データ可視化のリニューアル:Pandasでの時間ベースのリサンプリングのマスタリング
『データ可視化の進化:Pandasを使った時系列データのリサンプリングのマスタリング』

この包括的な記事では、PythonとPandasライブラリを使用した時間ベースのデータの視覚化について説明します。時間系列データは洞察の宝庫であり、巧妙なリサンプリング技術によって、生の時間データを視覚的に魅力的な物語に変換することができます。データのエキスパート、科学者、アナリスト、または時間ベースのデータに隠されたストーリーを解明したいという好奇心のある方々に、この記事は知識とツールを提供し、データの視覚化スキルを刷新するのに役立ちます。さあ、パンダのリサンプリング技術について議論し、データを情報を提供し、魅力的な時間ベースの傑作に変えましょう。
データリサンプリングの重要性
時間ベースのデータの視覚化では、データリサンプリングは重要で非常に役立ちます。これにより、データの粒度を制御して意味のある洞察を抽出し、視覚的に魅力的な表現を作成して理解を深めることができます。以下の画像で、要件に基づいて周波数に基づいて時系列データをアップサンプリングまたはダウンサンプリングできることがわかります。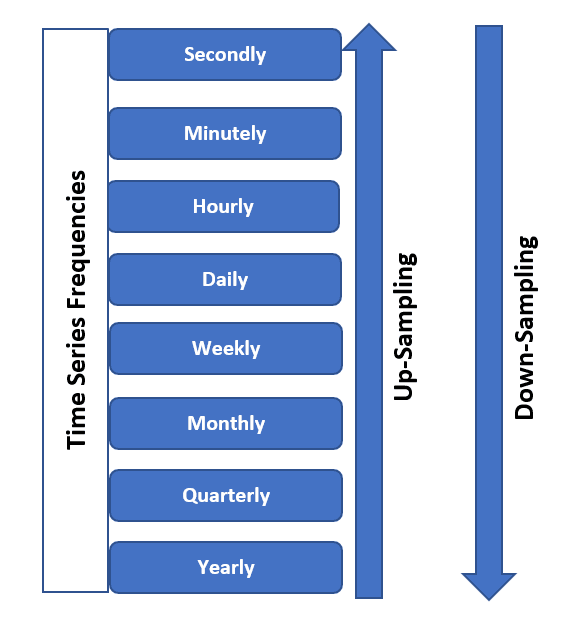
基本的に、データリサンプリングの2つの主な目的は以下の通りです:
- 粒度の調整: ビッグデータの収集により、データポイントが収集または集約される時間間隔を変更できます。ノイズではなく、重要な情報のみを得ることができます。これにより、視覚化のためのデータを管理しやすくするためにノイズのあるデータを取り除くことができます。
- 整合性: 異なるタイムインターバルを持つ複数のソースからのデータを整合させ、視覚化または分析を行う際に一貫性を保つのにも役立ちます。
例えば、
特定の企業の日次株価データを取得している場合、ノイズのあるデータポイントを分析に含めずに長期のトレンドを視覚化したいとします。このような場合、毎月の頻度にリサンプリングして各月の平均終値を取ることで、データのサイズを減らし、分析がより優れた洞察を提供することができます。
import pandas as pd# サンプルの日次株価データdata = {'Date': pd.date_range(start='2023-01-01', periods=365, freq='D'),'StockPrice': [100 + i + 10 * (i % 7) for i in range(365)]}df = pd.DataFrame(data)# 月次頻度にリサンプルmonthly_data = df.resample('M', on='Date').mean()print(monthly_data.head())
上記の例では、日次データを月次の区切りにリサンプリングし、各月の平均終値を計算しました。結果として、株価データのより滑らかでノイズの少ない表現が得られ、長期のトレンドやパターンを特定しやすくなり、意思決定に役立ちます。
適切なリサンプリング周波数の選択
時間系列データを扱う際に、リサンプリングの主なパラメータは周波数です。適切に選択することで、洞察に富んだ実用的な視覚化を得ることができます。基本的に、データの詳細度を意味するグラニュラリティと、データパターンが明らかにされる明瞭性の間にはトレードオフがあります。
例えば、
1年間の毎分の温度データが記録されていると想像してみてください。年間の温度傾向を視覚化する必要があるとします。毎分レベルのデータを使用すると、非常に密集し、乱雑なプロットになります。一方、データを年間平均に集約すると、貴重な情報が失われる可能性があります。
# サンプルの1分間レベルの温度データdata = { 'Timestamp': pd.date_range(start='2023-01-01', periods=525600, freq='T'), 'Temperature': [20 + 10 * (i % 1440) / 1440 for i in range(525600)]}df = pd.DataFrame(data)# 異なる頻度にリサンプルdaily_avg = df.resample('D', on='Timestamp').mean()monthly_avg = df.resample('M', on='Timestamp').mean()yearly_avg = df.resample('Y', on='Timestamp').mean()print(daily_avg.head())print(monthly_avg.head())print(yearly_avg.head())
この例では、分単位の気温データを日次、月次、年次の平均に再サンプリングします。分析や可視化の目的に応じて、最適な詳細レベルを選択することができます。日次平均では、日々の気温パターンが明らかになり、年次平均では年間の傾向が把握できます。
最適な再サンプリング頻度を選択することで、データの詳細度と可視化の明瞭さのバランスを取り、希望するパターンや洞察を簡単に理解できるようにすることができます。
集計方法と技術
時間ベースのデータを扱う際には、さまざまな集計方法と技術を理解することが重要です。これらの方法によって、データを効果的に要約し分析することができ、時間ベースの情報の異なる側面が明らかになります。標準の集計方法には、合計や平均の計算、カスタム関数の適用などが含まれます。 
例えば、
例えば、ある小売店の1年間の日次売上データを含んだデータセットがあるとします。年間の売上トレンドを分析したい場合、集計方法を使用して各月や年の総売上を計算することができます。
# Sample daily sales datadata = {'Date': pd.date_range(start='2023-01-01', periods=365, freq='D'),'Sales': [1000 + i * 10 + 5 * (i % 30) for i in range(365)]}df = pd.DataFrame(data)# Calculate monthly and yearly sales with the aggregation methodmonthly_totals = df.resample('M', on='Date').sum()yearly_totals = df.resample('Y', on='Date').sum()print(monthly_totals.head())print(yearly_totals.head())
この例では、sum()集計方法を使用して、日次売上データを月次と年次の合計に再サンプリングしています。これにより、異なる粒度で売上トレンドを分析することができます。月次合計は季節変動の特徴を示し、年次合計は年間の全体的なパフォーマンスを示します。
具体的な分析要件に応じて、データセットの分布に応じた平均や中央値の計算、カスタム関数の適用など他の集計方法も使用することができます。これらの方法を使用することで、時間ベースのデータから有益な洞察を抽出し、分析や可視化の目的に合った要約を行うことができます。
欠損データの処理
欠損データの処理は、タイムシリーズデータを扱う際の重要な要素であり、データにギャップがある場合でも正確で情報豊かな可視化と分析を維持するために重要です。
例えば、
歴史的な気温データを扱っていると想像してください。ただし、一部の日には機器の故障やデータ収集のエラーにより、気温の測定値が欠落している場合があります。これらの欠落した値を処理して、意味のある可視化を作成しデータの一貫性を保つ必要があります。
# Sample temperature data with missing valuesdata = { 'Date': pd.date_range(start='2023-01-01', periods=365, freq='D'), 'Temperature': [25 + np.random.randn() * 5 if np.random.rand() > 0.2 else np.nan for _ in range(365)]}df = pd.DataFrame(data)# Forward-fill missing values (fill with the previous day's temperature)df['Temperature'].fillna(method='ffill', inplace=True)# Visualize the temperature dataimport matplotlib.pyplot as pltplt.figure(figsize=(12, 6))plt.plot(df['Date'], df['Temperature'], label='Temperature', color='blue')plt.title('Daily Temperature Over Time')plt.xlabel('Date')plt.ylabel('Temperature (°C)')plt.grid(True)plt.show()
出力: 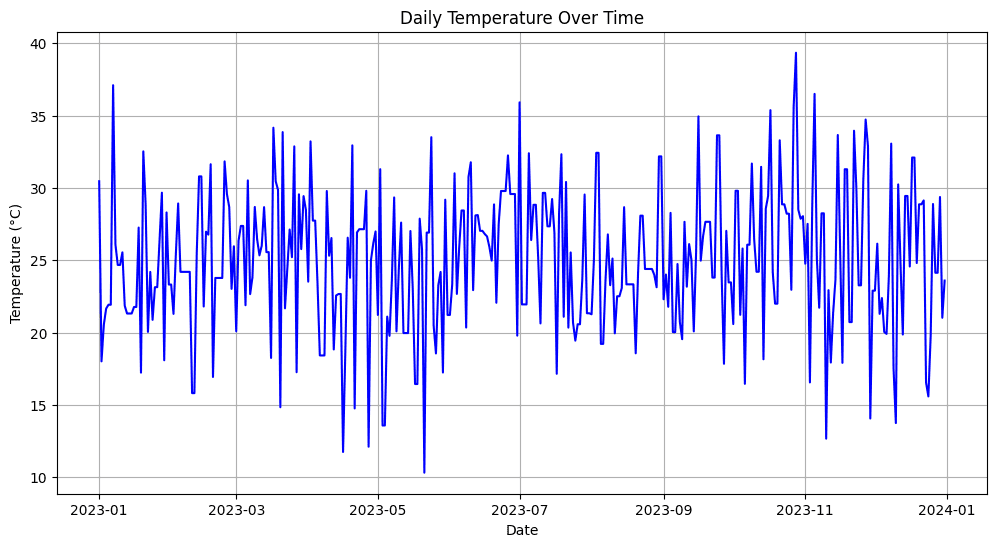
上記の例では、まず、欠損している気温値(データの約20%)をシミュレートし、前方埋め込み(ffill)メソッドを使用してギャップを埋めます。これにより、欠損値が前日の気温で置き換えられます。
したがって、欠損データの処理により、可視化が時間系列の基本的な傾向やパターンを正確に表現し、ギャップが洞察をゆがめたり観客を誤導することを防ぐことができます。データの性質や研究の問いに基づいて、内挿や後方埋めなどさまざまな戦略が採用できます。
トレンドとパターンの視覚化
pandasのデータリサンプリングを使用すると、連続または時間ベースのデータのトレンドとパターンを視覚化することができます。これにより、洞察を収集し、結果を他の人々に効果的に伝えることができます。その結果、トレンド、季節性、および不規則なパターン(おそらくデータのノイズ)を強調するために、データの明確で情報豊かな視覚的表現を見つけることができます。
例えば、
過去数年間にわたって収集されたウェブサイトの日次トラフィックデータを含むデータセットがあるとします。あなたは、後続の年間全体のトラフィックトレンドを視覚化し、季節性のパターンを特定し、トラフィックの不規則なスパイクや低下を見つけることを目指しています。
# サンプルの日次ウェブサイトトラフィックデータdata = {'Date': pd.date_range(start='2019-01-01', periods=1095, freq='D'),'Visitors': [500 + 10 * ((i % 365) - 180) + 50 * (i % 30) for i in range(1095)]}df = pd.DataFrame(data)# トレンドを視覚化するための折れ線グラフplt.figure(figsize=(12, 6))plt.plot(df['Date'], df['Visitors'], label='Daily Visitors', color='blue')plt.title('Website Traffic Over Time')plt.xlabel('Date')plt.ylabel('Visitors')plt.grid(True)# 季節性分解プロットを追加from statsmodels.tsa.seasonal import seasonal_decomposeresult = seasonal_decompose(df['Visitors'], model='additive', freq=365)result.plot()plt.show()
出力: 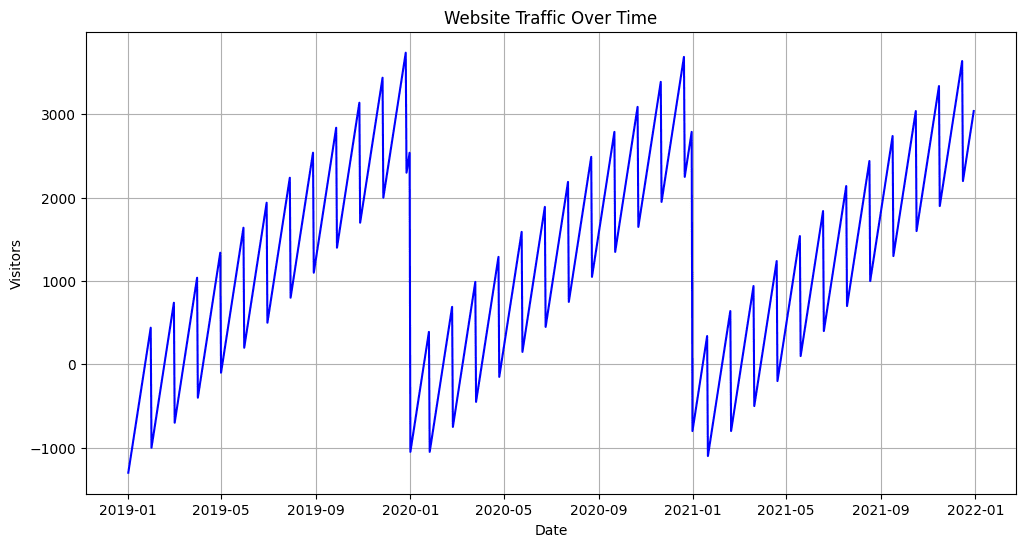
上記の例では、まず折れ線グラフを作成して、時間の経過に伴うウェブサイトの日次トラフィックトレンドを視覚化しています。このグラフは、データセットの全体の成長と不規則なパターンを説明しています。また、statsmodelsライブラリから季節性分解技術を使用してデータを異なる成分に分解しています。
これにより、ウェブサイトのトラフィックのトレンド、季節性、異常を関係者に効果的に伝えることができます。これにより、時間ベースのデータから重要な洞察を得て、データに基づく意思決定に変換する能力が向上します。
まとめ
Colabノートブックのリンク: https://colab.research.google.com/drive/19oM7NMdzRgQrEDfRsGhMavSvcHx79VDK#scrollTo=nHg3oSjPfS-Y
この記事では、Pythonでのデータの時間ベースのリサンプリングについて説明しました。そのため、セッションをまとめるために、この記事でカバーされた重要なポイントを要約しましょう:
- 時間ベースのリサンプリングは、時系列データを変換し、要約するための強力な技術であり、意思決定に向けた洞察を得るために重要です。
- リサンプリングの周波数の注意深い選択は、データの可読性と粒度をバランスよく保つために重要です。
- 合計、平均、およびカスタム関数などの集約手法は、時間ベースのデータの異なる側面を明らかにするのに役立ちます。
- 効果的な視覚化技術は、トレンド、季節性、および不規則なパターンを特定するのに役立ち、調査結果を明確に伝えるのに役立ちます。
- 金融、天気予報、ソーシャルメディア分析などの現実世界のユースケースは、時間ベースのリサンプリングの広範な影響を示しています。
Aryan Gargは、現在学部最終年度のB.Tech.電気工学の学生です。彼の興味はWeb開発と機械学習の分野にあります。彼はこの興味を追求し、これらの方向でさらに活動することを熱望しています。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
