「研究:社会的に意識した時間的因果関係デコーダー推薦システム」
Research Socially conscious temporal causal decoder recommendation system.
エルタイエブ・アフメド(リサーチエンジニア)とサブラジット・ロイ(シニアリサーチサイエンティスト)によるGoogle Researchの投稿
読書には、言語能力や生活スキルの向上など、若い学生に多くの利益があります。また、楽しみのための読書は学業の成功と相関することが示されています。さらに、学生は読書によって感情の幸福感が向上し、一般的な知識や他の文化の理解も向上すると報告しています。オンラインやオフラインの読み物が非常に多いため、適切な年齢層に合った関連性の高い興味を引くコンテンツを見つけることは難しい課題ですが、学生が読書に没頭するためには必要なステップです。関連性の高い読み物を効果的に推薦することは、学生の読書を継続させるのに役立ちます。これが機械学習(ML)が役立つ場所です。
MLは、動画から書籍、eコマース商品まで、さまざまな種類のデジタルコンテンツにおいて推薦システムの構築に広く使用されています。推薦システムは、ユーザーに関連性の高い興味を引くコンテンツを提示するために、さまざまなデジタルプラットフォームで使用されています。これらのシステムでは、ユーザーの好み、ユーザーの関与度、および推薦されるアイテムに基づいて、各ユーザーにアイテムを提案するためのMLモデルがトレーニングされます。これらのデータは、モデルが興味を引く可能性のあるアイテムを推薦できるようにするための強力な学習信号を提供し、ユーザーエクスペリエンスを向上させます。
「STUDY:社会的に意識した時間的因果デコーダ推薦システム」という論文では、教育の設定でのオーディオブックのコンテンツ推薦システムを紹介しています。このシステムでは、読書の社会的な性質を考慮しています。私たちは教育非営利団体であるLearning Allyとのパートナーシップを通じてSTUDYアルゴリズムを開発しました。Learning Allyは、学生に学校全体の購読プログラムを通じてオーディオブックを提供することを目的としています。Learning Allyの図書館には、さまざまなオーディオブックがあります。私たちの目標は、学生が自分の読書体験と関与を高めるための適切なコンテンツを見つけるのを支援することです。私たちは、同じクラスにいる学生の読書関与の履歴を共同で処理することで、現在のトレンドに基づいてモデルが学生のローカライズされたソーシャルグループ(この場合は教室)内でトレンドになっているものを利用するようにしました。
- 「Java ZGCアルゴリズムのチューニング」
- 「分かれれば倒れ、一緒に立つ:CoTrackerは、ビデオ内の複数のポイントを共同で追跡するAIアプローチです」
- マルチアームバンディットを用いた動的価格設定:実践による学習
データ
Learning Allyには、学生を対象とした豊富なデジタルオーディオブックのライブラリがあり、学生の学習成果を向上させるためのソーシャル推薦モデルの構築に適しています。私たちは2年分の匿名化されたオーディオブックの消費データを受け取りました。データ中のすべての学生、学校、およびグループは匿名化されており、Googleによって追跡できないランダムに生成されたIDでのみ識別されます。さらに、潜在的に識別可能なメタデータは集計形式でのみ共有され、学生や機関が再識別されることを防ぐためです。データには、学生のオーディオブックとの相互作用のタイムスタンプ付きレコードが含まれています。各相互作用には匿名化された学生ID(学生の学年と匿名化された学校IDを含む)、オーディオブックの識別子、および日付があります。多くの学校では、1つの学年の学生を複数の教室に分けていますが、このメタデータを活用して、同じ学校と同じ学年のすべての学生が同じ教室にいるという単純化された仮定を行います。これにより、より良いソーシャル推薦モデルを構築するために必要な基盤が提供されますが、個人、クラスグループ、学校を再識別することはできません。
STUDYアルゴリズム
私たちは、クリックスルー率の予測問題として推薦問題を構築しました。つまり、各特定のアイテムとの相互作用におけるユーザーがアクションを起こす条件付き確率をモデル化するものです。このモデル化には、Google Researchが開発した広く使用されているTransformerベースのモデルクラスが適しているという以前の研究結果があります。各ユーザーが個別に処理されると、これは自己回帰的なシーケンスモデリング問題になります。私たちはこの概念的なフレームワークを使用してデータをモデル化し、その後、STUDYアプローチを作成するためにこのフレームワークを拡張しました。
このクリックスルー率予測アプローチでは、個々のユーザーの過去と将来のアイテムの好みの依存関係をモデル化することができますが、推論時に異なるユーザー間の依存関係をモデル化することはできません。読書の社会的な性質を認識し、この欠点を補うために、私たちはSTUDYモデルを開発しました。このモデルでは、各学生が読んだ複数の本のシーケンスを1つのシーケンスに連結し、単一の教室内の複数の学生からデータを収集します。
しかし、このデータ表現はtransformerによってモデル化される場合には注意が必要です。transformerでは、注意マスクは入力がどの出力の予測に情報を提供できるかを制御する行列です。出力の予測に先行するすべてのトークンを入力に使用するパターンは、因果デコーダで伝統的に見られる上三角の注意行列につながります。しかし、STUDYモデルに供給されるシーケンスは時間的に順序づけられていないため、その構成要素の各部分シーケンスは時間的に順序づけられています。標準的な因果デコーダは、このシーケンスには適していません。各トークンを予測しようとするとき、モデルは展開時には利用できない後続のトークンすべてにアテンションを向けることは許されません。これらのトークンのいくつかは、後のタイムスタンプを持ち、展開時に利用できる情報を含んでいる可能性があります。
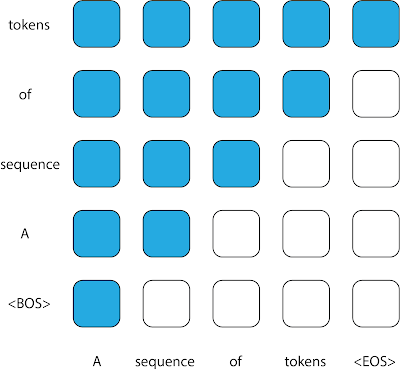 |
| この図では、通常、因果デコーダで使用されるアテンションマスクを示しています。各列は出力を表し、各列が出力を表します。特定の位置の行列エントリの値が1(青で表示される)である場合、モデルは対応する列の出力を予測する際にその行の入力を観察できることを示し、値が0(白で表示される)である場合はその逆を示します。 |
STUDYモデルは、時間刻みに基づいた柔軟なアテンションマスクを使用して、因果トランスフォーマーをベースに構築します。通常のトランスフォーマーでは、異なる部分列間でのアテンションを許可せず、シーケンス内では三角形の行列マスクが使用されますが、STUDYではシーケンス内で因果律のある三角形のアテンション行列を維持し、タイムスタンプに依存する柔軟な値を持つアテンションを異なるシーケンス間で許可します。したがって、シーケンス内の任意の出力ポイントでの予測は、その時点に対して過去に発生したすべての入力ポイントによって通知されます。これは、シーケンス内の現在の入力の前後に表示されるかどうかに関係なく、実際の世界の展開には利用できない未来の情報を使用して予測することを学習しないように、訓練時に強制される因果関係の制約が重要です。
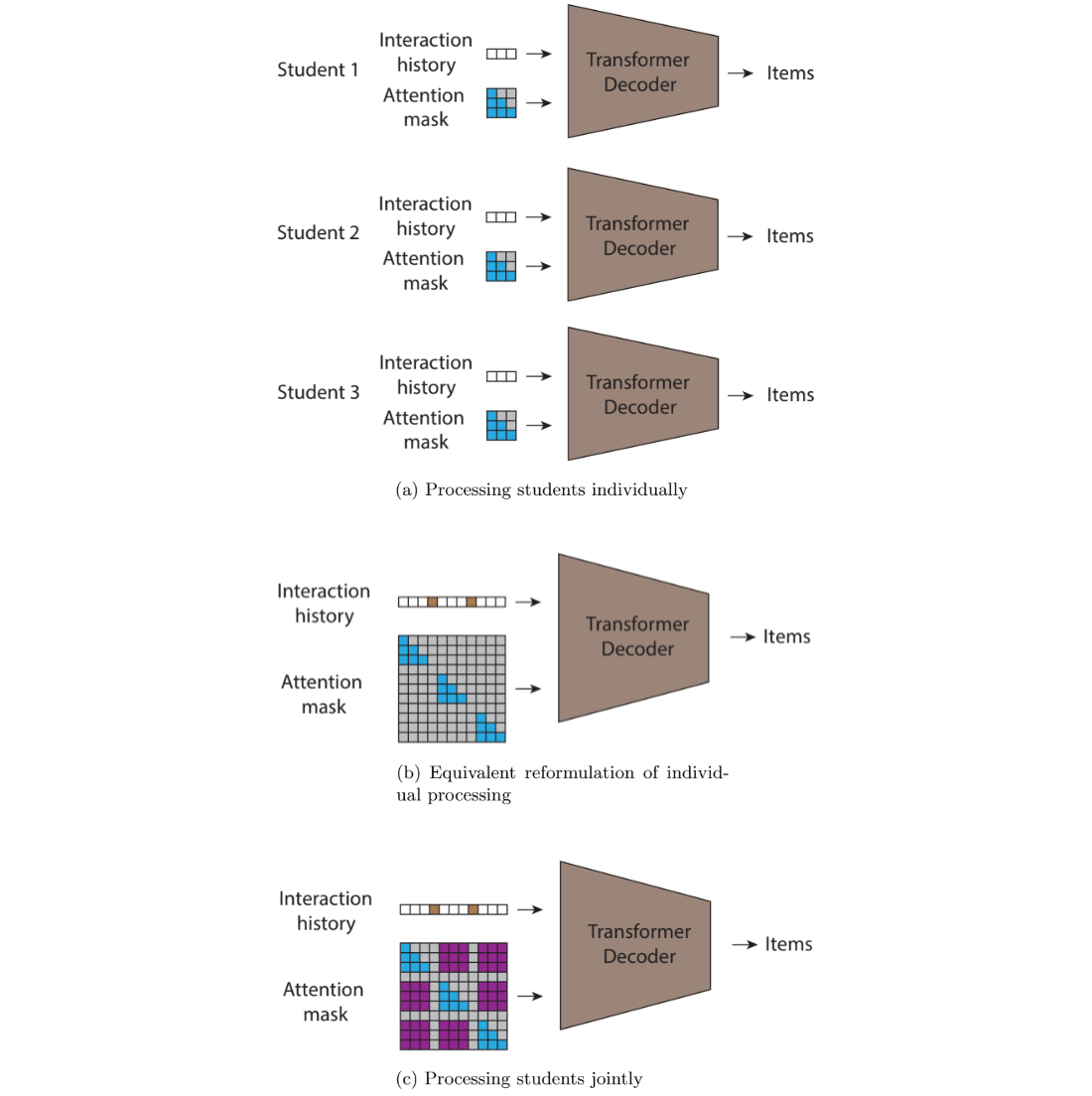 |
| (a)では、各ユーザーを個別に処理する因果律アテンションを持つ順次自己回帰トランスフォーマを示しています。 (b)では、同じ計算結果をもたらす同等の共同順送信を示しています。最後に、 (c)では、アテンションマスクに新しい非ゼロの値(紫で表示)を導入することで、ユーザー間で情報の流れを許可します。これにより、予測は同じユーザーからの相互作用に限らず、過去のタイムスタンプとのすべての相互作用に依存することができます。 |
実験
私たちは、比較のために複数のベースラインとともにSTUDYモデルを学習するためにLearning Allyデータセットを使用しました。私たちは、個別と呼んでいる自己回帰クリックスルーレートトランスフォーマーデコーダ、k最近傍法ベースライン(KNN)、および比較可能なソーシャルベースラインであるソーシャルアテンションメモリネットワーク(SAMN)を実装しました。訓練には最初の学年のデータを使用し、検証およびテストには2番目の学年のデータを使用しました。
これらのモデルを評価するために、nの異なる値に対して、ユーザーが実際に対話した次のアイテムがモデルの上位n件の推薦に含まれる割合(hits@n)を測定しました。テストセット全体でモデルを評価するだけでなく、テストセットの2つのサブセットでモデルのスコアを報告しました。これらのサブセットは、全データセットよりもよりチャレンジングです。学生は通常、複数のセッションでオーディオブックに対話するため、ユーザーが直近に読んだ本を単純に推薦するだけでは、強力なトリビアルな推薦となります。したがって、最初のテストサブセット(非継続と呼びます)では、学生が前回の対話と異なる本との推薦における各モデルのパフォーマンスのみを評価しました。また、学生は過去に読んだ本を再訪することも観察されましたので、テストセットでの強力なパフォーマンスは、各学生の推薦を過去に読んだ本に制限することによって達成することができます。学生に古いお気に入りを推薦することにも価値があるかもしれませんが、レコメンダーシステムの価値は、ユーザーにとって新しいかつ未知のコンテンツを提示することから生じます。これを測定するために、学生がタイトルと初めて対話するテストセットのサブセットでモデルを評価しました。この評価のサブセットを「新規」と呼びます。
私たちは、評価したほぼすべてのスライスにおいて、STUDYが他のすべてのテスト済みモデルを上回ることを見つけました。
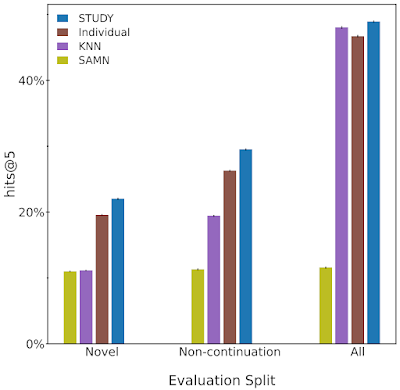 |
| この図では、Study、Individual、KNN、およびSAMNの4つのモデルのパフォーマンスを比較しています。モデルのパフォーマンスは、hits@5で測定します。つまり、モデルがトップ5の推薦の中でユーザーが次に読むタイトルを提案する可能性がどの程度あるかを示します。モデルの評価は、テストセット全体(all)および新規および非連続の分割で行われます。私たちは、STUDYがすべての分割で他の3つのモデルを常に上回っていることを確認しました。 |
適切なグループ分けの重要性
STUDYアルゴリズムの中心には、同じグループにいる複数のユーザーに対してモデルの単一の順方向パスで共同推論を行うためのユーザーのグループ化があります。私たちは実際のグループ分けがモデルのパフォーマンスに与える影響の重要性を調査する抜き打ち研究を行いました。私たちが提示したモデルでは、同じ学年および学校に在籍するすべての生徒を1つのグループにまとめています。その後、同じ学年および地区に在籍するすべての生徒でグループを作成し、各順方向パスに使用されるランダムなサブセットですべての生徒を1つのグループに配置する実験も行いました。また、参照用にこれらのモデルをIndividualモデルと比較しました。
学校と学年のグループ化が地区と学年のグループ化よりも効果的であることがわかりました。これは、STUDYモデルが成功するのは、読書などの社会的な活動の性質によるものであり、人々の読書の選択は周囲の人々の読書の選択と相関する可能性があるためです。これらのモデルのどちらも、学年を使用して生徒をグループ化しない場合の2つのモデル(単一グループおよびIndividual)を上回りました。これは、読書レベルと興味が似ているユーザーのデータがパフォーマンスに有益であることを示唆しています。
今後の課題
この研究は、社会的なつながりが均質であると想定されるユーザーポピュレーションの推薦モデリングに限定されています。将来的には、関係が均質でなく、異なるタイプの関係が存在するか、異なる関係の相対的な強さや影響力が既知のユーザーポピュレーションのモデリングが有益になるでしょう。
謝辞
この研究には、多様な専門分野の研究者、ソフトウェアエンジニア、教育の専門家の共同作業が含まれています。共著者のDiana Mincu、Lauren Harrell、Katherine Heller(Google)に感謝します。また、Learning Allyの同僚であるJeff Ho、Akshat Shah、Erin Walker、Tyler Bastian、Googleの共同研究者であるMarc Repnyek、Aki Estrella、Fernando Diaz、Scott Sanner、Emily Salkey、Lev Proleevにも感謝します。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles