「Swift Transformersのリリース:AppleデバイスでのオンデバイスLLMsの実行」
Release of Swift Transformers Executing On-Device LLMs on Apple devices
私はiOS/Macの開発者に多くの敬意を持っています。2007年にiPhone向けのアプリを書き始めたときは、まだAPIやドキュメントさえ存在しませんでした。新しいデバイスは、制約空間におけるいくつかの見慣れない決定を採用しました。パワー、画面の広さ、UIのイディオム、ネットワークアクセス、永続性、遅延などの組み合わせは、それまでとは異なるものでした。しかし、このコミュニティはすぐに新しいパラダイムに適した優れたアプリケーションを作り出すことに成功しました。
私はMLがソフトウェアを構築する新しい方法だと信じており、多くのSwift開発者が自分のアプリにAI機能を組み込みたいと思っていることを知っています。MLのエコシステムは大きく成熟し、さまざまな問題を解決する数千のモデルが存在しています。さらに、LLM(Language and Learning Models)は最近、ほぼ汎用のツールとして登場しました。テキストやテキストに似たデータで作業するため、新しいドメインに適応させることができます。私たちは、LLMが研究所から出てきて、誰にでも利用可能なコンピューティングツールになりつつあるという、コンピューティングの歴史上の転換点を目撃しています。
ただし、LlamaのようなLLMモデルをアプリに使用するには、多くの人が直面し、単独で解決する必要があるタスクがあります。私たちはこの領域を探求し、コミュニティと一緒に取り組みを続けたいと考えています。開発者がより速く開発できるように、ツールとビルディングブロックのセットを作成することを目指しています。
今日は、このガイドを公開し、MacでCore MLを使用してLlama 2などのモデルを実行するために必要な手順を説明します。また、開発者をサポートするためのアルファ版のライブラリとツールもリリースしています。MLに興味のあるすべてのSwift開発者にPRやバグレポート、意見を提供して、一緒に改善するよう呼びかけています。
- 「DPOを使用してLlama 2を微調整する」
- 「DENZAはWPPと協力し、NVIDIA Omniverse Cloud上で高度な車両設定ツールを構築・展開する」
- 「NVIDIA Studio内のコンテンツ作成が、新しいプロフェッショナルGPU、AIツール、OmniverseおよびOpenUSDの共同作業機能によって向上します」
さあ、始めましょう!
動画: Llama 2 (7B)チャットモデルがCore MLを使用してM1 MacBook Proで実行されています。
今日リリース
swift-transformersは、テキスト生成に焦点を当てたSwiftで実装されたtransformersライクなAPIを開発中のSwiftパッケージです。これはswift-coreml-transformersの進化版であり、より広範な目標を持っています。Hubの統合、任意のトークナイザのサポート、プラグイン可能なモデルなど。swift-chatは、パッケージの使用方法を示すシンプルなアプリです。- transformersモデルのCore ML変換のための更新されたバージョンの
exporters、Core ML変換ツールであるtransformers-to-coremlの更新されたバージョン。 - これらのテキスト生成ツールで使用するために準備されたLlama 2 7BやFalcon 7Bなどの変換されたモデル。
タスクの概要
私がFalconやLlama 2が自分のMacで動作していることを示すツイートを公開したとき、他の開発者からも同じモデルをCore MLに変換する方法について多くの質問を受けました。変換は重要なステップですが、パズルの最初のピースにすぎません。私がこれらのアプリを作る本当の理由は、他の開発者と同じ問題に直面し、どの領域で助けることができるかを特定することです。この投稿の残りの部分では、私たちはこれらのタスクのいくつかを取り上げ、どこで(そしてどこでないか)私たちが助けるためのツールを持っているかを説明します。
- Core MLへの変換。Llama 2を実例として使用します。
- モデル(およびアプリ)の高速化とメモリの消費量をできるだけ少なくするための最適化技術。これはプロジェクト全体に渡る領域であり、適用できる銀の弾丸のような解決策はありません。
swift-transformers、いくつかの一般的なタスクをサポートするための新しいライブラリ。- トークナイザ。トークナイゼーションとは、テキスト入力をモデルが処理する実際の数値のセットに変換する方法(および生成された予測からテキストに戻す方法)です。これは聞こえるよりも複雑で、さまざまなオプションや戦略があります。
- モデルとHubのラッパー。Hubのさまざまなモデルをサポートするために、モデルの設定をハードコードすることはできません。シンプルな
LanguageModelの抽象化と、Hubからモデルとトークナイザの設定ファイルをダウンロードするためのさまざまなユーティリティを作成しました。 - 生成アルゴリズム。言語モデルは、テキストのシーケンスの後に現れる可能性のある次のトークンの確率分布を予測するように訓練されます。テキストの出力を生成するためにモデルを複数回呼び出し、各ステップでトークンを選択する必要があります。次にどのトークンを選択するかを決定する方法はさまざまです。
- サポートされているモデル。すべてのモデルファミリーがサポートされているわけではありません(まだ)。
swift-chat。これは、プロジェクトでswift-transformersを使用する方法を示す小さなアプリです。- 欠けている部分/次に来るもの。重要なが利用できないものや、将来の作業の方向性。
- リソース。すべてのプロジェクトやツールへのリンク。
Core MLへの変換
Core MLはAppleのネイティブな機械学習フレームワークであり、また、それが使用するファイル形式の名前でもあります。例えば、PyTorchからCore MLにモデルを変換すると、Swiftアプリで使用することができます。Core MLフレームワークは、モデルを実行するための最適なハードウェアを自動的に選択します:CPU、GPU、またはニューラルエンジンと呼ばれる特殊なテンソルユニットです。システムの特性とモデルの詳細に応じて、これらの計算ユニットの組み合わせも可能です。
実際のモデル変換の様子を見るために、最近リリースされたLlama 2モデルの変換を見てみましょう。このプロセスは時に複雑になることもありますが、私たちはお手伝いするためのいくつかのツールを提供しています。これらのツールは常に動作するわけではありませんが、新しいモデルが常に導入されているため、調整や修正が必要です。
私たちの推奨手法は次のとおりです:
transformers-to-coreml変換スペースを使用する:
これはexporters(後述)の上に構築された自動化ツールであり、モデルに適用できるかどうかに関わらず動作します。コーディングは必要ありません:Hubモデル識別子を入力し、使用するタスクを選択し、適用をクリックします。変換が成功した場合、変換されたCore MLの重みをHubにプッシュして、完了です!
Spaceを訪れるか、ここで直接使用できます:
exportersを使用する:Appleのcoremltools(後述)の上に構築されたPython変換パッケージです。
このライブラリは、変換タスクを設定するためのさまざまなオプションを提供します。さらに、独自の変換設定クラスを作成することもできます。これにより、追加の制御や変換の問題への対処に使用できます。
coremltoolsを使用する:Appleの変換パッケージです。
これは最も低レベルなアプローチであり、したがって最大の制御を提供します。一部のモデル(特に新しいモデル)ではまだ失敗することがありますが、常にソースコードの内部に入り、なぜ失敗したのかを解明しようとするオプションがあります。
Llama 2に関して良いニュースは、私たちが手間をかけて変換プロセスを行い、これらのいずれの方法でも変換が機能するということです。悪いニュースは、リリース時に変換に失敗し、サポートするために修正を行ったことです。付録では、何が起こったのかを簡単に見て、問題が発生した場合の対処方法の一端をご紹介します。
重要な教訓
私は最近のモデル(Llama 2、Falcon、StarCoder)の変換プロセスを追い、それをexportersとtransformers-to-coreml Spaceの両方に適用しました。以下はいくつかの要点の要約です:
coremltoolsを使用する場合は、最新バージョンの7.0b1を使用してください。テクニカルにはベータ版であるにもかかわらず、私は数週間使用しており、非常に優れています:安定しており、多くの修正が含まれ、PyTorch 2をサポートし、高度な量子化ツールなどの新機能も備えています。exportersは、テキスト生成タスクの変換時に出力にsoftmaxを適用しなくなりました。これは一部の生成アルゴリズムに必要だと気づきました。exportersは、テキストモデルのために固定されたシーケンス長を使用するように変更されました。Core MLには、「柔軟な形状」という方法があり、入力シーケンスの長さを1から4096トークンの範囲で指定できます。柔軟な入力はCPUでのみ実行されることがわかりましたが、GPUやニューラルエンジンでは実行されません。近々詳しく調査します!
同じ問題を繰り返さないように、ベストプラクティスをツールに追加していきます。
最適化
ターゲットハードウェア上で高速に実行され、システムリソースを尊重することができない場合、モデルを変換する意味はありません。この記事で言及されているモデルは、ローカルでの使用にはかなり大きいですし、現在の技術の限界を引き伸ばすために意図的に使用されています。
私たちはいくつかの主要な最適化領域を特定しています。これらは私たちと現在進行中の取り組みの非常に重要なトピックです。いくつかの例を挙げると:
- トランスフォーマーモデルがPyTorchの実装で行っているように、以前の世代から注意のキーと値をキャッシュします。注意スコアの計算は、これまでに生成された全シーケンス上で実行する必要がありますが、過去のキーと値のペアはすでに前回の実行で計算されています。現在、Core MLモデルではキャッシュメカニズムを使用していませんが、今後導入する予定です!
- 小さな固定シーケンス長ではなく、離散的な形状を使用します。柔軟な形状を使用しない理由の主な理由は、GPUやニューラルエンジンと互換性がないことです。副次的な理由としては、上記のようなキャッシングの欠如のため、シーケンス長が増えると生成が遅くなることが挙げられます。一連の固定された形状を使用し、キャッシュされたキーと値のペアと組み合わせることで、より大きなコンテキストサイズとより自然なチャット体験を実現できます。
- 量子化技術。私たちはすでにStable Diffusionモデルのコンテキストでそれらを探索しており、それらがもたらすオプションに非常に興奮しています。例えば、6ビットパレット化はモデルサイズを減少させ、リソースと効率的です。新しい技術であるMixed-bit量子化は、モデルの品質に低い影響を与えながら(平均して)4ビットの量子化を実現できます。これらのトピックについても、言語モデルに取り組む予定です!
本番アプリケーションでは、特に開発中は小さなモデルで反復処理を行い、最小のモデルを選択するための最適化技術を適用することを検討してください。
swift-transformers
swift-transformersは、Swift開発者にtransformersのようなAPIを提供することを目指して進行中のSwiftパッケージです。それが持っているものと欠けているものを見てみましょう。
Tokenizers
トークン化は、テキスト入力をモデルが使用するテンソル形式に適応し、モデルの結果をテキストに変換する2つの補完的なタスクを解決します。例えば、次のようなニュアンスのある処理があります。
- 単語、文字、文字グループ、バイトを使用しますか?
- 大文字と小文字の違いはどのように扱うべきですか?違いを扱うべきですか?
- スペースなどの繰り返し文字を削除するべきですか、重要ですか?
- モデルの語彙に存在しない単語はどのように扱うべきですか?
いくつかの一般的なトークン化アルゴリズムと、モデルを効果的に使用するために重要な多くの異なる正規化および前処理手順があります。transformersライブラリは、これらのすべての操作を同じライブラリ(tokenizers)で抽象化し、モデルと一緒にHubに格納された設定ファイルとして表現します。たとえば、これはLlama 2のトークナイザの設定の一部分を記述した抜粋です。
"normalizer": {
"type": "Sequence",
"normalizers": [
{
"type": "Prepend",
"prepend": "▁"
},
{
"type": "Replace",
"pattern": {
"String": " "
},
"content": "▁"
}
]
},これは次のように読み取られます:正規化は順番に適用される操作のシーケンスです。最初に、入力文字列に_文字をPrependします。次に、すべてのスペースを_に置き換えます。潜在的な操作の膨大なリストがあり、正規表現の一致に適用でき、非常に特定の順序で実行する必要があります。tokenizersライブラリのコードは、Hub内のすべてのモデルのこれらの詳細に対応します。
それに対して、Swiftアプリなど他のドメインで言語モデルを使用するプロジェクトでは、通常、これらの決定をアプリのソースコードの一部としてハードコードします。これは数個のモデルに対しては問題ありませんが、異なるモデルに置き換えるのは難しく、間違いを起こしやすいです。
私たちがswift-transformersで行っているのは、これらの抽象化をSwiftで再現し、一度書けば誰でもアプリで使用できるようにすることです。まだ始めたばかりなので、カバレッジはまだ小さくなっています。リポジトリで問題を開いたり、独自の貢献を行ったりしてください!
具体的には、現在はBPE(Byte-Pair Encoding)トークナイザのみをサポートしています。これは現在使用されている3つの主要なファミリーのうちの1つです。GPTモデル、Falcon、およびLlamaはすべてこのメソッドを使用しています。UnigramおよびWordPieceトークナイザのサポートは後ほど追加される予定です。すべての可能な正規化、プリトークナイザ、およびポストプロセッサを移植しているわけではありません。Llama 2、Falcon、およびGPTモデルの変換中に遭遇したものだけです。
SwiftでTokenizersモジュールを使用する方法は次のとおりです。
import Tokenizers
func testTokenizer() async throws {
let tokenizer = try await AutoTokenizer.from(pretrained: "pcuenq/Llama-2-7b-chat-coreml")
let inputIds = tokenizer("Today she took a train to the West")
assert(inputIds == [1, 20628, 1183, 3614, 263, 7945, 304, 278, 3122])
}ただし、通常は入力テキストを自分でトークン化する必要はありません。テキストの生成コードがそれを処理します。
Model and Hubラッパー
上記で説明したように、transformersはHubに格納された設定ファイルを大量に使用しています。私たちはHubから設定ファイルをダウンロードするために簡単なHubモジュールを用意しました。これはトークナイザをインスタンス化し、モデルに関するメタデータを取得するために使用されます。
モデルに関しては、テキスト生成タスクに焦点を当てたCore MLモデルのラッパーとして単純なLanguageModelタイプを作成しました。プロトコルを使用することで、同じAPIで任意のモデルをクエリできます。
適切なメタデータを取得するために、swift-transformersは変換時にCore MLファイルに追加する必要のあるいくつかのカスタムメタデータフィールドに依存しています。 swift-transformersは、この情報を使用してHubから必要なすべての設定ファイルをダウンロードします。これらは、Xcodeのモデルプレビューで示されるように、以下のフィールドを使用しています:

exportersとtransformers-to-coremlは、これらのフィールドを自動的に追加します。ただし、coremltoolsを手動で使用する場合は、自分でこれらを追加するようにしてください。
生成アルゴリズム
言語モデルは、入力シーケンスの続きとして現れる可能性のある次のトークンの確率分布を予測するためにトレーニングされます。応答を作成するためには、特別な終了トークンが生成されるまで、または望む長さに達するまでモデルを複数回呼び出す必要があります。次に使用する最適なトークンを決定する方法はいくつかあります。現在、次の2つをサポートしています:
- グリーディデコーディング。これは明らかなアルゴリズムです:最も高い確率のトークンを選択し、シーケンスに追加して繰り返します。同じ入力シーケンスに対しては常に同じ結果が得られます。
- top-kサンプリング。確率が最も高い
top-k(kはパラメータ)のトークンを選択し、temperatureなどのパラメータを使用してそれらからランダムにサンプリングします。これにより、モデルがオフトピックに逸れたり、内容を見失ったりする可能性はありますが、変動性が増します。
「核サンプリング」という追加の手法も後で登場する予定です。生成手法とその動作についての優れた概要については、このブログ記事(最新版)をお勧めします。アシストされた生成などの高度な手法は最適化に非常に役立つ場合もあります!
サポートされているモデル
これまでに、swift-transformersは主な設計上の決定を検証するためにいくつかのモデルでテストを行ってきました。さらに多くのモデルを試すことを楽しみにしています!
- Llama 2.
- Falcon.
- GPTアーキテクチャのバリアントを基にしたStarCoderモデル。
- GPTファミリー(GPT2、distilgpt、GPT-NeoX、GPT-Jを含む)。
swift-chat
swift-chatは、swift-transformersを使用する方法を示すためのシンプルなデモアプリです。主な目的は、コードでswift-transformersを使用する方法を示すことですが、モデルのテストツールとしても使用できます。
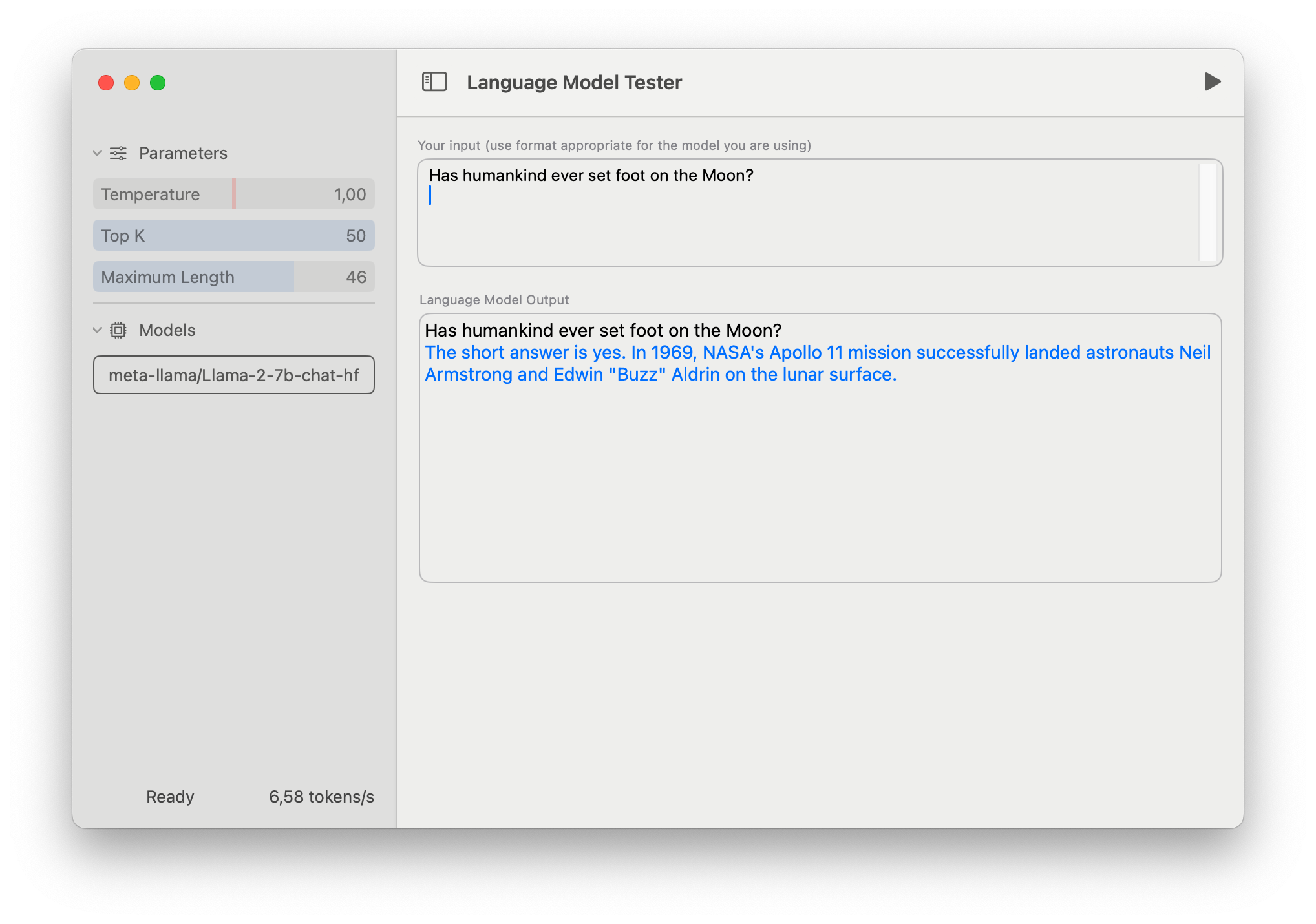
使用するには、HubからCore MLモデルをダウンロードするか、独自のモデルを作成し、UIから選択します。関連するモデルの設定ファイルは、メタデータ情報を使用して識別されます。
新しいモデルを初めて読み込む場合、準備には時間がかかります。このフェーズでは、CoreMLフレームワークがモデルをコンパイルし、マシンの仕様とモデルの構造に基づいて実行するための計算デバイスを決定します。この情報はキャッシュされ、将来の実行でも再利用されます。
このアプリはわかりやすく簡潔にするために意図的にシンプルになっています。また、現在のモデルコンテキストのサイズの制限のため、いくつかの機能が欠けています。たとえば、「システムプロンプト」は、言語モデルの動作やパーソナリティを指定するのに便利ですが、このアプリにはそのような機能はありません。
不足している部分/次に来るもの
述べたように、私たちはまだ始めたばかりです!次の優先事項には以下があります:
- T5やFlanなどのエンコーダー・デコーダーモデル。
- より多くのトークナイザー:UnigramとWordPieceのサポート。
- 追加の生成アルゴリズム。
- 最適化のためのキーバリューキャッシュのサポート。
- 変換用の離散的なシーケンス形状の使用。キーバリューキャッシュとともに、より大きなコンテキストが可能になります。
次に取り組むべき課題についてご意見をお聞かせください。または、Good First Issuesのリポジトリにアクセスして手を試してみてください!
結論
Swift開発者がアプリに言語モデルを組み込むためのツールセットを紹介しました。あなたがそれらを使って何を作るか楽しみにしていますし、コミュニティの助けを得て改善することも楽しみにしています!お気軽にご連絡ください 🙂
付録:Llama 2の困難な変換
Core MLの変換に問題があり、戦いに備えている場合を除き、このセクションは無視しても安全です 🙂
私の経験では、coremltoolsを使用してPyTorchモデルをCore MLに変換できない理由は主に2つあります:
- サポートされていないPyTorchの操作または操作のバリエーション
PyTorchには多くの操作があり、それらすべては中間表現(Model Intermediate LanguageのMIL)にマップされ、さらにネイティブのCore ML命令に変換される必要があります。PyTorchの操作のセットは静的ではないため、新しい操作をcoremltoolsに追加する必要があります。さらに、一部の操作は非常に複雑で、引数の異なる組み合わせで動作することがあります。PyTorch 2で導入された、非常に複雑な操作であるスケーリングされたドット積注意は最近追加された例です。部分的にサポートされている操作の例として、einsumがあります:すべての可能な方程式がMILに変換されるわけではありません。
- 特殊なケースと型の不一致
サポートされているPyTorchの操作でも、異なる入力タイプや異なるデバイス(CPU、CUDA)への複数のバックエンド実装、精度(float16、float32)など、すべての可能な入力に対して変換プロセスが正常に機能することは非常に困難です。すべての組み合わせの積は膨大であり、モデルがPyTorchコードを使用する方法によっては、考慮されていなかったりテストされていなかったりする変換パスがトリガーされることもあります。
私が最初にcoremltoolsを使用してLlama 2を変換しようとしたときに起こったのは次の通りです:
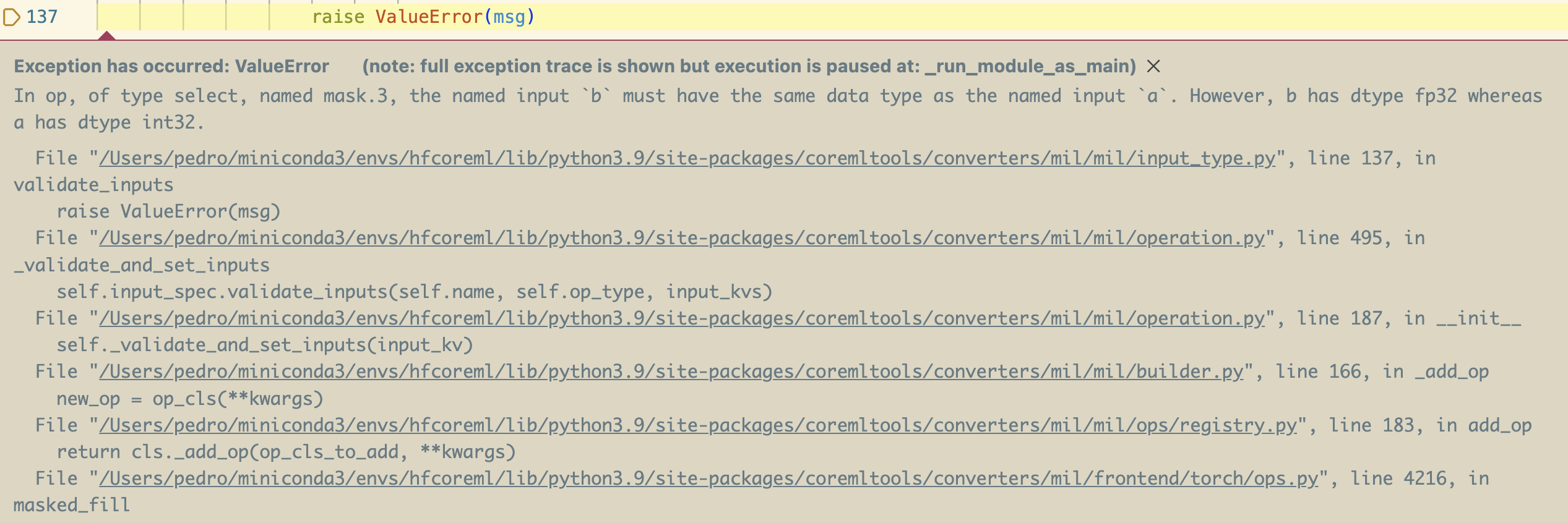
異なるtransformersのバージョンを比較することで、このコード行が導入されたときに問題が発生することがわかりました。これは、これらを使用するすべてのモデルにおいて因果マスクをよりよく処理するための最近のtransformersのリファクタリングの一部ですので、これはLlamaだけでなく他のモデルにとっても大きな問題になります。
エラースクリーンショットが示しているのは、マスクテンソルを埋める際に型の不一致があることです。これは行の0から来ており、それがintと解釈される一方、埋めるべきテンソルはfloatsを含んでいるため、異なる型の使用は変換プロセスによって拒否されました。この特定のケースでは、私はcoremltoolsのためのパッチを考え出しましたが、幸いにもこれはほとんど必要ありません。多くの場合、コードを修正(transformersのローカルコピーでの0.0を使用することで解決できたでしょう)するか、例外的なケースを処理するために「特別な操作」を作成することができます。私たちのexportersライブラリは、カスタムの特別な操作に非常に良いサポートを提供しています。この例では、einsum方程式の不足に対する対応策を、この例ではStarCoderモデルが新しいバージョンのcoremltoolsがリリースされるまで動作するための回避策を示しています。
幸いにも、新しい操作に対するcoremltoolsのカバレッジは良好であり、チームの対応も非常に速いです。
リソース
swift-transformers。swift-chat。exporters。transformers-to-coreml。- テキスト生成のためのいくつかのCore MLモデル:
- Llama-2-7b-chat-coreml
- Falcon-7b-instruct
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles






