ReLoRa GPU上で大規模な言語モデルを事前学習する
ReLoRa GPUで言語モデルを事前学習する
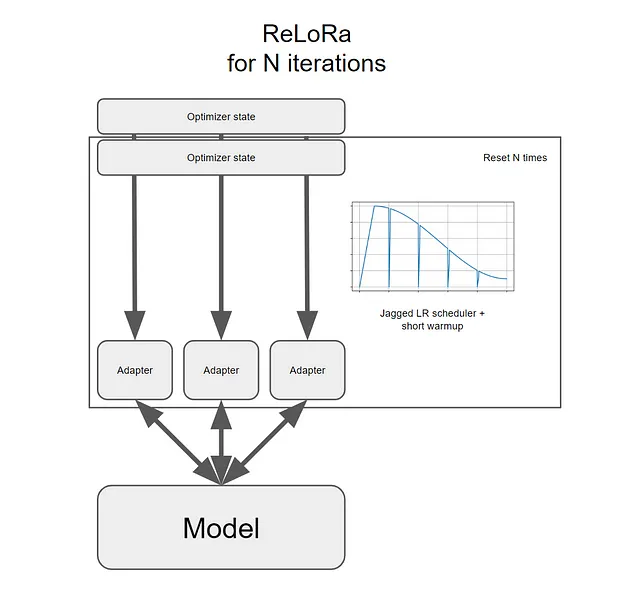
複数回のリセットを行うLoRa
2021年、HuらはLLMsのための低ランクアダプタ(LoRa)を提案しました。この方法は、高ランクネットワーク(LLMsの元のパラメータ)を凍結させたまま、わずかな追加パラメータ(低ランクネットワーク)のみをトレーニングすることで、大規模な言語モデル(LLMs)の微調整のコストを大幅に削減します。
LoRaでは、既存の事前学習モデルを微調整する必要があります。つまり、低ランクの制約により、良いLLMをゼロから事前学習することはできません。これにより、事前学習はほとんどの個人や組織にとって手の届かないものとなります。
このコストを削減するために、Lialinら(2023年)はReLoRaを提案しています。これは、LoRaの改良版であり、ゼロからLLMsを事前学習することができます。
この記事では、まずReLoRaの動作原理を説明します。次に、ReLoRaを説明する科学論文で発表された結果を分析し、コメントします。最後のセクションでは、コンピュータ上でReLoRaを設定して実行する方法を示します。
- SimPer:周期的なターゲットの簡単な自己教示学習
- LMSYS ORG プレゼント チャットボット・アリーナ:匿名でランダムなバトルを行うクラウドソーシング型 LLM ベンチマーク・プラットフォーム
- 「Mojo」という新しいプログラミング言語は、Pythonの使いやすさとCのパフォーマンスを組み合わせ、AIハードウェアのプログラム可能性とAIモデルの拡張性を他のどの言語よりも優れたものにします
ライセンスに関する注意事項: ReLoRaに関するarXivで発表された科学論文は、CC BY 4.0ライセンスの下で配布されています。ReLoRaのソースコードはGitHubで公開され、商用利用が許可されるApache 2.0ライセンスで配布されています。
ReLoRa:低ランクから高ランクネットワークへ
ReLoRaの動作原理を理解するためには、まずLoRaを詳しく見てみる必要があります。
LoRaは、トレーニング後に元の凍結された高ランクネットワークにマージされる2つの異なるセットの新しいトレーニング可能なパラメータAとBを追加することで機能します。
明らかなことかもしれませんが、AとBの合計のランクは、それぞれの個々のランクの合計よりも高くなります。これを以下のように形式化することができます:
LoRaはこれらの2つのパラメータセットのみをトレーニングしました。ただし、複数回リセットしてトレーニングし、元の高ランクネットワークに連続してマージすることができれば、ネットワークの総ランクを時間とともに増やすことができます。つまり、より大きなモデルを得ることができます。
なぜLoRaはこれらのリセットを行わないのでしょうか?
なぜなら、これらのリセットを有益にするためにはいくつかの重要な障害が存在するからです…
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- MPT-7Bをご紹介します MosaicMLによってキュレーションされた1Tトークンのテキストとコードでトレーニングされた新しいオープンソースの大規模言語モデルです
- AIとディープラーニングに最適なGPU
- ラミニAIに会ってください:開発者が簡単にChatGPTレベルの言語モデルをトレーニングすることができる、革命的なLLMエンジン
- MLCommonsは、臨床効果を提供するためのAIモデルのベンチマークを行うためのオープンソースプラットフォームであるMedPerfを紹介します
- 医学論文のLLaMAのFine-tuning:バイオメディカルQAベンチマークで高い性能を発揮するPMC-LLaMA-Aモデルに出会ってください
- 「ImageReward(イメージリワード)に会ってください:AIの生成能力と人間の価値観を結ぶ革命的なテキストから画像へのモデル」
- 大規模な言語モデルの理解:(チャット)GPTとBERTの物理学






