単一のGPUでChatgptのようなチャットボットをROCmで実行する
'ROCmを使用して、単一のGPUでChatGPTのようなチャットボットを実行する'
はじめに
ChatGPTは、OpenAIの画期的な言語モデルであり、人工知能の領域で影響力のある存在となり、様々なセクターでAIアプリケーションの多様な活用を可能にしています。その驚異的な人間のようなテキストの理解力と生成力により、ChatGPTは顧客サポートから創造的な文章作成まで、さまざまな産業を変革し、貴重な研究ツールとしても使われています。
OPT、LLAMA、Alpaca、Vicunaなど、大規模な言語モデルのオープンソース化にはさまざまな取り組みが行われていますが、その中でもVicunaはAMD GPU上でROCmを使用してVicuna 13Bモデルを実行する方法を説明します。
Vicunaとは何ですか?
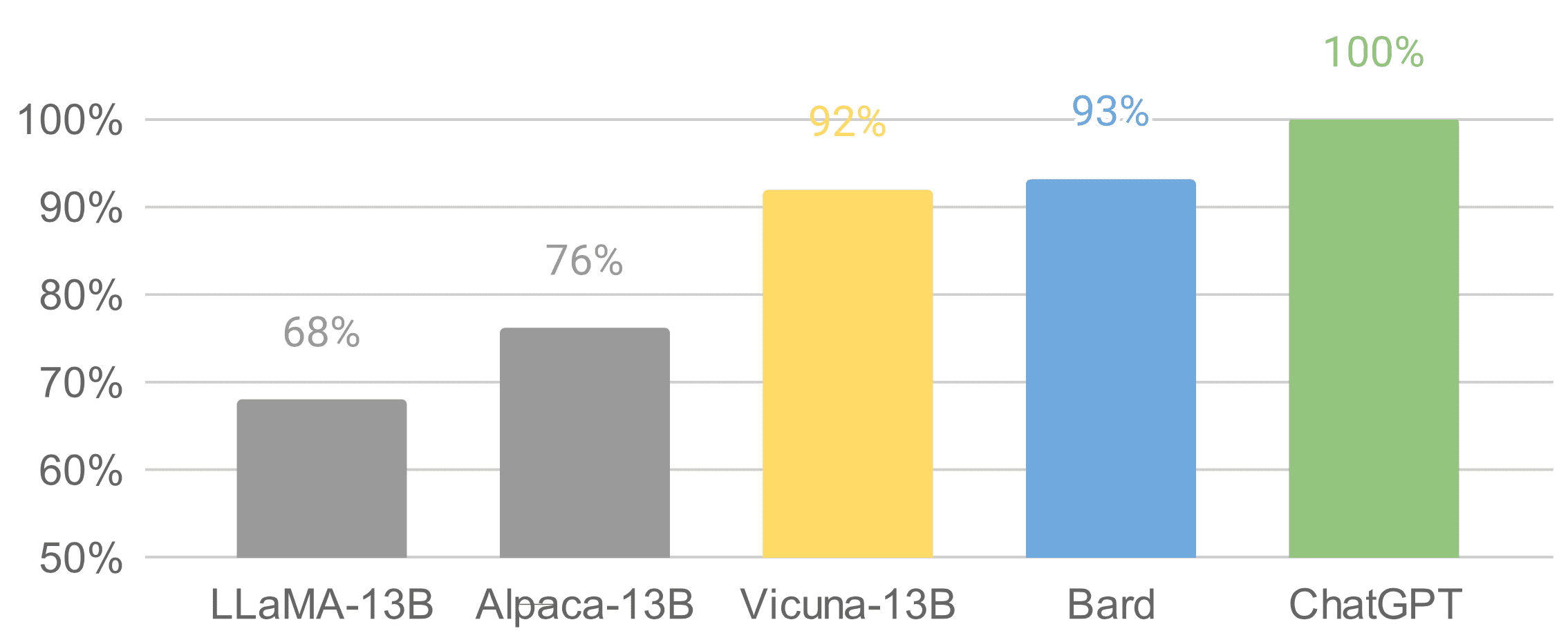
Vicunaは、UCバークレー、CMU、スタンフォード、UCサンディエゴのチームによって開発された13兆パラメータを持つオープンソースのチャットボットです。Vicunaは、LLAMAベースモデルを使用して、ShareGPT.comからの約70,000件のユーザー共有会話を収集し、公開APIを介してファインチューニングしました。GPT-4を参照とした初期の評価では、Vicuna-13BはOpenAI ChatGPTと比較して90%以上の品質を実現しています。
- より小さいほうが良いです:Xeon上で効率的な生成AI体験、Q8-Chat
- 大規模なネアデデュープリケーション:BigCodeの背後に
- Instruction-tuning Stable Diffusion with InstructPix2PixのHTMLを日本語に翻訳してください
それはわずか数週間前の4月11日にGithubでリリースされました。Vicunaのデータセット、トレーニングコード、評価メトリック、トレーニングコストはすべて公開されており、一般のユーザーにとって費用対効果の高いソリューションとなっています。
Vicunaの詳細については、https://vicuna.lmsys.org をご覧ください。
なぜ量子化されたGPTモデルが必要なのですか?
Vicuna-13Bモデルをfp16で実行するには、約28GBのGPU RAMが必要です。メモリの使用量をさらに減らすためには、最適化技術が必要です。最近発表された研究論文「GPTQ」では、低ビット精度を持つGPTモデルの正確な事後トレーニング量子化が提案されています。以下の図に示すように、パラメータが10Bを超えるモデルの場合、4ビットまたは3ビットのGPTQはfp16と同等の精度を実現することができます。
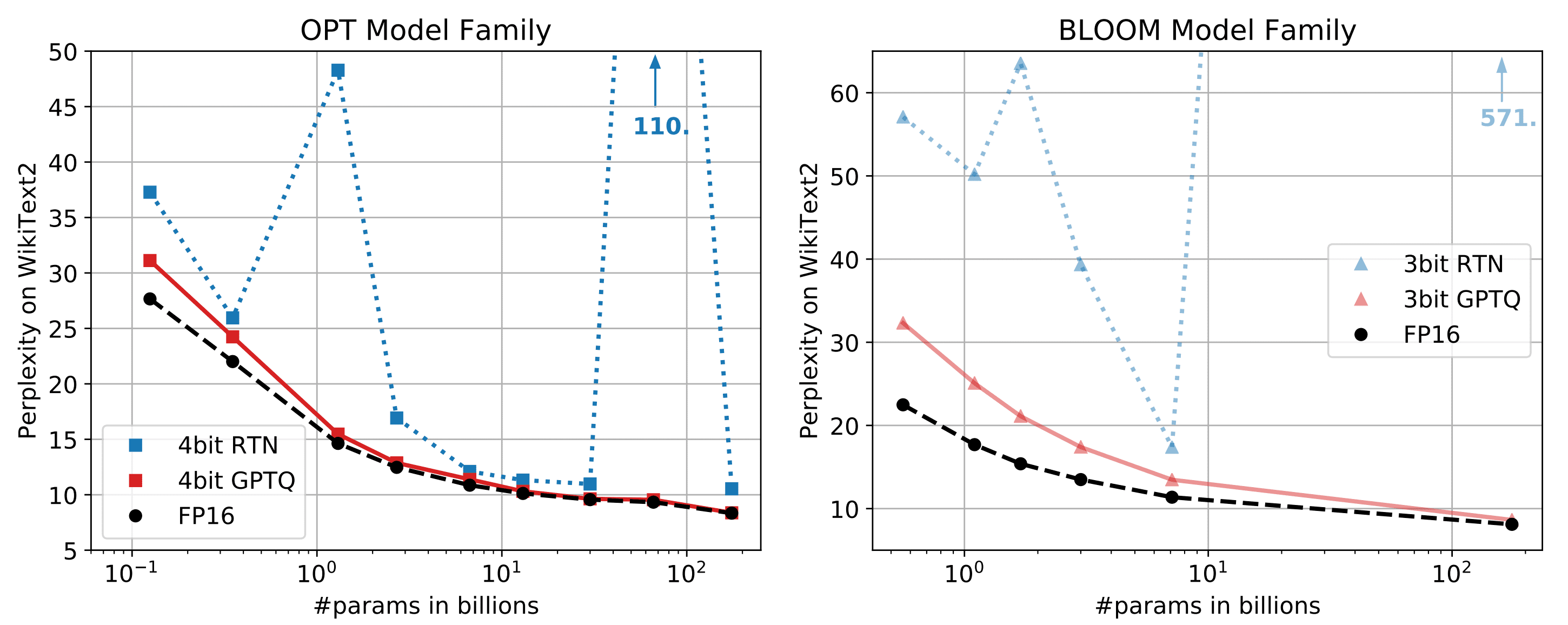
さらに、これらのモデルの大きなパラメータは、GPTトークン生成が計算(TFLOPsまたはTOPs)そのものよりもメモリ帯域幅(GB/s)によって制約されるため、GPTのレイテンシに深刻な影響を与えます。そのため、メモリに制約のある状況下では、量子化モデルはトークン生成のレイテンシを低下させません。GPTQの量子化の論文とGitHubリポジトリを参照してください。
この技術を活用することで、Hugging Faceからいくつかの4ビット量子化されたVicunaモデルが利用可能です。
ROCmを使用してAMD GPUでVicuna 13Bモデルを実行する
AMD GPUでVicuna 13Bモデルを実行するには、AMD GPUの高速化のためのオープンソースソフトウェアプラットフォームであるROCm(Radeon Open Compute)のパワーを活用する必要があります。
以下は、AMD GPUとROCmを使用してVicuna 13Bモデルを設定および実行する手順の詳細なガイドです:
システム要件
インストールプロセスに入る前に、システムが以下の要件を満たしていることを確認してください:
-
ROCmをサポートするAMD GPU(docs.amd.comの互換性リストを確認してください)
-
Ubuntu 18.04または20.04などのLinuxベースのオペレーティングシステム
-
CondaまたはDocker環境
-
Python 3.6以上
詳細については、https://docs.amd.com/bundle/ROCm-Installation-Guide-v5.4.3/page/Prerequisites.html をご覧ください。
この例は、ROCm5.4.3とPytorch2.0を使用したInstinct MI210とRadeon RX6900XTのGPUでテストされています。
クイックスタート
1 ROCmのインストールとDockerコンテナのセットアップ(ホストマシン)
1.1 ROCmのインストール
以下はROCm5.4.3とUbuntu 22.04用です。対象のROCmとUbuntuバージョンに応じて修正してください。: https://docs.amd.com/bundle/ROCm-Installation-Guide-v5.4.3/page/How_to_Install_ROCm.html
sudo apt update && sudo apt upgrade -y
wget https://repo.radeon.com/amdgpu-install/5.4.3/ubuntu/jammy/amdgpu-install_5.4.50403-1_all.deb
sudo apt-get install ./amdgpu-install_5.4.50403-1_all.deb
sudo amdgpu-install --usecase=hiplibsdk,rocm,dkms
sudo amdgpu-install --list-usecase
sudo reboot1.2 ROCmのインストールの確認
rocm-smi
sudo rocminfo1.3 DockerイメージのプルとDockerコンテナの実行
以下はROCm5.4.2でPytorch2.0を使用しています。対象のROCmとPytorchバージョンに応じて適切なDockerイメージを使用してください。: https://hub.docker.com/r/rocm/pytorch/tags
docker pull rocm/pytorch:rocm5.4.2_ubuntu20.04_py3.8_pytorch_2.0.0_preview
sudo docker run --device=/dev/kfd --device=/dev/dri --group-add video \
--shm-size=8g --cap-add=SYS_PTRACE --security-opt seccomp=unconfined \
--ipc=host -it --name vicuna_test -v ${PWD}:/workspace -e USER=${USER} \
rocm/pytorch:rocm5.4.2_ubuntu20.04_py3.8_pytorch_2.0.0_preview2 モデルの量子化とモデルの推論(Docker内部)
ハグインフォースから量子化されたVicuna-13bモデルをダウンロードするか、浮動小数点モデルを量子化することができます。浮動小数点モデルを量子化したい場合は、付録-GPTQモデルの量子化をご覧ください。
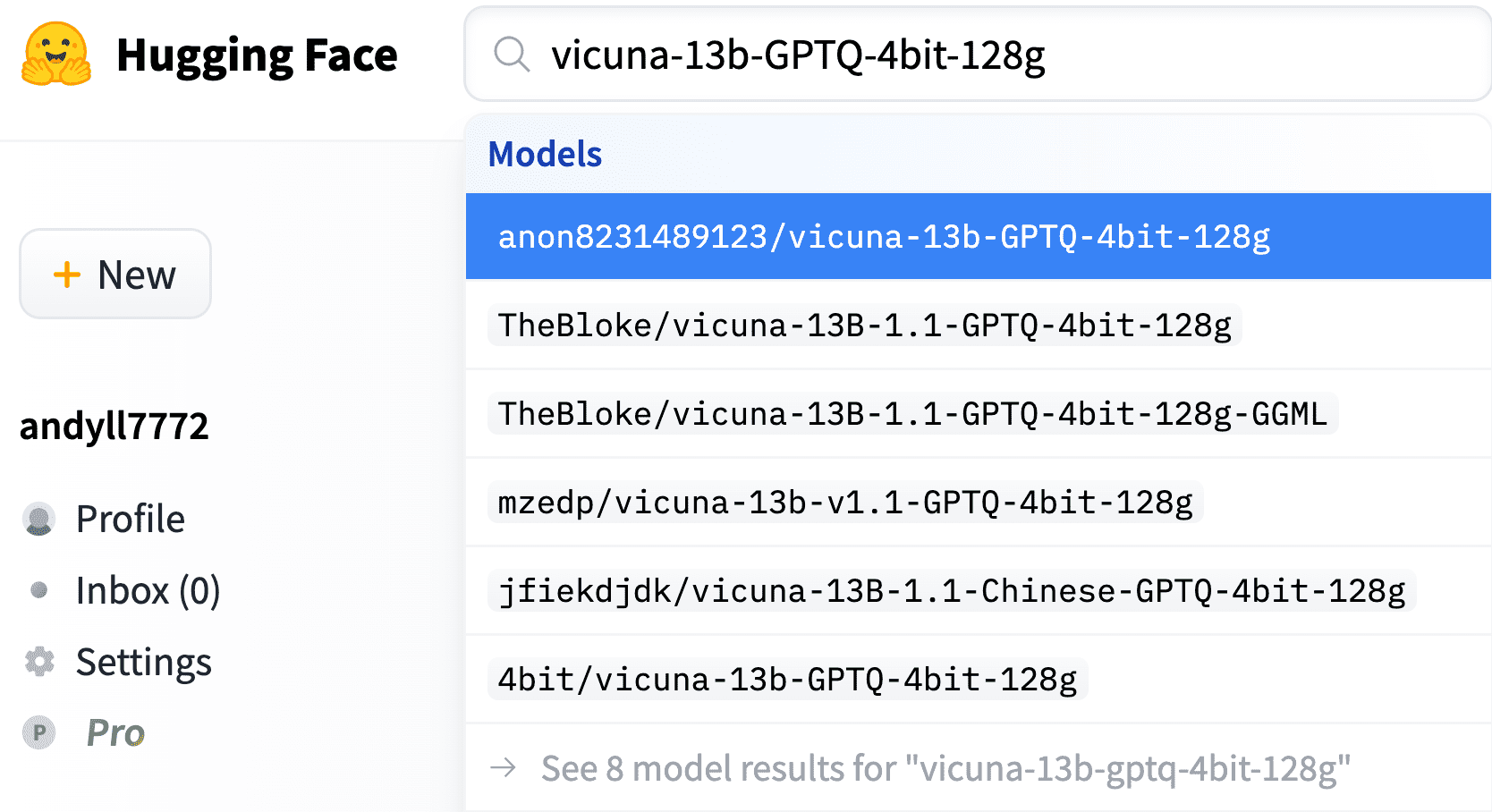
2.1 量子化されたVicuna-13bモデルのダウンロード
以下のgitリポジトリからdownload-model.pyスクリプトを使用します。
git clone https://github.com/oobabooga/text-generation-webui.git
cd text-generation-webui
python download-model.py anon8231489123/vicuna-13b-GPTQ-4bit-128g- AMD GPU上でVicuna 13B GPTQモデルを実行する
git clone https://github.com/oobabooga/GPTQ-for-LLaMa.git -b cuda
cd GPTQ-for-LLaMa
python setup_cuda.py installこれらのコマンドは、HIPIFIED CUDA等価のカーネルバイナリをコンパイルおよびリンクし、
PythonにC拡張として追加します。この実装のカーネルは、デクォンタイゼーション+FP32 Matmulで構成されています。追加の高速化のためにデクォンタイゼーション+FP16 Matmulを使用したい場合は、付録-GPTQデクォンタイゼーション+FP16 Mamulカーネル for AMD GPUsをご覧ください。
git clone https://github.com/oobabooga/GPTQ-for-LLaMa.git -b cuda
cd GPTQ-for-LLaMa/
python setup_cuda.py install
# モデルの推論
python llama_inference.py ../../models/vicuna-13b --wbits 4 --load \
../../models/vicuna-13b/vicuna-13b_4_actorder.safetensors --groupsize 128 --text “ここに入力テキストを入力”セットアップが完了したら、AMD GPU上でVicuna 13Bモデルを実行する準備が整いました。上記のコマンドを使用してモデルを実行します。入力テキストに使用するテキストで “ここに入力テキストを入力” を置き換えてください。正しくセットアップされていれば、モデルが入力に基づいて出力テキストを生成するのを確認できます。
3. Web APIサーバーに量子化されたVicunaモデルを公開する
次の行で、GPTQのPythonモジュール(GPTQ-for-LLaMa)のパスを変更します:
https://github.com/thisserand/FastChat/blob/4a57c928a906705404eae06f7a44b4da45828487/fastchat/serve/load_gptq_model.py#L7
gradioライブラリからWeb UXUIを起動するには、コントローラー、ワーカー(Vicunaモデルのワーカー)、Webサーバーをバックグラウンドジョブとして実行する必要があります。
nohup python0 -W ignore::UserWarning -m fastchat.serve.controller &
nohup python0 -W ignore::UserWarning -m fastchat.serve.model_worker --model-path /path/to/quantized_vicuna_weights \
--model-name vicuna-13b-quantization --wbits 4 --groupsize 128 &
nohup python0 -W ignore::UserWarning -m fastchat.serve.gradio_web_server &現在、4ビットの量子化されたVicuna-13Bモデルを16GBのDDRメモリを持つRX6900XT GPUに適合させることができます。13Bモデルを実行するにはDDRの7.52GB(16GBの46%)のみが必要ですが、モデルはfp16データ型では28GB以上のDDRスペースが必要です。レイテンシペナルティと精度ペナルティも非常に最小限であり、関連するメトリクスはこの記事の最後に提供されます。

Web APIサーバーで量子化されたVicunaモデルをテストする
試してみましょう。まず、言語翻訳にfp16のVicunaモデルを使用しましょう。

私よりもうまくやってくれます。次に、サッカーについて何か質問してみましょう。答えは私にとっても良さそうです。
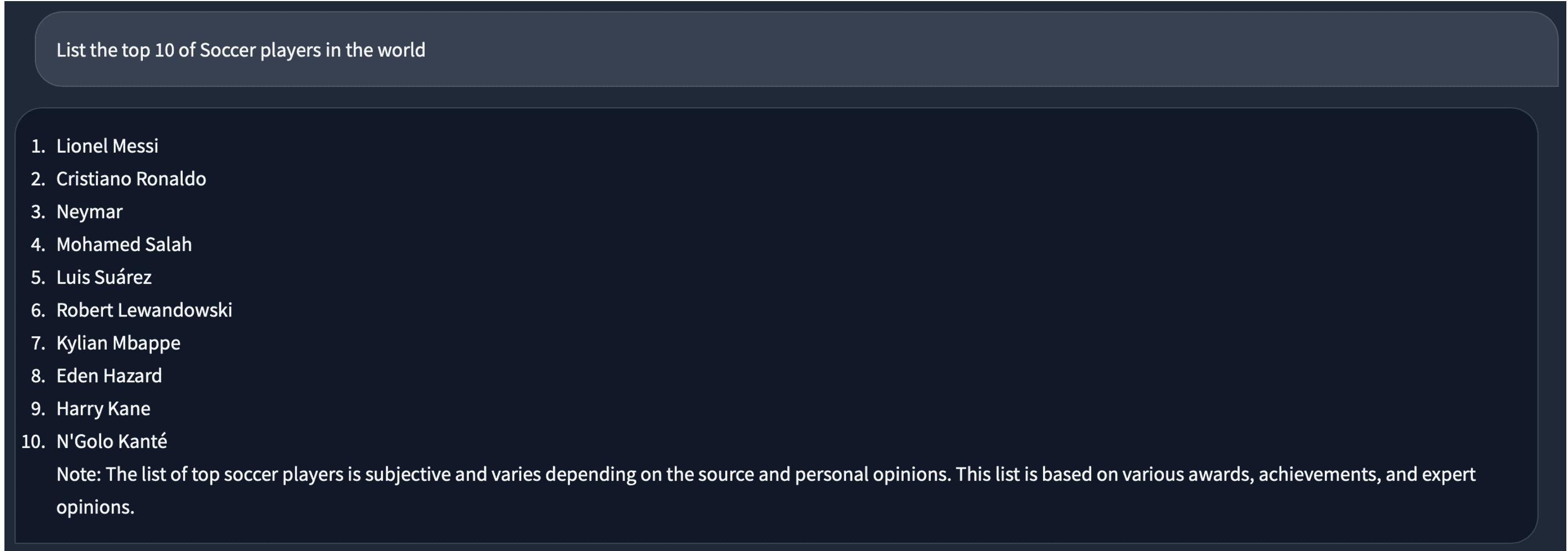
同じ質問に対して4ビットモデルに切り替えると、答えが少し異なります。中には重複した「Lionel Messi」があります。
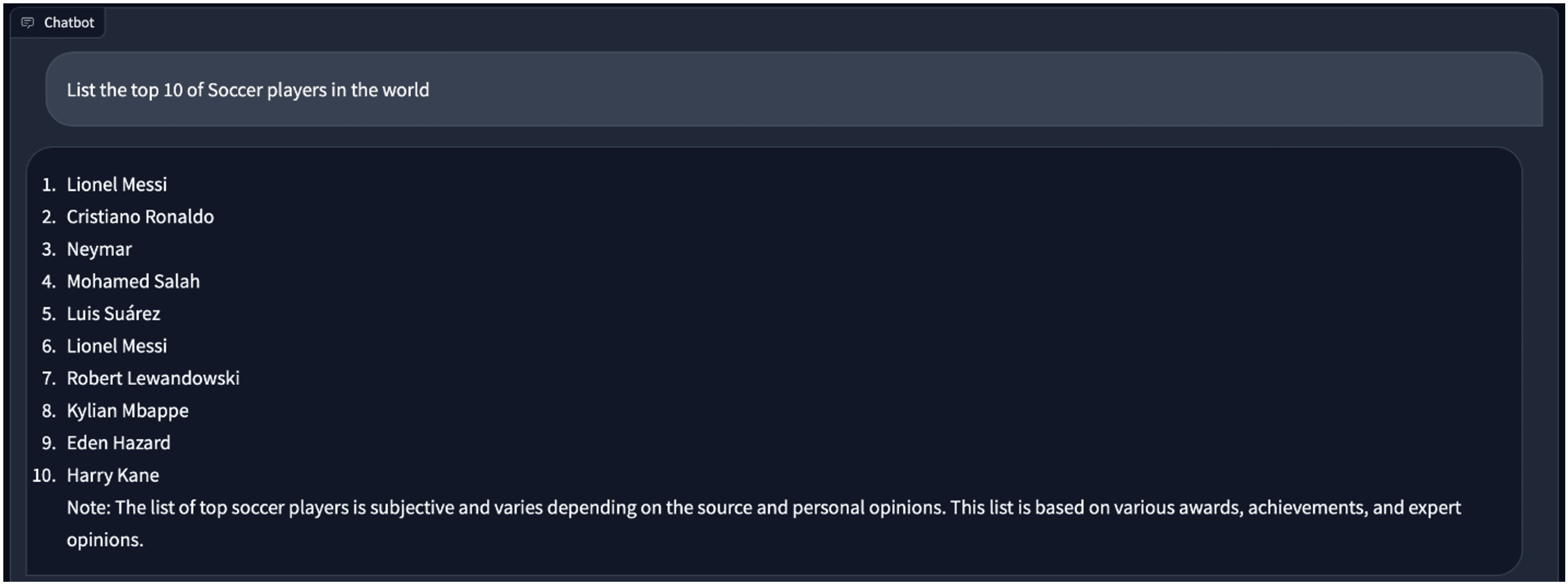
Vicuna fp16と4ビット量子化モデルの比較
テスト環境:
– GPU:Instinct MI210、RX6900XT
– Python: 3.10
– PyTorch: 2.1.0a0+gitfa08e54
– ROCm: 5.4.3
メトリクス – モデルサイズ(GB)
- モデルパラメータサイズ。モデルをGPU DDRにプリロードする場合、実際のDDRサイズの消費量は、入力および出力トークンスペースのキャッシュのためにモデル自体よりも大きくなります。

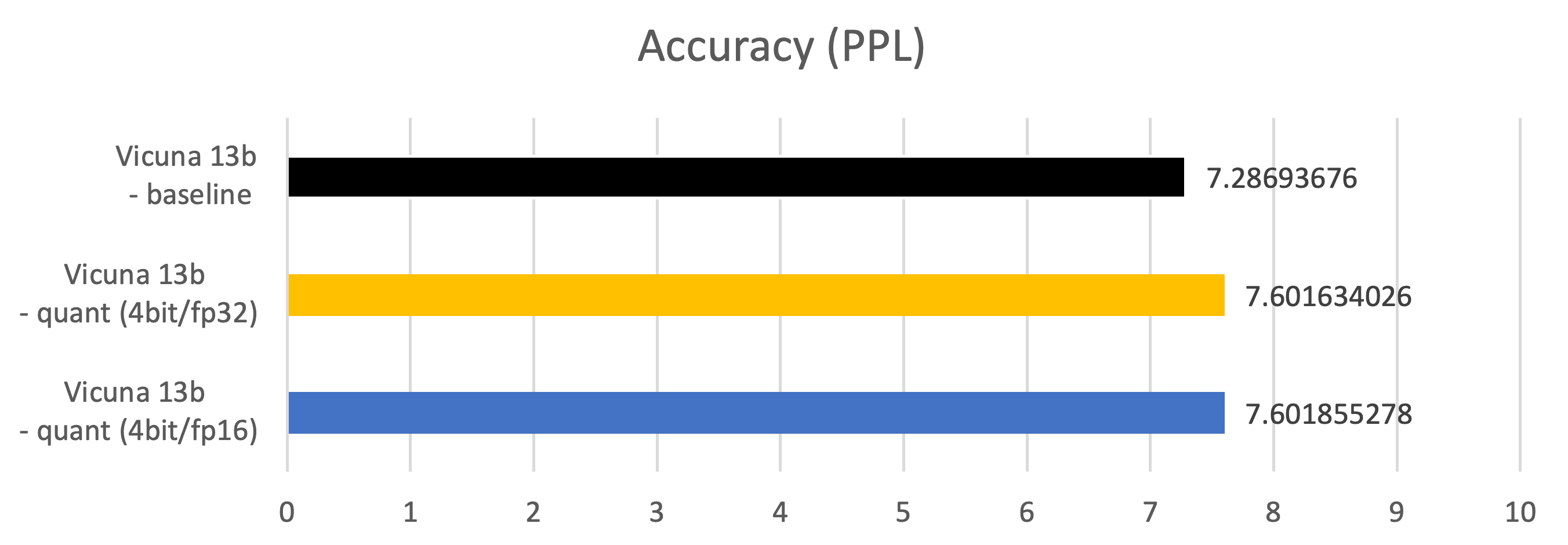
メトリクス – 精度(PPL:Perplexity)
-
C4(https://paperswithcode.com/dataset/c4)データセットの2048の例で測定
-
Vicuna 13b – ベースライン:fp16データ型のパラメータ、fp16 Matmul
-
Vicuna 13b – 量子化(4ビット/fp32):4ビットデータ型のパラメータ、fp32 Matmul
-
Vicuna 13b – 量子化(4ビット/fp16):4ビットデータ型のパラメータ、fp16 Matmul
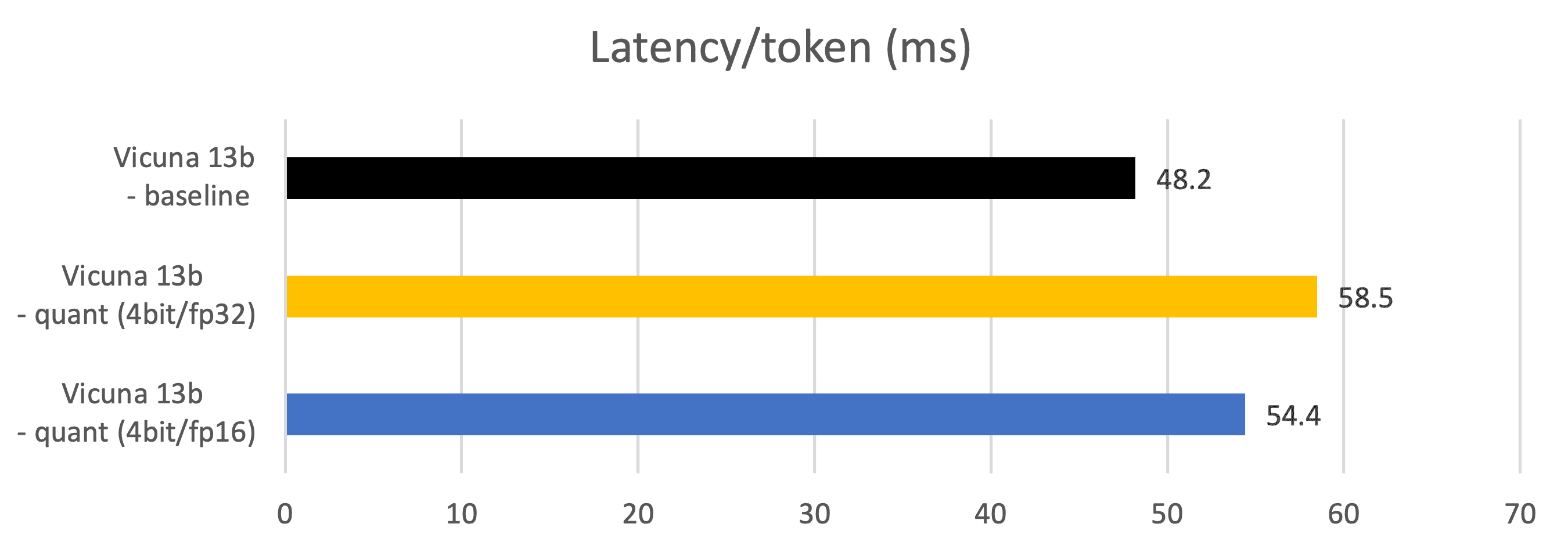
メトリクス – レイテンシ(トークン生成レイテンシ、ms)
-
トークン生成フェーズ中に測定されます。
-
Vicuna 13b – ベースライン:fp16データ型のパラメータ、fp16 Matmul
-
Vicuna 13b – 量子化(4ビット/fp32):4ビットデータ型のパラメータ、fp32 Matmul
-
Vicuna 13b – 量子化(4ビット/fp16):4ビットデータ型のパラメータ、fp16 Matmul
結論
大規模言語モデル(LLM)は、OpenAIのChatGPTでも見られるように、チャットボットシステムの進歩において重要な進展を遂げています。オープンソースのLLMモデルであるVicuna-13Bは、優れた能力と品質を実証しています。
このガイドに従うことで、AMD GPU上のROCMでVicuna 13Bモデルをセットアップして実行する方法について理解を深めることができるようになります。これにより、この最先端の言語モデルのフルポテンシャルを研究や個人のプロジェクトで活用することができます。
お読みいただき、ありがとうございました!
付録 – GPTQモデルの量子化
浮動小数点LLaMAモデルからVicuna量子化モデルの構築
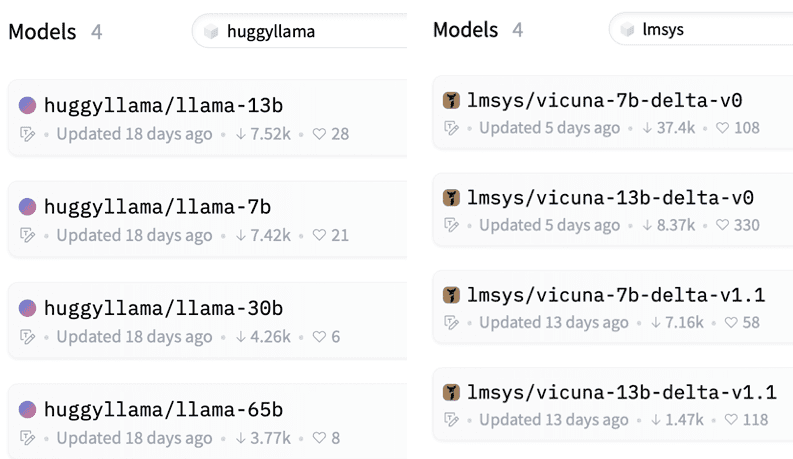
a. HuggingfaceからLLaMAとVicunaデルタモデルをダウンロードする
Vicunaの開発者(lmsys)は、LLaMAモデルに適用できるデルタモデルのみを提供しています。LLaMAのHuggingface形式とVicunaデルタパラメータを個別にダウンロードしてください。現在、Vicunaの7bと13bのデルタモデルが利用可能です。
https://huggingface.co/models?sort=downloads&search=huggyllama
https://huggingface.co/models?sort=downloads&search=lmsys
b. Vicunaデルタモデルを使用してLLaMAをVicunaに変換する
git clone https://github.com/lm-sys/FastChat
cd FastChatこのコマンドを使用して、LLaMAパラメータを変換します:
(注:vicuna-{7b, 13b}-*delta-v0は、LLaMAのvocab_sizeと異なるため、モデルを変換することはできません)
python -m fastchat.model.apply_delta --base /path/to/llama-13b --delta lmsys/vicuna-13b-delta-v1.1 \
--target ./vicuna-13b これでVicuna-13bモデルが準備できました。
c. Vicunaを2/3/4ビットに量子化する
GPTQをLLaMAとVicunaに適用するためには、
git clone https://github.com/oobabooga/GPTQ-for-LLaMa -b cuda
cd GPTQ-for-LLaMa(注:現時点ではhttps://github.com/qwopqwop200/GPTQ-for-LLaMaは使用しないでください。なぜなら、このリポジトリでは2、3、4ビットの量子化とMatMulカーネルが並列化されていないため、トークン生成パフォーマンスが低下するからです)
このコマンドでVicuna-13bモデルを量子化します。QATはc4データセットを基に行われますが、wikitext2などの他のデータセットも使用できます。
(注:モデルの精度が大幅に向上する限り、異なる組み合わせでグループサイズを変更してください。一部のwbitとgroupsizeの組み合わせでは、モデルの精度を大幅に向上させることができます。)
python llama.py ./Vicuna-13b c4 --wbits 4 --true-sequential --act-order \
--save_safetensors Vicuna-13b-4bit-act-order.safetensorsこれでモデルが準備され、Vicuna-13b-4bit-act-order.safetensorsとして保存されました。
GPTQデクォンタイズ + AMD GPU向けのFP16マルチプライカーネル
https://github.com/oobabooga/GPTQ-for-LLaMa/blob/57a26292ed583528d9941e79915824c5af012279/quant_cuda_kernel.cu#L891で最適化されたカーネル実装は、A100 GPUを対象としており、ROCM5.4.3 HIPIFYツールキットと互換性がありません。以下のように修正する必要があります。VecQuant2MatMulKernelFaster、VecQuant3MatMulKernelFaster、VecQuant4MatMulKernelFasterカーネルも同様です。
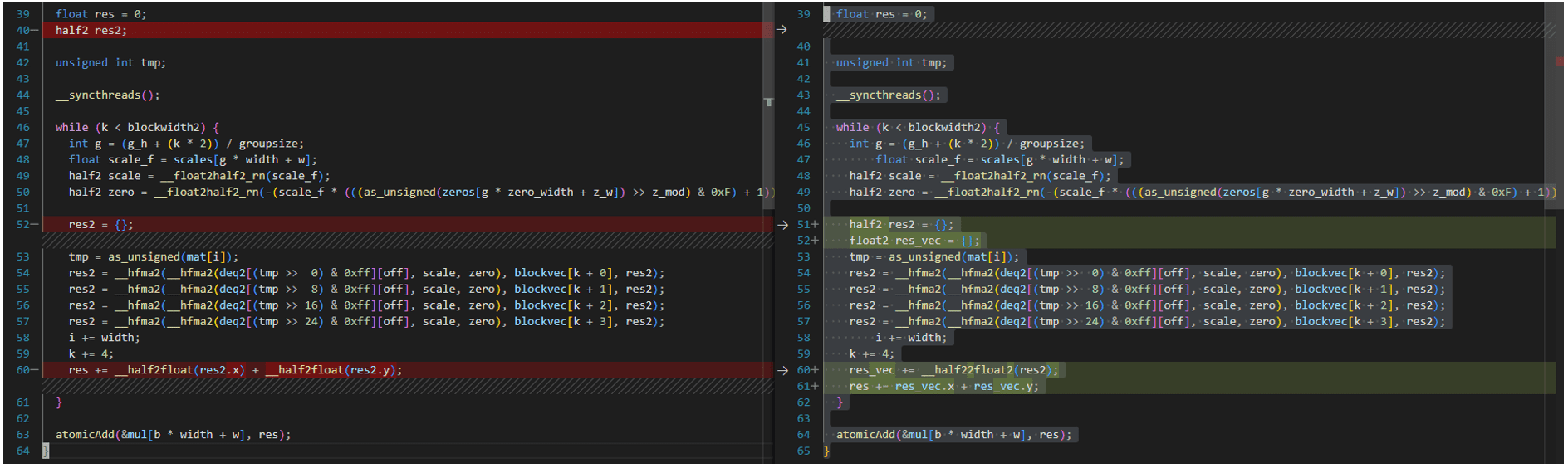
利便性のため、すべての修正されたコードはGithub Gistで利用可能です。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles





