「The Research Agent 大規模なテキストコーパスに基づいた質問に答える課題への取り組み」
Research Agent tackling the challenge of answering questions based on a large text corpus
私は自律型AI研究エージェントを作成しました。これは深いマルチホップ推論能力を持ち、困難な質問に答えることができます

問題の紹介
2021年、私は大量のテキストデータに基づいて質問に答えるという課題に取り組み始めました。事前学習済みトランスフォーマーが存在する以前の時代、この問題は解決が難しかったです。
そして、私は最も複雑で入り組んだストーリーの1つであるマハーバーラタで実験を始めました。マハーバーラタは18冊の本で構成され、合計約180万語のテキストを含んでいます。これは90,000の詩節から成る史上最大の詩です。イリアスとオデュッセイの合計の10倍の長さです。しかし、単に長さだけでなく、マハーバーラタの広がりも驚異的です。非線形で複雑な原因と結果を持ち、7世代にわたる数千のキャラクターが登場しますが、その中には完全に善でも悪でもないものは一人もいません。マハーバーラタには、義務(カルマ)、選択肢、人間の存在についての深い哲学的な論評があります。特に、義務と複数の間違いの選択肢の間の衝突についてです。バガヴァッド・ギーター(ヒンドゥー教の主要な哲学)もマハーバーラタの6冊目の一部です。
私はマハーバーラタのテキストデータをオンラインの複数のソースからクリーンなデータセットに編集しました。しかし、テキストに意味のある質問応答(QA)を実装する方法が見つかりませんでした。
2年も経たないうちに、すべてが変わりました。
- 「ニューヨーク大学の研究者が、人の見かけの年齢を画像内で変える新しい人工知能技術を開発しましたが、その人の独自の識別特徴を維持します」
- Googleの研究者たちは、AIによって生成された画像を透かしを入れたり識別するためのデジタルツールである「𝗦𝘆𝗻𝘁𝗵𝗜𝗗」を紹介しました
- 「GoogleはDeepfakeへの対策として、AIによって生成された画像にウォーターマークを付けます」
AIの急速な進歩と大規模な事前学習済みトランスフォーマーは、技術の世界を根本的に変えつつあります。私も最近の多くの技術者と同様に、それに魅了されています。
そこで、数ヶ月前に、私は新しく生まれたプロンプトエンジニアリングの技術の素朴な知識を持ちながら、問題に取り組み直しました。ただし、今回はどのような複雑な知識ベースでも動作する自律型研究エージェントを作成するという一般的なアイデアを持っています。
マハーバーラタは最も複雑なユースケースの一つです。ただし、法律、科学的研究、教育、医療などのあらゆる知識のドメインでは、すべてのプロジェクトが先行研究を深く行います。したがって、この問題は解決に値するものです。
研究エージェント
ここでは、深い推論能力を持つマルチホップKBQAの問題を解決できる自律型AI研究エージェントの設計と実装について説明します。Pythonノートブックで研究エージェントの初期実装とともにGitリポジトリを共有します。もしその部分に興味がある場合は、この記事の後の「実装」セクションに直接移動してください。
AIエージェント、知識ベースに基づく質問応答(KBQA)、AI研究エージェントの「なぜ」、「何」、および設計の進化について詳しく知りたい場合は、お読みください。
なぜ?
最初に思い浮かぶ疑問は、ChatGPTインターフェースを使用して質問をすることではないかというものです。ChatGPTは2021年までのインターネットデータの膨大な量でトレーニングされているため、マハーバーラタのようなテキストコーパスに詳しいはずです。
それが私の最初のアプローチでした。私はChatGPTに対してマハーバーラタに関するいくつかの質問をしました。一部の質問については良い回答が得られました。ただし、ほとんどの質問には厳密さが欠けていました。これは予想されたことです。GPTは一般的なデータセットでトレーニングされています。自然言語を理解し解釈することはできますし、十分に推論することもできます。ただし、特定のドメインの専門家ではありません。したがって、マハーバーラタについての一部の知識を持っているかもしれませんが、深く研究された回答を返すわけではありません。時にはGPTには何の回答もないかもしれません。その場合、質問に回答しないと謙虚に拒否するか、自信を持ってでっち上げます(幻覚)。
KBQAを実現するための2番目に明らかな方法は、検索型QAプロンプトを使用することです。ここで、LangChainが非常に役立つようになります。
リトリーバルQA
LangChainライブラリに慣れていない方々のために、それはコードでGPTのようなLLMを使用する最良の方法の一つです。LangChainを使用したKBQAの実装例を以下に示します。
リトリーバーを使用したQA | 🦜️🔗 Langchain
この例は、インデックス上の質問応答を示しています。
python.langchain.com
要約すると、ドキュメントの一連の手順でKBQAを実現するためのステップは以下の通りです。
- ナレッジベースをテキストのチャンクに分割します。
- 各チャンクに対して数値表現(埋め込み)を作成し、ベクトルデータベースに保存します。データが静的である場合、ステップ1と2は一度だけの作業です。
- ユーザーのクエリを使ってこのデータベースで意味的な検索を実行し、関連するテキストのチャンクを取得します。
- これらのテキストのチャンクをLLMにユーザーの質問と一緒に送り、回答を求めます。
以下はこのプロセスのグラフィカルな表現です。

ではなぜさらに進む必要があるのでしょうか?問題は解決済みのように思えます!
少し違います 🙁
このアプローチは、シンプルで事実に基づいたナレッジベース上の簡単な質問にはうまく機能します。しかし、より複雑なナレッジベースやより複雑な質問には適用できず、より深いマルチホップの推論が必要な場合には機能しません。マルチホップの推論とは、論理的または文脈的な推論の複数のステップを経て、結論や質問への回答に到達するプロセスを指します。
さらに、LLMは一度のプロンプトで処理できるテキストの長さに制限があります。もちろん、ドキュメントを一度に送信して、毎回回答を「洗練」または「縮小」することはできます。しかし、このアプローチでは複雑な「マルチホップ」の推論は許容されません。場合によっては、「洗練」または「縮小」アプローチを使用した結果が、すべてのドキュメントを単一のプロンプトに詰め込むよりも良い結果となることもありますが、差はそれほど大きくありません。
複雑なナレッジベースでは、ユーザーの質問自体だけでは、LLMが正確な回答を導くために必要な関連するドキュメントを見つけるのに十分ではありません。
例えば:
アルジュナは誰でしたか?
これはシンプルな質問で、限られた文脈で回答できます。しかし、次の質問:
マハーバーラタ戦争はなぜ起こったのですか?
は、その文脈がテキストコーパス全体に広がっている質問です。質問自体には文脈についての限られた情報しかありません。関連するテキストのチャンクを見つけ、それに基づいて推論することはうまくいかないかもしれません。
では、次は何ですか?
AIエージェント
これはAIの登場後に現れた最もクールな概念の一つです。AIエージェントの概念を知らない場合、その素晴らしさを説明するのが待ちきれませんが、それでもうまく伝えることができないかもしれません。まずはChatGPTを使用して説明します。
AIエージェント、または単に「エージェント」とは、環境を自律的に知覚し、決定を下し、特定の目標を達成するために行動を起こすソフトウェアプログラムまたはシステムを指します。AIエージェントは、問題解決や意思決定のタスクにおいて人間のような振る舞いを模倣するように設計されています。彼らは定義された環境内で動作し、その環境と対話して望ましい結果を達成します。
簡単に言えば、エージェントは問題を受け取り、解決方法を決定し、それを解決します。エージェントには、関数、メソッド、API呼び出しなどのツールセットが与えられます。それらのいずれかを選択し、適当な順序で使用することができます。これは従来のソフトウェアとは異なり、問題を解決するための手順の順序が事前にプログラムされているものです。もちろん、これは非常にあいまいな定義です。しかし、おそらく今までのところ理解していただけるでしょう。
以下は、KBQAのユースケースで試した2つの異なるエージェントです。
Reactこのエージェントは、与えられた問題に対してどのツールを使用するかを「React」(Reason and Action)スタイルの推論を使って決定します。
ReActエージェントのlangChain実装は次のとおりです:
ReAct | 🦜️🔗 Langchain
このウォークスルーでは、エージェントを使用してReActロジックを実装する方法を紹介します。
python.langchain.com
私はエージェントに以下のツールを提供しました:
- ドキュメントストアを使用した検索QAチェーン。
- キャラクターグロッサリー検索(事前学習済みモデルを使用して名前付きエンティティ認識で作成した用語集)。
- ウィキペディア検索。
Reactエージェントはうまく結果が得られず、ほとんどの場合、収束せずに回答を返しませんでした。GPT 3.5との互換性がありません。GPT 4であればうまく動作する可能性がありますが、GPT 3.5よりも20〜30倍高価ですので、まだ選択肢とはならないかもしれません。
収束しても、良い結果が得られませんでした。おそらく「react」プロンプトの作成に精通している他の人なら、もっと良い結果が得られたでしょう。
セルフアスクエージェントこのエージェントは、元の質問に基づいてフォローアップ質問を行い、中間の回答を見つけようとします。これらの中間回答を使用して、最終的な回答に至ります。セルフアスクエージェントの説明は、以下の記事にあります。
セルフアスクプロンプティング
セルフアスクプロンプティングは、チェーンオブソートプロンプティングからの進化です。いくつかの実践的な例と…
cobusgreyling.medium.com
このアプローチは、シングルホップの理由にはうまく機能します。ただし、複数のホップを必要とする質問には失敗します。
たとえば、次の質問:
カルナは誰によって殺され、なぜですか?
このアプローチで比較的簡単に答えることができます。
次の質問:
アルジュナはなぜ彼の異父兄弟であるカルナを殺したのですか?
これははるかに難しい質問です。これには、LLMがアルジュナがカルナが自分の異父兄弟であることを知らなかったという事実を知っている必要があります。LLMは、この事実を知る必要があるということを、質問を理解するか、元の質問に基づいてさらなる質問をすることによって知ることはできません。
人間の研究プロセス
再びGPTを引用します
人工知能エージェントは、問題解決や意思決定のタスクにおいて、人間のような振る舞いを模倣するよう設計されています
次に、私の次のアイデアは、人間がどのように研究を行うか、メタ研究として調査することでした。自分が図書館に座って(大学時代の懐かしい思い出)、研究の対象となるトピックに関連するすべての本に簡単にアクセスできる状況を想像しました。ノートブックとペンを取り、トピックを研究する際に私が従うプロセスを書き留め始めました。
以下に私が考えた内容を示します。
研究方法論:
ページに元のクエリを書き留めます。
- 数冊の本を読んで、現在の質問に答えようとします。このプロセスで、最も関連性の高いと思われるいくつかの抜粋をメモしたり、ブックマークしたりします。
- これらの抜粋には多くの未知の事項が含まれていることがよくあります。これらの未知の事項をメモし、これらの未知の事項について学ぶのに役立ついくつかの質問を書き留めます。
- これらの質問の中から、元の質問に最も関連性のある質問を選択します。
- ステップ1に戻ります
数回の反復の後、元の質問に答えるために十分な情報を持っているかどうかを自問自答します。
はいと答える場合、よくやった!いい仕事!
いいえと答える場合、努力を続けます。
ヴォワラ!
最後に、何をコード化するかわかりました。プロンプトエンジニアリングを少し行うことで、このプロセスは以前に試した他の方法よりも洞察に富んだ回答を提供してくれると期待しました。
ネタバレアラート…実際にそうなりました!:)
コードを書く前に、インターネットで類似のアイデアを検索しました。そして、BabyAGIを発見しました。素晴らしい世界です!
以下のリポジトリにはBabyAGIの説明があります。
BabyAGIの実装で使用されているプロンプトには、上記の研究プロセスと多くの類似点があることに気付きました。感謝の気持ちを込めて、BabyAGIのプロンプトからいくつかのインスピレーションを得ました。
リサーチエージェント-実装
ここでは、同じプロセスを素晴らしいdraw.ioを使用してフローチャートに変換したものです。
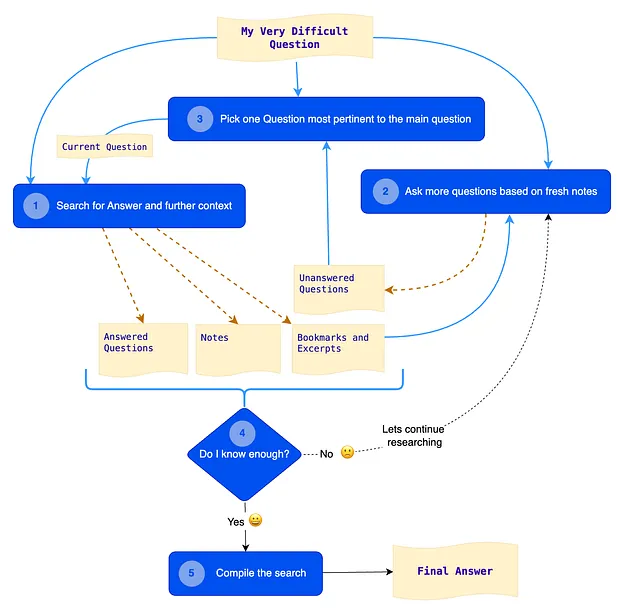
このチャートの青いボックスはすべてLLMへのコールです。
コンポーネント
- QAエージェント-回答と追加の文脈を検索これは、ベクトルストアを使用する単純な「もの」回収QAチェーンです。将来的には、ベクトルストア、検索API、またはWikipedia API、モデレーションAPI、および以前の研究データなどのツールを使用するAIエージェントになる可能性があります。ここでのプロンプトは、1.コンテキスト(ドキュメント)と2.元の質問への関連性に基づいて簡潔な回答を生成するように調整されています。最初のループ以外では、現在の質問は常にステップ2で生成され、ステップ3で選択された中間の質問です。エージェントは中間の回答をノートに追加し、最新の抜粋(現在の質問に答えるために使用されるドキュメント)をブックマークに追加します。これらのドキュメントの中で最新のものがステップ2で利用されます。
- 質問ジェネレーター-最新のノートに基づいてさらなる質問をするここでは、エージェントは最新のベクトル検索結果を使用して、現在の質問に一致する質問を生成します。これらの質問を未回答の質問のリストに追加します。ここでのプロンプトは、新しく生成された質問が既存の質問リストと重複しないように調整されています。
- 最も関連性のある質問ピッカー-元の質問に最も関連性のある質問を選択するこのプロンプトは、未回答の質問リストから元の質問に最も関連性のある質問を選択します。この質問は次のループのための現在の質問として使用されます。次のループでは、新しい質問セットを生成した後、エージェントはこの質問を未回答の質問リストから削除します。
- 分析者-十分な情報を持っていますか?私はループを終了するためにmax_iterationsパラメータを使用しています。これは現時点では非常にうまく機能しています。ただし、進化するコンテキストに基づいて反復の数や終了戦略を動的に決定する方が良いかもしれません。将来的に、これを自律的に行える「分析者」に取り組む予定です。
- リサーチコンパイラ-リサーチのコンパイルこれが最終的なプロンプトです。リサーチプロセス中に作成されたノートを使用して、「元の質問」に対する詳細な「最終回答」にたどり着きます。
結果
リサーチエージェントは、これまで試したすべてのアプローチよりも大幅に改善されています。他のアプローチよりも詳細で正確な回答を提供します。私はこれに数週間取り組んでおり、得られる回答の豊かさに驚いています。
エージェントは、以前のアプローチよりも幻覚の問題をより大きな範囲で回避します。最初の数回の反復で生成される幻覚や事実のエラーを自動的に修正します。問題に深く入り込むほど、より正確に結果を出力します。
ここに実行例があります。
質問: パーンダヴァたちはなぜ12年間森に住まなければならなかったのですか?
出力 –

もし興味がある場合は、ここに最終回答があります。
最終回答: パーンダヴァたちが12年間森に住むことを決めたのは、彼らの人生で展開された状況と出来事に主によるものでした。 クル王との賭博で敗北した後、パーンダヴァたちは13年間の追放を強いられ、最後の1年は匿名で過ごすことになりました。彼らの追放中、彼らは森での生活を含む数々の困難や苦難に直面しました。ビーマはクル族全員を殺すことを考えましたが、彼の兄ユディシュティラは常に彼をなだめ、彼らの欲望を満たすのに適切な時期ではないと述べました。したがって、森での生活は彼らが対立を避け、平和を維持するために彼らにとって有益でした。森での時間を通じて、パーンダヴァたちは数々の困難に直面しました。その中でも主な課題の1つは、ビーマが苦行的な生活を耐えることでした。彼はクル族全員を殺すことを考えましたが、彼の兄ユディシュティラは常に彼をなだめ、それを避けるよう忠告しました。さらに、パーンダヴァたちは王国が賭博で略奪されたため、森で生活し、自分たちの生計のために乞食に依存しなければなりませんでした。彼らは王国の喪失と女王ドラウパディへの侮辱に苦しんでいました。森自体も危険に満ちており、苦難を増大させました。さらに、パーンダヴァたちは森で彼らと一緒に滞在しているある信心深いブラフマナのニーズを満たすことができず、何も持っていないため自分たちの生存のために乞食に依存していました。これらの困難にもかかわらず、パーンダヴァたちは森での時間を最大限に活用しました。彼らは聖人や聖者から知識を得て、知恵と精神的な洞察を得るのに役立ちました。偉大な聖人ヴヤーサは、カルナ、シャクニ、ブリシュラヴァス、サラ、ドローナ、ビシュマを含む多くの将軍が彼らの従兄弟ドゥリヨーダナを支援することに同意したと彼らに伝えました。ヴヤーサはまた、アルジュナに対して、将来の戦争で戦うためにインドラ神とシヴァ神の神聖な武器を手に入れる必要があると伝えました。この情報に基づいて、ユディシュティラはアルジュナにヒマラヤ山脈に行ってシヴァ神を喜ばせるための苦行を行うよう命じました。これはアルジュナが将来の戦争で重要な役割を果たすこの回答はかなり詳しいものです。しかし、エージェントの美しいところは、元の質問に正確に答えただけでなく、質問に関連する物語を見つけ出したことです。
ほとんどの場合、私が得る回答はそのような詳細に富んでいます。そして、そのような回答はいつも私の好奇心を刺激します。
エージェントはまた、研究プロセス中にメモしている「回答済みの質問」と「未回答の質問」のセットも提供します。ですので、毎回実行後には、私が尋ねることができる多くの他の質問に導かれます。過去数週間で、私はそれ以前の何年間よりもマハーバーラタについて多くを学びました。
** 未回答の質問 ** '4. パーンダヴァスは森の中で聖人や神聖な人々からどのように知識を受け取ったのですか?''5. アルジュナはヒマラヤ山脈でどのような苦行を行ってシヴァ神を喜ばせたのですか?''6. パーンダヴァスは13年間の追放のほとんど全期間にわたりデュリョーダナのスパイからどのように隠れたのですか?''8. ビーマは森での苦行をどのように乗り越えたのですか?彼は追放中に特定の困難や苦労に直面しましたか?''9. デュリョーダナの目的を支持した将軍たちについての詳細情報を提供できますか?彼らはクルクシェートラ戦争でどのような役割と貢献をしたのですか?''10. パーンダヴァスはどのようにして森の中で平和な生活を維持したのですか?彼らが直面した困難にもかかわらず?''11. パーンダヴァスは森の中で聖人や神聖な人々からどのような教えや知識を受けましたか?''12. パーンダヴァスが森に行く前の1年間、彼らが住んでいた宮殿についての詳細情報を提供できますか?''13. パーンダヴァスの追放中、森の中での経験にロード・クリシュナの存在はどのように影響しましたか?''14. パーンダヴァスが森で暮らしている間に直面した危険についての詳細情報を提供できますか?''15. ユディシュティラと彼の兄弟たちは森の住人としての日常生活で直面した具体的な課題と困難は何でしたか?''
他の知識領域に対して同じプロセスを続けることを想像してみてください、とても興奮する考えですね!
コード
そして、ここには研究エージェントの実装を行ったPythonノートブックがあります。
GitHub - rahulnyk/research_agent
GitHubでアカウントを作成して、rahulnyk/research_agentの開発に貢献してください。
github.com
マハーバーラタのデータセットのGitリポジトリ
GitHub - rahulnyk/mahabharata: 複数のソースから編集されたマハーバーラタのテキストをチャンクごとに分割したもの...
マハーバーラタのテキストは複数のソースから編集され、チャンクごとに分割され、メタデータ付きのCSVファイルにパースされます。名前付きエンティティ...
github.com
次は何ですか?
現在の実装は、自律型のAI研究エージェントのアイデアの単純なバージョンです。私はエージェントの実装を通じて何度も研究プロセスを回しました。これは興味深い旅でしたが、楽しみはまだ終わっていません。現在取り組んでいるいくつかの改善点を以下に示します。
- このエージェントを公開リンクにデプロイし、より多くの利用パターンを観察する。
- マハーバーラタ以外の異なるソースドキュメントでエージェントを使用する。
- 現在のプロセスのステップ1は、ソーステキストコーパスを使用した単純な「stuff」QAチェーンです。私はそれを「ReAct」エージェントと置き換えるために、検索API、Wikipedia、モデレーションAPIなどの他のツールを研究プロセスに使用できるように取り組んでいます。
- 私は、毎回の実行時に生成されるデータとメタデータを`runs`ベクトルストアに保存しています。また、元の質問の埋め込みも同じストアに保存しています。これにより、エージェントの推論経路を追うことができ、そこから生じるいくつかの論理的なパターンを観察することができます。これにより、QAエージェントをより緻密な推論経路に従うように調整するのに役立ちます。
- 現在、研究エージェントは固定された一連の反復後に存在します。これはほとんどの質問には非常にうまく機能しますが、進化する文脈に基づいて反復の回数や終了戦略を動的に決定する方が良いかもしれません。これには自律的に行うことができる「解析エージェント」を作成します。
- エージェントは、メタ質問を除くほとんどの種類の質問に対してうまく機能します。例えば、「第5章3節で何が起こるかを説明してください」と尋ねると、エージェントは答えるのが難しいです。将来のバージョンでは、そのような場合に対処するために、「ReAct」エージェントに自己クエリリトリーバーを含める予定です。
- これまで、私はOpenAI GPT3.5モデルのみを使用してエージェントを試しました。これには約0.02ドルかかります。近々、ローカルでホストできるようなLlamaのような小さなモデルで研究エージェントを試してみます。
次の記事では、これらのアップデートの一部を実装した後の調査結果について書く予定です。より大きなアイデアは、困難な質問に対して深く研究された回答を見つけることに優れた自律型AI研究エージェントを作成することです。ですので、ぜひ提案していただき、可能であれば、一緒にこのエージェントを成熟させるために協力してください。
この記事と共有されたコードが役立つことを願っています。
読んでいただき、ありがとうございます。
AI研究エージェントがエキサイティングで役に立つものとなることを願っています。
共有したノートブックは、この「自律型AI研究エージェント」を作成するという大きなアイデアの単純な実装にすぎません。このエージェントを一流の研究者にするためには、さらに多くの作業が可能です。
ですので、ぜひ提案していただき、可能であれば、一緒にこのエージェントを成熟させるために協力してください。
読んでいただき、ありがとうございます。
上記の記事で使用したデータセットとそのライセンス情報のクレジット:
- Complete Translation by K. M. Ganguli: パブリックドメインで利用可能です。
- Laura Gibbs Tiny Tales: これは、マハーバーラタを200エピソードにまとめたもので、各エピソードは100語で構成されています。ここで彼女の作品を許可を得て使用しています。
- Kaggleデータリポジトリ by Tilak: NLPのためのテキスト形式のマハーバーラタの18パルヴァすべて。Tilakによってパブリックドメインライセンスで共有されています。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
-
このAI研究は、深層学習システムが継続的な学習環境で使用される際の「可塑性の喪失」という問題に取り組んでいます
-
Googleとジョージア工科大学の研究者が、セグメンテーションマスクを作成するための直感的な後処理AIメソッドであるDiffSegを紹介しました
-
「S-LabとNTUの研究者が、シーニメファイ(Scenimefy)を提案しましたこれは、現実世界の画像から自動的に高品質なアニメシーンのレンダリングを行うための画像対画像翻訳フレームワークであり、セミスーパーバイズド(半教師付き)手法を採用しています」
-
プリンストン大学の研究者が、MeZOというメモリ効率の高いゼロ次最適化器を紹介しましたこの最適化器は、大規模言語モデル(LLM)を微調整することができます
-
「SynthIDを使ったAI生成画像の識別」
-
UCLとGoogleの研究者が提案する「AudioSlots:オーディオドメインの盲目的なソース分離のためのスロット中心の生成モデル」
-
初心者のための2023年の機械学習論文の読み方





