「なんでもセグメント:任意のオブジェクトのセグメンテーションを促す」
Segment Anything Encouraging segmentation of any object.
ペーパー解説 — セグメントアニシング
今日のペーパー解説はビジュアルになります! MetaのAI研究チームによるセグメントアニシングという論文を分析します。この論文は研究コミュニティだけでなく、深層学習の実践者や支持者からも注目を集めました。
セグメントアニシングは、プロンプト可能なセグメンテーションのタスクを紹介し、セグメントアニシングモデル(SAM)を提案し、11億以上のマスクを含む1,100万枚の画像を含む新しい公開データセットの生成方法について詳細を説明しています。SAMはコミュニティで広く採用され、Grounding DINOとSAMを組み合わせたGrounded-SAMなどの新しい最先端の基礎モデルの開発につながりました。
論文: セグメントアニシング
コード: https://github.com/facebookresearch/segment-anything
初出版: 2023年4月5日
著者: Alexander Kirillov、Eric Mintun、Nikhila Ravi、Hanzi Mao、Chloe Rolland、Laura Gustafson、Tete Xiao、Spencer Whitehead、Alexander C. Berg、Wan-Yen Lo、Piotr Dollár、Ross Girshick
カテゴリ: セグメンテーション、ゼロショット予測、コンピュータビジョン、プロンプティング、大規模
アウトライン
- コンテキストと背景
- SAM — セグメントアニシングモデル
- SA-1B — 10億枚のマスクを含むデータセット
- 実験と除去
- 結論
- さらなる読み物とリソース
コンテキストと背景
セグメントアニシングの著者は明確な声明をしました:“[…]私たちの目標は、画像セグメンテーションのための基礎モデルを構築することです。” 基礎モデルは自己教師あり学習の大成功から生まれました。これらのモデルは大規模なスケールで訓練され、ゼロショットのタスクで非常に優れたパフォーマンスを発揮します。つまり、訓練されたタスクとは異なるタスクを解決し、合理的なパフォーマンスを発揮することができます。近年、多くの研究者がNLP基礎モデルの成功をコンピュータビジョンなどの他の領域にも応用するために取り組んできました。
CLIPやGLIPなどのモデルにより、画像分類や物体検出タスクを固定されたクラスの代わりにテキストプロンプトによって条件付けることが可能になりました。また、BYOLやDINOなどの他のモデルは、入力画像の意味豊かな表現を学習するための異なる技術を提案しました。この表現は、多くのコンピュータビジョンアプリケーションにおける主要な要件の一つです。
セグメントアニシングの論文の目的は以下の通りです:
- プロンプトによるゼロショットセグメンテーションの実現
- 大規模モデル(SAM)のトレーニング
- 最大の公開データセットの収集と公開
なぜゼロショットのパフォーマンスが重要なのでしょうか? — 答えは二つあります。まず、最初のコンピュータビジョンモデルは、データだけでなく、多くの正解ラベルも必要とする教師あり学習で訓練されました。これらのデータの収集は非常に時間とコストがかかります。次に、モデルが予測できるクラスは、訓練に使用された固定のクラスセットに限られます。モデルに新しいクラスを追加する場合、まずデータを収集し、モデルを再訓練する必要があります。
セグメンテーションモデルにプロンプトを与える方法はどのように可能なのでしょうか? — ChatGPT、CLIP、GLIPなどのモデルからテキストプロンプティングについてはおなじみかもしれません。SAMも原則としてテキストプロンプトでテストされましたが、主にマスク、ポイント、ボックス、またはポイントグリッドでプロンプトされます。以下の画像に示すように。

SAMを文脈に置いた後、Segment Anything Model(SAM)について詳しく見てみましょう。
SAM — セグメントアニシングモデル
セグメントアニシングモデル(SAM)は、画像と1つ以上のプロンプトを入力し、有効なセグメンテーションマスクを出力するマルチモーダルモデルです。このモデルは、画像エンコーダ、プロンプトエンコーダ、マスクデコーダの3つの主要なモジュールで構成されています。
SAMは、マスク、点のセット、バウンディングボックス、テキスト、またはそれらの組み合わせのいずれかをプロンプトとして受け取ります。
注:論文ではテキストをプロンプトとして使用していると言及していますが、公式の実装やSAMデモではまだリリースされていません(2023年9月時点)。
画像エンコーダ — 指定された入力画像に対して画像の埋め込みを出力します。SAMは、事前学習済みのViT-H/16マスク付きオートエンコーダを実装して適応させます。これは、性能が高い比較的大きなモデルです。
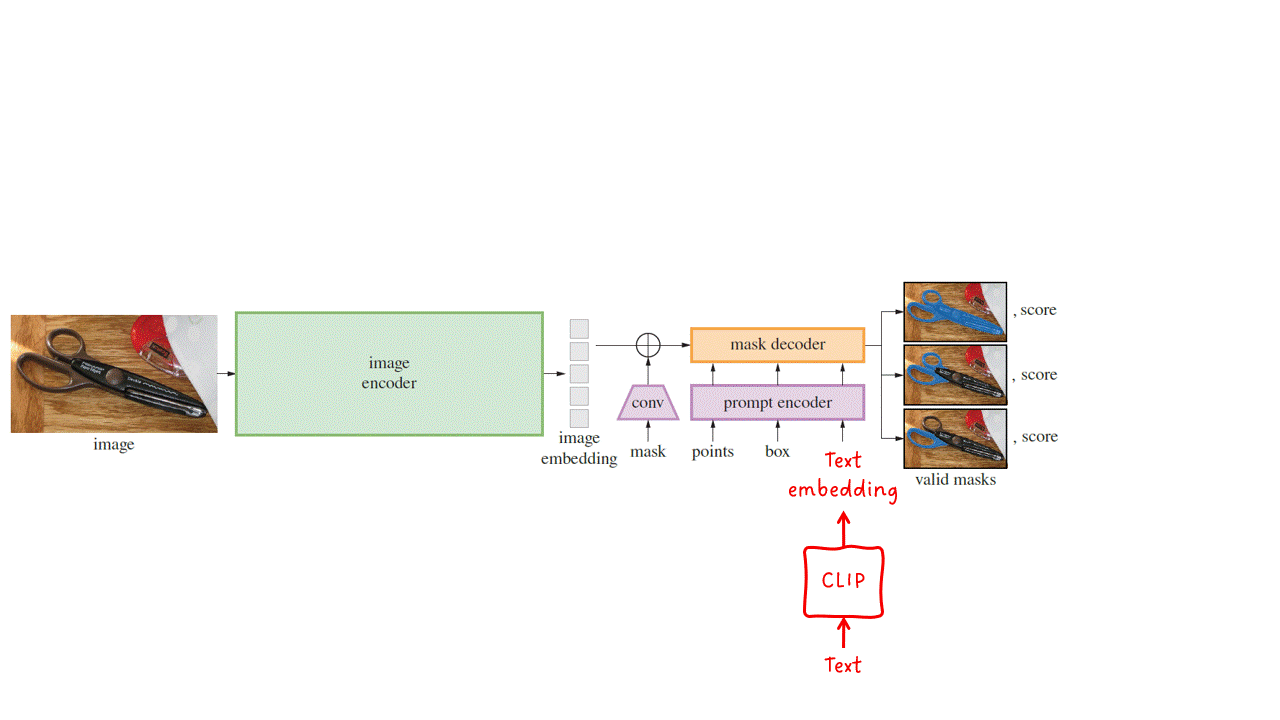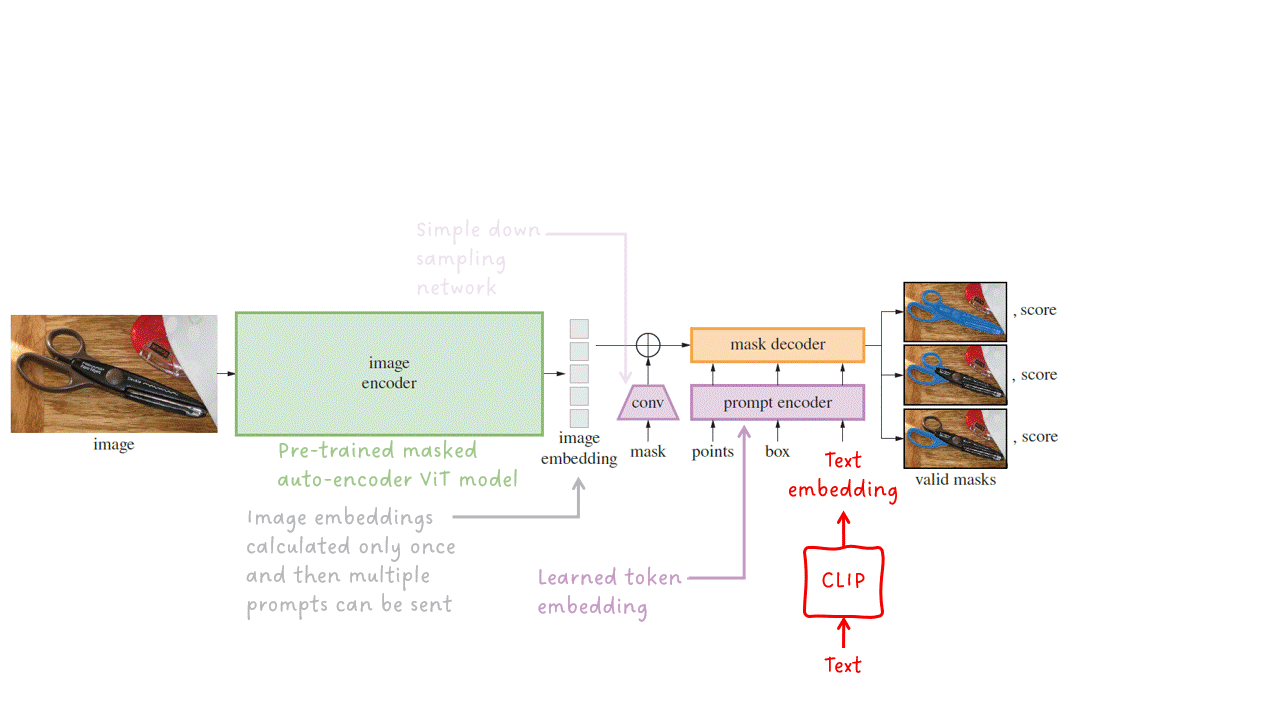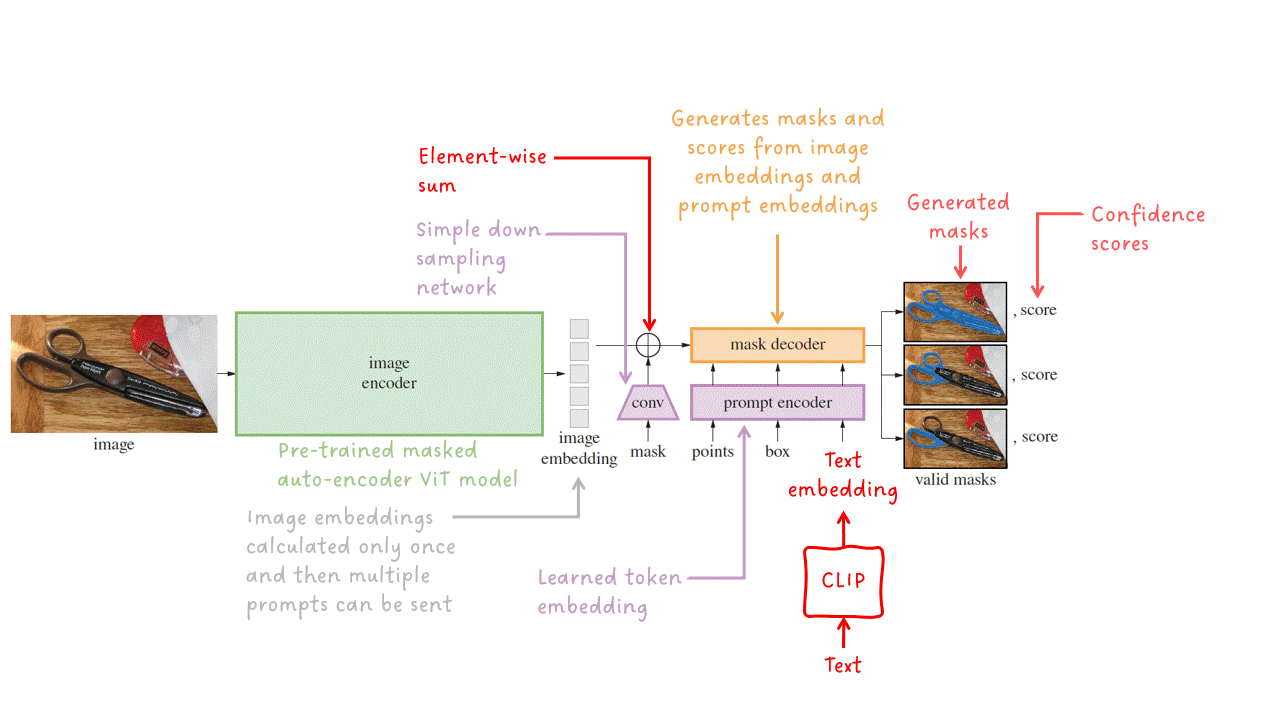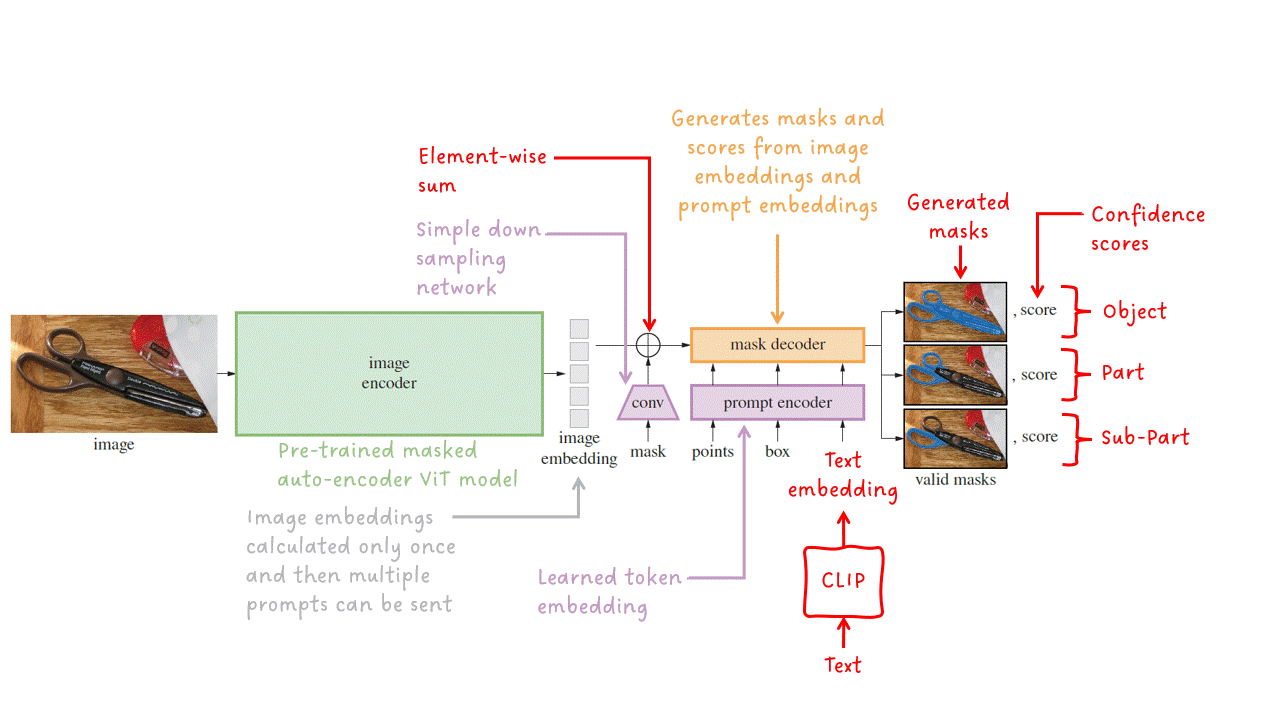
プロンプトエンコーダ — 疎なプロンプト(点、ボックス、テキストなど)は、埋め込みベクトルに変換されます。テキストプロンプトは、CLIPを使用してテキストの埋め込みに変換され、それをプロンプトエンコーダに入力します。密なプロンプト(マスクなど)は、ストライド畳み込みを使用してダウンサンプリングされ、画像の埋め込みと組み合わせられます。その後、すべての埋め込みが最終ステージであるマスクデコーダに入力されます。
マスクデコーダ — 一連の画像埋め込み(オプションで密なマスク埋め込みを含む)とプロンプト埋め込みを受け取り、有効なセグメンテーションマスクを出力します。
ここで2つの詳細を説明します:プロンプトの曖昧さと性能についてです。
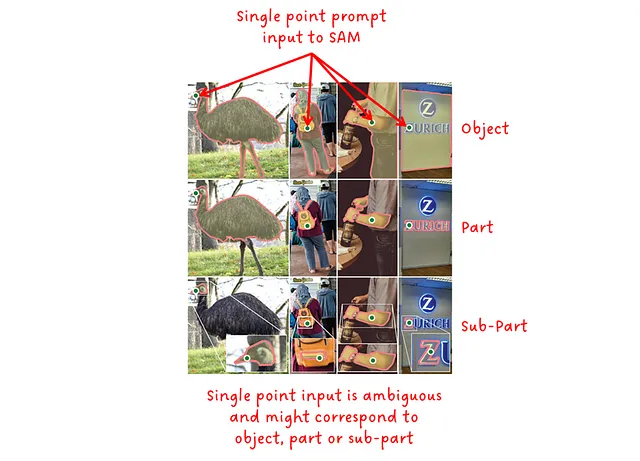
要するに、プロンプトが持つ文脈が少ないほど、曖昧さが増し、モデルが正しい出力を提供するのがより困難になります。テキストプロンプトでは、入力テキストの具体性とモデルの性能との間に関連性があることがCLIPとGLIPで確認されています。同様に、単一の点を入力として提供すると、さまざまな可能なマスクが生成される場合があります。そのため、SAMは、有効なマスクのオブジェクトレベル、パートレベル、サブパートレベルに対応する3つの出力マスクのセットを出力します。
2つ目の詳細は、推論速度のパフォーマンスです。画像エンコーダは、SAMの中で明らかに最も大きなサブモジュールですが、それは不公平な質問です。なぜなら、私はそれまでにあなたに伝えていなかったからですが、SAMは意味豊かな画像埋め込み(通常は大きなモデルが必要)を持つように設計されており、その後、軽量なプロンプトエンコーダと軽量なマスクデコーダを適用してこれらの埋め込みに対してアクションを起こします。良いことは、1つの画像エンコーダを実行するだけで、同じ画像埋め込みを使用してモデルに複数回プロンプトを実行できることです。これにより、画像埋め込みが計算された後、ブラウザでSAMを実行することができ、特定のプロンプトに対してマスクを予測するのに約50msしかかかりません。
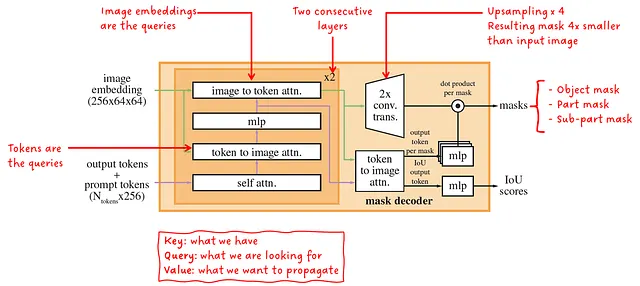
軽量なマスクデコーダについて詳しく見てみましょう。それは画像埋め込みとプロンプト埋め込みを入力し、対応するスコアを持つマスクのセットを出力します。内部では、2つの連続したデコーダブロックがセルフアテンションとクロスアテンションの組み合わせを実行し、画像とプロンプトの間に強い依存関係を生成します。単純なアップサンプリングネットワークともう1つのクロスアテンションブロックを組み合わせて、マスクとスコアを生成します。
SA-1B — 10億個のマスクを持つデータセット
Segment Anythingの第2の大きな進展は、セグメンテーションのための大規模なデータセットの作成と公開でした。このデータセットには、高解像度でライセンスされた画像が1100万枚あり、おおよそ11億個のマスクが含まれています。元のバージョンのデータセットは平均して3300×4950ピクセルでしたが、公開されたバージョンは最も短い辺に1500ピクセルのダウンサンプリングが行われました。さまざまなシーンや画像ごとのマスクの数も50以下から500以上まで、多様性に富んでいます。

このデータセットは、人間による手動のアノテーションとSAMによって生成された自動のアノテーションを組み合わせた三段階のデータエンジンで作成されました。
ステージ1:支援手動ステージ – プロのラベラーのチームが、一般的なセグメンテーションデータセットでトレーニングされた早期バージョンのSAMの支援を受けながら画像にラベルを付けました。彼らは最も目立つオブジェクトにラベルを付けるように求められ、30秒経過後も続行するように促されました。このステージの終わりに、新しいラベルでSAMが再トレーニングされました(合計12万枚の画像に430万個のマスク)。
ステージ2:半自動ステージ – このステージでは、まずSAMに一部のマスクを予測させ、その後ラベラーに残りの目立ちにくいオブジェクトをアノテーションさせることで、マスクの多様性を増やすことを目指しました。このステージの終わりに、新しいサンプルを含めてSAMが再トレーニングされました(合計30万枚の画像に1020万個のマスク)。
ステージ3:完全自動ステージ – このステージでは、アノテーションは完全に自動化されました。SAMには32×32のグリッドポイントが提示され、マスク生成といくつかの後処理が行われました。
データセットの分析
では、論文で紹介されたSA-1Bデータセットに関するいくつかの分析を詳しく見てみましょう。
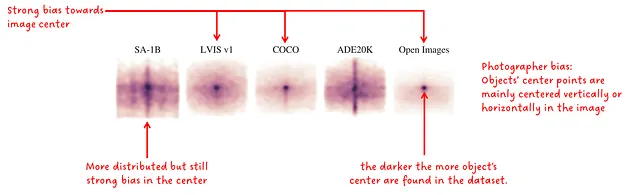
最初の評価では、マスクの中心点の正規化された分布を作成しました。興味深いことに、これらの分布は写真家のバイアスの対象となっており、ほとんどの写真では興味の対象となるオブジェクトが画像の中心と主軸に配置されています。
SA-1Bの主な強みの1つは、他のデータセットと比較して画像あたりのマスクの数が非常に多いことです(Fig.7 左)。これはまた、SA-1Bには多くの小さなマスクがあることを意味します(Fig.7 中央)。マスクの凹凸性を比較すると、複雑さの尺度となりますが、SA-1Bは手動でラベル付けされた他のデータセットと非常に類似しています(Fig.7 右)。

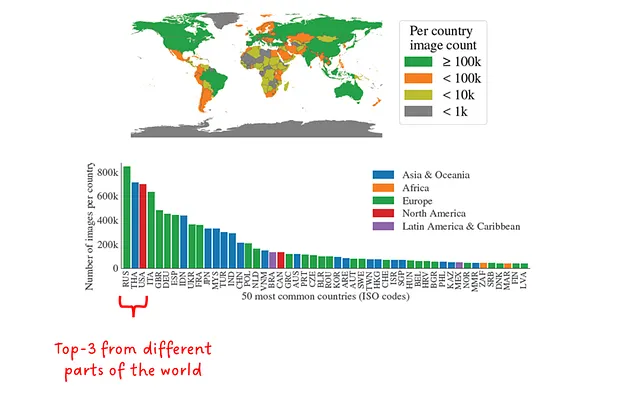
SA-1Bでは、特定の人々のグループに対するバイアスを分析するだけでなく、軽減することに重点が置かれています。Fig.8に示されているように、世界のほとんどの国々が1000以上の画像を持っており、トップ3の国々は世界のさまざまな地域から来ています。低所得国は相対的にはまだ少ない(すべてのサンプルの0.9%)、しかし絶対的には900万以上のマスクであり、他のセグメンテーションデータセット以上です。
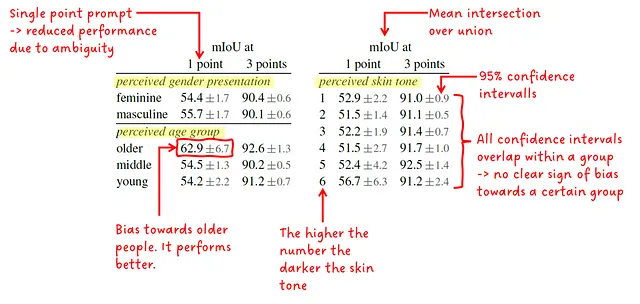
著者は、知覚された性別表現、知覚された年齢グループ、知覚された肌の色における性能の差異をさらに調査しました。彼らは、予測されたマスクと正解マスクの平均IoU(Intersection over Union)と95%信頼区間を提供しました。SAMは、単一のポイントまたは3つのポイントで提示されます。結果は、グループ内で非常に似ている(および重なり合う信頼区間)ことを示しており、グループのメンバーは特に偏見を受けていないことを示しています。唯一の例外は、知覚された年齢グループの中の年配の人々です。
実験と削減
Segment Anythingは、そのゼロショットのパフォーマンスに焦点を当てたいくつかの実験を提供しました。著者の主な目標は、プロンプト可能なゼロショットセグメンテーションモデルを見つけることでした。また、CLIPやGLIPなどの他のモデルからも、パフォーマンスの面ではプロンプトチューニングがほぼ同じくらい効果的であることがわかっています。
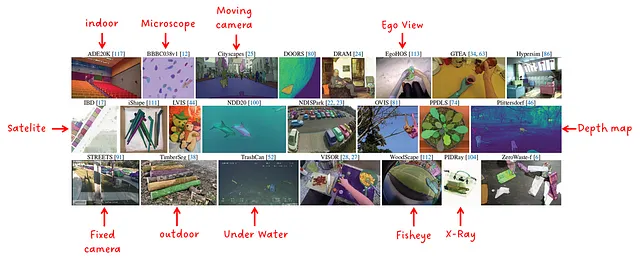
実験を行うために、23のさまざまなデータセットからなるスイートが編成されました。図10に示すように、さまざまなデータ分布からのサンプルが含まれています。
ゼロショットシングルポイント有効マスク評価
ゼロショットとは、モデルが評価中にそのデータでトレーニングされたことがないことを意味します。また、シングルポイントのプロンプティングは、図3に示すように、曖昧さがあるため、かなり難しいタスクです。
この最初の実験では、著者はSAMを彼らのベンチマークで最も優れたパフォーマンスを示した強力なインタラクティブセグメンターであるRITMと比較しました。
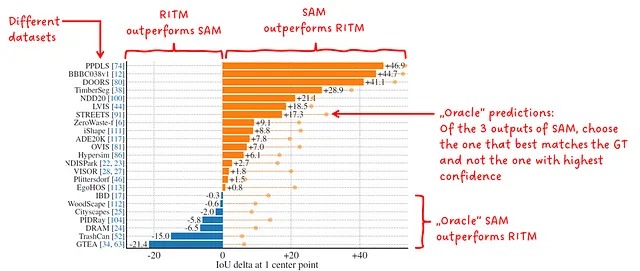
SAMは、単一のポイントでプロンプトされると、関連するスコアを持つ3つの異なるマスクを出力します。この実験では、最も高いスコアを持つマスクが評価のために選択されます。これが間違っている場合、著者はまた、予測を正解マスクと比較して最も重なり合うものを選択し、これらを「オラクル」の予測と評価します。
ゼロショットシングルポイント有効マスク予測において、SAMは23のデータセットのうち16つでRITMを上回ります。オラクルの予測を行う場合、すべての23のデータセットでRITMを上回ります。
ゼロショットテキストからマスクへ
この実験では、SAMはテキストでプロンプトされました。著者は、この機能を概念の証明として言及しており、詳細な実験は行っておらず、公式のコード実装にはこの機能は含まれていません。
図12を見ると、「ビーバーの歯のグリル」といった複雑なオブジェクトに対しても、SAMが正しいマスクを返すことができることがわかります。他の場合では、モデルはテキストのプロンプトのみを挿入して失敗し、ポイントの形でコンテキストを提供すると、SAMが単一または複数のワイパーを正しく予測できることを示しています。つまり、予測にはポイントだけでなくテキストも考慮されています。

ゼロショットエッジ検出
興味深いことに、SAMはエッジ検出にも使用することができます。トレーニング中にこのタスクを行うことは考慮されておらず、またそのようなデータにアクセスすることもありませんでした。
マップを予測するために、まずSAMは16×16のポイントのグリッドにプロンプトされ、768個の予測マスク(各ポイントに対してオブジェクト、パーツ、サブパーツ)が生成されます。生成されたマスクはフィルタリングおよび後処理され、エッジマスクを取得します。
図13に示すように、グラウンドトゥルースと比較して、SAMはより詳細な情報を予測します。ただし、公平を期すために、GTが完全ではない場合や、異なる抽象化のレイヤーをカバーしている場合、この比較は公平ではないように思われます。それにもかかわらず、パフォーマンスは非常に良好です!

ゼロショットインスタンスセグメンテーション
この実験では、SAMにはCOCOおよびLVISでトレーニングされた完全教師付きViTDet-Hのバウンディングボックス出力が与えられます。その後、生成されたマスクは初期のバウンディングボックスと共に再びSAMに入力され、結果を改良します。ViTDetとSAMの比較は図14に示されています。

ここで注目すべき2つのことがあります。COCOとLVISを調べると、マスクがオブジェクトとピクセルが一致していないことがわかります。このバイアスはViTDetに存在しており、そのためSAMの品質がより良く見えるのです。計算されたメトリックでは、どれだけ良いのかはわかりにくいです。なぜなら、グラウンドトゥルースも同じバイアスを持っており、悪いGTと比較すると、SAMのパフォーマンスは悪くなるからです。そのため、人間に視覚的に検査するよう依頼しました。また、なぜこの象は3本の足しか持っていないのかということも注目です。どれだけ頑張っても4本目が見えないのですが… 😅
消去実験
消去セクションでは、著者たちはデータセットやプロンプトのポイント数、イメージエンコーダのサイズをスケーリングすることに関心を持っていました(図13を参照)。パフォーマンスは平均IoUで報告されています。
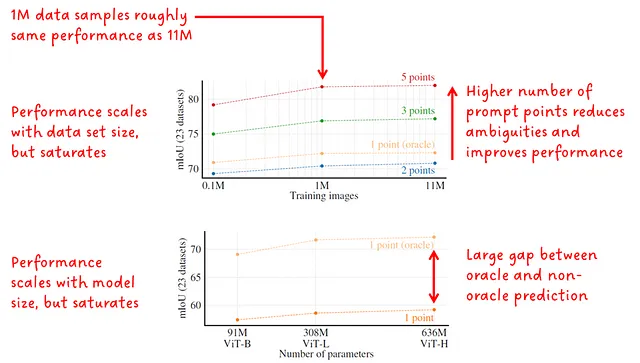
興味深いことに、データとモデルのサイズをスケーリングしても、mIoUのパフォーマンスは飽和します。これは、モデルが非常に優れているため改善の余地がほとんどないことを示しているか、おそらく彼らのアプローチの制限である可能性があります。
結論
Segment Anythingは、プロンプト可能なSegment Anythingモデル(SAM)と、1億以上のマスクと1100万枚以上の画像を含む大規模なセグメンテーションデータセットを紹介しました。セグメンテーションモデルにプロンプトを与えることは、トレーニング済みモデルを見えないタスクに適応させたり、未知のクラスを検出したりするなど、柔軟性をもたらします。SAMが監督学習の方法でトレーニングされた基礎モデルと見なされるかどうかについては議論の余地がありますが、その非凡な結果が示され、広く採用されています。
さらなる読み物とリソース
おそらくご自身でもご存知のように、深層学習の分野は信じられないほど速いペースで進化しています。そのため、SAMのリリース直後に、その成功を基にした多くの新しいプロジェクトが登場し、予測の品質をさらに向上させたり、推論時間を短縮したり、モデルをエッジアプリケーションに適したものにしたりしています。
SAMに基づいた興味深いリソースのリストを以下に示します:
- グラウンデッドセグメントアニシング
- 高品質なセグメントアニシング
- 高速セグメントアニシング
- より高速なセグメントアニシング: モバイルアプリケーション向けの軽量なSAMへ
ここでは、SAMとSA-1Bを実際に試してみたい場合のいくつかのリンクを共有します:
- SA-1Bデータセットのダウンロード
- セグメントアニシングデモ
- セグメントアニシングGitHub
- SAMを試すためのPythonノートブック
以下は、いくつかの関連する基礎モデルを分析した私の記事です:
CLIP Foundationモデル
論文要約- 自然言語監督からの転移可能なビジュアルモデルの学習
towardsdatascience.com
GLIP: オブジェクト検出への言語-画像プレトレーニングの導入
論文要約- グラウンデッド言語-画像プレトレーニング
towardsdatascience.com
BYOL – コントラスティブ自己教師あり学習の代替手法
論文分析- 自己教師あり学習への新しいアプローチ: Bootstrap Your Own Latent
towardsdatascience.com
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- アリババグループによるこの論文では、FederatedScope-LLMという包括的なパッケージが紹介されていますこれは、フェデレーテッドラーニングでLLMを微調整するためのものです
- 「LangChain、Activeloop、そしてGPT-4を使用して、Redditのソースコードをリバースエンジニアリングするための分かりやすいガイド」
- コンテンツクリエーターに必要不可欠なChatGPTプラグイン
- PyTorch LSTMCell — 入力、隠れ状態、セル状態、および出力の形状
- 「トルコ地震ツイートに対する感情分析」
- PyTorch LSTM — 入力、隠れ状態、セル状態、および出力の形状
- 『3Dディープラーニングへの道:Pythonでの人工ニューラルネットワーク』






