RLアンプラグド:オフライン強化学習のベンチマーク
RLアンプラグド:オフライン強化学習のベンチマーク

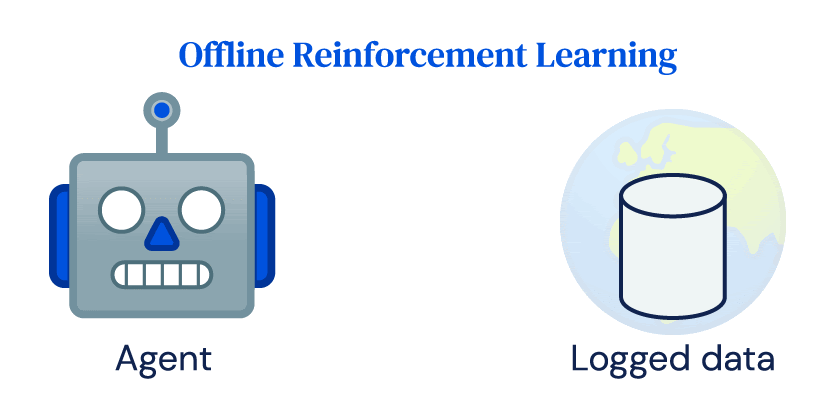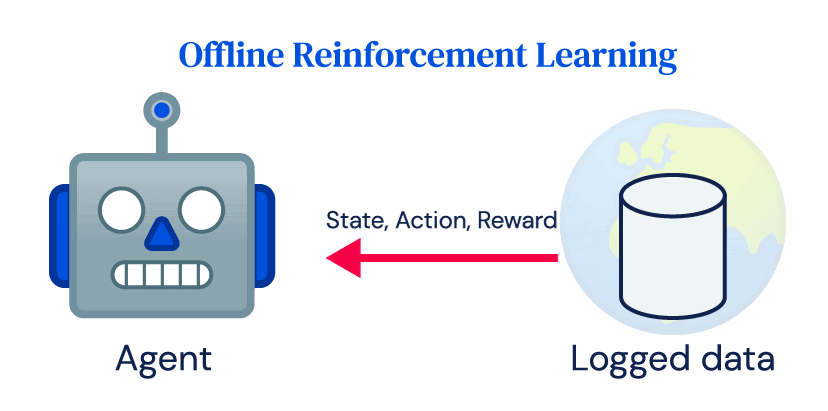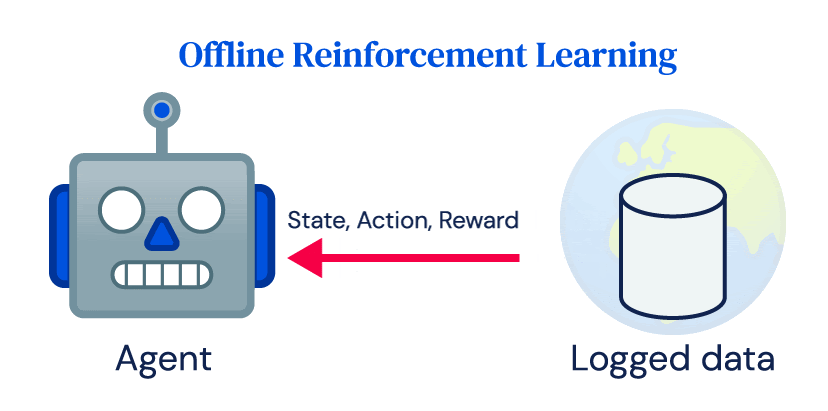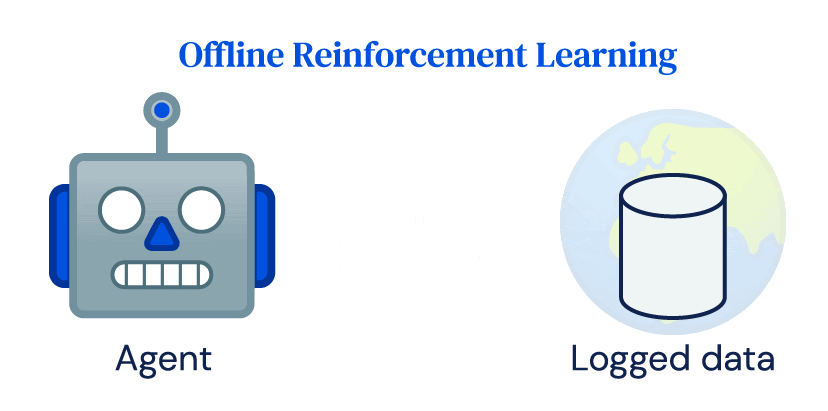
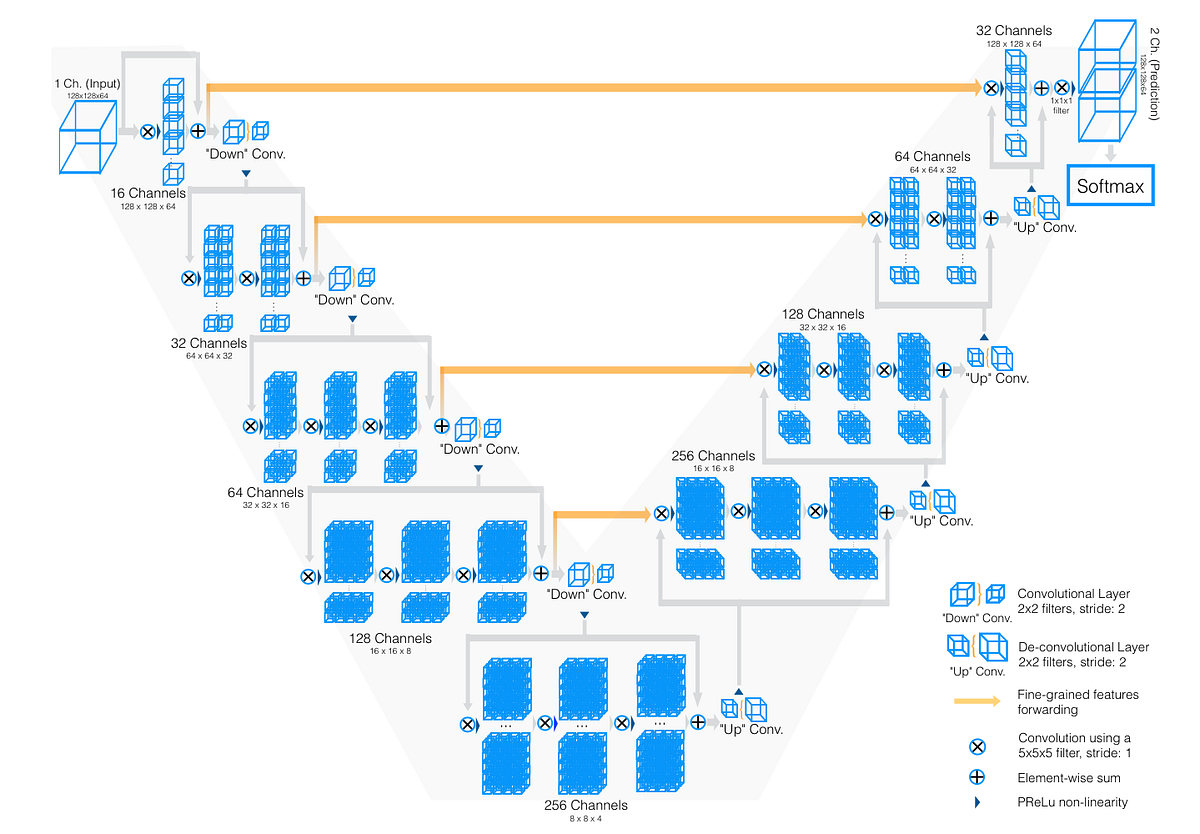
RLの成功の多くは、エージェントと環境の間の繰り返しのオンライン相互作用に大きく依存しています。これをオンラインRLと呼びます。シミュレーションでは成功しているにもかかわらず、RLの実世界への適用は限定的であり、発電所、ロボット、医療システム、または自動運転車などは稼働コストが高く、不適切な制御は危険な結果をもたらします。これらのシステムはRLの探索の重要なアイデアやオンラインRLアルゴリズムのデータ要件とは簡単には互換性がありません。それにもかかわらず、ほとんどの実世界のシステムは、通常の運用の一環として大量のデータを生成し、オフラインRLの目標は、環境との相互作用なしで直接そのログデータからポリシーを学習することです。
オフラインRLの手法(例:Agarwal et al.、2020; Fujimoto et al.、2018)は、よく知られたベンチマークドメインで有望な結果を示しています。しかし、非標準化の評価プロトコル、異なるデータセット、およびベースラインの不足により、アルゴリズムの比較が困難になっています。それにもかかわらず、部分観測、高次元のセンサーストリーム(例:画像)、多様な行動空間、探索問題、非定常性、および確率性など、潜在的な実世界のアプリケーションドメインの重要な特性は、現在のオフラインRLの文献では不十分に表現されています。
[GIF + キャプションを挿入]
私たちは、タスクドメインと関連するデータセットの新しいコレクションと明確な評価プロトコルを紹介します。DM Control Suite(Tassa et al.、2018)やAtari 2600ゲーム(Bellemare et al.、2013)などの広く使用されているドメインだけでなく、強力なオンラインRLアルゴリズムにとってまだ挑戦的な実世界のRL(RWRL)スイートタスク(Dulac-Arnold et al.、2020)やDM Locomotionタスク(Heess et al.、2017; Merel et al.、2019a,b, 2020)などのドメインも含まれています。環境、データセット、および評価プロトコルを標準化することで、オフラインRLの研究を再現可能でアクセス可能にすることを目指しています。私たちは、私たちのベンチマークスイートを「RL Unplugged」と呼びます。なぜなら、オフラインRLの手法は、環境との相互作用なしにそれを使用できるからです。私たちの論文は、次の4つの主な貢献を提供しています:(i)データセットのための統一されたAPI、(ii)さまざまな環境、(iii)オフラインRL研究のための明確な評価プロトコル、および(iv)参照パフォーマンスベースライン。
オフライン強化学習のためのRL Unplugged:ベンチマーク
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles