兆のトークンからリトリーブして言語モデルを向上させる
Retrieve from trillions of tokens to improve language models.
近年、Transformerモデルのパラメータ数を増やすことにより、自己回帰言語モデリングの性能が大幅に向上しました。これにより、トレーニングエネルギーコストが莫大に増加し、100億以上のパラメータを持つ密な「大規模言語モデル」(LLM)が生成されました。同時に、ウェブページ、書籍、ニュース、コードを含む兆候のワードを含む大規模データセットが収集され、これらのLLMの訓練を容易にしました。
私たちは言語モデルの改善のための別のアプローチを探求しています。つまり、テキストパッセージのデータベースを検索することで、Transformerに機能を追加します。このデータベースには、ウェブページ、書籍、ニュース、コードなどが含まれています。私たちはこの方法を「Retrieval Enhanced TRansfOrmers(RETRO)」と呼んでいます。
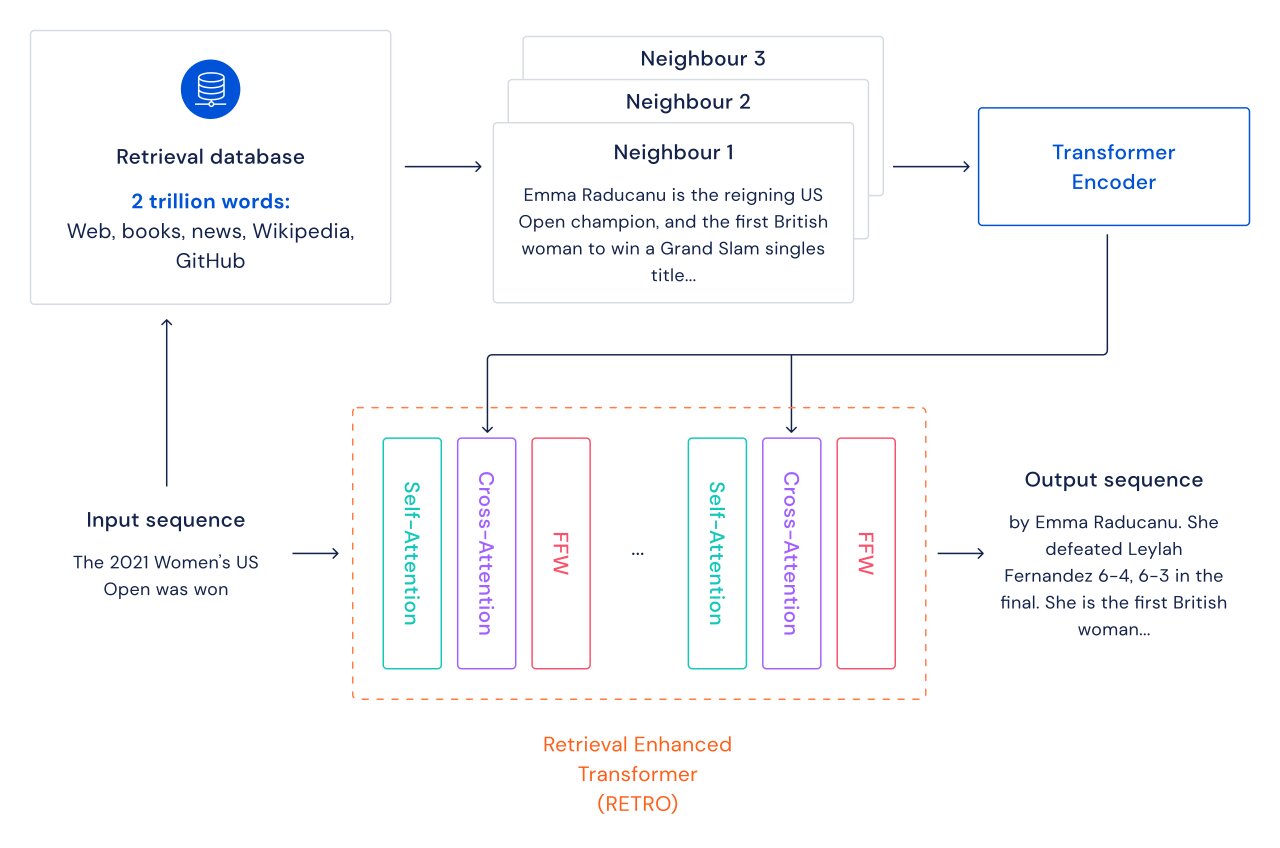
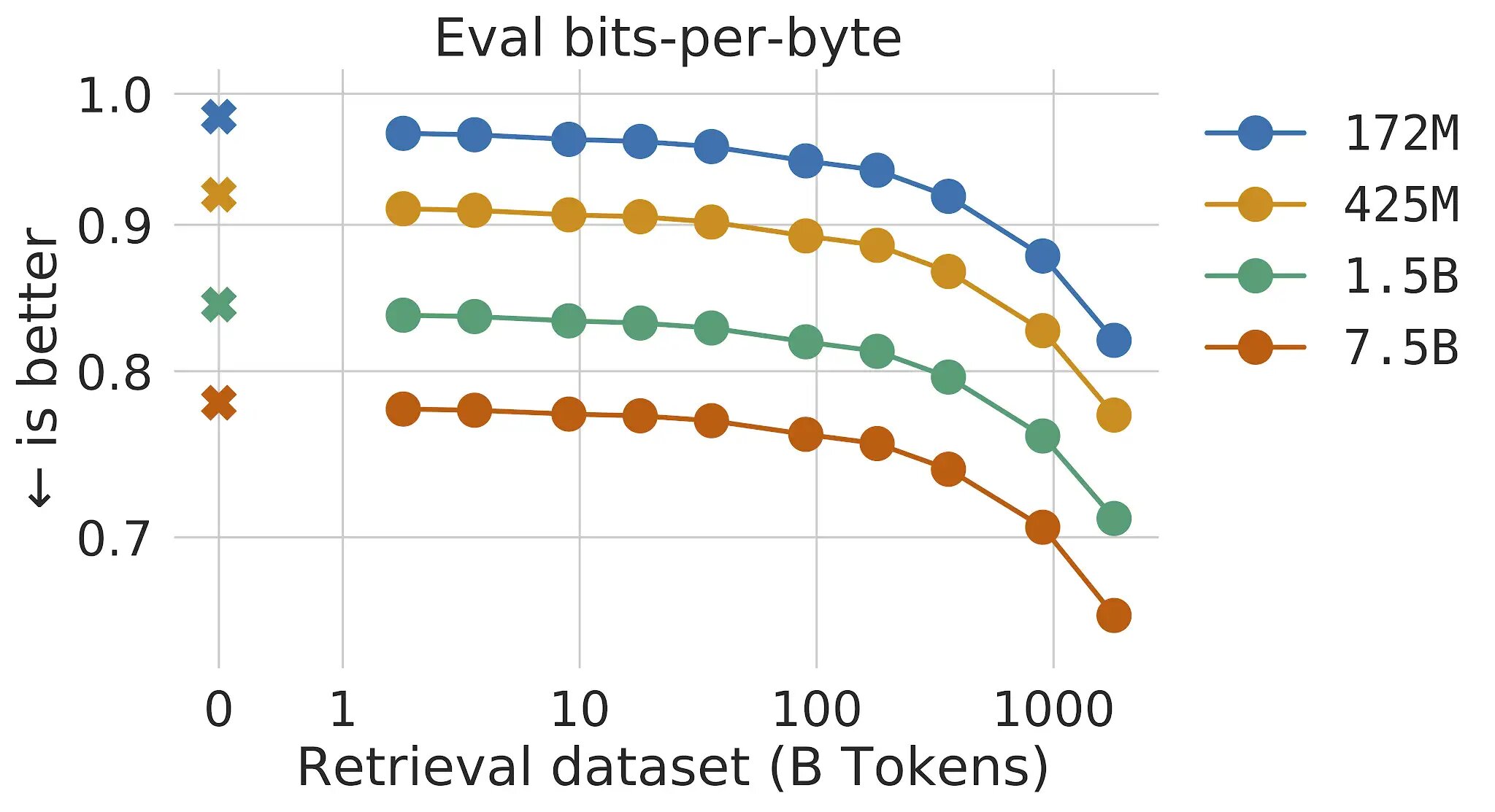
従来のTransformer言語モデルでは、モデルのサイズとデータのサイズの利点はリンクしています。データセットが十分に大きい限り、言語モデリングの性能はモデルのサイズに制約されます。しかし、RETROではモデルはトレーニング中に見たデータに制限されません-リトリーバルメカニズムを介してトレーニングデータセット全体にアクセスできます。これにより、同じパラメータ数を持つ標準のTransformerと比較して、大幅な性能向上が実現されます。リトリーバルデータベースのサイズを増やすと、言語モデリングが連続して改善することを示します。少なくとも2兆トークン-連続的な読書の175倍の寿命まで。
各テキストパッセージ(おおよそ文書の段落)ごとに、最近傍検索が実行され、トレーニングデータベースで見つかった類似のシーケンスとそれらの継続が返されます。これらのシーケンスは、入力テキストの継続を予測するのに役立ちます。RETROアーキテクチャは、文書レベルでの通常の自己アテンションと、より詳細なパスレベルでの取得された近隣との交差アテンションを交互に行います。これにより、より正確で事実に基づいた継続が実現されます。さらに、RETROはモデルの予測の解釈可能性を高め、テキスト継続の安全性を向上させるためにリトリーバルデータベースを介した直接的な介入のルートを提供します。Pileという標準の言語モデリングベンチマークでの実験では、75億パラメータのRETROモデルは、1750億パラメータのJurassic-1に対して16個のデータセットのうち10個で優れ、280B Gopherに対して16個のデータセットのうち9個で優れています。
以下に、7Bのベースラインモデルと7.5BのRETROモデルから抽出した2つのサンプルを示します。これらのサンプルは、RETROのサンプルがベースラインのサンプルよりも事実に即しており、トピックに沿っていることを強調しています。


We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles






