RedPajamaプロジェクト:LLMの民主化を目指すオープンソースイニシアチブ
RedPajama Project Open Source Initiative aiming for the democratization of LLM.

近年、Large Language Models (LLM)が主流となっています。ChatGPTの登場により、テキスト生成モデルを誰でも利用できるようになりました。しかし、多くの強力なモデルは商用でしか利用できないため、多くの研究やカスタマイズが制限されています。
もちろん、現在オープンソースでLLMを公開しようとするプロジェクトが多数存在しています。例えば、Pythia、Dolly、DLiteなどがあります。しかし、なぜLLMをオープンソースにする必要があるのでしょうか。それは、閉鎖モデルが持つ制限を克服するために、コミュニティの感情がこれらのプロジェクトを推進したからです。しかし、オープンソースのモデルは閉鎖モデルに比べて劣るのでしょうか。もちろん、そうではありません。多くのモデルが商用モデルに匹敵し、多くの分野で有望な結果を示しています。
この動きに続いて、LLMを民主化するためのオープンソースプロジェクトの1つであるRedPajamaがあります。このプロジェクトは、Ontocord.ai、ETH DS3Lab、Stanford CRFM、Hazy Researchの共同プロジェクトであり、再現可能なオープンソースのLLMを開発することを目的としています。RedPajamaプロジェクトには、以下の3つのマイルストーンが含まれています。
- Gorillaに会ってください:UCバークレーとMicrosoftのAPI拡張LLMは、GPT-4、Chat-GPT、およびClaudeを上回ります
- FLOPsとMACsを使用して、Deep Learningモデルの計算効率を計算する
- AIの変革の道:OpenAIのGPT-4を通してのオデッセイ
- Pre-training data
- Base models
- Instruction tuning data and models
この記事が書かれた時点で、RedPajamaプロジェクトは、ベース、インストラクト、チャットバージョンを含む、事前学習データとモデルを開発していました。
RedPajama
RedPajamaは、Ontocord.ai、ETH DS3Lab、Stanford CRFM、Hazy Researchの共同プロジェクトであり、再現可能なオープンソースのLLMを開発することを目的としています。RedPajamaプロジェクトには、以下の3つのマイルストーンが含まれています。
- Pre-training data
- Base models
- Instruction tuning data and models
この記事が書かれた時点で、RedPajamaプロジェクトは、ベース、インストラクト、チャットバージョンを含む、事前学習データとモデルを開発していました。
RedPajama Pre-Trained Data
最初のステップでは、RedPajamaは、半オープンなモデルのLLaMaデータセットを複製しようとしています。これは、RedPajamaが1兆2000億のトークンを持つ事前学習データを構築し、コミュニティに完全オープンソースで提供することを意味します。現時点では、完全なデータとサンプルデータはHuggingFaceでダウンロードできます。
RedPajamaデータセットのデータソースは、以下の表でまとめられています。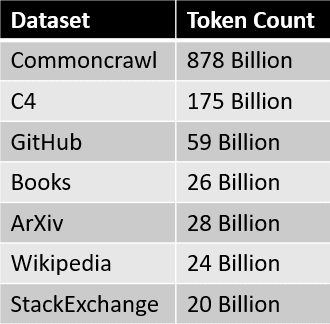 各データスライスは注意深く前処理とフィルタリングが行われ、トークン数もLLaMaの論文で報告された数にほぼ一致しています。
各データスライスは注意深く前処理とフィルタリングが行われ、トークン数もLLaMaの論文で報告された数にほぼ一致しています。
データセット作成後の次のステップは、ベースモデルの開発です。
RedPajama Models
RedPajamaデータセットの作成後の数週間で、データセット上で最初のモデルがリリースされました。ベースモデルには、30億パラメータモデルと70億パラメータモデルの2つのバージョンがあります。RedPajamaプロジェクトは、それぞれのベースモデルに対して2つのバリエーションをリリースしています。インストラクションチューニングモデルとチャットモデルです。
各モデルの概要は、以下の表で確認できます。
上記のモデルには、以下のリンクからアクセスできます。
- RedPajama-INCITE-Base-3B-v1
- RedPajama-INCITE-Chat-3B-v1
- RedPajama-INCITE-Instruct-3B-v1
- RedPajama-INCITE-Base-7B-v0.1
- RedPajama-INCITE-Chat-7B-v0.1
- RedPajama-INCITE-Instruct-7B-v0.1
例えば、HuggingFaceから適応したコードでRedPajamaベースモデルを試してみましょう。
import torch
import transformers
from transformers import AutoTokenizer, AutoModelForCausalLM
# init
tokenizer = AutoTokenizer.from_pretrained(
"togethercomputer/RedPajama-INCITE-Base-3B-v1"
)
model = AutoModelForCausalLM.from_pretrained(
"togethercomputer/RedPajama-INCITE-Base-3B-v1", torch_dtype=torch.bfloat16
)
# infer
prompt = "Mother Teresa is"
inputs = tokenizer(prompt, return_tensors="pt").to(model.device)
input_length = inputs.input_ids.shape[1]
outputs = model.generate(
**inputs,
max_new_tokens=128,
do_sample=True,
temperature=0.7,
top_p=0.7,
top_k=50,
return_dict_in_generate=True
)
token = outputs.sequences[0, input_length:]
output_str = tokenizer.decode(token)
print(output_str)
a Catholic saint and is known for her work with the poor and dying in Calcutta, India.
Born in Skopje, Macedonia, in 1910, she was the youngest of thirteen children. Her parents died when she was only eight years old, and she was raised by her older brother, who was a priest.
In 1928, she entered the Order of the Sisters of Loreto in Ireland. She became a teacher and then a nun, and she devoted herself to caring for the poor and sick.
She was known for her work with the poor and dying in Calcutta, India.3Bベースモデルの結果は有望であり、7Bベースモデルを使用するとさらに良くなる可能性があります。開発はまだ進行中であり、将来的にプロジェクトにはさらに良いモデルがあるかもしれません。
結論
生成AIは台頭していますが、残念ながら多くの優れたモデルは企業のアーカイブの中に閉じ込められています。RedPajamaは、半オープンのLLaMAモデルを複製してLLMを民主化しようとする主要なプロジェクトの1つです。RedPajamaは、LLamaに類似したデータセットを開発し、多くのオープンソースプロジェクトが使用しているオープンソースの1.2兆トークンのデータセットを作成することに成功しました。
RedPajamaは、3Bおよび7Bパラメータベースモデルの2種類のモデルもリリースしており、それぞれのベースモデルには、指示チューニングモデルとチャットモデルが含まれています。Cornellius Yudha Wijayaは、データサイエンスアシスタントマネージャー兼データライターです。Allianz Indonesiaでフルタイムで働きながら、彼はソーシャルメディアやライティングメディアを通じてPythonやデータのヒントを共有することが大好きです。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles