大規模言語モデル:RoBERTa — ロバストに最適化されたBERTアプローチ
RoBERTa A Robustly Optimized BERT Approach for Large-scale Language Models
BERT最適化に使用される主な技術について学ぶ
はじめに
BERTモデルの登場により、NLPの分野で大きな進歩が見られました。BERTはTransformerからアーキテクチャを派生させ、言語モデリング、次の文予測、質問応答、NERタギングなど、さまざまな下流タスクで最先端の結果を実現しています。
大規模言語モデル:BERT — Transformerからの双方向エンコーダ表現
BERTが最先端の埋め込みを構築する方法を理解する
towardsdatascience.com
BERTの優れた性能にもかかわらず、研究者たちはその構成を試行錯誤し、さらに優れた指標を達成することを目指して実験を続けました。幸いにも、彼らは成功し、RoBERTaと呼ばれる新しいモデルを発表しました。RoBERTaは、堅牢な最適化BERTアプローチを実現するためのいくつかの独立した改良点を含んでいます。
- 「TikTokがAI生成コンテンツのためのAIラベリングツールを導入」
- デシAIは、DeciDiffusion 1.0を公開しました:820億パラメータのテキストから画像への潜在的拡散モデルで、安定した拡散と比べて3倍の速度です
- 「Hugging FaceはLLMのための新しいGitHubです」
本記事では、モデルに関する詳細な情報が含まれている公式のRoBERTa論文を参照します。簡単に言うと、RoBERTaは元のBERTモデルをベースにしたいくつかの改良点を含んでおり、アーキテクチャを含む他の原則は変わりません。この記事では、すべての改良点について説明します。
1. ダイナミックマスキング
BERTのアーキテクチャからは、事前学習中にBERTが一定割合のマスクされたトークンを予測することによって言語モデリングを行うことを覚えています。元の実装の問題は、異なるバッチ間で同じテキストシーケンスのための選択トークンが時々同じであるという事実です。
より具体的には、トレーニングデータセットは10回複製されるため、各シーケンスは10通りの異なる方法でマスクされます。BERTは40回のトレーニングエポックを実行するため、同じマスキングを持つ各シーケンスがBERTに4回渡されます。研究者たちは、シーケンスがBERTに渡されるたびにマスキングが一意に生成されるダイナミックマスキングを使用する方がわずかに良いと結論づけました。これにより、トレーニング中の重複データが減り、モデルがよりさまざまなデータとマスキングパターンで作業する機会が生まれます。

2. 次の文予測
論文の著者たちは、次の文予測タスクをモデル化するための最適な方法を見つけるための研究を行いました。その結果、いくつかの貴重な洞察を得ました:
- 次の文予測の損失を削除するとわずかに性能が向上します。
- 単一の自然文をBERTの入力に渡すと、複数の文から構成されるシーケンスを渡す場合と比べて性能が低下します。この現象を説明する最も可能性の高い仮説の一つは、モデルが単一の文に頼るだけで長距離の依存関係を学習する難しさです。
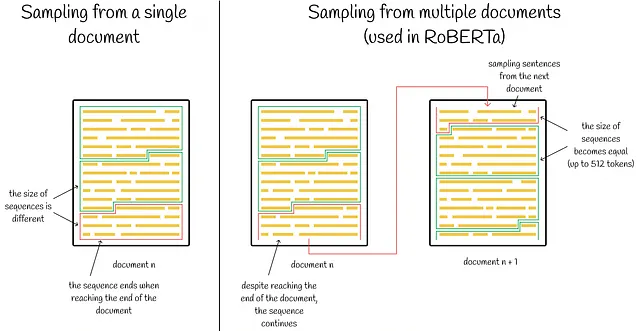
- 複数の文書からではなく、単一の文書から連続した文をサンプリングして入力シーケンスを構築する方が有益です。通常、シーケンスは単一の文書の連続した完全な文から構成されるため、合計トークン数は最大で512トークンになります。問題は、文書の末尾に到達したときに発生します。この点で、研究者たちは、そのようなシーケンスのために文のサンプリングを停止することが価値があるかどうか、または次の文書の最初のいくつかの文を追加的にサンプリングするか(文書間に対応するセパレータトークンを追加)を比較しました。結果は、最初のオプションが優れていることを示しました。
最終的なRoBERTaの実装では、著者たちは最初の2つの側面を保持し、3番目の側面を省略することを選びました。3番目の洞察の背後にある改善点にもかかわらず、研究者たちはそれを進めなかったのは、それによって以前の実装間の比較がより問題になるためです。文書の境界に到達し、そこで停止することは、入力シーケンスが512トークン未満になることを意味します。すべてのバッチで同じトークン数を持つために、そのような場合にはバッチサイズを増やす必要があります。これにより、可変バッチサイズとより複雑な比較が生じ、研究者たちはそれを避けたかったのです。
3. バッチサイズの増加
最近のNLPの進歩により、適切な学習率の減少とトレーニングステップ数の減少とともにバッチサイズを増やすことが、通常モデルの性能を向上させる傾向があることが示されています。
念のために言っておくと、BERTベースモデルは、256のシーケンスを持つバッチサイズで100万ステップでトレーニングされました。著者たちは、BERTを2Kおよび8Kのバッチサイズでトレーニングしており、後者の値がRoBERTaのトレーニングに選ばれました。対応するトレーニングステップ数と学習率の値は、それぞれ31Kと1e-3となりました。
また、バッチサイズの増加は、「勾配蓄積」と呼ばれる特別な技術を通じて簡単に並列化することができるということも重要です。
4. バイトテキストエンコーディング
NLPでは、主に3つのテキストトークナイゼーションのタイプが存在します:
- 文字レベルのトークナイゼーション
- サブワードレベルのトークナイゼーション
- 単語レベルのトークナイゼーション
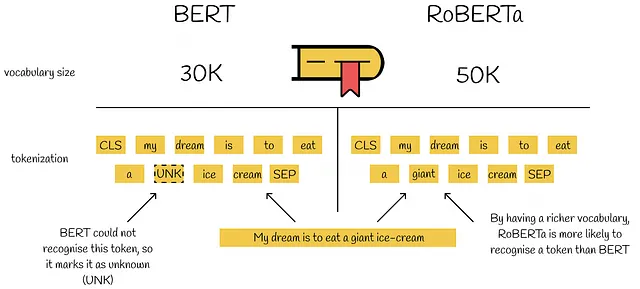
元のBERTは、入力前処理といくつかのヒューリスティックを使用して学習される30Kのサイズのサブワードレベルのトークナイゼーションを使用しています。RoBERTaは、プリプロセッシングや入力トークナイゼーションなしで、バイトをベースとしてサブワードを使用し、語彙サイズを50Kまで拡大しています。これにより、BERTベースモデルとBERTラージモデルにそれぞれ15Mおよび20Mの追加パラメータが生じます。RoBERTaで導入されたエンコーディングバージョンは、以前よりもわずかに悪い結果を示しています。
ただし、RoBERTaの語彙サイズの増加により、BERTと比較して未知のトークンを使用せずにほぼすべての単語やサブワードをエンコードすることが可能になります。これは、稀な単語を含む複雑なテキストをより完全に理解することができるというRoBERTaに著しい利点をもたらします。
事前トレーニング
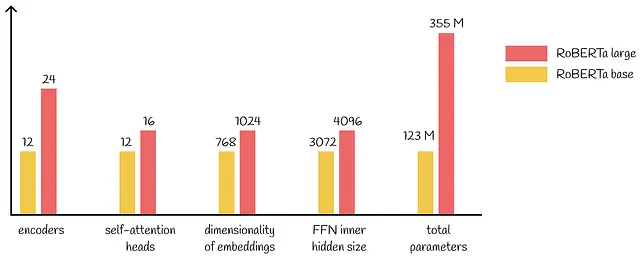
RoBERTaは、BERTラージと同じアーキテクチャパラメータを使用して、上記で説明された4つの側面すべてを適用します。RoBERTaの合計パラメータ数は355Mです。
RoBERTaは、合計160 GBのテキストデータからなる5つの大規模なデータセットの組み合わせで事前トレーニングされます。一方、BERTラージはわずか13 GBのデータで事前トレーニングされています。最後に、著者たちはトレーニングステップ数を100Kから500Kに増やしました。
その結果、RoBERTaは最も人気のあるベンチマークでBERTラージおよびXLNetラージを上回る性能を発揮しています。
RoBERTaのバージョン
BERTと同様に、研究者たちはRoBERTaの2つのバージョンを開発しました。ベースバージョンとラージバージョンのほとんどのハイパーパラメータは同じです。以下の図は、主な違いを示しています:
RoBERTaのファインチューニングプロセスはBERTと似ています。
結論
この記事では、BERTの改良版であるRoBERTaを、以下の側面を導入することで元のトレーニング手法を変更したものを検証しました:
- ダイナミックマスキング
- 次の文予測目標の省略
- より長い文でのトレーニング
- 語彙サイズの増加
- データ上でより長いバッチでのトレーニング
その結果、RoBERTaモデルは、トップのベンチマークでその祖先に比べて優れた性能を発揮するようです。より複雑な構成にもかかわらず、RoBERTaはBERTと比較して15Mの追加パラメータしか追加せず、推論速度もほぼ同等です。
参考資料
- RoBERTa:堅牢な最適化BERT事前トレーニング手法
すべての画像(特に注記がない場合)は著者によるものです
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles





