「教師付き機械学習と集合論を通じた現実世界の時系列異常検出」
Real-world time series anomaly detection through supervised machine learning and set theory
シアトルバーク・ギルマン・トレイル
シアトル市のオープンデータを探索する
目次:
I. 問題の設定
- 「Tabnine」は、ベータ版のエンタープライズグレードのコード中心のチャットアプリケーション「Tabnine Chat」を導入しましたこれにより、開発者は自然言語を使用してTabnineのAIモデルと対話することができます
- 効率化の解除:Amazon SageMaker Pipelinesでの選択的な実行の活用
- 「AIプロジェクトはどのように異なるのか」
II. 時系列データの監視型問題へのリモデリング
III. 監視型モデリングと分析
I. 問題の設定
データはこちらからダウンロードできます: シアトルバーク・ギルマン・トレイル | Kaggle
この問題の本質は、3時間後にトレイル上の総人数が500人を超える異常を検出する必要があるということです。異常は、ペデストリアンと自転車のトレイルの1時間ごとのデータが与えられているため、解決するためには3時間後のデータを予測する必要があります。
II. 時系列データの監視型問題へのリモデリング
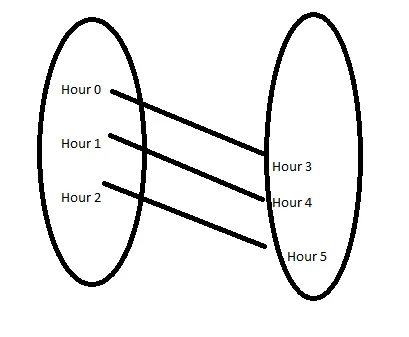
では、データの2つのコピーを作成し、データを結合して、0時のデータが同じ行の3時にマッピングされるようにすることができます。
これはどのように行われるのでしょうか。
まず、データを取り込みます:
import pandas as pddf = pd.read_csv(r’/content/burke-gilman-trail-north-of-ne-70th-st-bike-and-ped-counter.csv’)次に:
# dfをdataframeに変更df = pd.DataFrame(df)
df = df.fillna(0)これを行った後、4行目から始まるデータのコピーを作成します:
# 4行目から始まるdf2を作成df2 = df[df.index >= 3]df2.head()次に、両方のデータフレームに1から始まるインデックス列を追加します:
# df1とdf2の両方に番号の列を追加します。最初の行は1、2番目の行は2、以降の行も同様ですdf['index'] = list(range(1, len(df) + 1))df2['index'] = list(range(1, len(df2) + 1))これを行う理由は、インデックス列で結合するためです。インデックス1はdf2のインデックス1に結合されますが、その行では左側には0時、右側には3時が表示されます…
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- 「Embroid」を紹介します:複数の小さなモデルから埋め込み情報を組み合わせるAIメソッドで、監視なしでLLMの予測を自動的に修正することができます
- 「ONNXフレームワークによるモデルの相互運用性と効率の向上」
- トムソン・ロイターが6週間以内に開発したエンタープライズグレードの大規模言語モデルプレイグラウンド、Open Arena
- Amazon SageMakerを使用して、オーバーヘッドイメージで自己教師ありビジョン変換モデルをトレーニングする
- MLOpsとは何ですか
- LangChain チートシート
- マイクロソフトは、エンタープライズ向けにカスタマイズされたAzure ChatGPTを発表しました






