時間をかけて生存者を助け、機械学習を利用して競争する
'Save survivors and compete using machine learning.'
2023年2月6日、トルコ南東部でマグニチュード7.7と7.6の地震が発生し、10の都市に影響を及ぼし、2月21日現在で4万2000人以上が死亡し、12万人以上が負傷しました。
地震の数時間後、プログラマーのグループが「アフェタリタ」と呼ばれるアプリケーションを展開するためのDiscordサーバーを立ち上げました。このアプリケーションは、捜索救助チームとボランティアが生存者を見つけて支援するために使用されます。このようなアプリの必要性は、生存者が自分の住所や必要なもの(救助を含む)をテキストのスクリーンショットとしてソーシャルメディアに投稿したことから生じました。一部の生存者は、自分が生きていることと救助を必要としていることを、ツイートで伝え、それにより親族が知ることができました。これらのツイートから情報を抽出する必要があり、私たちはこれらを構造化されたデータに変換するためのさまざまなアプリケーションを開発し、展開するために時間との競争をしました。
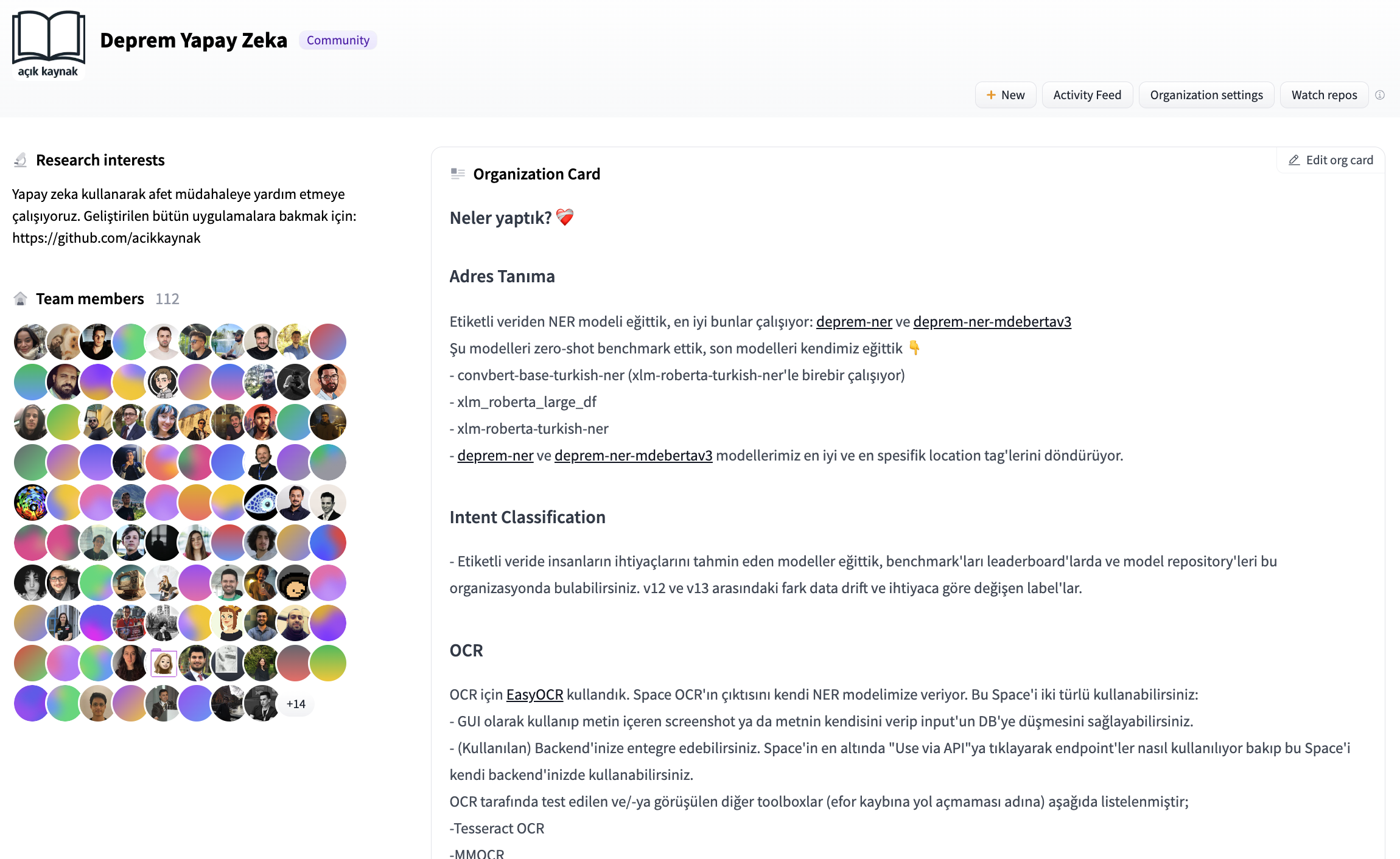
Discordサーバーに招待されたとき、私たちは(ボランティアとして)どのように運営し、何をするかについてかなりの混乱がありました。私たちは共同でモデルをトレーニングするために、モデルとデータセットのレジストリが必要でした。私たちはHugging Faceの組織アカウントを開設し、MLベースのアプリケーションを受け取り、情報を処理するためのプルリクエストを通じて共同作業しました。
- Hugging FaceとFlowerを使用したフェデレーテッドラーニング
- 大規模言語モデルの高速推論:Habana Gaudi2アクセラレータ上のBLOOMZ
- 🤗 Transformersを使用してTensorFlowとTPUで言語モデルをトレーニングする
他のチームのボランティアから、スクリーンショットを投稿し、スクリーンショットから情報を抽出し、それを構造化してデータベースに書き込むアプリケーションの需要があることを聞きました。私たちは、与えられた画像を取得し、まずテキストを抽出し、そのテキストから名前、電話番号、住所を抽出し、これらの情報を権限付与された当局に提供するデータベースに書き込むアプリケーションの開発を開始しました。さまざまなオープンソースのOCRツールを試した後、OCR部分には「easyocr」を使用し、このアプリケーションのインターフェースの構築には「Gradio」を使用しました。OCRからのテキスト出力は、トランスフォーマーベースのファインチューニングされたNERモデルを使用して解析されます。
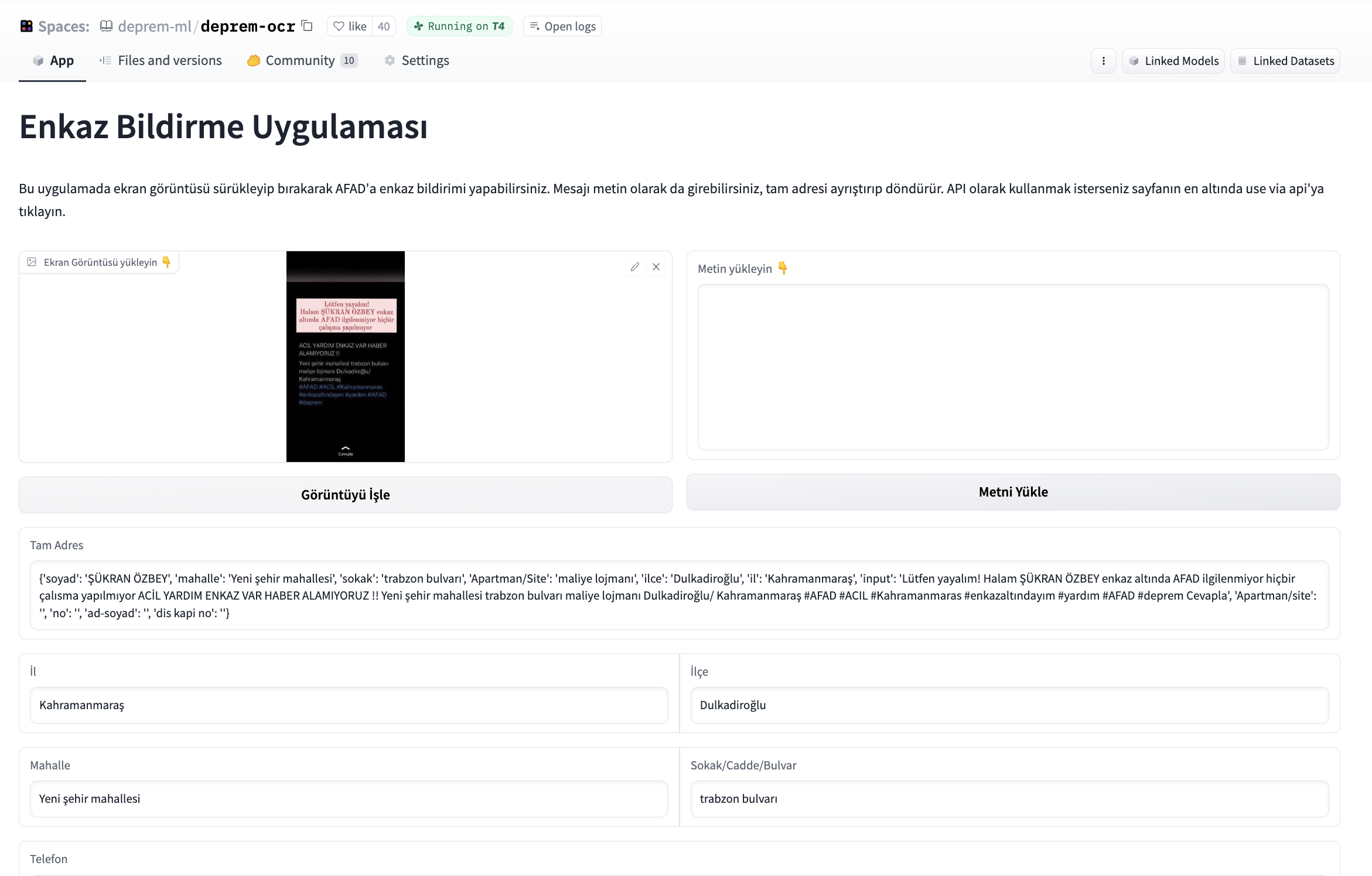
アプリケーションを共同で改善するために、Hugging Face Spacesにホストし、アプリケーションを維持するためのGPUグラントを受け取りました。Hugging Face HubチームはCIボットをセットアップしてくれたので、プルリクエストがSpaceにどのように影響を与えるかを見ることができ、プルリクエストのレビュー中に役立ちました。
その後、さまざまなチャンネル(Twitter、Discordなど)からラベル付けされたコンテンツが提供されました。これには、助けを求める生存者のツイートの生データと、それらから抽出された住所と個人情報が含まれていました。私たちは、まずはHugging Face Hub上のオープンソースのNLIモデルと、クローズドソースの生成モデルエンドポイントを使用したフューショットの実験から始めました。私たちは、xlm-roberta-large-xnliとconvbert-base-turkish-mc4-cased-allnli_trというモデルを試しました。NLIモデルは特に役立ちました。候補ラベルを使用して直接推論でき、データのドリフトが発生した際にラベルを変更できるため、生成モデルはバックエンドへの応答時にラベルを作り上げる可能性があり、不一致を引き起こす可能性がありました。最初はラベル付けされたデータがなかったので、何でも動くでしょう。
最終的に、私たちは独自のモデルを微調整することにしました。1つのGPUでBERTのテキスト分類ヘッドを微調整するのに約3分かかります。このモデルをトレーニングするためのデータセットを開発するためのラベリングの取り組みがありました。モデルカードのメタデータに実験結果を記録し、後でどのモデルを展開するかを追跡するためのリーダーボードを作成しました。ベースモデルとして、bert-base-turkish-uncasedとbert-base-turkish-128k-casedを試しましたが、bert-base-turkish-casedよりも優れたパフォーマンスを発揮することがわかりました。リーダーボードはこちらでご覧いただけます。
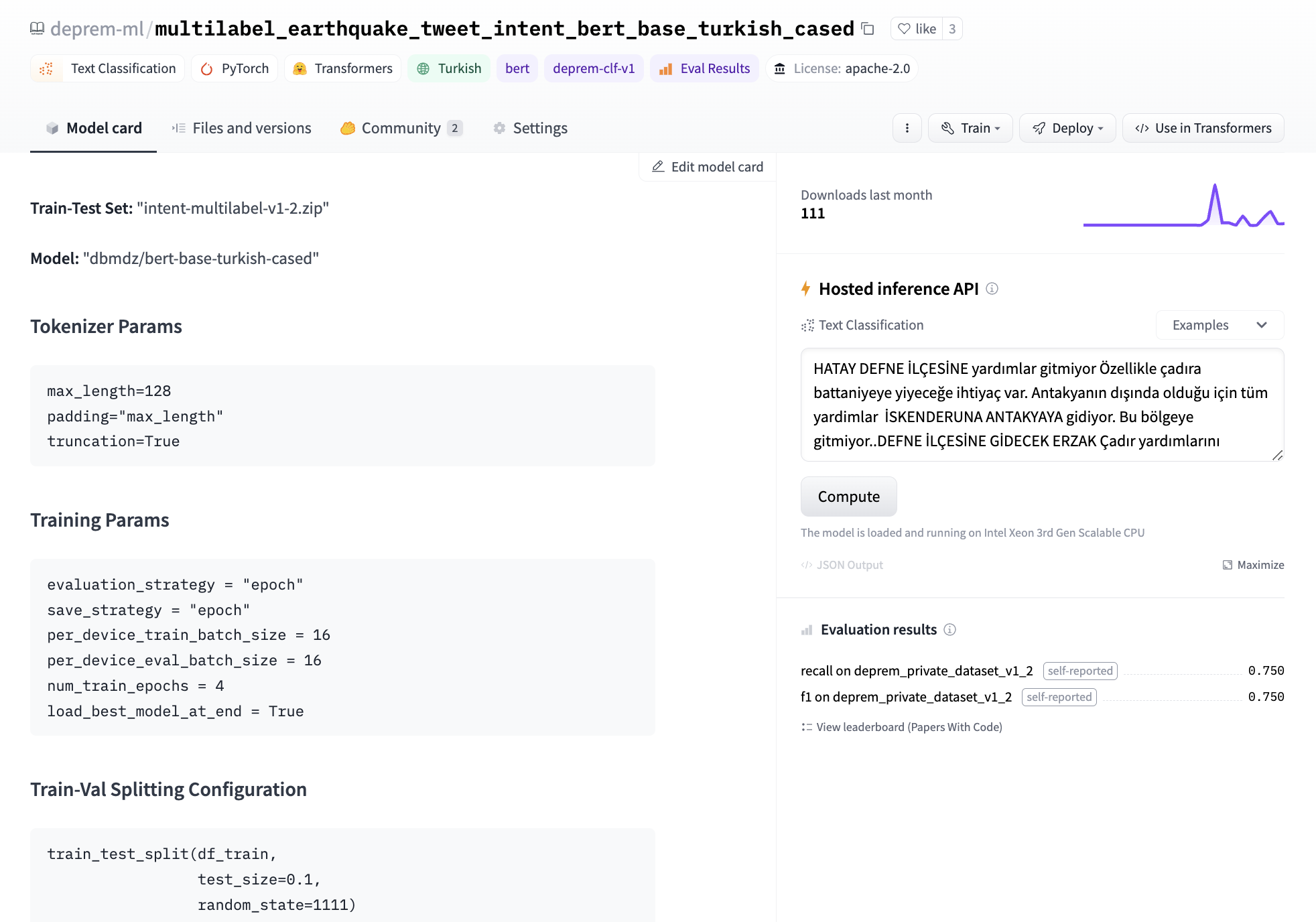
課題とデータクラスの不均衡を考慮し、偽陰性を排除することに焦点を当て、すべてのモデルの再現率とF1スコアをベンチマークするためのスペースを作成しました。これには、関連するモデルリポジトリにメタデータタグdeprem-clf-v1を追加し、このタグを使用して記録されたF1スコアと再現率を自動的に取得し、モデルをランク付けしました。漏れを防ぐために別のベンチマークセットを用意し、モデルを一貫してベンチマークしました。また、各モデルをベンチマークし、展開用の各ラベルに対して最適な閾値を特定しました。
NERモデルを評価するために、データラベラーが改善された意図データセットを提供するために取り組んでいるため、クラウドソーシングの取り組みとしてNERモデルを評価するためのラベリングインターフェースを設定しました。このインターフェースでは、ArgillaとGradioを使用して、ツイートを入力し、出力を正しい/正しくない/曖昧などのフラグで示すことができます。
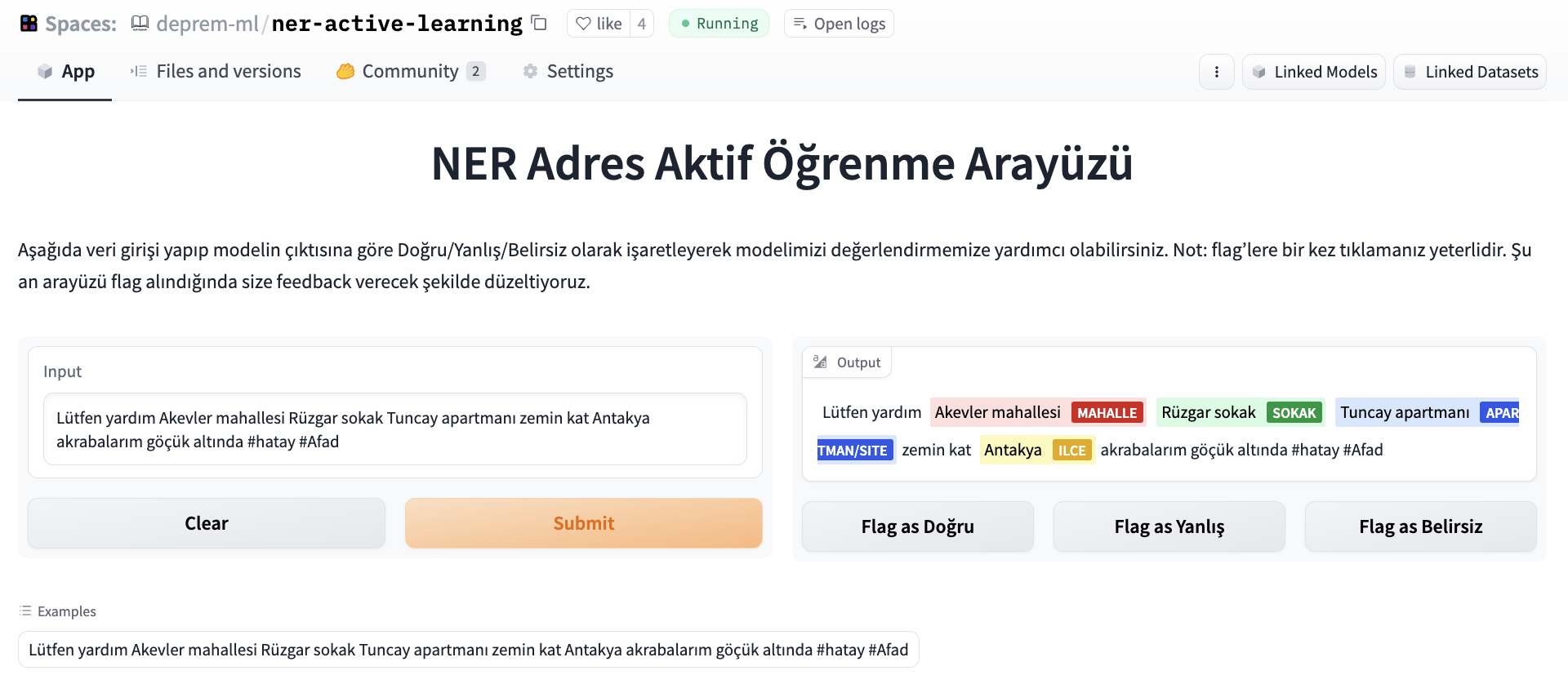
後で、データセットは重複を排除してさらなる実験のベンチマークに使用されました。
機械学習の別のチームは、特定のニーズを得るために生成モデル(ゲート付きAPIの背後)と連携し、テキストとして自由なテキストを使用し、各投稿に追加のコンテキストとしてテキストを渡すためにAPIエンドポイントを別のAPIとしてラップし、クラウドに展開しました。少数のショットのプロンプティングをLLMsと組み合わせて使用することで、急速に変化するデータのドリフトの存在下で細かいニーズに対応するのに役立ちます。調整する必要があるのはプロンプトだけであり、ラベル付けされたデータは必要ありません。
これらのモデルは現在、生存者にニーズを伝えるためにボランティアや救助チームがヒートマップ上のポイントを作成するために本番環境で使用されています。
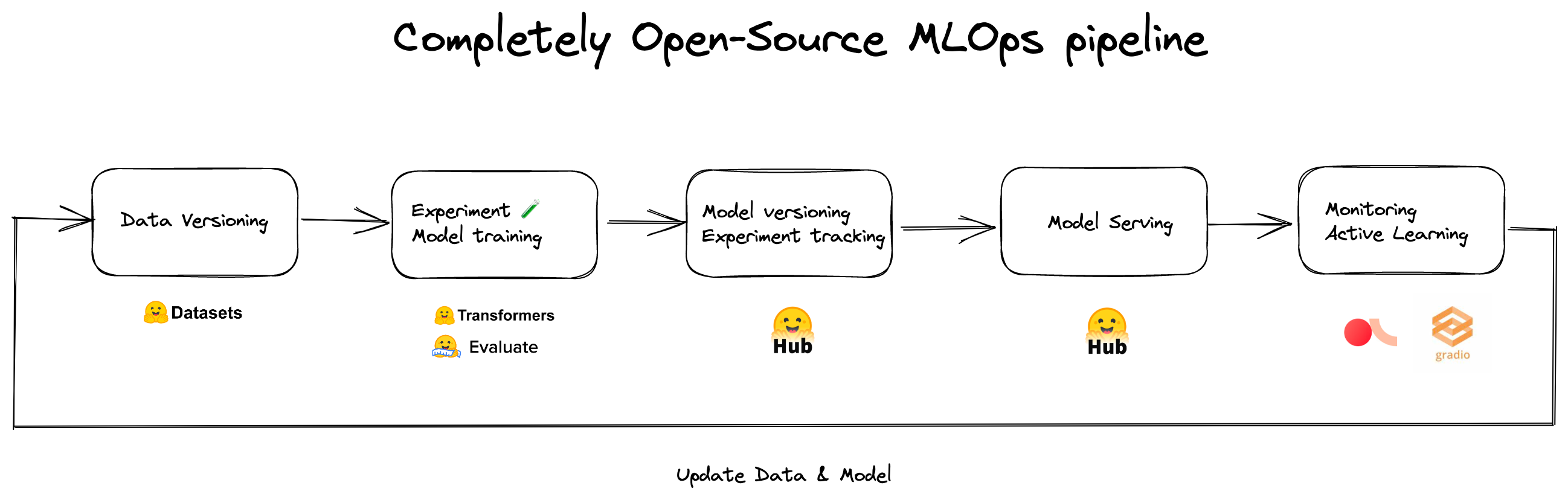
Hugging Face Hubとエコシステムがなかったら、私たちはこのように迅速に協力し、プロトタイプを作成し、展開することはできませんでした。以下は住所認識および意図分類モデルのためのMLOpsパイプラインです。
このアプリケーションとその個々のコンポーネントには何十人ものボランティアがおり、短期間でこれらを提供するために寝ずに働きました。
リモートセンシングアプリケーション
他のチームは、建物やインフラの被害を評価し、救助活動を指示するためのリモートセンシングアプリケーションに取り組みました。地震発生後の最初の48時間は電力と安定したモバイルネットワークの欠如、崩壊した道路などの影響で、被害の範囲を評価し、どこで支援が必要かを判断することが非常に困難でした。コミュニケーションと輸送の困難により、倒壊や損壊した建物の誤った報告も多くあり、救助活動にも大きな影響を与えました。
これらの問題に対処し、将来に活用できるオープンソースツールを作成するために、Planet Labs、Maxar、Copernicus Open Access Hubから被災地域の地震前後の衛星画像を収集しました。

最初のアプローチとして、オブジェクト検出とインスタンスセグメンテーションのための衛星画像を迅速にラベル付けし、”buildings”という単一のカテゴリで被害の範囲を評価しました。同じエリアから収集した地震前後の建物の数を比較することで、被害の範囲を評価することを目的としました。モデルをトレーニングしやすくするために、最初に1080×1080の衛星画像を640×640の小さなチャンクに切り取りました。次に、建物検出のためにYOLOv5、YOLOv8、EfficientNetモデルを微調整し、建物の意味セグメンテーションのためにSegFormerモデルを微調整し、これらのアプリをHugging Face Spacesとして展開しました。
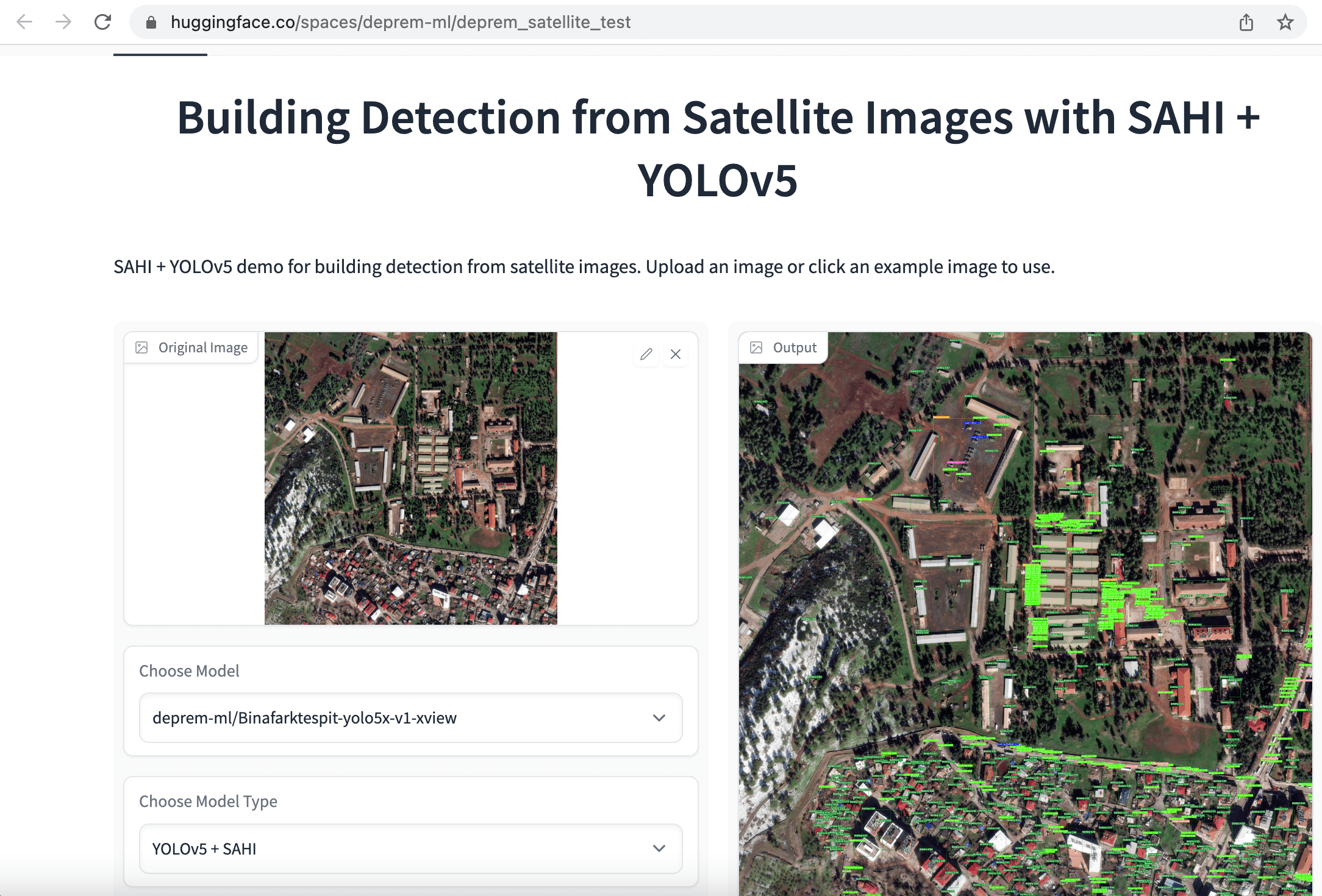
再び、数十人のボランティアがラベリング、データの準備、モデルのトレーニングに取り組みました。個々のボランティアに加えて、Co-Oneのような企業も、建物や基盤などのより詳細な注釈付きの衛星データのラベリングに協力しました。注釈には、損傷なし、破壊、損傷、損傷施設、および無傷施設のラベルが含まれます。現在の目標は、将来的に世界中の捜索・救助活動を迅速化できる包括的なオープンソースのデータセットをリリースすることです。

まとめ
この極端なユースケースでは、わずか1%の改善も重要な分類指標に対して素早く最適化する必要がありました。進行中には多くの倫理的な議論がありましたが、最適化する指標を選ぶこと自体が倫理的な問題でした。オープンソースの機械学習と民主主義化が個人が命を救うアプリケーションを構築できるようにすることを見てきました。Hugging Faceのコミュニティがこれらのモデルとデータセットをリリースしてくれたこと、そしてHugging FaceのチームがインフラストラクチャとMLOpsのサポートを提供してくれたことに感謝しています。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles





