「LangchainとDeep Lakeでドキュメントを検索してください!」
Search documents in Langchain and Deep Lake!
イントロダクション
langchainやdeep lakeのような大規模言語モデルは、ドキュメントQ&Aや情報検索の分野で大きな進歩を遂げています。これらのモデルは世界について多くの知識を持っていますが、時には自分が何を知らないかを知ることに苦労することがあります。それにより、知識の欠落を埋めるためにでたらめな情報を作り出すことがありますが、これは良いことではありません。

しかし、Retrieval Augmented Generation(RAG)という新しい手法が有望です。RAGを使用して、プライベートな知識ベースと組み合わせてLLMにクエリを投げることで、これらのモデルをより良くすることができます。これにより、彼らはデータソースから追加の情報を得ることができ、イノベーションを促進し、十分な情報がない場合の誤りを減らすことができます。
RAGは、プロンプトを独自のデータで強化することによって機能し、大規模言語モデルの知識を高め、同時に幻覚の発生を減らします。
学習目標
1. RAGのアプローチとその利点の理解
2. ドキュメントQ&Aの課題の認識
3. シンプルな生成とRetrieval Augmented Generationの違い
4. Doc-QnAのような業界のユースケースでのRAGの実践
この学習記事の最後までに、Retrieval Augmented Generation(RAG)とそのドキュメントの質問応答と情報検索におけるLLMのパフォーマンス向上への応用について、しっかりと理解を持つことができるでしょう。
この記事はデータサイエンスブログマラソンの一環として公開されました。
はじめに
ドキュメントの質問応答に関して、理想的な解決策は、モデルに質問があった時に必要な情報をすぐに与えることです。しかし、どの情報が関連しているかを決定することは難しい場合があり、大規模言語モデルがどのような動作をするかに依存します。これがRAGの概念が重要になる理由です。
RAGパイプラインの動作方法を見てみましょう:
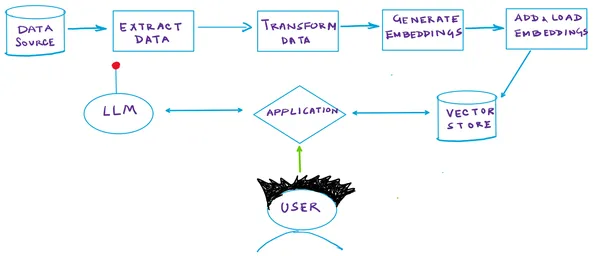
Retrieval Augmented Generation
RAGは、セマンティック類似性を利用して、クエリに応じて関連情報を自律的に特定する先端的な生成AIアーキテクチャです。以下にRAGの機能の簡潔な説明を示します:
- ベクトルデータベース:RAGシステムでは、ドキュメントは専用のベクトルDB内に格納されます。各ドキュメントは、埋め込みモデルによって生成されるセマンティックベクトルに基づいてインデックス化されます。このアプローチにより、与えられたクエリベクトルに密接に関連するドキュメントを迅速に取得することができます。各ドキュメントには、セマンティックな意味を示す数値表現(ベクトル)が割り当てられます。
- クエリベクトルの生成:クエリが送信されると、同じ埋め込みモデルがクエリを表すセマンティックベクトルを生成します。
- ベクトルベースの検索:その後、モデルはベクトル検索を利用して、クエリのベクトルに密接に一致するベクトルを持つDB内のドキュメントを特定します。これは、最も関連性の高いドキュメントを特定するために重要なステップです。
- 応答生成:関連するドキュメントを取得した後、モデルはそれらをクエリと組み合わせて応答を生成します。この戦略により、モデルは必要な時に正確に外部データにアクセスすることができ、内部の知識を補完します。
図解
以下の図は、上記で説明した手順をまとめたものです:
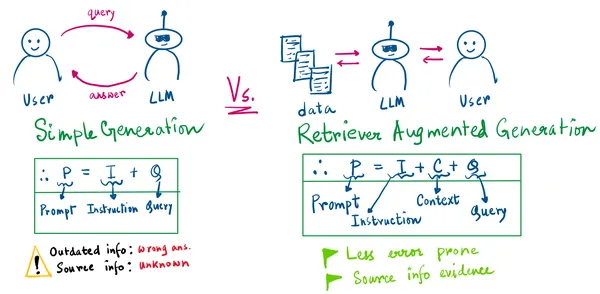
上記の図から、次の2つの重要な点を指摘できます:
- シンプルな生成では、ソース情報を知ることはありません。
- シンプルな生成は、モデルが古くなっているか、その知識の範囲がクエリが問われる前に終了している場合、間違った情報生成につながる可能性があります。
RAGのアプローチでは、LLMのプロンプトは私たちからの指示、取得したコンテキスト、およびユーザーのクエリになります。 これで、取得した情報の証拠を持っています。
それでは、情報のシナリオが常に変化する場合に、パイプラインを何度も再トレーニングする手間をかける代わりに、ベクトルストア/データストアに更新情報を追加することができます。ユーザーは次回訪れて、回答が変更された類似の質問をすることができます(例えば、XYZ企業の財務記録のようなものを考えてみてください)。それで準備完了です。
RAGの仕組みについて思い出していただければ幸いです。では、本題に移りましょう。コードです。
ちょっとした雑談のためにここに来たわけではないと思いますが、気にしないでください。👻
本題に移りましょう!
1: VSCodeプロジェクトの構造を作成する
VSCodeまたはお好きなコードエディタを開き、以下のようなプロジェクトディレクトリを作成してください(フォルダ構造に注意してください)。
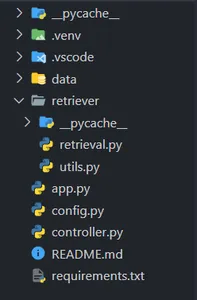
requirements.txtファイルに記載されている依存関係をインストールするために、Python ≥ 3.9の仮想環境を作成することを忘れないでください。(心配しないでください、リソースのGitHubリンクを共有します。)
2: 検索と埋め込みの操作のためのクラスを作成する
controller.pyファイルに以下のコードを貼り付けて保存してください。
from retriever.retrieval import Retriever
# ドキュメントの埋め込みと検索を管理するためのControllerクラスを作成する
class Controller:
def __init__(self):
self.retriever = None
self.query = ""
def embed_document(self, file):
# 'file'が提供された場合はドキュメントを埋め込む
if file is not None:
self.retriever = Retriever()
# 提供されたドキュメントファイルの埋め込みを作成して追加する
self.retriever.create_and_add_embeddings(file.name)
def retrieve(self, query):
# ユーザーのクエリに基づいてテキストを検索する
texts = self.retriever.retrieve_text(query)
return texts これは私たちのRetrieverのオブジェクトを作成するためのヘルパークラスです。次の2つの関数を実装しています。
embed_document: ドキュメントの埋め込みを生成します
retrieve: ユーザーがクエリを投げたときにテキストを検索します
進んでいくうちに、Retrieverのcreate_and_add_embeddingsとretrieve_textのヘルパー関数についても詳しく見ていきます!
3: 検索パイプラインのコーディング!
retrieval.pyファイルに以下のコードを貼り付けて保存してください。
3.1: 必要なライブラリとモジュールをインポートする
import os
from langchain import PromptTemplate
from langchain.embeddings import OpenAIEmbeddings
from langchain.vectorstores.deeplake import DeepLake
from langchain.document_loaders import TextLoader
from langchain.text_splitter import CharacterTextSplitter
from langchain.document_loaders import PyMuPDFLoader
from langchain.chat_models.openai import ChatOpenAI
from langchain.chains import RetrievalQA
from langchain.memory import ConversationBufferWindowMemory
from .utils import save
import config as cfg3.2: Retrieverクラスを初期化する
# Retrieverクラスを定義する
class Retriever:
def __init__(self):
self.text_retriever = None
self.text_deeplake_schema = None
self.embeddings = None
self.memory = ConversationBufferWindowMemory(k=2, return_messages=True)csv3.3: ドキュメントの埋め込みを作成してDeep Lakeに追加するためのコードを書きましょう
def create_and_add_embeddings(self, file):
# "data"という名前のディレクトリを作成する(存在しない場合)
os.makedirs("data", exist_ok=True)
# OpenAIEmbeddingsを使用して埋め込みを初期化する
self.embeddings = OpenAIEmbeddings(
openai_api_key=cfg.OPENAI_API_KEY,
chunk_size=cfg.OPENAI_EMBEDDINGS_CHUNK_SIZE,
)
# PyMuPDFLoaderを使用して提供されたファイルからドキュメントを読み込む
loader = PyMuPDFLoader(file)
documents = loader.load()
# CharacterTextSplitterを使用してテキストをチャンクに分割する
text_splitter = CharacterTextSplitter(
chunk_size=cfg.CHARACTER_SPLITTER_CHUNK_SIZE,
chunk_overlap=0,
)
docs = text_splitter.split_documents(documents)
# テキストドキュメント用のDeepLakeスキーマを作成する
self.text_deeplake_schema = DeepLake(
dataset_path=cfg.TEXT_VECTORSTORE_PATH,
embedding_function=self.embeddings,
overwrite=True,
)
# 分割されたドキュメントをDeepLakeスキーマに追加する
self.text_deeplake_schema.add_documents(docs)
# "similarity"という検索タイプでDeepLakeスキーマからテキストリトリーバを作成する
self.text_retriever = self.text_deeplake_schema.as_retriever(
search_type="similarity"
)
# テキストリトリーバの検索パラメータを設定する
self.text_retriever.search_kwargs["distance_metric"] = "cos"
self.text_retriever.search_kwargs["fetch_k"] = 15
self.text_retriever.search_kwargs["maximal_marginal_relevance"] = True
self.text_retriever.search_kwargs["k"] = 33.4: さあ、テキストを取得する関数をコーディングしましょう!
def retrieve_text(self, query):
# 読み取り専用モードでテキストドキュメント用のDeepLakeスキーマを作成します
self.text_deeplake_schema = DeepLake(
dataset_path=cfg.TEXT_VECTORSTORE_PATH,
read_only=True,
embedding_function=self.embeddings,
)
# モデルに指示を与えるためのプロンプトテンプレートを定義します
prompt_template = """あなたはテキストを分析し、ユーザーのクエリに詳細な回答を提供する高度なAIです。ユーザーがドキュメントを再訪する必要をなくすため、包括的な回答を提供することが目標です。回答ができない場合は、情報をでっち上げるのではなく、それを認識してください。
{context}
質問: {question}
回答:
"""
# "context"と"question"を持つPromptTemplateを作成します
PROMPT = PromptTemplate(
template=prompt_template, input_variables=["context", "question"]
)
# チェーンタイプを定義します
chain_type_kwargs = {"prompt": PROMPT}
# ChatOpenAIモデルを初期化します
model = ChatOpenAI(
model_name="gpt-3.5-turbo",
openai_api_key=cfg.OPENAI_API_KEY,
)
# モデルのRetrievalQAインスタンスを作成します
qa = RetrievalQA.from_chain_type(
llm=model,
chain_type="stuff",
retriever=self.text_retriever,
return_source_documents=False,
verbose=False,
chain_type_kwargs=chain_type_kwargs,
memory=self.memory,
)
# ユーザーの質問でモデルにクエリを実行します
response = qa({"query": query})
# llmからの応答を返します
return response["result"]4: パイプラインをクエリし、結果を抽出するためのユーティリティ関数
以下のコードをutils.pyファイルに貼り付けてください:
def save(query, qa):
# get_openai_callback関数を使用します
with get_openai_callback() as cb:
# qaオブジェクトにユーザーの質問でクエリを実行します
response = qa({"query": query}, return_only_outputs=True)
# llmの応答から回答を返します
return response["result"]5: キーを保存するための設定ファイル…特に特別なものではありません!
以下のコードをconfig.pyファイルに貼り付けてください:
import os
OPENAI_API_KEY = os.getenv(OPENAI_API_KEY)
TEXT_VECTORSTORE_PATH = "data\deeplake_text_vectorstore"
CHARACTER_SPLITTER_CHUNK_SIZE = 75
OPENAI_EMBEDDINGS_CHUNK_SIZE = 16最後に、デモ用のGradioアプリをコーディングすることができます!
6: Gradioアプリ!
以下のコードをapp.pyファイルに貼り付けてください:
# 必要なライブラリをインポートします
import os
from controller import Controller
import gradio as gr
# パフォーマンス向上のために、トークナイザの並列処理を無効にします
os.environ["TOKENIZERS_PARALLELISM"] = "false"
# Controllerクラスを初期化します
controller = Controller()
# アップロードされたPDFファイルを処理するための関数を定義します
def process_pdf(file):
if file is not None:
controller.embed_document(file)
return (
gr.update(visible=True),
gr.update(visible=True),
gr.update(visible=True),
gr.update(visible=True),
)
# ユーザーメッセージに応答するための関数を定義します
def respond(message, history):
botmessage = controller.retrieve(message)
history.append((message, botmessage))
return "", history
# 会話履歴をクリアするための関数を定義します
def clear_everything():
return (None, None, None)
# Gradioインターフェースを作成します
with gr.Blocks(css=CSS, title="") as demo:
# 見出しと説明を表示します
gr.Markdown("# AskPDF ", elem_id="app-title")
gr.Markdown("## PDFをアップロードして質問してください!", elem_id="select-a-file")
gr.Markdown(
"興味深いPDFをドロップして、それについての質問をしてください!",
elem_id="select-a-file",
)
# アップロードセクションを作成します
with gr.Row():
with gr.Column(scale=3):
upload = gr.File(label="PDFをアップロード", type="file")
with gr.Row():
clear_button = gr.Button("クリア", variant="secondary")
# チャットボットインターフェースを作成します
with gr.Column(scale=6):
chatbot = gr.Chatbot()
with gr.Row().style(equal_height=True):
with gr.Column(scale=8):
question = gr.Textbox(
show_label=False,
placeholder="例:ドキュメントの内容は?",
lines=1,
max_lines=1,
).style(container=False)
with gr.Column(scale=1, min_width=60):
submit_button = gr.Button(
"🤖 質問してください", variant="primary", elem_id="submit-button"
)
# ボタンを定義します
upload.change(
fn=process_pdf,
inputs=[upload],
outputs=[
question,
clear_button,
submit_button,
chatbot,
],
api_name="upload",
)
question.submit(respond, [question, chatbot], [question, chatbot])
submit_button.click(respond, [question, chatbot], [question, chatbot])
clear_button.click(
fn=clear_everything,
inputs=[],
outputs=[upload, question, chatbot],
api_name="clear",
)
# Gradioインターフェースを起動します
if __name__ == "__main__":
demo.launch(enable_queue=False, share=False)自分の🧋を手に入れて、今度はパイプラインの動作を確認しましょう!
Gradioアプリを起動するには、新しいターミナルインスタンスを開き、次のコマンドを入力します:
python app.py注意: 仮想環境がアクティブ化されており、現在のプロジェクトディレクトリにいることを確認してください。
Gradioは、以下のようにlocalhostサーバーでアプリケーションの新しいインスタンスを起動します:

する必要があるのは、localhostのURL(最後の行)をCTRL + クリックするだけで、アプリがブラウザで開きます。
やったー!
私たちのGradioアプリがここにあります!
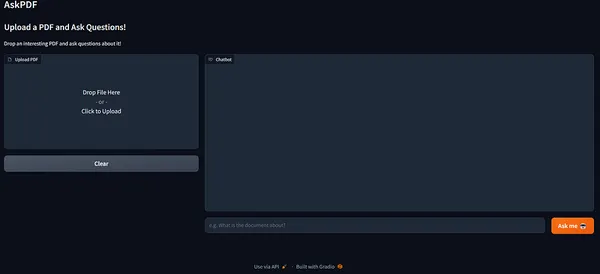
面白いPDFをドロップしましょう!私は、Harry Potterの第1章のPDFを使用します。このKaggleリポジトリには、章ごとのHarry Potterの本が.pdf形式で含まれています。
Lumos! 光があなたと共にありますように🪄
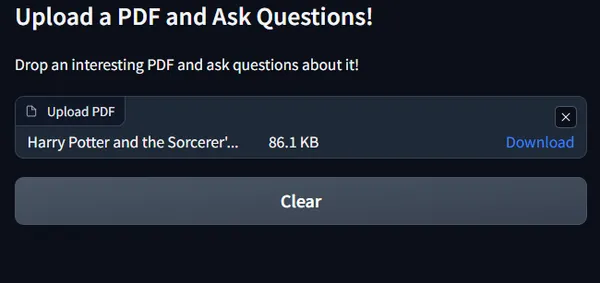
アップロードすると、クエリを問い合わせるテキストボックスが以下のように有効になります:

さあ、待望のクイズの部分に進みましょう!
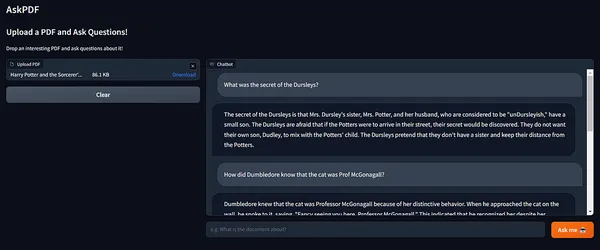
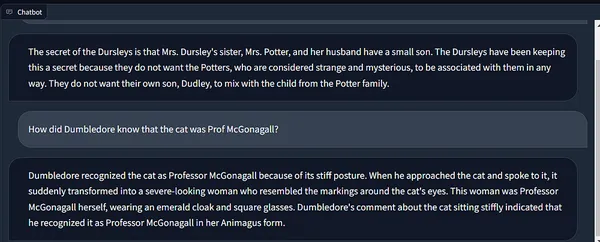
わぁ! 😲
回答の正確さに感動です!
また、Langchainのメモリがチェーンの状態を保持しており、過去の実行からのコンテキストを組み込んでいるのも見てください。
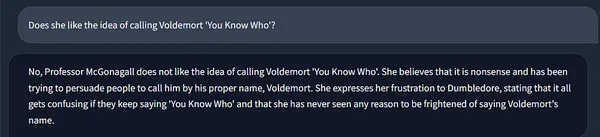
ここでは、sheは私たちの愛すべきマクゴナガル教授です! ❤️🔥
アプリの動作の短いデモ!
RAGの実践的で責任あるアプローチは、さまざまな研究分野のデータサイエンティストにとって、正確で責任あるAI製品を構築するのに非常に役立ちます。
1. 医療診断では、RAGを実装して、患者の記録、医学文献、研究論文、ジャーナルを知識ベースに統合し、重要な意思決定と研究を行う際に最新の情報を取得するのに役立ちます。
2. カスタマーサポートでは、RAGを使用した対話型AIチャットボットを簡単に利用して、顧客の問い合わせ、クレーム、製品やマニュアルに関する情報、プライベート製品および購買注文情報データベースに対する正確な応答を提供することで、顧客エクスペリエンスを向上させることができます!
3. フィンテックでは、アナリストはリアルタイムの金融データ、市場ニュース、歴史的な株価を知識ベースに組み込み、RAGフレームワークが市場のトレンド、企業の財務、投資、収益に関するクエリに迅速かつ効率的に応答し、強力で責任ある意思決定を支援します。
4. Ed-Tech市場では、RAG製のチャットボットを展開して、学生がテキストブック、研究論文、教育資源の広範なリポジトリに基づいて提案、包括的な回答、解決策を提供することで、学生が広範なマニュアル研究を必要とせずに科目の理解を深めるのに役立ちます。
範囲は無限です!
結論
この記事では、LangchainとDeep Lakeを使用して、RAGのメカニズムを探求しました。セマンティック類似性は関連情報を特定する際に重要な役割を果たします。ベクトルデータベース、クエリベクトル生成、ベクトルベースの検索を使用することで、これらのモデルは必要なときに正確に外部データにアクセスします。
その結果、より正確で文脈に適した応答が、独自のデータで充実されます。お気に入りいただけたら幸いですし、途中で何か学べたら嬉しいです!完全なコードは、GitHubのリポジトリからダウンロードして試すことができますので、ご自由にどうぞ。
キーポイント
- RAGの紹介:取得拡張生成(RAG)は、自己のデータソースから追加情報を取得することで、大規模言語モデル(LLM)の知識を向上させる有望な技術です。これにより、モデルはよりスマートになり、情報不足時のエラーが減ります。
- ドキュメントQ&Aの課題:大規模言語モデルは、ドキュメントの質問応答(Q&A)で大きな進展を遂げていますが、情報不足を判断するのに苦労することがあり、エラーが発生することがあります。
- RAGパイプライン:RAGパイプラインでは、セマンティック類似性を使用して関連するクエリ情報を特定します。ベクトルデータベース、クエリベクトル生成、ベクトルベースの検索、応答生成が関与し、より正確で文脈に適した応答が提供されます。
- RAGの利点:RAGにより、モデルは取得した情報の証拠を提供できるため、急速に変化する情報シナリオでの頻繁な再トレーニングの必要性が減ります。
- 実装の実践:この記事では、RAGパイプラインの実装ガイドを提供しています。プロジェクトの構造の設定、検索と埋め込みクラスの作成、検索パイプラインのコーディング、リアルタイムインタラクションのためのGradioアプリの構築などが含まれます。
よくある質問
この記事に表示されるメディアはAnalytics Vidhyaの所有物ではなく、著者の裁量で使用されています。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- データ・コモンズは、AIを使用して世界の公共データをよりアクセスしやすく、役に立つものにしています
- 「捕獲再捕獲法」
- VoAGIニュース、9月13日:5つのステップでSQLを始める • データサイエンスにおけるデータベース入門
- 「ウィーンのオープンデータポータルを利用した都市緑地の平等性の評価」
- 「VoAGI調査:データサイエンスの支出とトレンド2023 H2における同業他社とのベンチマーク」
- 「PyGraftに会ってください:高度にカスタマイズされた、ドメインに依存しないスキーマと知識グラフを生成する、オープンソースのPythonベースのAIツール」
- 「コンピュータビジョンと言語モデルが見たものを理解する手助け」
