Scikit-Learnのパイプラインを使用して、機械学習モデルのトレーニングと予測を自動化する
Scikit-Learnのパイプラインを使用して、機械学習モデルを自動化する
この記事では、Scikit-Learnのパイプラインクラスの理論と使用方法について、クロスバリデーションとハイパーパラメータのチューニングのコーディング例を使って説明します。
Scikit-Learnのパイプラインは、機械学習ライフサイクル(主にデータの前処理、モデルの作成、テストデータでの予測)で複数の操作を連鎖させるために使用されます。これにより、クロスバリデーションやハイパーパラメータのチューニングにおいて、多くの手作業が省略されます。
Scikit-Learnのパイプラインに入る前に、これらのパイプラインを使用する利点をまず理解しましょう。
便利さとカプセル化
Scikit-Learnのパイプラインをコードに組み込むと、データに対してfitメソッドとpredictメソッドを呼び出すだけで、前処理とモデルトレーニングの一連の操作を適用することができます。また、Scikit-Learnのパイプラインを使用することで、異なる機械学習アルゴリズムを試すことも容易になります。
共同パラメータの選択
パイプライン内の推定器のすべてのパラメータに対して一度にグリッドサーチを行うことができます。
安全性
Scikit-Learnのパイプラインは、クロスバリデーションにおいてテストデータからトレーニング済みモデルへの統計情報の漏洩を防ぎます。これは、トランスフォーマーと予測器のトレーニングに使用するデータが同じであることを確認することで実現されます。
Scikit-Learnのパイプラインの使用方法を示すために、KaggleのSpaceship Titanicデータセットを使用します。この記事では、データサイエンスプロジェクトライフサイクルの前処理ステップから始めます。データの探索的データ分析を見たい場合は、私の他の記事をご覧ください。
Pythonを使用した探索的データ分析(EDA)の実践ガイド
この記事では、データサイエンスプロジェクトのライフサイクルの中でも最も重要な部分の1つである、つまり…
VoAGI.com
この問題のデータは、次の前処理が必要です:
- 欠損値の補完
- カテゴリデータのエンコーディング
- 数値データのスケーリング
- 外れ値の除去
- 対数正規変換(オプション)
Scikit-Learnには、カテゴリデータのエンコーディング、欠損値の補完、スケーリングなど、ほとんどの基本的な前処理操作のための組み込みトランスフォーマーがあります。しかし、時には組み込みのScikit-Learnトランスフォーマーではデータに対して行いたい特定の操作が必要な場合があります。そのような場合は、必要に応じてカスタムトランスフォーマーを作成します。
外れ値の除去や対数正規変換のための組み込みのScikit-Learnトランスフォーマーはありません。そのため、自分自身で作成する必要があります。この記事の範囲はScikit-Learnのパイプラインの使用方法を知ることなので、ここではカスタムトランスフォーマーの作成方法については説明しません。ただし、カスタムトランスフォーマーについてのみ説明している私の他の記事もご覧いただけます。
Scikit-Learnクラスを使用したカスタムトランスフォーマーの作成のシンプルなアプローチ
この記事では、Scikit-Learnを使用して処理のニーズに応じたトランスフォーマーを作成する方法について説明します…
VoAGI.com
外れ値の除去のためのカスタムトランスフォーマーの作成
## データから外れ値を処理するためのカスタムトランスフォーマーの作成from sklearn.base import BaseEstimator, TransformerMixinclass Outlier_Remover(BaseEstimator, TransformerMixin): def __init__(self,list_of_feature_names = num_feat): self.list_of_feature_names = list_of_feature_names def fit(self, X, y=None): return self def transform(self, X, y=None): quantiles = X[num_feat].quantile(np.arange(0,1,0.25)).T quantiles = quantiles.rename(columns={0.25:'Q1', 0.50: 'Q2', 0.75:'Q3'}) quantiles['IQR'] = quantiles['Q3'] - quantiles['Q1'] quantiles['Lower_Limit'] = quantiles['Q1'] - 1.5*quantiles['IQR'] quantiles['Upper_Limit'] = quantiles['Q3'] + 1.5*quantiles['IQR'] for feature in num_feat: X[feature] = np.where((X[feature] < quantiles.loc[feature,'Lower_Limit']) | (X[feature] > quantiles.loc[feature,'Upper_Limit']) & (X[feature] is not np.nan), X[feature].median(), X[feature]) return Xここでは、num_feat はデータ内の数値特徴の名前のリストです。
対数正規分布のためのカスタムトランスフォーマーの作成
## フィーチャーの値に対して対数変換を行うために使用されるカスタムトランスフォーマーの作成class Log_Transformer(BaseEstimator, TransformerMixin): def __init__(self): pass def fit(self, X, y=None): return self def transform(self, X, y=None): for feature in num_feat: X[feature] = np.where(X[feature]==0,np.log(X[feature]+0.0002),np.log(X[feature])) return X数値特徴の前処理のためのパイプラインの作成
Scikit-Learnには、パイプラインを作成するためのPipelineクラスがあります。
数値パイプラインには3つのステップが含まれます。それらは次のとおりです:
- 上記で作成したトランスフォーマーを使用した外れ値の除去
- 欠損値を除去するためのトランスフォーマー:ここでは、Scikit-LearnのSimpleImputerトランスフォーマーを使用します。
- 数値特徴のスケーリングのためのトランスフォーマー:ここでは、scikit-learnのStandardScalerトランスフォーマーを使用します。
Scikit-LearnのPipelineオブジェクトは、タプルのリストを受け取ります。これらのタプルのそれぞれは、プロセスの1つに対して専用であり、各プロセスには2つの引数があります。最初の引数はステップの名前であり、2番目の引数はトランスフォーマーまたは推定器オブジェクトです。
Pipeline ([
(プロセス1の名前、プロセス1のオブジェクト),
(プロセス2の名前、プロセス2のオブジェクト),
…)
## sklearnのPipelineクラスを使用して数値特徴の前処理パイプラインを作成するfrom sklearn.pipeline import Pipelinefrom sklearn.impute import SimpleImputerfrom sklearn.preprocessing import MinMaxScalernum_pipe = Pipeline(steps=[ ('outlier_removal',Outlier_Remover()), ('log_transformation',Log_Transformer()), ('replacing_num_missing_values',SimpleImputer(strategy='median', missing_values=np.nan)), ('scaling',MinMaxScaler())]上記のコードブロックで、outlier_removal、replacing_num_missing_values、log_transformation、scalingはトランスフォーマーの名前です。それぞれの名前の隣に、それぞれのトランスフォーマーオブジェクトが記載されています。
カテゴリカル特徴の前処理のためのパイプラインの作成
数値特徴の場合と同様に、カテゴリカル特徴のためにも1つのパイプラインを作成します。カテゴリカル特徴の前処理には以下のステップが必要です:
- 不要な特徴の削除
- 欠損値を最頻値で置き換える
- 特徴の値を整数にエンコードする
- 欠損値を最頻値で置き換える
## sklearnのPipelineクラスを使用してカテゴリカル特徴の前処理パイプラインを作成するfrom sklearn.preprocessing import OrdinalEncoderfrom sklearn.impute import SimpleImputercat_pipe = Pipeline(steps=[ ('remove_useless_features',Remove_Useless_Features()), ('replacing_cat_missing_values', SimpleImputer(strategy='most_frequent', missing_values=np.nan)), ('encoding', OrdinalEncoder(handle_unknown='use_encoded_value', unknown_value=np.nan)), ('replacing_cat_missing_values2', SimpleImputer(strategy='most_frequent', missing_values=np.nan)) # エンコーディングステップで作成された欠損値を埋めるためにこのステップが必要です])ここでは、特徴値のエンコーディング後に再び欠損値補完を行っています。これは、エンコーダーが新しいカテゴリーを検出した場合に、それをヌル値としてエンコードするように設計されているためです(これは訓練データではなくテストデータで発生する可能性があります)。
数値とカテゴリカルの前処理パイプラインを組み合わせる
前のステップで、データの数値特徴とカテゴリカル特徴のためにパイプラインを作成しました。したがって、これら2つの事前に作成したパイプラインを組み合わせて、一括ですべての特徴の前処理が可能な1つのパイプラインを作成します。
Scikit-Learnには、これに使用するための組み込みクラスがあります。ColumnTransformerクラスがこの作業に使用されます。Scikit-LearnのColumnTransformerは、タプルのリストを主な引数として受け取ります。各タプルには3種類の情報が含まれています。最初はプロセスの名前であり、2番目はその操作に必要なオブジェクト、3番目はこのプロセスを実行するために必要な特徴の名前のリストです。
## sklearnのColumnTransformerクラスを使用して(数値とカテゴリカルの)パイプラインを組み合わせるfrom sklearn.compose import ColumnTransformerpreprocess_pipe = ColumnTransformer([ ('num_preprocessing',num_pipe, notable_num_feat), ('cat_preprocessing', cat_pipe, notable_cat_feat)], remainder='drop')cat_preprocessingとnum_preprocessingは2つのプロセスの名前です。cat_pipeとnum_pipeは前の2つのステップで作成したオブジェクトです。cat_featとnum_featは、cat_pipeとnum_pipeが適用される特徴の名前のリストです。
ColumnTransformer ([
(process1_name、process1_object、feature_names1)、
(process2_name、process2_object、feature_names2)、
以下同様…
])
ColumnTransformerには、remainderという2番目の引数があります。ここでのremainderの’drop’の値は、num_featリストまたはcat_featリストに存在しないデータのすべての特徴を削除します。ここで、引数remainderに’pass’の値を使用すると、この場合、num_featリストまたはcat_featリストに存在しないすべての特徴は前処理ステップで無視されますが、データから削除されません。
これで、前処理パイプラインが完成しましたので、いくつかの機械学習モデルを作成しましょう。
いくつかの機械学習モデルの作成
## モデル1:サポートベクトル回帰from sklearn.svm import SVRsvr = SVR()## モデル2:最近傍法回帰from sklearn.neighbors import KNeighborsRegressorknr = KNeighborsRegressor()## モデル3:決定木回帰from sklearn.tree import DecisionTreeRegressordtr = DecisionTreeRegressor(max_depth=4,random_state=123)## モデル4:ランダムフォレスト回帰from sklearn.ensemble import RandomForestRegressorrfr = RandomForestRegressor()## モデル5:Xgboost回帰from xgboost import XGBRegressorxgbr = XGBRegressor(seed=24324)## モデル6:AdaBoost回帰from sklearn.ensemble import AdaBoostRegressorabr = AdaBoostRegressor(random_state=123)## モデル7:勾配ブースティング回帰from sklearn.ensemble import GradientBoostingRegressorgbr = GradientBoostingRegressor()## モデル8:モデル1、モデル2、モデル4の投票回帰from sklearn.ensemble import VotingRegressorvr = VotingRegressor(estimators = [('svr', svr), ('knr', knr), ('rfr', rfr)])## モデル9:LightGBM回帰from lightgbm import LGBMRegressorlgbmr = LGBMRegressor()## モデル10:CatBoost回帰from catboost import CatBoostRegressorcbr = CatBoostRegressor(verbose=False)モデルができました。次のステップは、前処理パイプライン全体を上記で作成した各機械学習モデルと組み合わせることです。前処理パイプラインとモデルを組み合わせるために、再びScikit-LearnのPipelineクラスを使用します。
## svrパイプラインsvr_pipe = Pipeline(steps=[ ('preprocess_pipe',preprocess_pipe), ('svr_model',svr)])## knrパイプラインknr_pipe = Pipeline(steps=[ ('preprocess_pipe',preprocess_pipe), ('knr_model',knr)])## dtrパイプラインdtr_pipe = Pipeline(steps=[ ('preprocess_pipe',preprocess_pipe), ('dtr_model',dtr)])## rfrパイプラインrfr_pipe = Pipeline(steps=[ ('preprocess_pipe',preprocess_pipe), ('rfr_model',rfr)])## xgbrパイプラインxgbr_pipe = Pipeline(steps=[ ('preprocess_pipe',preprocess_pipe), ('xgbr_model',xgbr)])## abrパイプラインabr_pipe = Pipeline(steps=[ ('preprocess_pipe',preprocess_pipe), ('abr_model', abr)])## gbrパイプラインgbr_pipe = Pipeline(steps=[ ('preprocess_pipe',preprocess_pipe), ('gbr_model', gbr)])## vrパイプラインvr_pipe = Pipeline(steps=[ ('preprocess_pipe', preprocess_pipe), ('vr_model', vr)])## lgbmrパイプラインlgbmr_pipe = Pipeline(steps=[ ('preprocess_pipe',preprocess_pipe), ('lgbmr_model',lgbmr)])## cbrパイプラインcbr_pipe = Pipeline(steps=[ ('preprocess_pipe',preprocess_pipe), ('cbr_model',cbr)])これでパイプラインの作成が終了しました。上記のコードブロックで作成したパイプラインは、preprocessingとモデルのビルディングをfitメソッドの1回の呼び出しで行うことができます。fitメソッドとfit_transformメソッドの正しい使用方法については、次の記事をご覧ください:
scikit-learnのfit、transform、fit_transform、およびpredictメソッドの違いと使用方法
この記事では、scikit-learnのfitとfit_transformメソッドの基本的な違いと使用時の違いを教えます…
VoAGI.com
また、これらのパイプラインはクロスバリデーションやハイパーパラメータのチューニングにも使用できます。それについても例を見てみましょう。
パイプラインを使用してデータのクロスバリデーションを行う
## sklearn.model_selectionからKFoldとcross_val_scoreを使ってクロスバリデーションを行うfrom sklearn.model_selection import KFoldfrom sklearn.model_selection import cross_val_scorepipelines = [svr_pipe, knr_pipe, dtr_pipe, rfr_pipe, xgbr_pipe, abr_pipe, gbr_pipe, vr_pipe, lgbmr_pipe, cbr_pipe]models = ['SupportVectorRegressor', 'KneighborsRegressor', 'DecisionTreeRegressor', 'RandomForestRegressor', 'XgboostRegressor', 'AdaboostRegressor', 'GradientBoostRegressor', 'VotingRegressor', 'LGBMRegressor', 'CatBoostRegressor']cv = KFold(n_splits=10)for index, pipeline in enumerate(pipelines): mean = np.round(cross_val_score(estimator=pipeline, X=X, y=y,cv=cv,scoring='r2').mean(),3) std = np.round(cross_val_score(estimator=pipeline, X=X, y=y,cv=cv,scoring='r2').std(),3) print(f"モデル{models[index]}のクロスバリデーションスコアは{mean} +/- {std}です。")
ここでは、cross_val_scoreメソッドでパイプラインを最終推定器として使用しました。前処理とモデル作成を最終パイプラインに組み込んでいるため、自分で処理を行う必要はありません。
次に、最も高いr2スコアを持つアルゴリズムに対してScikit-Learnパイプラインを使用したハイパーパラメータのチューニングの例を見てみましょう。
Scikit-Learnパイプラインを使用してハイパーパラメータのチューニングを行う
上記で作成した各機械学習モデルのハイパーパラメータの辞書を作成しましょう。
ここでは、クロスバリデーションによる高性能な機械学習モデルのみに対してハイパーパラメータのチューニングを行います。
## ランダムフォレスト回帰のテスト対象ハイパーパラメータrfr_params = { 'n_estimators': np.arange(100,600,100), 'max_depth': np.arange(3,10,1), 'max_features': np.arange(9,28,3), 'bootstrap': [True, False]}## グラディエントブースト回帰のテスト対象ハイパーパラメータgbr_params = { 'learning_rate': np.arange(0.1,1.1,0.1), 'n_estimators': np.arange(100,600,100), 'max_depth': np.arange(3,10,1), 'max_features': np.arange(9,28,3)}## XGBoost回帰のテスト対象ハイパーパラメータxgbr_params = { 'n_estimators': np.arange(100,600,100), 'max_depth': np.arange(2,10,1), 'learning_rate': np.arange(0.1,1.1,0.1)}## LGBMRegressorのテスト対象ハイパーパラメータlgbmr_params = { 'boosting_type': ['gbdt', 'dart'], 'num_leaves': [2,3,4], 'max_depth': np.arange(3,10,1), 'learning_rate': np.arange(0.1,1.1,0.1), 'n_estimators': np.arange(100,600,100)}## Catboost回帰のテスト対象ハイパーパラメータcbr_params = { 'learning_rate': np.arange(0.1,1.1,0.1), 'max_depth': np.arange(3,10,1), 'n_estimators': np.arange(100,600,100)}それでは、ハイパーパラメータのチューニングを行いましょう。
from sklearn.model_selection import RandomizedSearchCVtune_models = [rfr, xgbr, gbr, lgbmr, cbr]tune_model_names = ['Random Forest Regressor', 'XGBoost Regressor', 'Gradient Boost Regressor', 'LGBM Regressor', 'Catboost Regressor']tuning_params = [rfr_params, xgbr_params, gbr_params, lgbmr_params, cbr_params]for index, model in enumerate(tune_models): grid = RandomizedSearchCV(model, tuning_params[index], cv=5, scoring='r2',random_state=2434) grid.fit(preprocess_pipe.fit_transform(X),y) print(f"ハイパーパラメータのチューニング後のモデル{tune_model_names[index]}の最良スコアは{grid.best_score_}です。") print(f"この最良スコアを与えるパラメータは{grid.best_params_}です。\n")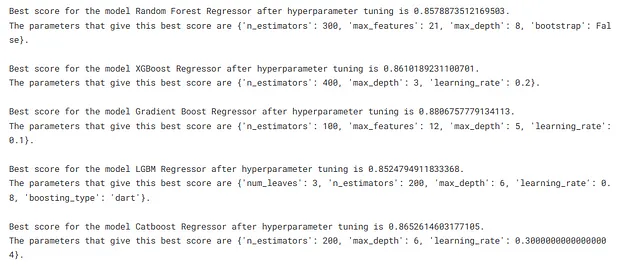
モデルに高いパフォーマンスを与えるパラメータを取得しました。それでは、それらのパラメータをモデルに設定し、パイプラインをトレーニングしましょう。
rfr.set_params(bootstrap=False,max_depth=8,max_features=21,n_estimators=300,random_state=234)xgbr.set_params(learning_rate=0.2, max_depth=3, n_estimators=400)gbr.set_params(n_estimators=100, max_features=12, max_depth=5, learning_rate=0.1, random_state=23432)lgbmr.set_params(boosting_type='dart', learning_rate=0.8, max_depth=6, n_estimators=200, num_leaves=3, random_state=3423)cbr.set_params(learning_rate=0.3, max_depth=6, n_estimators=200, random_seed=2344)パイプラインのトレーニングと保存
上記のすべての作成したパイプラインでデータをトレーニングし、それぞれを保存します。トレーニングでは、パイプライン名とデータのみを提供する必要があります。処理とトレーニングに含まれるすべてのステップは、パイプラインのおかげで自動的に実行されます。
import os, picklefor index,pipeline in enumerate(pipelines): model = pipeline.fit(X,y) with open(os.path.join('main_dir',str(models[index])+'.pkl'), 'wb') as f: pickle.dump(model,f)最後のステップは、新しいデータをロードして高パフォーマンスの訓練済みパイプラインを使用して予測するだけです。
Scikit-Learnのパイプラインは、一度にさまざまな種類の機械学習アルゴリズムを試すことで、最もパフォーマンスの良いモデルを見つけるのに非常に役立ちます。また、上記で見たように、クロスバリデーションやハイパーパラメータのチューニングを一度に多くの機械学習モデルで行うことが非常に簡単になりました。基本的に、これらのパイプラインは、多くのアルゴリズムを一つずつ試すために必要な時間を大幅に節約することによって、私たちの生活を大いに便利にしてくれます。
Scikit-Learnパイプラインとその使用方法について基本的なアイデアを得ていただけたことを願っています。この記事のコードは私のKaggleプロフィールから借用しました。全体のコードをチェックしてください:
House Prices Prediction – sklearnパイプライン
Kaggleノートブックで機械学習コードを探索・実行する | House Prices – Advanced Regressionからのデータを使用して…
www.kaggle.com
役立つリソース
Scikit-Learnドキュメント
「Hands-on Machine Learning with Scikit-Learn, Keras & TensorFlow」という書籍
(2025) scikit-learnのヒント — YouTube
アウトロ
この記事がお気に入りになったことを願っています。私のVoAGIで私の他の記事を読むためにフォローしてください。
私とつながる
ウェブサイト
[email protected] にメール
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- 直感的にR2と調整済みR2のメトリックを探索する
- 「2023年の最高のAI文法チェッカーツール」
- 高リスクの女性における前がん変化の予測 マンモグラフィに基づくディープラーニング手法の突破
- 光ベースのコンピューティング革命:強化された光ニューラルネットワークでChatGPTタイプの機械学習プログラムを動かす
- 「Advanced Reasoning Benchmark(ARB)に会いましょう:大規模な言語モデルを評価するための新しいベンチマーク」
- 「FACTOOLにご紹介いたします:大規模言語モデル(例:ChatGPT)によって生成されたテキストの事実エラーを検出するためのタスクとドメインに依存しないフレームワーク」
- LGBMClassifier 入門ガイド





