「Rodinに会ってください:さまざまな入力ソースから3Dデジタルアバターを生成する革新的な人工知能(AI)フレームワーク」
Rodin Innovative AI framework for generating 3D digital avatars from various input sources


生成モデルは、コンピュータサイエンスの多くの困難なタスクに対する事実上の解決策となっています。それらは視覚データの分析と合成のための最も有望な方法の一つを表しています。Stable Diffusionは、複雑な入力プロンプトから美しいリアルな画像を生成するための最もよく知られた生成モデルです。このアーキテクチャはDiffusion Models(DMs)に基づいており、画像と動画に対して驚異的な生成力を示しています。拡散と生成モデリングの急速な進歩が、2Dコンテンツの創造において革命を起こしています。その鍵となる言葉は非常にシンプルです。「それを説明できるなら、それを視覚化できる」ということです。または、さらに良いと言えば、「それを説明できるなら、モデルがそれを描くことができる」ということです。本当に信じられないほど、生成モデルが何ができるかです。
2DコンテンツはDMsにとってストレステストとなることが示されていますが、3Dコンテンツは追加の次元によると限定されないさまざまな課題をもたらします。アバターなどの3Dコンテンツを2Dコンテンツと同じ品質で生成することは、高品質のアバターに必要な豊富な詳細を生成するためのメモリと処理コストが制約となるため、困難な課題です。
技術が映画、ゲーム、メタバース、そして3D産業でデジタルアバターの使用を推進する中、誰でもデジタルアバターを作成できるようにすることは有益です。それがこの研究の進展を促している動機です。
- 「デバイス内AIの強化 QualcommとMetaがLlama 2テクノロジーと共同開発」
- マイクロソフトが「TypeChat」をリリース:型を使用して自然言語インターフェースを簡単に構築できるAIライブラリ
- 「テキストゥアをご紹介します:3Dメッシュのテキストゥアリングのための新しい人工知能(AI)フレームワーク」
著者たちは、デジタルアバターの作成の問題に対処するために、Roll-out diffusion network(Rodin)を提案しています。モデルの概要は、以下の図に示されています。
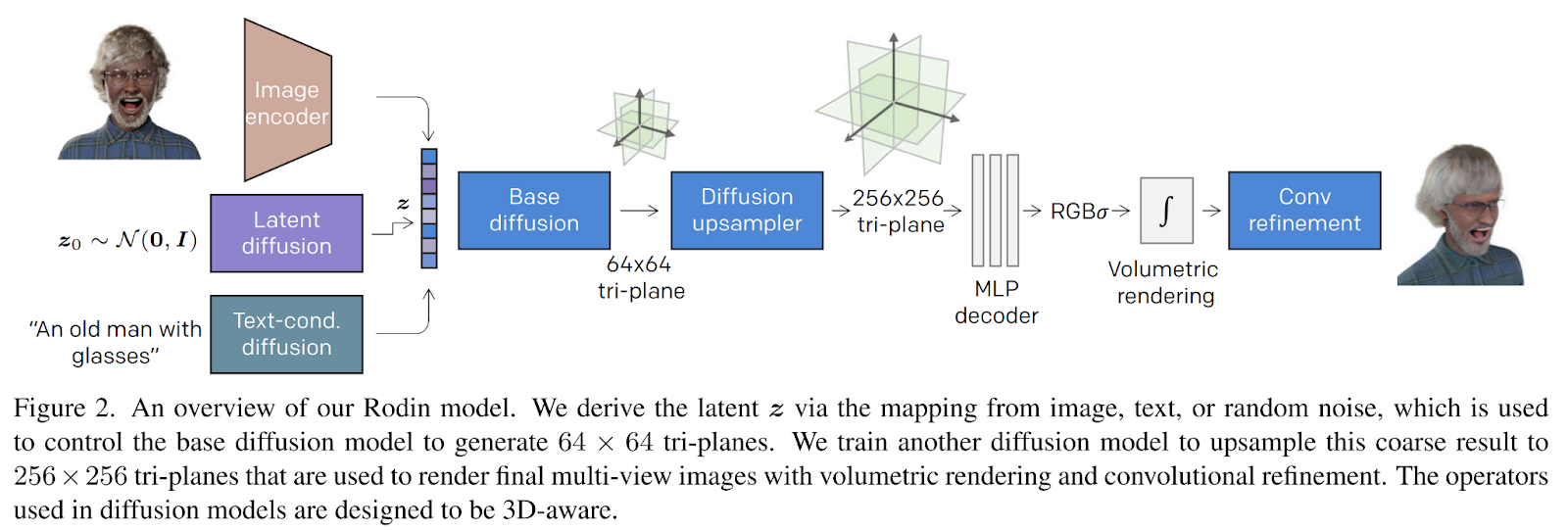

モデルへの入力は画像、ランダムノイズ、または望ましいアバターのテキストの説明であることができます。次に、与えられた入力から潜在ベクトルzが導かれ、拡散に使用されます。拡散プロセスは、いくつかのノイズ除去ステップから成り立っています。最初に、ランダムノイズが初期状態または画像に追加され、より鮮明な画像が得られるようにノイズが除去されます。
ここでの違いは、望ましいコンテンツの3D性質にあります。拡散プロセスは通常通り実行されますが、2D画像を対象とする代わりに、拡散モデルはアバターの粗いジオメトリを生成し、詳細合成のための拡散アップサンプラーを生成します。
計算およびメモリの効率性は、この研究の目標の一つです。このため、著者たちはニューラル輝度場の三軸(三軸)表現を利用しました。この表現は、ボクセルグリッドと比較して、記憶フットプリントをかなり小さくすることができるため、表現力を犠牲にすることなく効率性を高めることができます。
次に、別の拡散モデルが訓練され、生成された三面体プレーン表現を望ましい解像度にアップサンプリングします。最後に、4つの完全接続層から構成される軽量なMLPデコーダを利用して、RGBの体積画像を生成します。
以下にいくつかの結果を報告します。

先述の最先端の手法と比較して、Rodinは最も鮮明なデジタルアバターを提供します。モデルでは、他の手法とは異なり、共有されたサンプルにはアーティファクトが見られません。
これは、さまざまな入力ソースから簡単に3Dデジタルアバターを生成するための新しいフレームワークであるRodinの概要でした。興味がある場合は、以下のリンクで詳細情報を見つけることができます。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- 「Amazon Transcribe Toxicity Detectionを使用して、会話中の有害な言語をフラグ付けします」
- 「AWSは、人工知能、機械学習、生成AIのガイドを提供しており、AI戦略を計画するための新しい情報を提供しています」
- 「グラフ注意ネットワーク論文のイラストとPyTorchによる実装の説明」
- 「AIの力を解き放つ – VoAGIとMachine Learning Masteryによる特別リリース」
- 「DreamPose」というAIフレームワークを使用して、ファッション画像を見事な写真のようなビデオに変換します
- 遺伝的アルゴリズムを使用したPythonによるTV番組スケジューリングの最適化
- 「MACTAに会いましょう:キャッシュタイミング攻撃と検出のためのオープンソースのマルチエージェント強化学習手法」





