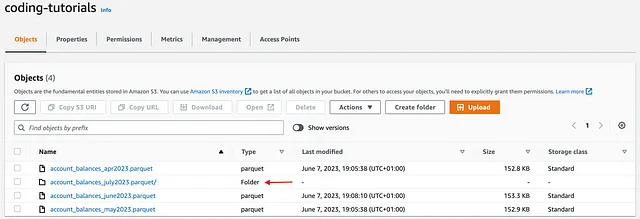
比較 → AWSWrangler の勝利
pandas を使用する場合、awswranglerは、特にこの場合、最適なツールではないboto3と比較して、S3にファイルを書き込む際にはるかに高度な操作セットを提供します。
# 7.1 オブジェクトの読み込み(Python)
boto3を使用してS3からオブジェクトを読み込もうとする場合も同様の理由が適用されます。このライブラリには組み込みの読み取りメソッドがないため、API呼び出し(get_object())を実行し、responseのBodyを読み取り、pandasにparquet_objectを渡す必要があります。
pd.read_parquet()メソッドは、入力としてファイルのようなオブジェクトを期待するため、parquet_objectから読み取ったコンテンツをバイナリストリームとして渡す必要があります。
実際には、io.BytesIO()を使用して、メモリ内の一時ファイルのようなオブジェクトを作成し、Parquetファイルをローカルに保存する必要がないため、パフォーマンスが向上します。特に、大きなファイルを扱う場合に有効です。
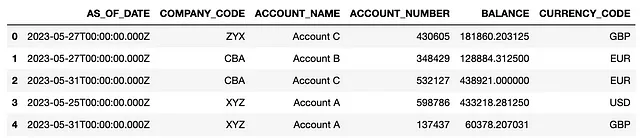
object_key = 'account_balances_may2023.parquet'# BOTO3client = boto3.client('s3')# パーケットファイルを読み取るresponse = client.get_object(Bucket=bucket, Key=object_key)parquet_object = response['Body'].read()df = pd.read_parquet(io.BytesIO(parquet_object))df.head()期待通り、awswranglerはS3からオブジェクトを読み取る際にも優れたパフォーマンスを発揮し、pandas dfを出力します。
awswranglerは、csv、json、parquetなど、複数の入力形式をサポートしており、chunkedパラメータを渡すことで、メモリにやさしい方法でオブジェクトを読み込むこともできます。
# AWS WRANGLERdf = wr.s3.read_parquet(path=f's3://{bucket}/{object_key}')df.head()# wr.s3.read_csv()# wr.s3.read_json()# wr.s3.read_parquet_table()# wr.s3.read_deltalake()上記のコードを実行すると、5月のデータを含むpandas dfが返されます。
比較 → AWSWrangler の勝利
はい、boto3の適切なメソッドがない場合でも、awswranglerはS3オブジェクトを効率的に読み取るために作成されたライブラリであり、このチャレンジでも勝利します。
# 7.2 オブジェクトの読み取り(SQL)
ここまで読み進めた方々にはボーナスが与えられます。そのボーナスは、プレーンなSQLを使用してS3からオブジェクトを読み取ることです。
以下のquery(AS_OF_DATEでデータをフィルタリングするもの)を使用して、account_balances_may2023.parquetオブジェクトからデータを取得することを希望したとしましょう。
object_key = 'account_balances_may2023.parquet'query = """SELECT * FROM s3object s WHERE AS_OF_DATE > CAST('2023-05-13T' AS TIMESTAMP)"""boto3では、select_object_content()メソッドを使用してこれを実現できます。また、inputSerializationとOutputSerializationフォーマットも指定する必要があることに注意してください。
# BOTO3client = boto3.client('s3')resp = client.select_object_content( Bucket=bucket, Key=object_key, Expression= query, ExpressionType='SQL', InputSerialization={"Parquet": {}}, OutputSerialization={'JSON': {}},)records = []# 応答を処理するfor event in resp['Payload']: if 'Records' in event: records.append(event['Records']['Payload'].decode('utf-8')) # JSONレコードを1つの文字列に連結するjson_string = ''.join(records)# JSONデータをPandas DataFrameに読み込むdf = pd.read_json(json_string, lines=True)# DataFrameを表示するdf.head()pandasのdfを使用できる場合は、awswranglerも非常に便利なselect_query()メソッドを提供しています。
# AWS WRANGLERdf = wr.s3.select_query( sql=query, path=f's3://{bucket}/{object_key}', input_serialization="Parquet", input_serialization_params={})df.head()両方のライブラリでは、返されるdfは次のようになります。
結論
このチュートリアルでは、S3バケットで実行できる7つの一般的な操作を探索し、boto3とawswranglerライブラリの比較分析を実行しました。
両方のアプローチはS3バケットとやり取りできますが、boto3クライアントはAWSサービスへの低レベルアクセスを提供し、awswranglerはさまざまなデータエンジニアリングタスクに対して簡略化されたより高レベルのインターフェイスを提供します。
全体的に、awswranglerは3ポイント(オブジェクトの存在を確認する、オブジェクトを書き込む、オブジェクトを読み取る)、boto3は2ポイント(オブジェクトのリスト、オブジェクトの削除)を獲得し、upload/downloadオブジェクトのカテゴリでは引き分けとなり、ポイントは与えられませんでした。
上記の結果にもかかわらず、真実は、両方のライブラリがそれぞれのタスクで優れるため、相互に交換して使用すると最良の結果が得られます。
ソース
- AWS Wranglerドキュメント
- Boto3 S3クライアントドキュメント
すべての画像は、特に注記がない限り、筆者によるものです。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
