「Amazon Rekognition、Amazon SageMaker基盤モデル、およびAmazon OpenSearch Serviceを使用した記事のための意味論的画像検索」
Semantic image search for articles using Amazon Rekognition, Amazon SageMaker foundation model, and Amazon OpenSearch Service
デジタルパブリッシャーは、できるだけ迅速に新しいコンテンツを生成し、公開するために、メディアのワークフローを効率化し自動化する方法を常に探しています。
パブリッシャーは数百万の画像を含むリポジトリを持っており、これらの画像を記事間で再利用する必要があります。このような規模のリポジトリ内で、記事に最も適した画像を見つけることは、時間のかかる繰り返しの手作業であり、自動化することができます。また、リポジトリ内の画像が正しくタグ付けされていることを前提としていますが、これも自動化できます(顧客の成功事例については、「Aller Media Finds Success with KeyCore and AWS」を参照してください)。
この記事では、このビジネスの課題を解決するために、Amazon Rekognition、Amazon SageMaker JumpStart、およびAmazon OpenSearch Serviceを使用する方法を示します。 Amazon Rekognitionは、機械学習(ML)の専門知識なしでアプリケーションに画像分析機能を簡単に追加できるようにし、オブジェクト検出、コンテンツモデレーション、顔検出と分析、テキストとセレブリティの認識などのユースケースを満たすさまざまなAPIが付属しています。これらのAPIをこの例で使用します。 SageMaker JumpStartは、プリビルトのソリューション、サンプルノートブック、および公開されているソースからの多くの最新のプリトレーニングモデルを備えたローコードサービスであり、単一のクリックでAWSアカウントにデプロイできます。これらのモデルは、Amazon SageMaker APIを介して安全かつ簡単にデプロイできるようにパッケージ化されています。新しいSageMaker JumpStart Foundation Hubでは、大規模な言語モデル(LLM)を簡単にデプロイし、アプリケーションと統合することができます。 OpenSearch Serviceは、OpenSearchをデプロイ、スケーリング、運用するのが簡単なフルマネージドサービスです。 OpenSearch Serviceを使用すると、インデックスにベクトルやその他のデータ型を保存し、ベクトルを使用して文書を検索し、意味的な関連性を測定するなどの豊富な機能を提供できます。この記事では、これらの機能を使用します。
この記事の最終目標は、テキスト(記事やTVの概要など)に意味的に類似した一連の画像を表示する方法を示すことです。
- 「英語のアクセント分類のための機械学習パイプラインの構築」
- イクイノックスに会いましょう:ニューラルネットワークとsciMLのためのJAXライブラリ
- 「CityDreamerと出会う:無限の3D都市のための構成的生成モデル」
次のスクリーンショットは、キーワードではなく、ミニ記事を検索入力として使用し、意味的に類似した画像を表示する例を示しています。 
ソリューションの概要
このソリューションは、主に2つのセクションに分かれています。まず、Amazon Rekognitionを使用して画像からラベルとセレブリティのメタデータを抽出します。次に、LLMを使用してメタデータの埋め込みを生成します。セレブリティの名前とメタデータの埋め込みをOpenSearch Serviceに保存します。2つ目の主要なセクションでは、OpenSearchのインテリジェントな検索機能を使用して、テキストに意味的に類似した画像をOpenSearch ServiceのインデックスからクエリするためのAPIがあります。
このソリューションでは、イベント駆動型のサービスであるAmazon EventBridge、AWS Step Functions、およびAWS Lambdaを使用して、Amazon Rekognitionを使用して画像からメタデータを抽出するプロセスをオーケストレートします。 Amazon Rekognitionは、2つのAPIコールを行って、画像からラベルと既知のセレブリティを抽出します。
Amazon Rekognitionのセレブリティ検出APIは、応答でいくつかの要素を返します。この記事では、次の要素を使用します:
- 名前、ID、URL:セレブリティの名前、一意のAmazon Rekognition ID、セレブリティのIMDbやWikipediaのリンクなどのURLのリスト。
- MatchConfidence:APIの動作を制御するために使用できる一致信頼スコア。このスコアに適切な閾値を設定して、好ましい動作ポイントを選択することをおすすめします。たとえば、99%の閾値を設定することで、より多くの誤検知を排除できますが、一部の潜在的な一致を見逃す可能性もあります。
2番目のAPIコールでは、Amazon Rekognitionのラベル検出APIが応答でいくつかの要素を返します。次の要素を使用します:
- 名前:検出されたラベルの名前
- Confidence:検出されたオブジェクトに割り当てられたラベルの信頼レベル
意味的検索の重要な概念は埋め込みです。単語の埋め込みは、ベクトルの形式で表される単語または単語グループの数値表現です。ベクトルが多数ある場合、それらの間の距離を測定し、距離が近いベクトルは意味的に類似しています。したがって、すべての画像のメタデータの埋め込みを生成し、同じモデルを使用してテキスト(記事やTVの概要など)の埋め込みを生成すると、与えられたテキストに意味的に類似した画像を見つけることができます。
SageMaker JumpStartには、埋め込みを生成するための多くのモデルがあります。このソリューションでは、Hugging FaceのGPT-J 6B Embeddingを使用します。これは高品質な埋め込みを生成し、Hugging Faceの評価結果によると、トップのパフォーマンスメトリクスの1つを持っています。もう1つのオプションとして、Amazon Bedrockもあり、ここではAmazon Titan Text Embeddingsモデルを選択して埋め込みを生成することができます。
画像メタデータの埋め込みを作成し、これをOpenSearch Serviceのインデックスにk-NNベクトルとして保存します。また、別のフィールドにはセレブリティの名前も保存します。
ソリューションの2番目の部分は、テキストに意味的に類似したトップ10の画像をユーザーに返すことです。これは記事やテレビのシノプシスなどになります。セレブリティが存在する場合は、それらも含めます。記事に添付する画像を選ぶ際には、記事の関連ポイントと共鳴する画像を望みます。SageMaker JumpStartには、多くの要約モデルがホストされており、これらは長い本文を受け取り、元の本文から主要なポイントを取り出すことができます。要約モデルとして、AI21 LabsのSummarizeモデルを使用します。このモデルは、高品質なニュース記事の要約を提供し、ソーステキストにはおおよそ10,000語のテキストを含めることができます。これにより、ユーザーは一度に記事全体を要約することができます。
テキストに名前や有名人の情報が含まれているかどうかを検出するために、Amazon Comprehendを使用します。これはテキスト文字列から主要なエンティティを抽出することができます。その後、Personエンティティでフィルタリングし、入力検索パラメータとして使用します。
次に、要約された記事を取り出し、埋め込みを生成して別の入力検索パラメータとして使用します。重要な点として、記事の埋め込みを生成するために使用するモデルとインフラストラクチャは、画像の埋め込みを生成するために使用したものと同じであることです。その後、Exact k-NNとスコアリングスクリプトを使用して、セレブリティの名前と記事の意味情報をキャプチャしたベクトルの2つのフィールドで検索できるようにします。大規模なインデックスでのこのアプローチは、高いレイテンシを引き起こす可能性があるため、スコアリングスクリプトの拡張性に関しては、「Amazon OpenSearch Serviceのベクトルデータベースの機能について説明した」投稿を参照してください。
ウォークスルー
以下の図は、ソリューションアーキテクチャを示しています。
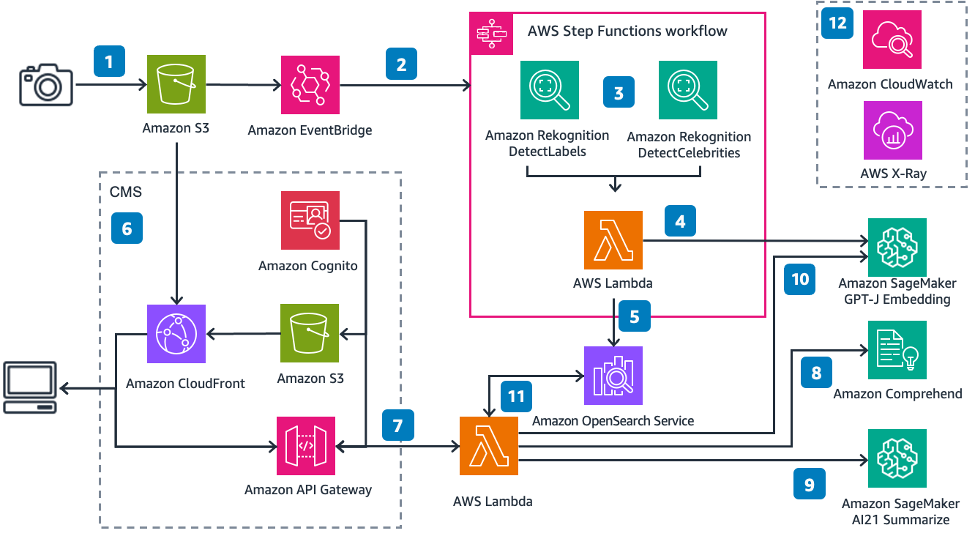
番号付きのラベルに従って:
- 画像をAmazon S3バケットにアップロードします
- Amazon EventBridgeはこのイベントを受け取り、AWS Step Functionsの実行をトリガーします
- Step Functionは画像の入力を受け取り、ラベルとセレブリティのメタデータを抽出します
- AWS Lambda関数は画像のメタデータを取得し、埋め込みを生成します
- その後、Lambda関数はセレブリティ名(存在する場合)と埋め込みをk-NNベクトルとしてOpenSearch Serviceのインデックスに挿入します
- Amazon S3は、Amazon CloudFrontディストリビューションによって提供されるシンプルな静的ウェブサイトをホストします。フロントエンドのユーザーインターフェース(UI)では、Amazon Cognitoを使用してアプリケーションに認証し、画像を検索することができます
- UIを介して記事またはテキストを送信します
- 別のLambda関数がAmazon Comprehendを呼び出してテキスト内の名前を検出します
- 関数はその後、記事から関連するポイントを要約します
- 関数は要約された記事の埋め込みを生成します
- 関数は、セレブリティの名前に一致する画像と、余弦類似性を使用してベクトルのk-nearest neighborsを検索するためにOpenSearch Serviceの画像インデックスを検索します
- Amazon CloudWatchとAWS X-Rayは、エンドツーエンドのワークフローに対する観測性を提供し、問題が発生した場合にアラートを出します。
主要な画像メタデータを抽出して保存する
Amazon Rekognition DetectLabelsおよびRecognizeCelebrities APIを使用すると、画像からメタデータが取得できます。これは、埋め込みを生成するために使用できるテキストラベルです。記事は埋め込みを生成するために使用できるテキスト入力を提供します。
単語の埋め込みを生成して保存する
以下の図は、画像のベクトルを2次元空間にプロットしたものであり、ビジュアルエイドとして、埋め込みを主要なカテゴリで分類しています。

また、この新しく書かれた記事の埋め込みを生成し、このベクトル空間内の記事に最も近い画像をOpenSearch Serviceで検索することもできます。k-nearest neighbors(k-NN)アルゴリズムを使用して、結果に返す画像の数を定義します。
先行する図を拡大すると、ベクトルは記事からの距離に基づいてランク付けされ、その後K-nearest imagesが返されます。この例では、Kの値は10です。
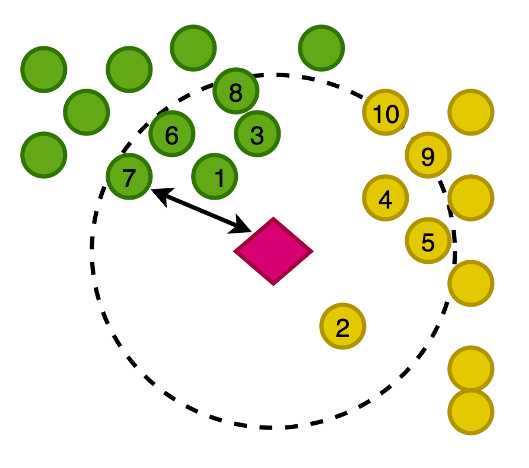
OpenSearch Serviceでは、大きなベクトルをインデックスに格納する機能が提供されており、また、さまざまな測定方法を使用して、ベクトルの近傍にベクトルを持つk-nearest documentsを返すクエリを実行する機能も提供されています。この例では、コサイン類似度を使用しています。
記事中の名前を検出する
Amazon Comprehendを使用して、記事からキーエンティティを抽出するために、AI自然言語処理(NLP)サービスであるAmazon Comprehendを使用します。この例では、Amazon Comprehendを使用してエンティティを抽出し、エンティティが「Person」であるフィルタをかけます。これにより、ジャーナリストのストーリーにAmazon Comprehendが見つけられる名前が返されます。以下は数行のコードです:
def get_celebrities(payload):
response = comprehend_client.detect_entities(
Text=' '.join(payload["text_inputs"]),
LanguageCode="en",
)
celebrities = ""
for entity in response["Entities"]:
if entity["Type"] == "PERSON":
celebrities += entity["Text"] + " "
return celebritiesこの例では、イメージをAmazon Simple Storage Service(Amazon S3)にアップロードし、ラベルや有名人を含むイメージからメタデータを抽出するワークフローがトリガーされます。次に、その抽出されたメタデータを埋め込み形式に変換し、これらのデータをすべてOpenSearch Serviceに格納します。
記事を要約し、埋め込みを生成する
記事を要約することは重要なステップであり、単語の埋め込みが記事の関連ポイントを捉えていること、そしてしたがって記事のテーマに共鳴する画像が返されることを確認するために必要です。
AI21 LabsのSummarizeモデルは、プロンプトなしで簡単に使用でき、数行のコードだけで使えます:
def summarise_article(payload):
sagemaker_endpoint_summarise = os.environ["SAGEMAKER_ENDPOINT_SUMMARIZE"]
response = ai21.Summarize.execute(
source=payload,
sourceType="TEXT",
destination=ai21.SageMakerDestination(sagemaker_endpoint_summarise)
)
response_summary = response.summary
return response_summary次に、GPT-Jモデルを使用して埋め込みを生成します
def get_vector(payload_summary):
sagemaker_endpoint = os.environ["SAGEMAKER_ENDPOINT_VECTOR"]
response = sm_runtime_client.invoke_endpoint(
EndpointName=sagemaker_endpoint,
ContentType="application/json",
Body=json.dumps(payload_summary).encode("utf-8"),
)
response_body = json.loads((response["Body"].read()))
return response_body["embedding"][0]次に、OpenSearch Serviceで画像を検索します
以下はそのクエリの例のスニペットです:
def search_document_celeb_context(person_names, vector):
results = wr.opensearch.search(
client=os_client,
index="images",
search_body={
"size": 10,
"query": {
"script_score": {
"query": {
"match": {"celebrities": person_names }
},
"script": {
"lang": "knn",
"source": "knn_score",
"params": {
"field": "image_vector",
"query_value": vector,
"space_type": "cosinesimil"
}
}
}
}
},
)
return results.drop(columns=["image_vector"]).to_dict()アーキテクチャには、コンテンツ管理システム(CMS)を表すシンプルなWebアプリが含まれています。
例として、次の入力を使用しました:
「ヴェルナーフォーゲルスは、彼のトヨタで世界中を旅行するのが大好きでした。彼がさまざまな顧客に会いに行くために車を運転する様子が多くのシーンで見られます。」
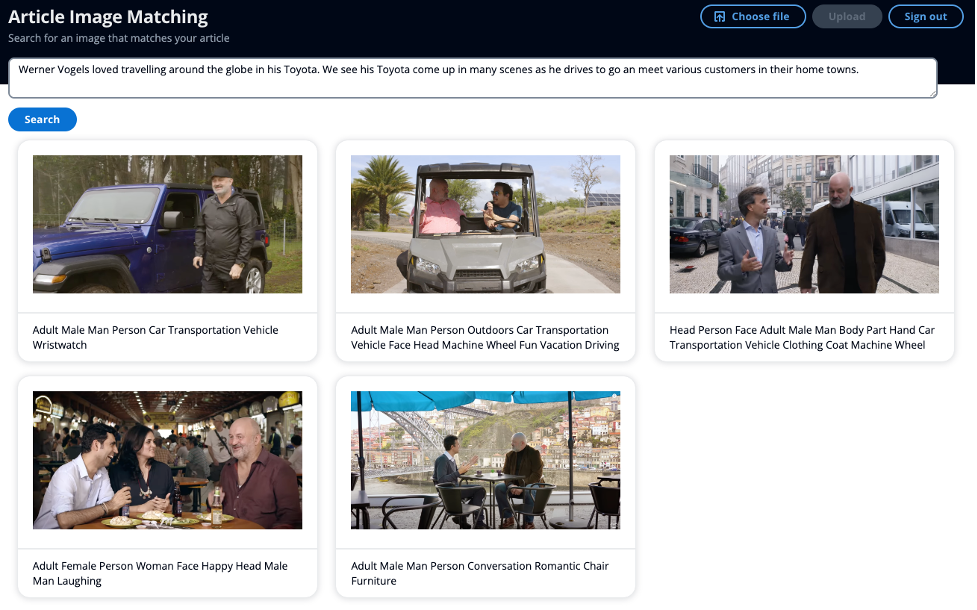
これらの画像には「トヨタ」という単語のメタデータは含まれていませんが、単語「トヨタ」の意味は車や運転と同義です。したがって、この例ではキーワード検索を超えて意味的に類似した画像を返す方法を示すことができます。上記のUIのスクリーンショットでは、画像の下に表示されるキャプションにはAmazon Rekognitionが抽出したメタデータが表示されます。
既に画像から抽出したメタデータを使用して、セレブリティの名前など他のキーワードと一緒にベクトル検索を使用して、最も共鳴する画像やドキュメントを返すような大規模なワークフローにこのソリューションを含めることができます。
結論
本記事では、Amazon Rekognition、Amazon Comprehend、SageMaker、およびOpenSearch Serviceを使用して画像からメタデータを抽出し、セレブリティや意味的な検索を使用して自動的にそれらを発見する方法を紹介しました。これは特に出版業界で重要であり、新鮮なコンテンツを迅速に複数のプラットフォームに提供することが求められます。
メディアアセットの操作に関する詳細は、「Media2Cloud 3.0でメディアインテリジェンスがさらにスマートになりました」を参照してください。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- Google AIは、高いベンチマークパフォーマンスを実現するために、線形モデルの特性を活用した長期予測のための高度な多変量モデル、TSMixerを導入します
- ジャクソン・ジュエットは、より少ないコンクリートを使用する建物の設計をしたいと考えています
- 「YaRNに会ってください:トランスフォーマーベースの言語モデルのコンテキストウィンドウを拡張するための計算効率の高い方法で、以前の方法よりもトークンが10倍少なく、トレーニングステップが2.5倍少なくて済みます」
- 「テンソル量子化:語られなかった物語」
- 「ステーブル拡散」は実際にどのように機能するのでしょうか?直感的な説明
- 「Amazon SageMaker Pipelinesを使用した機械学習ワークフローの構築のためのベストプラクティスとデザインパターン」
- BYOL(Bootstrap Your Own Latent)— コントラスティブな自己教示学習の代替手段






