「自己教師あり学習とトランスフォーマー? – DINO論文の解説」
Self-Supervised Learning and Transformers? - Explanation of DINO Paper
DINOフレームワークが自己教師あり学習の新しいSOTAを達成した方法!
![オリジナルのDINO論文[1]からの画像](https://miro.medium.com/v2/resize:fit:640/format:webp/1*TKKi9sfafVv18rI0A3aWag.png)
トランスフォーマーと自己教師あり学習。これらはどれくらい相性がいいのでしょうか?
一部の人々はトランスフォーマーアーキテクチャを好み、それをコンピュータビジョンの領域に取り入れます。他の人々は新しいプレイグラウンドに新しい子供がいることを受け入れたくありません。Facebook AI Researchの研究者たちは、最初のDINO [1]論文に取り組んでいるときに、BYOLs [2]の自己蒸留のアイデアを自己教師あり学習に組み込み、ビジョントランスフォーマーを接続した場合に何が起こるかを調査しました。これらを組み合わせると、どのような興味深い性質が出てくるのでしょうか? それは、トランスフォーマーを使用することで、モデルの自己注意マップを見ることができるというクールな効果があります!
上記のティーザー画像でそれを見ることができます。最終層のクラストークンの自己注意マップを視覚化することができ、モデルが画像の主要なオブジェクトを認識することをほぼ見ることができます。モデルはラベルなしでセグメンテーションマップを学習します!
これは本当にクールだと思います!!!
- 「NTUシンガポールの研究者がResShiftを導入:他の手法と比較して、残差シフトを使用し、画像超解像度をより速く実現する新しいアップスケーラモデル」
- UCバークレーの研究者たちは、ビデオ予測報酬(VIPER)というアルゴリズムを紹介しましたこれは、強化学習のためのアクションフリーの報酬信号として事前学習されたビデオ予測モデルを活用しています
- 「このAI研究は、合成的なタスクにおけるTransformer Large Language Models(LLMs)の制限と能力を、経験的および理論的に探求します」
最初の行の最初の画像の最終表現を予測する際、モデルは鳥に最も注意を払い、2行目の最初の画像を予測する際にはボートに注意を払い、以降も同様です!このボートの例は、モデルがショートカットを学習する傾向があるため、教師ありの方法でトレーニングする際に特にトリッキーです。水と金属のオブジェクトはボートを意味するため、モデルは水にも注意を払うようになります。
しかし、クールな発見を続ける前に、これを実現する方法を見てみましょう!
DINOフレームワーク
![DINOフレームワーク。出典:[1]](https://miro.medium.com/v2/resize:fit:640/format:webp/1*9CeO-DXXq48WDHygDBmwpg.png)
これは、自己蒸留ファミリーの一部でもあるトレーニングパイプラインです。
まず、元のソース画像を使用し、2つの異なるランダムな拡張を適用して、2つの異なるビュー、x1とx2を得ます。そして、オンラインネットワーク、すなわち学生ネットワーク、およびターゲット、すなわち教師ネットワーク(学生ネットワークの指数移動平均)、があります。ここから、事情は異なって見え始めます。さらなる射影層や予測ヘッドはありません!予測ヘッドがない場合、表現の崩壊(または確率の低下)をどのように防ぐのでしょうか? まず、教師の予測にバイアスcを単純に追加するというセンタリングがあります。
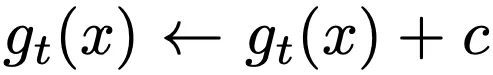
このバイアスはバッチ統計を使用してバッチの平均を計算し、EMAと同様に更新されます。
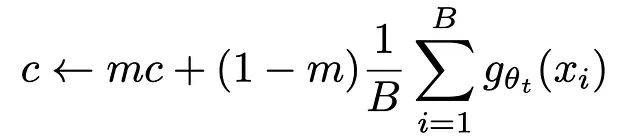
このハイパーパラメータmは、EMAの方程式の𝜏パラメータとほぼ同じです。バイアスパラメータcは、バッチごとにわずかに更新されます。このセンタリングは、定数関数への崩壊を避けるための主要な操作です!センタリングは、ある次元が擬似ラベルとして支配することを防ぎ、均一分布への崩壊を促進します!そのため、フレームワークはシャープ化されたsoftmaxにも多少依存しています。シャープ化は、オブジェクトを「分類」する際に、つまり、特徴ベクトル全体を1つの特徴次元に強く沿わせたい場合、モデルが混乱せずに常に異なるオブジェクトをランダムに選択することを防ぎます。つまり、一様分布を常に予測します。モデルがオブジェクトを選択しようとする傾向があるとき、それが自信を持って選択するようにするための技術です。学生の出力により遠くにシャープ化されたsoftmax関数を適用した後、最終的な損失はクロスエントロピー損失です。
なぜBYOLと同じくMSEではなくクロスエントロピーを使用するのですか?
![異なるパイプラインの異なる部分の効果を確認する除去研究。出典:[1]](https://miro.medium.com/v2/resize:fit:640/format:webp/1*0amAl9svY9FnlhQgLuiUXA.png)
2行目を見ると、MSEはDINOでも驚くほど機能しますが、クロスエントロピー(1行目、3行目、4行目)の方が明らかに良い結果を示します。DINOはまた、学生ネットワークにさらなる予測ヘッドを追加すると(3行目)、機能します!しかし、それはあまり助けになりません。実際、MSE損失を使用する場合、私たちはソフトマックス操作を必要としません。しかし、クロスエントロピーを使用する場合は必要です。なぜなら、その損失は確率分布上で定義されているため、再び明らかに良い結果を示すからです!
わかりました… これは解明するのに多くの情報が含まれており、直感を構築するのにも役立ちます!しかし、これは実験的に何がうまくいき、何がうまくいかないかを確認するために行われる多くの実験を示すことを願っています!
損失関数
さらに良い結果を示すのは、単純に異なるビュー埋め込みにクロスエントロピーを使用するのではなく、非常に特定のセットアップを使用することです!
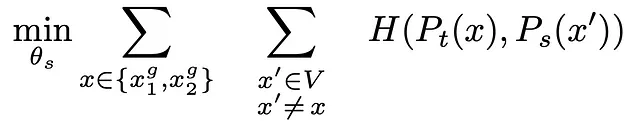
実際にこれがどういう意味なのかを見て、友好的なクオッカに戻りましょう!

再び複数のビューを生成しましょう。今回は4つのビューとします。色をわずかに変え、クロップしてリサイズします。クロップする際には、特に2つのケースがあります。元の画像の50%以上を含むクロップと、小さなカットアウトがあるクロップです。これらの大きなクロップは「g」とマークされたグローバルクロップと呼ばれます。
ビューを2つのブランチに割り当てる際、教師の場合は特にグローバルビューのみを使用し、学生の場合はすべてのビュー、つまりローカルクロップとグローバルクロップを使用します。
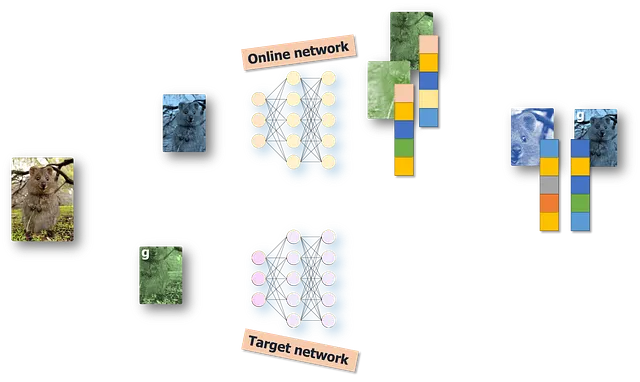
今、私たちが比較しているのは、1つのグローバルクロップの教師の埋め込みと、学生ネットワークのすべてのサンプルの埋め込み(同じグローバルビューの埋め込みを除く)です。これにより、各学生埋め込みとこの1つの教師埋め込みのクロスエントロピーを計算し、このプロセス全体を繰り返すことができます。これにより、ローカルからグローバルへの対応を強制する奇妙なクロスエントロピーの損失が得られます。
SimCLRの記事で既に2つのクロッピングケースについて話しましたが、ここではローカルとグローバルビューのように特定のケースが強制されます。モデルは、より大きなオブジェクトの一部を見ることを学び、それを埋め込みと一致させようとするときにより良い学習結果を得るようです。グローバルビューの埋め込みにはより多くの情報があり、オブジェクトをより良く認識できるためです。
直感の構築
この仮定は、教師が学生よりも優れた埋め込みを生成し、BYOLの論文でも前提とされているので、私には理にかなっています。ただし、DINOの著者は実験、除去研究、直感の構築の探求に取り組んでいるため、実際にはこの仮定を学生ネットワークと教師ネットワークの精度をトレーニング中に調べることで検証しています。
![トレーニング中の教師ネットワークと学生ネットワークの精度。出典:[1]](https://miro.medium.com/v2/resize:fit:640/format:webp/1*k-QLZR3qzO7PvcbVAoiB3g.png)
教師は生徒よりも賢く見えるし、生徒が向上すると教師も同様に向上します。それは生徒のより安定したバージョンであるためです。キーワード:指数移動平均。一定のポイントまで、教師にはもう教えることがありませんし、両者は収束します。
でも、いいですよ。私たちは再びアーキテクチャに関係なく、新しい自己蒸留フレームワークを見てきました。では、トランスフォーマーはどこにあり、なぜこのフレームワークで特に特別なのですか?!
さて、単に異なる自己教師あり学習フレームワークの比較と、古典的なResNetとVision Transformerを組み合わせてみましょう。
![異なる自己教師あり学習フレームワークを使用してトレーニングされたResNet-50とViTモデルの評価。出典:[1]](https://miro.medium.com/v2/resize:fit:640/format:webp/1*g0ZIVHQjeIegR1f01ZZQjg.png)
トレーニングされたResNetの検証精度を見ると、DINOフレームワークが最高のパフォーマンスを発揮していることがわかりますが、他のベースラインアプローチとほぼ同等と言えます。
ただし、ResNetアーキテクチャをVision Transformerに置き換えると、DINOはそのポテンシャルを発揮し、他のベースラインを大幅に上回ります!特にk-NN分類の場合はそうです。k-NNは、今日の自己教師あり学習の標準評価プロトコルの1つですが、SimCLRとBYOLが開発・公開された当時はそうではありませんでした。
ああ…あの頃…まるで2〜3年前のことのように…
k-NN!それはとてもクールで、どうやって機能するのですか?微調整は必要ありません!
もちろん、ラベルはまだ必要ですが、単にすべてのラベル付きデータを表現空間に投影し、クラスのクラスタを生成するだけです。

新しいデータポイント(例:画像)を分類したい場合、ニューラルネットワークを通して表現空間に投影します。そして、単にk個(この場合は3個)の最近傍を数え、多数決を行います。この場合、ほとんどの近傍がオレンジのクラスであるため、新しい画像もオレンジのクラスとして分類されます。このkは新しいハイパーパラメータです(まだ十分ではありませんでした)が、論文では11に設定すると最良の結果が得られることがわかっています。
結果
![線形評価とk-NNプロトコルにおける異なる自己教師あり学習および教師ありトレーニングアプローチの評価。出典:[1]](https://miro.medium.com/v2/resize:fit:640/format:webp/1*YIbAm15P96VFnKb8ZPKegA.png)
ここに、非常に興味深い結果を示す表があります。DINOは、ResNetだけで見た場合、ViTだけで見た場合、および異なるアーキテクチャ全体で最も優れています。ただし、同じサイズのアーキテクチャを見ると、完全に教師ありモデルにはまだ及びません。
素晴らしいです。しかし、さらにクールなのは、内部を見て注意マップを可視化することです。
![最終ViTブロックの上位3つの注意マップ(異なる注意ヘッドの)の視覚化。出典:[1]](https://miro.medium.com/v2/resize:fit:640/format:webp/1*v80a03EB_-09_-vqYJF6HA.png)
上位3つの注意ヘッドの注意マップを見ると、印象的な特性が見られます!各カーネルが特定の特徴を抽出するのに責任を持つCNNと同様に、異なる注意ヘッドが画像の異なる意味的領域に注意を払っていることがわかります! 2行目の最初の例では、1つのヘッドが時計の文字盤に、もう1つのヘッドが旗に、もう1つのヘッドが塔自体に注意を払っています!また、その例の1つ下の行では、1つのヘッドが襟に、1つのヘッドが頭に、1つのヘッドがシマウマの白い首に注意を払っているのが見えます!
これはとてもクールですね?!
これらすべては、ラベルや特定のセグメンテーションマップなしで学習されます!実際、私たちは単に1つの注意マップをセグメンテーションの出力として解釈し、教師ありと自己教師ありのトレーニングを比較することができます!DINOを使用しています!
![最終層のトップアテンションヘッドの注意マップの可視化。完全な教師付きでトレーニングされたモデルとDINOフレームワークを使用してトレーニングされたモデルの2回。出典:[1]](https://miro.medium.com/v2/resize:fit:640/format:webp/1*uujBrRfYwA5HhbhHzKHT_A.png)
すでに述べたように、自己教師ありの方法でトレーニングすると、モデルは特に分類のためにネットワークをトレーニングする場合よりも、画像の主要なオブジェクトに重点を置くように学習します。
自己教師あり学習の場合、学習信号はより強くなります!
分類では、モデルはタスクを解決するためにショートカットを使用することができます。鳥の画像を鳥のクラスに一致させようとする場合、モデルは空や枝を重要な特徴として使用することができます。最終的に、分類の正確度、または最適化される損失が満足されていれば、モデルは実際に鳥だけを見るのか、その周囲も見るのか、本当に気にしません。一方、自己教師ありトレーニングでは、そんなに単純で明確な最適化タスクはありません。モデルはカラーオーグメンテーションされたローカルビューをグローバルビューに一致させることを学ぶ必要があります。元のソースイメージに適用されたすべてのオーグメンテーションを無視しながら埋め込みを生成することを学ぶ必要があります。学習する必要のある特徴ははるかに具体的です。
これが理解できれば、もしかしたらこの情報に頭が少し圧倒されているかもしれませんが、特に自己教師あり学習に関する私の以前の投稿をすべて読んだばかりの場合、それは理にかなっていると思います!実は…この研究を行った後、私の脳はフライパンになってしまったかもしれません。そして、おそらくすべての詳細を把握できたわけでもありません!
自己教師あり学習は本当にクールで強力で興味深いです!しかし、これはまだ表面をかいただけです!DINOの後続論文であるiBOT [3]やDINOv2 [4]では、マスクされたイメージモデリングなどのさらなる進歩が行われました。学習された表現はさまざまな下流タスクに使用できます!
![学習済みDINOv2特徴抽出器を使用したさまざまな下流タスクの定性的な結果。出典:[4]](https://miro.medium.com/v2/resize:fit:640/format:webp/1*BZvLfAdQYdhzDL4qujVMhg.png)
DINOv2によるiBOTのトレーニングとアーキテクチャの改善は、パッチサイズやティーチャーモメンタム、より良い中心化アルゴリズムなど、多くの小さな調整ノブのリストです。
![DINOv2に追加された改善のリスト。出典:[4]](https://miro.medium.com/v2/resize:fit:640/format:webp/1*vlfwxvoJdSuTBMYA3EzcoA.png)
また、DINOv2は非常に洗練されたデータ前処理パイプラインを開発し、より大きなが手に入るが、慎重に選ばれたデータセットを生成しました。
![出典:[4]](https://miro.medium.com/v2/resize:fit:640/format:webp/1*FkXe2zHffRcsT8lbyqD04g.png)
自己教師あり学習は、膨大な数の方法と、それぞれが複雑な実装を持つ困難な分野です。そのため、Meta AIは最近、この分野を案内するための45ページのクックブック[5]を公開しました。したがって、このトピックに興味がある場合(そして、あなたはまだこのポイントで読んでいるので、おそらく興味があるでしょう)、その出版物を参照することを強くお勧めします。それはたくさんの情報ですが、非常に良い読み物です!そして、この小さなシリーズが、クックブックを使って基本的な理解を得るのに役立つことを願っています。
読んでいただき、ありがとうございました!まだであれば、自己教師あり学習と最新のAI研究についてもっと深く掘り下げるために、私の他の投稿もぜひチェックしてみてください。
P.S.: もしこのコンテンツやビジュアルが気に入った場合は、私のYouTubeチャンネルもチェックしてみてください。そこでは似たようなコンテンツを投稿していますが、より洗練されたアニメーションがあります!
参考文献
[1] 自己教師ありビジョンTransformerにおける新たな特性、M. Caron et. al、https://arxiv.org/abs/2104.14294
[2] 自己教師あり学習に対する新たなアプローチ:自分自身の潜在空間をブートストラップする、J. B. Grill、F. Strub、F. Altché、C. Tallec、P. H. Richemond et al.、https://arxiv.org/abs/2006.07733
[3] オンライントークナイザを用いた画像BERTの事前学習:iBOT、J. Zhou et al.、https://arxiv.org/abs/2111.07832
[4] 監督なしで頑健なビジュアル特徴を学習するDINOv2、M. Oquab、T. Darcet、T. Moutakanni et al.、https://arxiv.org/abs/2304.07193
[5] 自己教師あり学習のクックブック、R. Balestiero、M. Ibrahim et. al、https://arxiv.org/abs/2304.12210
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- 「Pythia 詳細な研究のための16個のLLMスイート」
- 「新しいAI研究が、PanGu-Coder2モデルとRRTFフレームワークを提案し、コード生成のための事前学習済み大規模言語モデルを効果的に向上させる」というものです
- 「AIと脳インプラントにより、麻痺した男性の運動と感覚が回復する」
- UCバークレーの研究者が、Neural Radiance Field(NeRF)の開発に利用できるPythonフレームワーク「Nerfstudio」を紹介しました
- AIを使用してAI画像の改ざんを防ぐ
- 「NYUとMeta AIの研究者は、ユーザーと展開されたモデルの間の自然な対話から学習し、追加の注釈なしで社会的な対話エージェントの改善を研究しています」
- 中国からの新しいAI研究が提案するSHIP:既存のファインチューニング手法を改善するためのプラグアンドプレイの生成AIアプローチ




