「Amazon SageMakerを使用して数千のMLモデルのトレーニングと推論をスケール化する」
Scaling the training and inference of thousands of ML models using Amazon SageMaker.
機械学習(ML)がさまざまな産業でますます普及するにつれて、組織は顧客の多様なニーズに応えるために大量のMLモデルをトレーニングおよび提供する必要性を感じています。特にサービスとしてのソフトウェア(SaaS)プロバイダーにとっては、数千のモデルを効率的かつ費用効果の高い方法でトレーニングおよび提供する能力は、急速に変化する市場で競争力を維持するために重要です。
数千のモデルをトレーニングおよび提供するには、頑強でスケーラブルなインフラストラクチャが必要です。ここでAmazon SageMakerが役立ちます。SageMakerは、開発者やデータサイエンティストが迅速にMLモデルを構築、トレーニング、展開できる完全管理型のプラットフォームであり、AWSクラウドインフラストラクチャを使用することでコスト削減の利点も提供します。
この記事では、Amazon SageMaker Processing、SageMakerトレーニングジョブ、SageMakerマルチモデルエンドポイント(MME)などのSageMakerの機能を使用して、費用効果の高い方法で数千のモデルをトレーニングおよび提供する方法について探求します。説明されたソリューションで始めるには、GitHubの付属のノートブックを参照できます。
ユースケース:エネルギー予測
この記事では、エネルギー消費量を追跡し予測を提供することで顧客の持続可能性を向上させるISV企業の役割を想定しています。当社は1,000人の顧客がおり、エネルギー使用状況をよりよく理解し、環境への影響を軽減するための情報を得たいと考えています。このために、合成データセットを使用し、Prophetに基づいたMLモデルを各顧客ごとにトレーニングしてエネルギー消費量の予測を行います。SageMakerを使用することで、1,000のモデルを効率的にトレーニングおよび提供し、顧客に正確で実行可能なエネルギー使用状況の洞察を提供することができます。
生成されたデータセットには次の3つの特徴があります:
- customer_id – これは各顧客の整数識別子で、0から999の範囲です。
- timestamp – これはエネルギー消費が測定された時刻を示す日時値です。タイムスタンプはコードで指定された開始日と終了日の間でランダムに生成されます。
- consumption – これはエネルギー消費を示す浮動小数点値で、いくつかの任意の単位で測定されます。消費量の値は、0から1,000の範囲で正弦波の季節性を持ってランダムに生成されます。
ソリューションの概要
数千のMLモデルを効率的にトレーニングおよび提供するために、次のSageMakerの機能を使用できます:
- SageMaker Processing – SageMaker Processingは、入力データのデータ処理およびモデル評価タスクを実行できる完全管理型のデータ準備サービスです。SageMaker Processingを使用して、生データをトレーニングおよび推論に必要な形式に変換し、モデルのバッチおよびオンライン評価を実行することができます。
- SageMakerトレーニングジョブ – SageMakerトレーニングジョブを使用して、さまざまなアルゴリズムと入力データタイプでモデルをトレーニングし、トレーニングに必要な計算リソースを指定することができます。
- SageMaker MME(マルチモデルエンドポイント) – マルチモデルエンドポイントを使用すると、単一のエンドポイント上で複数のモデルをホストすることができます。これにより、単一のAPIを使用して複数のモデルから予測を提供することが容易になります。MMEは、複数のモデルから予測を提供するために必要なエンドポイントの数を減らすことで、時間とリソースを節約することができます。MMEはCPUおよびGPUをバックエンドとするモデルのホスティングをサポートしています。なお、このシナリオでは1,000のモデルを使用していますが、これはサービス自体の制限ではありません。
次の図は、ソリューションアーキテクチャを示しています。
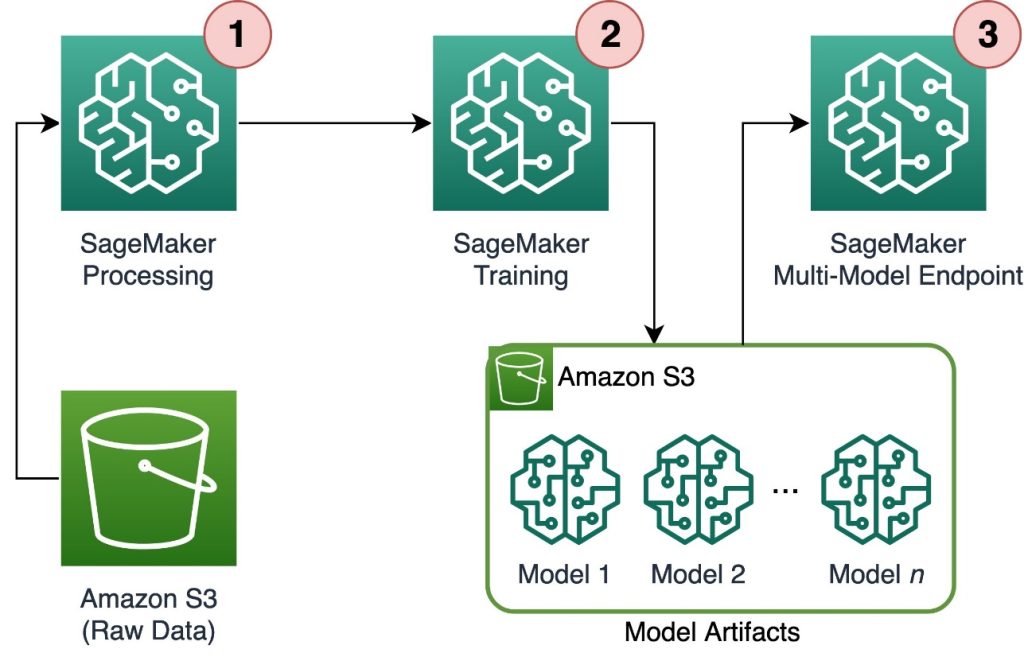
ワークフローには次のステップが含まれます:
- SageMaker Processingを使用して、データを前処理し、各顧客ごとに1つのCSVファイルを作成し、Amazon Simple Storage Service(Amazon S3)に保存します。
- SageMakerトレーニングジョブは、SageMaker Processingジョブの出力を読み取り、ラウンドロビン方式でトレーニングインスタンスに分散します。なお、これはAmazon SageMaker Pipelinesでも実現できます。
- モデルアーティファクトはトレーニングジョブによってAmazon S3に保存され、SageMaker MMEから直接提供されます。
数千のモデルへのトレーニングのスケーリング
数千のモデルのトレーニングをスケーリングするには、SageMaker Python SDKのTrainingInputクラスのdistributionパラメータを使用します。このパラメータを使用すると、トレーニングジョブのための複数のトレーニングインスタンスにデータをどのように分散するかを指定することができます。 distributionパラメータには3つのオプションがあります:FullyReplicated、ShardedByS3Key、およびShardedByRecord。 ShardedByS3Keyオプションは、トレーニングデータをS3オブジェクトキーでシャーディングし、各トレーニングインスタンスがデータのユニークなサブセットを受け取るようにすることで重複を回避します。 SageMakerがトレーニングコンテナにデータをコピーした後、フォルダとファイルの構造を読み取って、顧客ファイルごとにユニークなモデルをトレーニングすることができます。以下はコードの例です:
# トレーニングデータがすでにS3バケットにあると仮定し、親フォルダを渡す
s3_input_train = sagemaker.inputs.TrainingInput(
s3_data='s3://my-bucket/customer_data',
distribution='ShardedByS3Key'
)
# SageMakerエスティメータを作成し、トレーニングインプットを設定する
estimator = sagemaker.estimator.Estimator(...)
estimator.fit(inputs=s3_input_train)SageMakerの各トレーニングジョブは、トレーニングジョブが完了するとモデルを /opt/ml/model フォルダに保存し、それを model.tar.gz ファイルにアーカイブしてAmazon S3にアップロードします。パワーユーザーはSageMakerパイプラインを使用してこのプロセスを自動化することもできます。同じトレーニングジョブで複数のモデルを保存する場合、SageMakerはすべてのトレーニング済みモデルを含む単一の model.tar.gz ファイルを作成します。これにより、モデルをサービス化するためにはアーカイブを展開する必要があります。これを避けるために、個々のモデルの状態を保存するためにチェックポイントを使用します。SageMakerは、トレーニングジョブ中に作成されたチェックポイントをAmazon S3にコピーする機能を提供します。ここでは、チェックポイントを事前指定された場所に保存する必要がありますが、デフォルトでは /opt/ml/checkpoints となります。これらのチェックポイントは、後でトレーニングを再開するためのものやエンドポイントにデプロイするためのモデルとして使用することができます。SageMakerのトレーニングプラットフォームがAWS CloudストレージとSageMakerのトレーニングジョブ間のトレーニングデータセット、モデルアーティファクト、チェックポイント、および出力のためにストレージパスをどのように管理しているかの概要については、「Amazon SageMaker Training Storage Folders for Training Datasets, Checkpoints, Model Artifacts, and Outputs」を参照してください。
次のコードは、トレーニングロジックを含む train.py スクリプト内の架空の model.save() 関数を使用しています:
import tarfile
import boto3
import os
[ ... argument parsing ... ]
for customer in os.list_dir(args.input_path):
# トレーニングジョブ内でローカルにデータを読み込む
df = pd.read_csv(os.path.join(args.input_path, customer, 'data.csv'))
# モデルを定義してトレーニングする
model = MyModel()
model.fit(df)
# モデルを出力ディレクトリに保存する
with open(os.path.join(output_dir, 'model.json'), 'w') as fout:
fout.write(model_to_json(model))
# モデルとトレーニングスクリプトを含む model.tar.gz アーカイブを作成する
with tarfile.open(os.path.join(output_dir, '{customer}.tar.gz'), "w:gz") as tar:
tar.add(os.path.join(output_dir, 'model.json'), "model.json")
tar.add(os.path.join(args.code_dir, "training.py"), "training.py")SageMaker MMEを使用して数千のモデルをスケーリングする
SageMaker MMEを使用すると、エンドポイント構成に複数のモデルを含めることで同時に複数のモデルをサービス化できます。そして、そのエンドポイント構成を使用してエンドポイントを作成します。新しいモデルを追加するたびにエンドポイントを再デプロイする必要はありません。なぜなら、エンドポイントは指定されたS3パスに保存されたすべてのモデルを自動的にサービス化するからです。これは、マルチモデルサーバ(MMS)を使用して実現されます。MMSは、MLモデルを提供するためのフロントエンドを提供するためにコンテナにインストールされるオープンソースのフレームワークです。また、TorchServeやTritonなどの他のモデルサーバも使用できます。MMSはSageMaker推論ツールキットを介してカスタムコンテナにインストールすることもできます。Dockerfileを構成してMMSを含め、モデルを提供するために使用する方法については、「Build Your Own Container for SageMaker Multi-Model Endpoints」を参照してください。
次のコードスニペットは、SageMaker Python SDKを使用してMMEを作成する方法を示しています:
from sagemaker.multidatamodel import MultiDataModel
# MultiDataModelの定義を作成する
multimodel = MultiDataModel(
name='customer-models',
model_data_prefix=f's3://{bucket}/scaling-thousand-models/models',
model=your_model,
)
# リアルタイムエンドポイントにデプロイする
predictor = multimodel.deploy(
initial_instance_count=1,
instance_type='ml.c5.xlarge',
)MMEが稼働している場合、予測を生成するために呼び出すことができます。呼び出しは、AWS SDKだけでなくSageMaker Python SDKでも行うことができます。以下のコードスニペットに示すように:
predictor.predict(
data='{"period": 7}', # ペイロード、この場合はJSON
target_model='{customer}.tar.gz' # ターゲットモデルの名前
)モデルを呼び出す際、モデルは初めにAmazon S3からインスタンスに読み込まれます。これにより、新しいモデルを呼び出す際にはコールドスタートが発生することがあります。頻繁に使用されるモデルは、低遅延の推論を提供するためにメモリとディスク上にキャッシュされます。
結論
SageMakerは、数千のMLモデルをトレーニングおよび提供するための強力で費用効果の高いプラットフォームです。SageMaker Processing、トレーニングジョブ、およびMMEなどの機能により、組織は効率的にスケールできる数千のモデルをトレーニングおよび提供することができます。また、AWS Cloudインフラストラクチャを使用することによるコスト節約の利点も享受することができます。数千のモデルのトレーニングと提供にSageMakerを使用する方法について詳しくは、「データの処理、Amazon SageMakerでのモデルのトレーニング、および1つのエンドポイントの背後に1つのコンテナで複数のモデルをホストする」を参照してください。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles






