「Scikit-Learnによるアンサンブル学習:フレンドリーな紹介」
Scikit-Learnのアンサンブル学習のフレンドリーな紹介
XGBoostやランダムフォレストなどのアンサンブル学習アルゴリズムは、Kaggleのコンペティションでトップのパフォーマンスを示しています。それらはどのように機能するのでしょうか?

ロジスティック回帰や線形回帰などの基本的な学習アルゴリズムは、機械学習の問題に適切な結果を得るにはあまりにも単純すぎます。ニューラルネットワークを使用するという解決策もありますが、それにはほとんど利用できないほどの大量のトレーニングデータが必要です。アンサンブル学習技術を使用すると、限られた量のデータでも単純なモデルのパフォーマンスを向上させることができます。
大きな瓶の中にいくつのジェリービーンズが入っているかを人に推測してもらうと想像してください。一人の人の回答は正確な推定値とは限りません。代わりに、同じ質問を千人にすると、平均的な回答は実際の数値に近いものになるでしょう。これを「群衆の知恵」と呼びます[1]。複雑な推定課題に取り組む際には、群衆は個人よりもはるかに正確な場合があります。
アンサンブル学習アルゴリズムは、回帰器や分類器などのモデルの予測を集約することで、この単純な原理を利用します。分類器の集約では、アンサンブルモデルは低レベル分類器の予測の中で最も一般的なクラスを選ぶことができます。代わりに、回帰タスクでは予測の平均値や中央値を使用することができます。
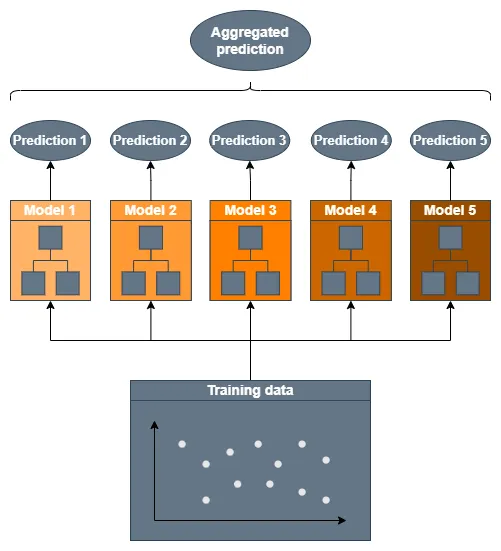
多数の弱い学習者、つまりランダムな推測よりもわずかに優れた分類器や回帰器を集約することで、信じられない結果を得ることができます。2値分類のタスクを考えてみましょう。個々の精度が51%である1000の独立した分類器を集約することにより、精度が75%のアンサンブルを作成することができます[2]。
これがなぜアンサンブルアルゴリズムが多くの機械学習コンペティションで勝利する理由です!
アンサンブル学習アルゴリズムを構築するためのいくつかの技術が存在します。主なものはバギング、ブースティング、スタッキングです。以下に続きます…
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- 「機械学習を利用した資産の健全性とグリッドの耐久性の向上」
- 「Amazon Rekognition、Amazon SageMaker基盤モデル、およびAmazon OpenSearch Serviceを使用した記事のための意味論的画像検索」
- 「英語のアクセント分類のための機械学習パイプラインの構築」
- イクイノックスに会いましょう:ニューラルネットワークとsciMLのためのJAXライブラリ
- 「CityDreamerと出会う:無限の3D都市のための構成的生成モデル」
- Google AIは、高いベンチマークパフォーマンスを実現するために、線形モデルの特性を活用した長期予測のための高度な多変量モデル、TSMixerを導入します
- ジャクソン・ジュエットは、より少ないコンクリートを使用する建物の設計をしたいと考えています





