RWKVとは、トランスフォーマーの利点を持つRNNの紹介です
RWKVは、トランスフォーマーの利点を持つRNNの紹介です
ChatGPTとチャットボットを活用したアプリケーションは、自然言語処理(NLP)の領域で注目を集めています。コミュニティは、アプリケーションやユースケースに強力で信頼性の高いオープンソースモデルを常に求めています。これらの強力なモデルの台頭は、Vaswaniらによって2017年に最初に紹介されたトランスフォーマーベースのモデルの民主化と広範な採用によるものです。これらのモデルは、それ以降のSoTA NLPモデルである再帰型ニューラルネットワーク(RNN)ベースのモデルを大幅に上回りました。このブログ投稿では、RNNとトランスフォーマーの両方の利点を組み合わせた新しいアーキテクチャであるRWKVの統合を紹介します。このアーキテクチャは最近、Hugging Face transformersライブラリに統合されました。
RWKVプロジェクトの概要
RWKVプロジェクトは、Bo Peng氏が立ち上げ、リードしています。Bo Peng氏は積極的にプロジェクトに貢献し、メンテナンスを行っています。コミュニティは、公式のdiscordチャンネルで組織されており、パフォーマンス(RWKV.cpp、量子化など)、スケーラビリティ(データセットの処理とスクレイピング)、および研究(チャットの微調整、マルチモーダルの微調整など)など、さまざまなトピックでプロジェクトの成果物を常に拡張しています。RWKVモデルのトレーニングに使用されるGPUは、Stability AIによって寄付されています。
公式のdiscordチャンネルに参加し、RWKVの基本的なアイデアについて詳しく学ぶことで、参加することができます。以下の2つのブログ投稿で詳細を確認できます:https://johanwind.github.io/2023/03/23/rwkv_overview.html / https://johanwind.github.io/2023/03/23/rwkv_details.html
トランスフォーマーアーキテクチャとRNN
RNNアーキテクチャは、データのシーケンスを処理するための最初の広く使用されているニューラルネットワークアーキテクチャの1つであり、固定サイズの入力を取る従来のアーキテクチャとは異なります。RNNは、現在の「トークン」(つまり、データストリームの現在のデータポイント)、前の「状態」を入力として受け取り、次のトークンと次の状態を予測します。新しい状態は、次のトークンの予測を計算するために使用され、以降も同様に続きます。RNNは異なる「モード」でも使用できるため、Andrej Karpathy氏のブログ投稿で示されているように、1対1(画像分類)、1対多(画像キャプション)、多対1(シーケンス分類)、多対多(シーケンス生成)など、さまざまなシナリオでRNNを適用することが可能です。
- 単一のGPUでChatgptのようなチャットボットをROCmで実行する
- より小さいほうが良いです:Xeon上で効率的な生成AI体験、Q8-Chat
- 大規模なネアデデュープリケーション:BigCodeの背後に
RNNは、各ステップで予測を計算するために同じ重みを使用するため、勾配消失の問題により長距離のシーケンスに対する情報の記憶に苦労します。この制限に対処するために、LSTMやGRUなどの新しいアーキテクチャが導入されましたが、トランスフォーマーアーキテクチャはこの問題を解決するためにこれまでで最も効果的なものとなりました。
トランスフォーマーアーキテクチャでは、入力トークンは自己注意モジュールで同時に処理されます。トークンは、クエリ、キー、値の重みを使用して異なる空間に線形にプロジェクションされます。結果の行列は、アテンションスコアを計算するために直接使用され、その後値の隠れ状態と乗算されて最終的な隠れ状態が得られます。この設計により、アーキテクチャは長距離のシーケンスの問題を効果的に緩和し、RNNモデルと比較して推論とトレーニングの速度も高速化します。
トランスフォーマーアーキテクチャは、トレーニング中に従来のRNNおよびCNNに比べていくつかの利点があります。最も重要な利点の1つは、文脈的な表現を学習できる能力です。RNNやCNNとは異なり、トランスフォーマーアーキテクチャは単語ごとではなく、入力シーケンス全体を処理します。これにより、シーケンス内の単語間の長距離の依存関係を捉えることができます。これは、言語翻訳や質問応答などのタスクに特に有用です。
推論中、RNNは速度とメモリ効率の面でいくつかの利点があります。これらの利点には、単純さ(行列-ベクトル演算のみが必要)とメモリ効率(推論中にメモリ要件が増えない)が含まれます。さらに、現在のトークンと状態にのみ作用するため、コンテキストウィンドウの長さに関係なく計算速度が同じままです。
RWKVアーキテクチャ
RWKVは、AppleのAttention Free Transformerに触発されています。アーキテクチャは注意深く簡素化され、最適化されており、RNNに変換することができます。さらに、TokenShiftやSmallInitEmbなどのトリックが追加されています(公式のGitHubリポジトリのREADMEにトリックのリストが記載されています)。これにより、モデルのパフォーマンスがGPTに匹敵するように向上しています。現在、トレーニングを14Bパラメータまでスケーリングするためのインフラストラクチャがあり、RWKV-4(本日の最新バージョン)では数値の不安定性など、いくつかの問題が反復的に修正されました。
RNNとトランスフォーマーの組み合わせとしてのRWKV
トランスフォーマーベースのモデルの主な欠点は、アテンションスコアがシーケンス全体に対して同時に計算されるため、特定の値よりも大きなコンテキストウィンドウを持つモデルを実行することが困難になることです。
RNNは非常に長いコンテキスト長をネイティブにサポートしています – トレーニングで見られるコンテキスト長に制限されるだけですが、注意深いコーディングにより数百万のトークンまで拡張することができます。現在、コンテキスト長8192(ctx8192)でトレーニングされたRWKVモデルがあり、ctx1024モデルと同じくらい速く、同じ量のRAMを必要とします。
従来のRNNモデルの主な欠点とRWKVの違い:
- 従来のRNNモデルは非常に長いコンテキストを利用することができません(LSTMはLMとして使用される場合、約100トークンしか処理できません)。しかし、RWKVは数千以上のトークンを利用することができます。以下に示すように:
- 従来のRNNモデルはトレーニング時に並列化することができません。RWKVは「線形化されたGPT」に似ており、GPTよりも高速にトレーニングできます。
これらの利点を1つのアーキテクチャに組み合わせることで、RWKVがその部分の合計以上に成長することを期待しています。
RWKVのアテンションの形成
モデルのアーキテクチャは、クラシックなトランスフォーマーベースのモデルと非常に似ています(埋め込み層、複数の同一の層、レイヤー正規化、次のトークンを予測するための因果関係言語モデリングヘッド)。唯一の違いは、アテンション層で、従来のトランスフォーマーベースのモデルとはまったく異なります。
アテンション層のより包括的な理解を得るためには、Johan Sokrates Wind氏によるブログ記事の詳しい説明を参照することをお勧めします。
既存のチェックポイント
純粋な言語モデル:RWKV-4モデル
最も採用されているRWKVモデルは、約170Mパラメータから14Bパラメータまでの範囲です。RWKVの概要ブログ記事によれば、これらのモデルはPileデータセットでトレーニングされ、異なるベンチマークで他のSoTAモデルと評価されており、非常に比較可能な結果を示しています。
インストラクションファインチューン/チャットバージョン:RWKV-4 Raven
BoはRWKVアーキテクチャの「チャット」バージョンであるRWKV-4 Ravenモデルもトレーニングしました。これはRWKV-4パイル(The Pileデータセットで事前トレーニングされたRWKVモデル)モデルであり、ALPACA、CodeAlpaca、Guanaco、GPT4All、ShareGPTなどでファインチューニングされています。モデルは複数のバージョンで利用可能で、異なる言語(英語のみ、英語+中国語+日本語、英語+日本語など)と異なるサイズ(1.5Bパラメータ、7Bパラメータ、14Bパラメータ)でトレーニングされています。
すべてのHF変換モデルは、RWKV組織でHugging Face Hubで利用できます。
🤗 Transformersの統合
このアーキテクチャは、このPull Requestのおかげでtransformersライブラリに追加されました。執筆時点では、ソースからtransformersをインストールするか、ライブラリのmainブランチを使用して使用することができます。アーキテクチャはライブラリと緊密に統合されており、他のアーキテクチャと同様に使用することができます。
以下の例を見てみましょう。
テキスト生成の例
入力プロンプトからテキストを生成するには、pipelineを使用してテキストを生成できます:
from transformers import pipeline
model_id = "RWKV/rwkv-4-169m-pile"
prompt = "\nIn a shocking finding, scientist discovered a herd of dragons living in a remote, previously unexplored valley, in Tibet. Even more surprising to the researchers was the fact that the dragons spoke perfect Chinese."
pipe = pipeline("text-generation", model=model_id)
print(pipe(prompt, max_new_tokens=20))
>>> [{'generated_text': '\nIn a shocking finding, scientist discovered a herd of dragons living in a remote, previously unexplored valley, in Tibet. Even more surprising to the researchers was the fact that the dragons spoke perfect Chinese.\n\nThe researchers found that the dragons were able to communicate with each other, and that they were'}]または、以下のスニペットから実行して開始することもできます:
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
model = AutoModelForCausalLM.from_pretrained("RWKV/rwkv-4-169m-pile")
tokenizer = AutoTokenizer.from_pretrained("RWKV/rwkv-4-169m-pile")
prompt = "\nChōdō no kiken na kentō de, kagakusha wa Tibētosan no motō no, mada tanken sarete inai tani ni, doragon no shōrō ga aru no o hakken shimashita. Kenkyūsha ni wa, doragon ga kanpeki na chūgokugo o hanasu to iu koto wa, mottō odoroku mono deshita."
inputs = tokenizer(prompt, return_tensors="pt")
output = model.generate(inputs["input_ids"], max_new_tokens=20)
print(tokenizer.decode(output[0].tolist()))
>>> Chōdō no kiken na kentō de, kagakusha wa Tibētosan no motō no, mada tanken sarete inai tani ni, doragon no shōrō ga aru no o hakken shimashita. Kenkyūsha ni wa, doragon ga kanpeki na chūgokugo o hanasu to iu koto wa, mottō odoroku mono deshita.\n\nKenkyūsha wa, doragon ga otagai to tsunagatte iru koto, soshite sore gaレイヴンモデル(チャットモデル)を使用する
アルパカスタイルでチャットモデルにプロンプトを与えることができます。以下に例を示します:
from transformers import AutoTokenizer, AutoModelForCausalLM
model_id = "RWKV/rwkv-raven-1b5"
model = AutoModelForCausalLM.from_pretrained(model_id).to(0)
tokenizer = AutoTokenizer.from_pretrained(model_id)
question = "レイヴンについて教えてください"
prompt = f"### Instruction: {question}\n### Response:"
inputs = tokenizer(prompt, return_tensors="pt").to(0)
output = model.generate(inputs["input_ids"], max_new_tokens=100)
print(tokenizer.decode(output[0].tolist(), skip_special_tokens=True))
>>> ### Instruction: レイヴンについて教えてください
### Response: レイヴンは、中東や北アフリカに生息する鳥の一種です。彼らは知能、適応性、さまざまな環境で生きる能力で知られています。レイヴンは知能、適応性、さまざまな環境で生きる能力で知られています。彼らは知能、適応性、さまざまな環境で生きる能力で知られています。Boによると、より良い指示技術については、このdiscordメッセージに詳細が記載されています(クリックする前にチャンネルに参加してください)
| 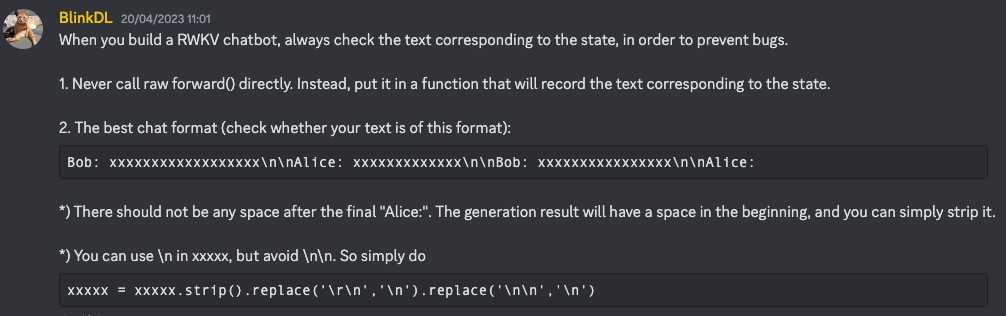 |
|
重みの変換
どのユーザーでも、単にtransformersライブラリで提供されている変換スクリプトを実行することで、元のRWKVの重みをHF形式に簡単に変換できます。まず、”raw”の重みをHugging Face Hubにプッシュします(そのリポジトリをRAW_HUB_REPO、rawファイルをRAW_FILEとします)、次に変換スクリプトを実行します:
python convert_rwkv_checkpoint_to_hf.py --repo_id RAW_HUB_REPO --checkpoint_file RAW_FILE --output_dir OUTPUT_DIR変換したモデルをHubにプッシュしたい場合(たとえば、dummy_user/converted-rwkvという名前で)、モデルをプッシュする前にhuggingface-cli loginでログインするのを忘れずに、次のコマンドを実行します:
python convert_rwkv_checkpoint_to_hf.py --repo_id RAW_HUB_REPO --checkpoint_file RAW_FILE --output_dir OUTPUT_DIR --push_to_hub --model_name dummy_user/converted-rwkv今後の課題
マルチリンガルRWKV
Boは現在、マルチリンガルコーパスを使用してRWKVモデルをトレーニングしています。最近、新しいマルチリンガルトークナイザーがリリースされました。
コミュニティ指向および研究プロジェクト
RWKVコミュニティは非常に活発で、いくつかの追加の方向性に取り組んでいます。クールなプロジェクトのリストは、discordの専用チャンネルで見つけることができます(クリックする前にチャンネルに参加してください)。また、このアーキテクチャに関する研究に専念したチャンネルもありますので、ぜひ参加して貢献してください。
モデルの圧縮と高速化
行列-ベクトル演算のみが必要なため、RWKVはフォトニックプロセッサ/アクセラレータなどの非標準的で実験的なコンピューティングハードウェアにとって理想的な候補です。
そのため、このアーキテクチャは、ONNX、4ビット/8ビットの量子化などのクラシックなアクセラレーションと圧縮技術(など)からも自然に利益を得ることができ、我々はこのアーキテクチャのtransformersの統合とともに、これが開発者や実践者にとっても民主化されることを望んでいます。
RWKVはまた、optimumライブラリによって提案されたアクセラレーション技術からも近い将来利益を得ることができます。これらの技術の一部は、rwkv.cppリポジトリやrwkv-cpp-cudaリポジトリで紹介されています。
謝辞
Hugging Faceチームは、BoとRWKVコミュニティに感謝の意を表明し、アーキテクチャに関する質問に対して私たちの時間と回答をいただいたことに感謝します。また、彼らの助けとサポートに感謝し、HFエコシステムでのRWKVモデルの採用がさらに進むことを楽しみにしています。また、Johan Wind氏のRWKVに関するブログ投稿の作業にも感謝の意を表します。これは、アーキテクチャとその潜在能力を理解するのに非常に役立ちました。最後に、最初のtransformers PRの作業を再開したArEnScの作業にも感謝と謝意を表します。また、このブログ投稿をより良くするために、Merve Noyan氏、Maria Khalusova氏、Pedro Cuenca氏にも大きな賞賛と感謝の意を表します!
引用
あなたの作業でRWKVを使用する場合は、以下のcff引用を使用してください。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- Instruction-tuning Stable Diffusion with InstructPix2PixのHTMLを日本語に翻訳してください
- 🐶セーフテンソルは、本当に安全であり、デフォルトの選択肢として採用されました
- Hugging FaceとIBMは、AIビルダー向けの次世代エンタープライズスタジオであるwatsonx.aiにおいてパートナーシップを結成しました
- bitsandbytes、4ビットの量子化、そしてQLoRAを使用して、LLMをさらに利用しやすくする
- Intel CPUのNNCFと🤗 Optimumを使用した安定したディフュージョンの最適化
- オープンソースAIゲームジャムを発表します 🎮
- AI音声認識をUnityで






