一度言えば十分です!単語の繰り返しはAIの向上に役立ちません
Say it once, that's enough! Repeating words does not contribute to the improvement of AI.
| ARTIFICIAL INTELLIGENCE | NLP | LLMs
LLMsにおいてトークンの繰り返しがどのように、なぜ問題になるのか?
大規模言語モデル(LLMs)は能力を発揮して、世界中で注目を集めています。現在は、どの大企業もモデルを持っていますが、その中身はすべてトランスフォーマーです。 誰もが兆候のパラメータを夢見ますが、限界はありませんか?
この記事では、以下について議論しています。
- より大きなモデルが小さいモデルよりも優れたパフォーマンスを発揮することは保証されているのでしょうか?
- 巨大なモデルのデータはありますか?
- 新しいデータを収集する代わりに、データを再利用した場合に何が起こるのでしょうか?
空を飛び越えるスケーリング:翼を傷つけているのは何ですか?
OpenAIはスケーリング則を定義し、モデルのパフォーマンスは使用されるパラメータとデータポイントの数に応じてべき乗則に従うと述べています。これに加えて、新しい性質の発見を求める探索がパラメータ競争を生み出しました: モデルが大きければ大きいほど、優れているとされます。
それは本当でしょうか?より大きなモデルがより良いパフォーマンスを発揮しているのでしょうか?
最近、新しい性質が危機に陥っています。スタンフォード大学の研究者たちが示したように、新しい性質の概念は存在しないかもしれません。
AIにおける新しい能力:私たちは神話を追いかけているのでしょうか?
大規模言語モデルの新しい性質に対する見方の変化
towardsdatascience.com
スケーリング則は、データセットに対する割り当てが実際に考えられているよりもはるかに少ない値を示している可能性があります。DeepMindはChinchillaというプロジェクトで示しましたが、パラメータをスケーリングするだけでなく、データもスケーリングする必要があります。実際、ChinchillaはGopher(70B対280Bパラメータ)よりも容量が優れていることを示しています。
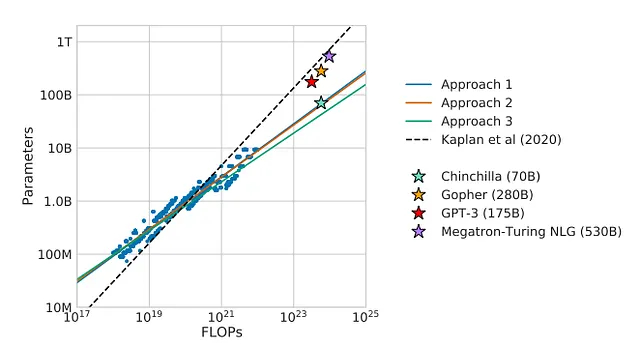
最近、機械学習コミュニティはLLaMAに興奮しています。これはオープンソースであり、パラメータが65BのバージョンがOPT 175Bよりも優れたパフォーマンスを発揮しているからです。
METAのLLaMA:巨人に打ち勝つ小さな言語モデル
METAオープンソースモデルにより、LMSのバイアスがどのようにして発生するかを理解することができます
VoAGI.com
DeepMindはChinchilla記事で述べていますが、最新の状態の良いLLMを完全にトレーニングするには、どれだけのトークンが必要かを推定することができます。一方で、高品質なトークンがどの程度存在するかを推定することもできます。最近の研究では、このトピックについて疑問が投げかけられています。以下のように結論づけました:
- 言語データセットは指数関数的に増加しており、言語データセットの出版物は年間50%のペースで増加しています(2022年末までに2e12語に達する)。これは、新しい言語データセットの研究と出版が非常に活発な分野であることを示しています。
- 一方、インターネット上の単語数(在庫単語)は増加しています(著者は7e13から7e16単語の間と推定しています、つまり1.5〜4.5桁)。
- ただし、実際に高品質の在庫単語を使用しようとするため、著者は在庫単語の品質をn 4.6e12から1.7e13単語と推定しています。著者は、2023年から2027年にかけて、品質単語の数が枯渇すると述べ、2030年から2050年にかけて在庫全体がなくなると予測しています。
- 画像の在庫もあまり良くありません(3〜4桁)
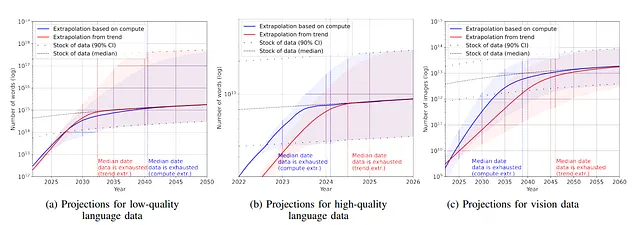
なぜこんなことが起こっているのでしょうか?
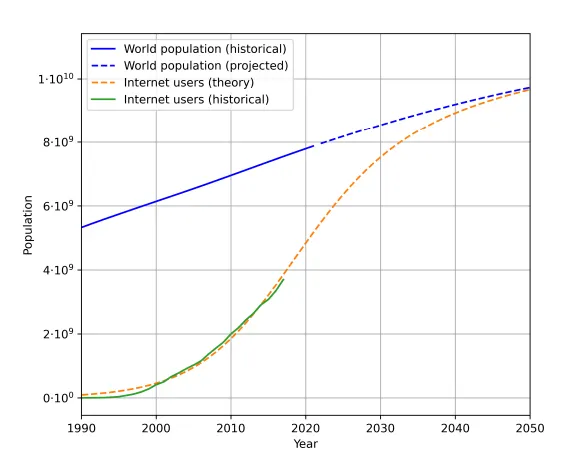
それは、私たち人間が無限ではなく、ChatGPTほどのテキストを生産しないからです。実際、インターネットユーザーの数の予測(実際と予測)は、多くを物語っています:
実際、テキスト、コード、その他のソースをトレーニングに使用することについて、誰もが喜んでいるわけではありません。実際、モデルをトレーニングするために歴史的に使用されてきたウィキペディア、Reddit、およびその他のソースは、そのデータの使用に対して企業に支払うよう求めています。これに対して、企業は公正な使用を引用しており、現在の規制環境は不明瞭です。
データを組み合わせると、トレンドが明確に見られます。LLMを最適にトレーニングするために必要なトークンの数が在庫のトークンよりも速く増加していることがわかります。
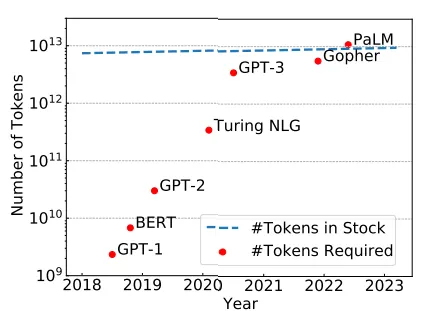
Chinchillaによって定義されたスケーリング則によると、最適なLLMトレーニングに必要なトークンの数はすでに限界を超えています。グラフから、PaLM-540 Bでこれらの推定によると、限界に達したことがわかります(在庫の9兆に対して必要な108兆のトークン)。
この問題について、一部の著者は「トークン危機」と呼んでいます。さらに、私たちはこれまで英語のトークンだけを考慮してきましたが、7,000以上の他の言語があります。ウェブ全体の56%が英語であり、残りの44%はわずか100の他の言語に属しています。そして、これは他の言語のモデルの性能に反映されています。
より多くのデータを取得できますか?
私たちは、より多くのパラメータが必ずしもより良いパフォーマンスにつながるわけではないことを見てきました。より良いパフォーマンスを得るには、品質の高いトークン(テキスト)が必要ですが、これらは不足しています。どのようにしてそれらを取得できますか?人工知能を使用して自分で手伝うことはできますか?
なぜChat-GPTを使用してテキストを生成しないのですか?
もしそうであれば、なぜ自動化しないのですか?最近の研究では、このプロセスが最適ではないことが示されています。Stanford Alpacaは、GPT-3から派生した52,000の例を使用してトレーニングされましたが、性能は同等だけであったようです。実際には、モデルはターゲットモデルのスタイルを学習しますが、その知識は学習しません。
なぜトレーニング時間を長くしないのですか?
PaLM、Gopher、LLaMA(および他のLLM)については、モデルが数エポック(1つまたはいくつか)トレーニングされたことが明確に記載されています。これは、Transformerの制限ではなく、たとえばVision Transformers(ViT)は、表に示されているように、ImageNet(100万枚の画像)で300エポックトレーニングされました。
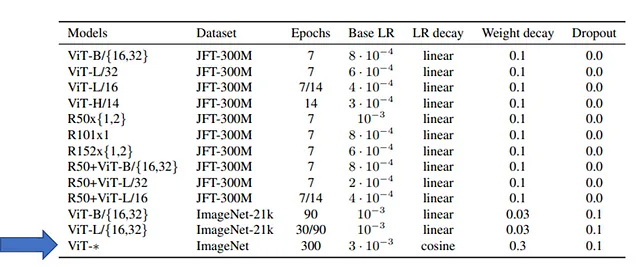
それは非常に高価すぎるからです。LLaMAの記事では、著者たちはわずか1エポック(データセットの一部については2エポック)だけトレーニングしたと報告しています。それにもかかわらず、著者たちは次のように報告しています:
65Bパラメータモデルをトレーニングする場合、私たちのコードは2048 A100 GPUで1秒あたり約380トークン/秒/GPUを処理します。つまり、1.4Tトークンを含むデータセットをトレーニングするのに約21日かかります。 (出典)
LLMのトレーニングは、数エポックでも非常に高価です。Dmytro Nikolaiev(Dimid)が計算したところによると、Google Cloud PlatformでMETAのLLaMAに似たモデルをトレーニングする場合、それは400万ドルを意味します。
そのため、他のエポックのトレーニングはコストが指数関数的に増加します。 また、この追加のトレーニングが本当に役立つのかどうかはわかりません。まだテストしていません。
最近、シンガポール大学の研究者グループが、LLMを複数のエポックにトレーニングすると何が起こるかを研究しました。
繰り返すべきか否か:Token-Crisis下でのLLMのスケーリングからの洞察
最近の研究は、言語モデルのスケーリングにおけるデータセットサイズの重要性を強調しています。ただし、大規模な言語…
arxiv.org
Repetita iuvant aut continuata secant
今までのところ、モデルのパフォーマンスは、パラメータの数だけでなく、トレーニングに使用される品質の高いトークンの数によっても決まっています。
一方、これらの品質の高いトークンは無限ではなく、限界に近づいています。 品質の高いトークンが十分になく、AIで生成するオプションがある場合、どうすればよいでしょうか?
同じトレーニングセットを使用して、トレーニングを長く行うことはできますか?
繰り返すことは有益であるというラテン語の言葉があります(repetita iuvant)が、時間が経つにつれて「しかし継続すると退屈になる」(continuata secant)と誰かが追加しました。
ニューラルネットワークについても同じことが当てはまります。エポック数を増やすと、ネットワークのパフォーマンス(損失の減少)が向上します。しかし、訓練セットの損失が減少し続ける一方で、検証セットの損失が上昇し始めると、ニューラルネットワークは過剰適合に陥り、訓練セットにのみ存在するパターンを考慮し、一般化する能力を失います。
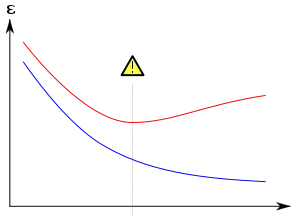
OK、小さなニューラルネットワークについてはこれが広く研究されていますが、巨大なトランスフォーマーについてはどうでしょうか?
この研究の著者たちは、C4データセット上のT5モデル(エンコーダーデコーダーモデル)を使用しました。著者たちは、モデルのサイズが大きくなると、パラメータの数が増え、より多くのトークンを受け取るようになるまで、モデルのパフォーマンスが向上することを示すまで、複数のバージョンのモデルをトレーニングしました(Chinchillaの法則による)。著者たちは、必要なトークンの数とモデルのサイズとの間に線形な関係があることを指摘しました(DeepMindがChinchillaで見たことを確認)。
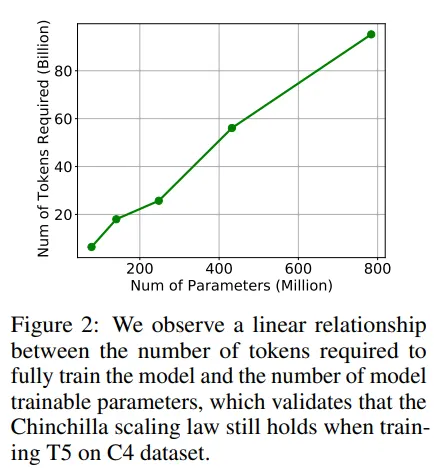
C4データセットは限られています(無限のトークンを持っていません)ので、著者たちは、トークン不足状態で何が起こるかをシミュレートすることにしました。彼らは一定数のトークンをサンプリングし、モデルがトークンのトレーニングで再びそれらを見ることになったという結果を示しました:
- 繰り返されたトークンはパフォーマンスを低下させます。
- 大きなモデルは、トークン不足の状況で過剰適合しやすくなります(理論的にはより多くの計算リソースを消費するため、パフォーマンスが低下します)。
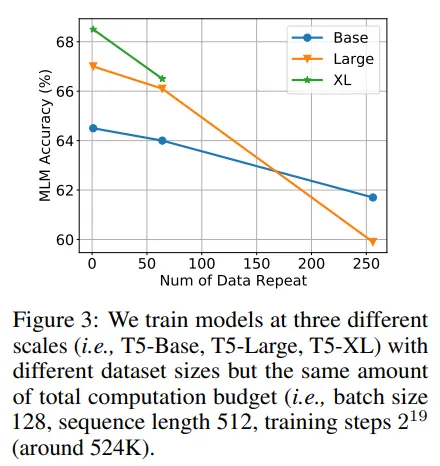
さらに、これらのモデルは下流タスクに使用されます。LLMは、大量のテキストに対して教師なしでトレーニングされ、その後下流タスクのために小さなデータセットでファインチューニングされることがよくあります。またはChatGPTの場合のように、アラインメントと呼ばれるプロセスを経る場合もあります。
LLMが繰り返しデータでトレーニングされた場合、別のデータセットでファインチューニングされたとしても、パフォーマンスが低下します。したがって、下流タスクにも影響があります。
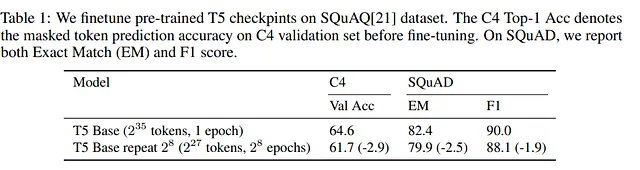
繰り返しトークンが良くない理由
繰り返しトークンがトレーニングに悪影響を与えることを見ましたが、なぜそうなるのでしょうか?
著者たちは、繰り返されるトークンの数を一定にし、データセットの総トークン数を増やすことで調査することにしました。その結果、大きなデータセットは、複数のエポックの劣化問題を緩和することがわかりました。
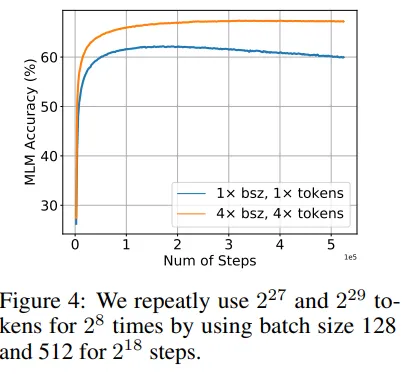
昨年、科学者を助けるはずだったGalacticaが公開されました(ただしわずか3日で終了しました)。驚異的な失敗に加えて、記事はデータの質の一部が結果に影響したと示唆しています。著者によると、データの質が高いと、繰り返しトークンを使用することで上流と下流のパフォーマンスが向上し、過学習のリスクが低下します。
繰り返されたトークンを使用することで、私たちは過学習せず、上流および下流のパフォーマンスが向上します(ソース)
著者によれば、繰り返しトークンは、モデルのトレーニングに悪影響を与えるだけでなく、下流のパフォーマンスを向上させることができます。
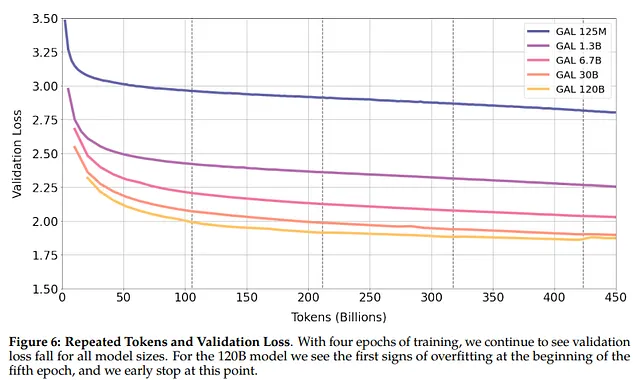
この新しい研究では、著者たちはC4よりも高品質のデータセットであるWikipediaデータセットを使用し、繰り返しトークンを追加しました。その結果、Galacticaの記事で述べられていることとは異なり、類似したレベルの劣化が見られました。

著者たちは、モデルのスケーリングも影響を与えるかどうかを調査しました。モデルをスケーリングする際には、パラメータ数と計算コストが増加します。著者たちは、これら2つの要因を個別に研究することにしました。
- Mixture-of-Experts(MoE)は、パラメータ数を増やしながら、同じ計算コストを維持するため、選択されます。
- ParamShareは、パラメータ数を減らしながら、同じ計算コストを維持するために選択されます。
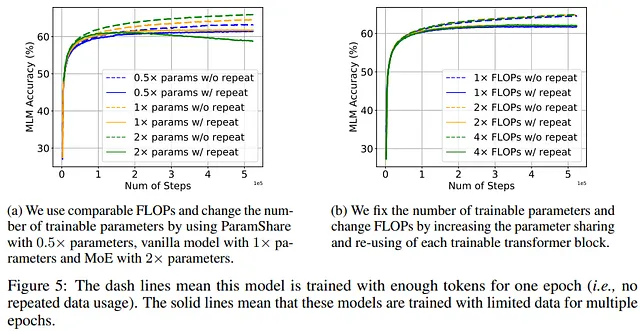
その結果、パラメータが少ないモデルは、繰り返しトークンの影響を受けにくいことがわかりました。一方、パラメータ数が多いMoEモデルは、過学習しやすい傾向があります。この結果は興味深いものであり、MoEは多くのAIモデルで成功しているため、十分なデータがある場合には有用な技術であると著者は指摘していますが、トークンが不十分な場合にはパフォーマンスに悪影響を与える可能性があると述べています。
著者たちは、トレーニング目標がパフォーマンスの劣化に影響を与えるかどうかも調査しました。一般的に、2つのトレーニング目標があります。
- 次のトークン予測(トークンのシーケンスが与えられた場合、次のトークンを予測する)。
- マスクされた言語モデリング、1つまたは複数のトークンをマスクし、予測する必要がある。
最近、GoogleはPaLM2–2とUL2を組み合わせたUL2を導入し、モデルのトレーニングを加速することが示されました。しかし、興味深いことに、UL2は過学習により影響を受けやすく、多重エポックの劣化が大きくなる傾向にあります。
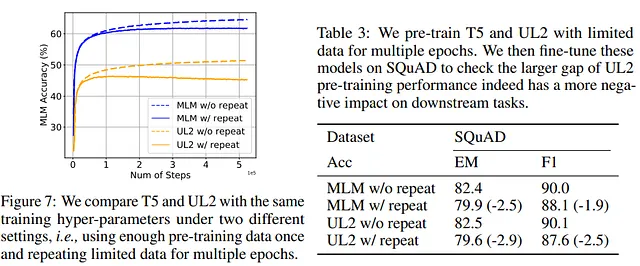
著者らは次に、多重エポックの劣化を緩和する方法を探求しました。正則化技術は過学習を防止するために使用されるため、著者らはこれらの技術がここでも有益な効果があるかどうかをテストしました。
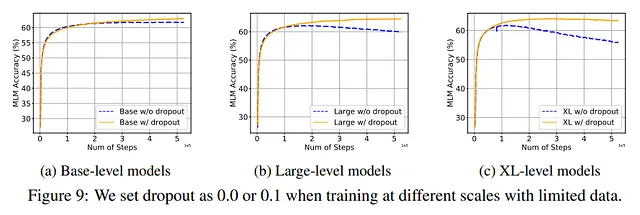
ドロップアウトは、この問題を緩和するために最も効率的な技術の1つであることが示されています。これは最も効率的な正則化技術の1つであり、ほとんどのモデルで容易に並列化して使用されているため、驚くべきことではありません。

また、著者らにとっては、ドロップアウトを開始時には使用せず、後になってからドロップアウトを追加することが最も効果的であることがわかりました。

一方、著者らは、ドロップアウトをいくつかのモデル、特に大きなモデルで使用すると、わずかな性能低下を引き起こす可能性があることに注意しています。したがって、過学習に対して有益な影響を持つかもしれないが、他の文脈では予期しない振る舞いを引き起こす可能性があるため、GPT-3、PaLM、LLaMA、Chinchilla、Gopherなどのモデルはアーキテクチャで使用しないことが多いです。
以下の表に示すように、著者らは実験にほぼ小型のモデルを使用しました。そのため、LLMを設計する際に異なるハイパーパラメータをテストするのは高価です。
たとえば、特定のシナリオでは、T5-XLを5回トレーニングするのにGoogle Cloud TPUsをレンタルすると、約37,000米ドルが必要になります。PaLMやGPT-4などのさらに大きなデータセットでトレーニングされたより大きなモデルを考慮すると、この費用は扱いにくくなります(ソース)
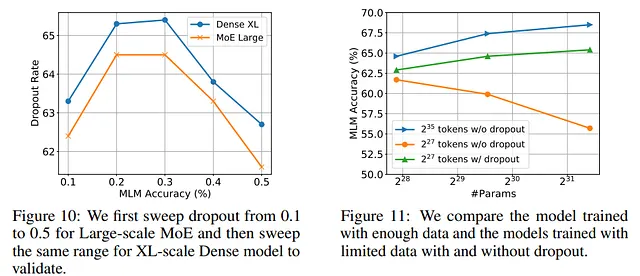
彼らの実験では、Sparse MoEモデルが密なモデルの振る舞いを近似するため(より計算コストがかかる)、最適なハイパーパラメータを探索するために使用できます。
例えば、著者らはMoEモデルの異なる学習率をテストでき、それが等価な密なモデルと同等のパフォーマンスを示すことを示しています。したがって、著者らにとっては、MoEモデルで異なるハイパーパラメータをテストし、選択されたパラメータで密なモデルをトレーニングすることができるため、コストを節約できます。
MoE Largeモデルの掃引には、Google Cloud Platformで約10.6K米ドルの費用がかかりました。一方、Dense XLモデルを1回トレーニングするだけで、7.4K米ドルが必要でした。したがって、掃引を含めた全体の開発プロセスは、直接Dense XLモデルを調整する費用の0.48倍である18K米ドルになります(ソース)
最後に
最近、最も大きなモデルを持つことに競争がありました。一方で、この競争は、あるスケールで、より小さなモデルでは予測できない性質が現れることがあったために動機づけられました。他方で、OpenAIのスケーリング則は、パフォーマンスがモデルパラメータの数の関数であるということを述べています。
過去1年間、このパラダイムは危機に陥っています。
最近、LLaMAはデータ品質の重要性を示しました。また、Chinchillaは、モデルを最適にトレーニングするために必要なトークン数を計算する新しいルールを示しました。実際、一定数のパラメータを持つモデルは、最適に機能するために一定のデータ数が必要です。
その後の研究では、品質の高いトークン数は無限ではないことが示されています。一方、モデルパラメータの数は、人間が生成できるトークン数よりも増加しています。
これにより、トークン危機をどのように解決できるかという問題が生じました。最近の研究では、LLMを使用してトークンを生成することは実行可能な方法ではないことが示されています。この新しい研究は、同じトークンを複数のエポックに使用することが実際にパフォーマンスを低下させる方法を示しています。
このような研究は重要です。LLMのトレーニングと使用がますます増えているにもかかわらず、私たちが知らない基本的な側面が多数あります。この研究では、実験データで答える著者たちの基本的な質問に答えることで、複数のエポックのLLMのトレーニングを行うと何が起こるか?という問題に答えています。
さらに、この記事は、パラメータ数の無批判な増加は不要であることを示す文献の増加する一部です。一方、ますます大きくなるモデルはより高価であり、より多くの電力を消費します。リソースを最適化する必要があるため、この記事は、十分なデータがない状態で巨大なモデルをトレーニングすることはただの浪費であると示唆しています。
この記事は、トランスフォーマーを置き換える新しいアーキテクチャが必要であることを示しています。したがって、モデルのスケールアップを継続する代わりに、新しいアイデアに研究を集中する時間が来ています。
もし興味を持っていただけた場合は:
他の記事を探すことができます。また、記事の公開時に通知を受け取るために購読することもできます。また、VoAGIメンバーになって、すべてのストーリーにアクセスできるようにすることもできます(私が収益を得られるプラットフォームのアフィリエイトリンクが含まれていますが、あなたに費用はかかりません)。また、LinkedInで私につながったり、連絡を取ったりすることもできます。
こちらは私のGitHubリポジトリへのリンクです。ここでは、機械学習、人工知能、その他に関連するコードや多くのリソースを収集する予定です。
GitHub – SalvatoreRa/tutorial: Tutorials on machine learning, artificial intelligence, data science…
Tutorials on machine learning, artificial intelligence, data science with math explanation and reusable code (in python…
github.com
また、次のいずれかの記事に興味があるかもしれません。
Scaling Isn’t Everything: How Bigger Models Fail Harder
Are Large Language Models really understanding programming languages?
salvatore-raieli.medium.com
META’S LIMA: Maria Kondo’s way for LLMs training
Less and tidy data to create a model capable to rival ChatGPT
levelup.gitconnected.com
Google Med-PaLM 2: is AI ready for medical residency?
Google’s new model achieves impressive results in the medical domain
levelup.gitconnected.com
To AI or not to AI: how to survive?
With generative AI threatening businesses and side hustles, how you can find space?
levelup.gitconnected.com
References
この記事で参照された主要な参考文献のリストです:
- Fuzhao Xue et al, 2023, To Repeat or Not To Repeat: Insights from Scaling LLM under Token-Crisis, link
- Hugo Touvron et all. 2023, LLaMA: Open and Efficient Foundation Language Models. link
- Arnav Gudibande et all, 2023, The False Promise of Imitating Proprietary LLMs. link
- PaLM 2, google blog, link
- Pathways Language Model (PaLM): Scaling to 540 Billion Parameters for Breakthrough Performance. Google Blog, link
- Buck Shlegeris et all, 2022, Language models are better than humans at next-token prediction, link
- Pablo Villalobos et. all, 2022, Will we run out of data? An analysis of the limits of scaling datasets in Machine Learning. link
- Susan Zhang et al. 2022, OPT: Open Pre-trained Transformer Language Models. link
- Jordan Hoffmann et all, 2022, An empirical analysis of compute-optimal large language model training. link
- Ross Taylor et al, 2022, Galactica: A Large Language Model for Science, link
- Zixiang Chen et al, 2022, Towards Understanding Mixture of Experts in Deep Learning, link
- Jared Kaplan et all, 2020, Scaling Laws for Neural Language Models. link
- How AI could fuel global warming, TDS, link
- Masked language modeling, HuggingFace blog, link
- Mixture-of-Experts with Expert Choice Routing, Google Blog, link
- Why Meta’s latest large language model survived only three days online, MIT review, link
- Exploring Transfer Learning with T5: the Text-To-Text Transfer Transformer, Google Blog, link
- Scaling laws for reward model overoptimization, OpenAI blog, link
- An empirical analysis of compute-optimal large language model training, DeepMind blog, link
- Xiaonan Nie et al, 2022, EvoMoE: An Evolutional Mixture-of-Experts Training Framework via Dense-To-Sparse Gate. link
- Tianyu Chen et al, 2022, Task-Specific Expert Pruning for Sparse Mixture-of-Experts, link
- Bo Li et al, 2022, Sparse Mixture-of-Experts are Domain Generalizable Learners, link
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
