スコア! チームNVIDIAが推薦システムでトロフィーを獲得しました
Score! Team NVIDIA won a trophy in the recommendation system.
5人の機械学習の専門家が4つの大陸に分散し、最先端のレコメンデーションシステムを構築するための激しい競争で3つのタスク全てに勝利しました。
この結果は、グループがNVIDIA AIプラットフォームをデジタル経済のエンジンであるこれらのエンジンに適用する際の知識と技術の賜物です。レコメンデーションシステムは、毎日数十兆の検索結果、広告、製品、音楽、ニュースストーリーを数十億人に提供しています。
Amazon KDD Cup ’23には、450以上のデータサイエンティストチームが参加しました。この3ヶ月間のチャレンジには、予測不可能な展開と、緊迫したフィニッシュがありました。
高速ギアへの切り替え
コンペティションの最初の10週間、チームは快適なリードを築きました。しかし、最終フェーズでは、主催者が新しいテストデータセットに切り替え、他のチームが急進しました。
NVIDIANsは夜間や週末にも働き、追いつくために最高のパフォーマンスを発揮しました。彼らは、ベルリンから東京まで様々な都市に住むチームメンバーからの24時間体制のSlackメッセージを残しました。
「私たちはぶっ通しで働いていました。非常に興奮していました」とサンディエゴのチームメンバーであるクリス・デオットは語りました。
別の名前の製品
最後の3つのタスクは最も難しかったです。
参加者は、ユーザーのブラウジングセッションのデータに基づいて、ユーザーがどの製品を購入するかを予測する必要がありました。しかし、トレーニングデータには多くの選択肢のブランド名が含まれていませんでした。
「最初から、これは非常に、非常に難しいテストだとわかっていました」とギルベルト「ギバ」ティテリッツは述べました。
KGMONの救世主
ブラジルのクリチバを拠点とするティテリッツは、Kaggleのコンペティションでグランドマスターにランクされた4人のメンバーの一人であり、データサイエンスのオンラインオリンピックであるKaggleのグランドマスターを勝ち抜いた数多くの機械学習のニンジャのチームの一員です。NVIDIAの創設者兼CEOであるジェンセン・ファンは彼らをKGMON(Kaggle Grandmasters of NVIDIA)と呼び、ポケモンにちなんだ遊び心のある名前です。
ティテリッツは、数十の実験で、大規模な言語モデル(LLM)を使用して生成型AIを構築し、製品名を予測しましたが、どれもうまくいきませんでした。
チームは創造的な閃きで回避策を見つけました。新しいハイブリッドランキング/分類モデルを使用した予測が的中しました。
ギリギリの戦い
競争の最後の数時間、チームは最後の提出用にすべてのモデルをまとめるために急いでいました。彼らは最大40台のコンピュータで夜間の実験を実施していました。
東京のKGMONである小野寺一樹は、緊張していました。「実際のスコアが私たちの推定と一致するかどうか本当に分からなかった」と彼は言いました。

デオットもKGMONであり、「100以上の異なるモデルが協力して単一の出力を生成する…それをリーダーボードに提出し、パウ!」と彼は思い出しました。
チームは、AI版の写真のフィニッシュラインで最も近いライバルを僅かに押しのけました。
転移学習の力
別のタスクでは、チームは英語、ドイツ語、日本語の大規模データセットから学んだ知識をフランス語、イタリア語、スペイン語の10分の1の小規模データセットに適用する必要がありました。これは、グローバルにデジタルプレゼンスを拡大する企業が直面する現実の課題です。
パリ郊外を拠点とする3回のKaggleグランドマスターであるジャン=フランソワ・ピュージェは、転移学習への効果的なアプローチを知っていました。彼は、事前学習済みのマルチリンガルモデルを使用して製品名をエンコードし、エンコーディングを微調整しました。
「転移学習の使用により、リーダーボードのスコアが大幅に改善されました」と彼は言いました。
知識とスマートソフトウェアの組み合わせ
KGMONの取り組みは、レコメンデーションシステムとしてのrecsysというフィールドが、時には科学よりも芸術の要素を持つことを示しています。それは直感と反復を組み合わせた実践です。
これは、NVIDIA Merlinなどのソフトウェア製品にエンコードされた専門知識であり、ユーザーが独自のレコメンデーションシステムを迅速に構築するためのフレームワークです。
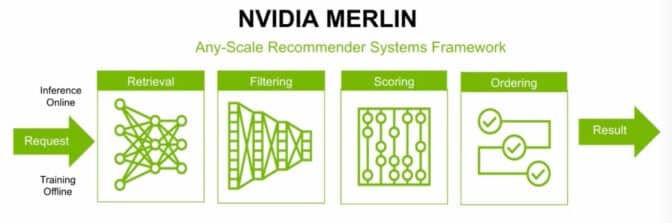
ベルリン拠点のチームメンバーであり、Merlinの設計に携わるベネディクト・シファラーは、そのソフトウェアを使用して、コンペティションの古典的なrecsysのタスクを圧倒しました。
「Merlinは、素晴らしい結果をすぐに提供してくれますし、柔軟な設計を使って特定の課題に合わせたモデルをカスタマイズすることもできます」と彼は言いました。
RAPIDSに乗る
彼もチームメイトと同様に、GPU上でデータサイエンスを加速するためのオープンソースライブラリであるRAPIDSを使用しました。
例えば、DeotteはNGCというNVIDIAの高速ソフトウェアハブからコードにアクセスしました。DASK XGBoostと呼ばれるこのコードは、大きくて複雑なタスクを8つのGPUとそれらのメモリに分散させるのに役立ちました。
一方、TitericzはcuMLというRAPIDSのライブラリを使用して、数百万の商品比較を数秒で検索しました。
チームは、複数のユーザーの訪問データを必要としないセッションベースの推薦システムに焦点を当てました。多くのユーザーがプライバシーを保護したいという要望があるため、これは現在のベストプラクティスです。
詳細は以下をご覧ください:
- Merlinを使用してセッションベースの推薦システムを構築するためのGTCセッションを視聴してください。
- NVIDIA Deep Learning Instituteのレコメンダーシステムコースを受講してください。
- NVIDIA AI Enterpriseに含まれる次アイテム予測ワークフローをチェックしてください。これは、企業が求めるセキュリティとサポートを備えた完全なソフトウェアスイートです。
- 以下のビデオもご覧ください。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
