電車利用者のためのリアルタイム混雑予測
Real-time congestion prediction for train users.
サーバーレスAzureテクノロジーを使用して、旅行プランナーアプリにストリーミング予測を提供する
Wessel Radstokと共に

オランダの鉄道利用者は、オランダの鉄道機関のアプリを使用して旅行を計画することができます。旅行を計画する際、アプリは対象の列車の混雑具合の予測を表示します。これは、低い占有率、VoAGI、または高いという3つのカテゴリとして表示されます。旅行者は、この情報を使用して、少し混雑していない他の列車を利用するかどうかを決めることができます。
これらの予測はバッチプロセスで実行されます。機械学習モデルは定期的に過去のデータでトレーニングされ、毎朝列車の混雑具合を予測するためのプロセスが実行されます。これは、予想される乗客数を予測し、ルートに予定されている列車の容量と組み合わせることによって行われます。
しかし、日中には列車がキャンセルされたり、迂回されたりする事故が発生することがあります。また、ダブルデッカー列車が予定されているが、シングルデッカー列車しか利用できない場合もあります。その結果、旅行者は古い混雑情報を見ることになります。出発する列車の約20%が出発日に容量が変更され、しばしば出発直前に変更されます。
- ウェブコンテンツの選択肢と制御を進化させるための原則に基づいたアプローチ
- 以下がSteamサマーセールのゲームをGeForce NOWでストリーミングする方法です
- 「私のお気に入りの3Dアプリ」:Blenderファンが今週「NVIDIA Studio」で彼の日本インスパイアされたシーンを共有
このブログでは、ルートの予定された列車の長さと種類に関するリアルタイム情報を取得し、アプリ内の予想される混雑度を更新するストリーミングパイプラインの構築方法について説明します。私たちはLambdaアーキテクチャに従っており、夜間の予測がバッチレイヤーを実装し、更新プロセスがストリーミングレイヤーを実装しています。このパイプラインは現在、オランダのアプリを使用しているすべての列車利用者に、旅行の予想される混雑具合についてよりリアルタイムなビューを提供しています。
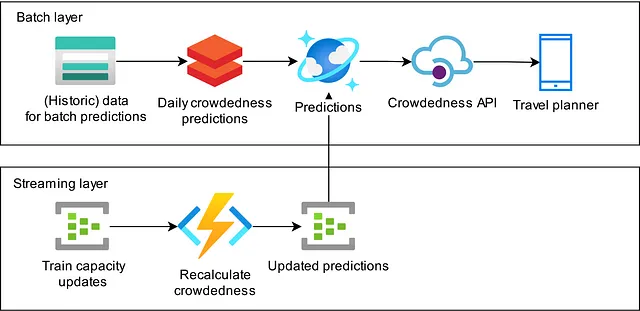
このアーキテクチャを実装するために私たちが取ったアプローチについて説明します。最初の実装はSpark Structured Streamingを使用して行われ、私たちの期待に沿わなかったため、異なるアプローチを取ることにしました。私たちが話し合う経験に基づいて、Azureクラウドのサーバーレスリソースを使用することにしました。
最初の試み:Spark Structured Streaming
私たちの毎日の混雑予測は、データ処理にSparkを使用してDatabricksで実行されます。Sparkはストリーミングデータ処理をサポートしているため、予測のリアルタイム更新をSpark Structured Streamingで実装するのは論理的な選択です。この決定により、既に利用可能なプラットフォームを使用して、既に経験があるDataFrameパラダイムを使用してロジックを実装することができました。
私たちは、ストリーミングジョブを起動するための小さなノートブックと、必要なロジックを含むカスタムPythonパッケージを持つ一貫したSpark Structured Streaming実装を開始しました。
開発プロセス中に、Structured Streamingを使用したプログラミングについていくつかのことを学びました。まず、SQL DataFramesとStructured Streaming DataFramesのプログラミングインターフェースは同じではありません。Structured Streamingはできることに制限が多く、バッチモデルをそのままストリーミング形式で実装することはできなかったため、何度かアルゴリズムを見直してうまく動作させる必要がありました。Structured Streamingインターフェースの限られた表現力は、読みづらいコードを生み出し、保守が困難になるため、メンテナンスが難しいコードになりました。
これの単純な例は、時間ウィンドウに基づいて2つのデータストリームで外部結合を実行したいということです。ただし、Spark Structured Streamingでは、結合条件に等価性が必要であり、同じデータを持つ2つの列がありませんでした。等価性のために同じ値を持つ2つのリテラルフィールドを2つのストリームに追加してみたが、Sparkはそんなに簡単にはだまされない。私たちは結局、「千年」というフィールドを作成することになりました。なぜなら、私たちのタイムスタンプはすべて3千年目にあるからです。それはうまくいったが、本質的に「Y3K」バグを作り出したことになる。
さらに、異なるモデルの異なる部分に異なる時間制約があったため、アルゴリズムを別々のステップに分割する必要がありましたが、これを1つのStructured Streamingジョブに実装することはできませんでした。私たちはモデルをいくつかのパートに分割し、その間に持続的なストレージレイヤーとしてAzure Event Hubsを使用して結合しました。これにより、処理の各パートに明確な目標があり、個別にテストすることができました。
私たちは2つの方法でフローをテストしました。ユニットテストでは、ストリーミングロジックを単純なバッチSpark SQL DataFramesに供給してテストしました。これにより、ストリーミングフローの一部を実際にストリーミングジョブを開始せずにテストすることができます。このアプローチは多くの機能要件を捉えていますが、タイミングの問題は捉えられません。2番目のテストステップでは、Spark Structured Streamingメモリシンクを使用してクエリをストリーミングモードで実行し、タイミングの効果も捉えることができます。
最終的に、コードをデプロイし、クラウドの請求額が大幅に増加するのを目にしました。これには2つの理由があります。まず、Databricksはバッチ分析ジョブには優れたソリューションですが、ストリーミングジョブを連続して実行し続けるのは高価です。第二に、私たちの雇用主の情報セキュリティポリシーでは、データアクセスをログに記録する必要があります。Structured Streamingのステートストアにはデータが含まれるため、これも記録する必要がありました。ただし、ステートストアは非常に頻繁に更新され、多くの小さなファイルが含まれているため、キャプチャするのに莫大なログセットが生成されます。
最終的に、私たちはこのアプローチを断念することにしました。私たちが取り組んでいる問題に対してクラウドのコストが高すぎました。また、Spark Structured Streamingの表現力が限られているため、モデルの実装を理解し、メンテナンスするのが非常に困難であるという事実もあり、このアプローチを改善するためにさらに投資することはしたくありませんでした。代わりに、別の方法でこれに取り組むことができるかどうかを見てみることにしました。
サーバーレステクノロジーを使用した再設計
フローの多くの部分でステートが必要ではないことに注目し、各メッセージを個別に処理できるようにAzure Functionsをコンピュートプラットフォームとして使用するシステムに行き着きました。ステートが必要な場合は、Stream Analyticsを使用します。これにより、メッセージを比較したり、メッセージを再生したり、別のストリームと結合したりすることができます。補助データへの高速アクセスを可能にするために、Cosmos Databaseを使用しています。すべての部分を結び付けるために、まだAzure Event Hubsを使用しています。

Azure Functions
Azure Functionsは、イベントストリームに操作を適用するための簡単な方法です。ストリーム内の各イベントごとに個別に呼び出されるため、ビジネスロジックを理解するのは簡単です。Pythonのネイティブサポートを備えているため、メンテナブルな操作を簡単に記述することができます。プラットフォームがすべてのクラウド接続のボイラープレートを管理しているため、ローカルでの開発とテストが容易です。私たちはフローのさまざまな部分でそれらを使用しています:
- 一部の関数は単純に受信メッセージをフィルタリングし、後続のステップの計算負荷を減らし、容量とコストを削減します。
- いくつかの関数は、たとえばCosmos DBで利用可能な他のデータソースと結合することでメッセージを豊かにします。
- 他の関数は、メッセージを1つの形式から別の形式に変換します。
- 最後に、Azure Functionsを使用してバッチレイヤーからストリーミングレイヤーにデータを取り込みます。
フィルタリング、エンリッチメント、および変換
これらのステップを実行する関数は、簡単なPythonコードです。例として、フィルタリング関数の主要な部分はわずか数行です:
def main(event: func.EventHubEvent, evh: func.Out[bytes]) -> None: """ ストリーミングフローに関連するメッセージのみを送信するためのフィルタリング関数です。 """ message = json.loads(event.get_body().decode("utf-8")) if _is_ns_operator(message): message = _remove_keys(message) message = _add_build_id(message) evh.set(str.encode(json.dumps(message)))リスト1:メッセージをフィルタリングおよび変換するための例となるAzure関数コード。
ここでは、各メッセージを取り、当社が運行する電車に関連するメッセージのみをフィルタリングし、メッセージに興味のないデータフィールド(キー)を削除します。最後に、デバッグ目的でトレース情報を持つためにビルドIDメタデータをメッセージに追加します。興味のある読者のために、JSON文字列はstr.encode()を使用してBytesオブジェクトとしてエンコードされます。通常の文字列がイベントハブに送信されると、自動的に整形されるため、メッセージに多くの余分なスペースが導入されます。Bytesオブジェクトは変更されずに送信されます。
高速なCosmosデータベースへのデータ取り込み
電車の混雑度を再計算するためには、電車の予測旅行者数、新しい車両の容量、および低、VoAGI、高分類の境界値へのクイックアクセスが必要です。このデータは、バッチプロセスの一環として毎日生成され、パーケット形式でデータレイクに書き込まれます。再計算アクションごとにデータレイクからこのデータを読み込むことは速度が遅すぎます。Azure Cosmosデータベースのキーバリューストアを利用して、Azure Functionsが電車の混雑度を再計算するために必要な静的データを低遅延で利用できるようにします。
理想的なシナリオは、夜間のバッチプロセスからデータの取り込みをトリガーし、取り込みが成功または失敗したかどうかも受け取ることです。また、取り込みプロセスはAzure Data Factoryのコピー活動のサポートが削除された複雑な型のパーケットファイルを読み込む必要もあります。解決策として、Azure Durable Functionsを利用しました。これは、状態を持つ長時間実行される関数を実現する、標準のAzure Functionsプラットフォームの拡張です。具体的には、durable functionsはWebhookをサポートしており、取り込みがオーケストレーターに成功したかどうかを通信することができます。
次に、取り込みは次のように動作します。夜間のバッチプロセスが耐久性のある関数をトリガーします。この耐久性のある関数は、取り込む必要があるデータソースに対して正しいアクティビティ関数を選択し、利用可能な各パーケットファイルに対してこのアクティビティをトリガーします。次に、各ファイルをpandasを使用して読み込み、いくつかのシンプルな変換を行い、レコードをCosmosデータベースに一括挿入します。耐久性のある関数は、自動的に失敗を追跡し、その関数を再試行します。
Azure Stream Analytics
Azure Functionsでは簡単に実行できない操作もあります。これは主に状態を持つ操作や、時間ウィンドウを経てメッセージを結合する操作に当てはまります。
私たちの毎日の混雑予測は、予測が即座に計算されないバッチプロセスで行われます。時間がかかり、その間に新しい電車の容量の更新が発生するかもしれません。それが起こった場合、混雑度を2回更新したいと考えています。最初に、最新の前回の予測に対して、次に新しい予測が利用可能になったときに更新します。ここで、Azure Stream Analyticsを使用して、更新メッセージの状態を保持し、新しいバッチ予測が利用可能になったときに特定のタイムスタンプから再生します。
Azure Stream AnalyticsクエリはSQL方言で記述されます。変換の実装は比較的簡単です。ただし、メッセージのスループットが高い場合には注意が必要です。私たちの場合、直接的な実装では入力ストリームに追いつけず、ストリームアナリティクスクエリが容易に並列方式で実行できるようにする必要がありました。
並列クエリにはいくつかの要件と制限があります。パーティション化されたデータを処理する必要があり、パーティション内で含まれる状態を持つ操作(例:結合)を実行する必要があります。つまり、2つのEvent Hubストリームを結合する場合、それらは同じ数のパーティションを持っている必要があり、最初のEvent Hubのパーティション1のデータは、2番目のEvent Hubのパーティション1のデータとのみ結合できます。
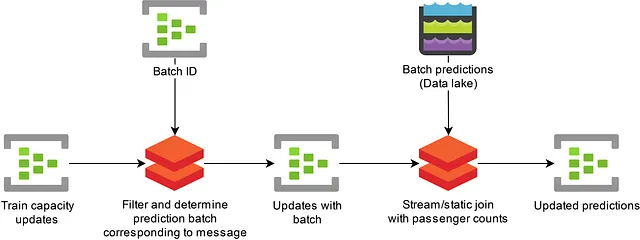
これを解決するために、データの一部を複数のEvent Hubパーティションに複製し、基本的にブロードキャスト結合操作を実装します。次のクエリでこれを説明します。ここでは、各混雑予測にバッチIDとバッチ開始時間が与えられ、どの列車容量更新メッセージがどの予測に適用されるかを決定するために使用されます。メッセージは、新しい予測セットの計算中に到着した場合、複数の予測に適用される場合があります。この場合、複数のメッセージが出力されます。各バッチIDは、複数のEvent Hubパーティションに複製されます。
SELECT batchid.batch_id, batchid.batch_start_time, event.message, event.message_timestamp INTO [Target]
FROM [SourceData] event TIMESTAMP BY event.message_timestamp PARTITION BY PartitionId
JOIN [BatchId] batchid TIMESTAMP BY batchid.EventEnqueuedUtcTime PARTITION BY PartitionId ON
-- メッセージよりもバッチIDメッセージが受信された場合は結合する(正のDATEDIFF)
-- メッセージよりもバッチIDメッセージが受信された場合は再生する(負のDATEDIFF)
-- メッセージがバッチの開始時間よりも後にエンキューされた場合のみ
-- バッチの再処理を高速化するため、バッチに対して有効でなくなったメッセージは破棄する
DATEDIFF(HOUR, batchid, event) BETWEEN -24 AND 24
AND CAST(batchid.batch_start_time AS datetime) <= CAST(event.message_timestamp AS datetime)
AND CAST(event.message.valid_until AS datetime) >= CAST(batchid.batch_start_time AS datetime)
AND event.PartitionId = batchid.PartitionIdリスト2:各メッセージに予測用の対応するバッチIDを追加するAzure Stream Analyticsのクエリの例。
エンドツーエンドの統合テスト
プロジェクトの初めのコミットから、ストリーミングフローに対して自動化されたエンドツーエンドの統合テストを実施することを決定しました。このテストは、エントリーイベントハブにサンプルメッセージを生成してシードし、出力イベントハブで作成されたメッセージを検証する形で行いました。また、この統合テストフローにはCosmosデータベースの取り込みも含まれています。これらのテストを継続的デプロイメントの一部とすることで、フロー内のコンポーネントの数が増え、それに伴い複雑さが増す中での変更時に大きな信頼性を得ることができました。
結論と重要な学び
列車のサービス変更が発生する場合でも、私たちの列車の利用者に最新の混雑状況の洞察を提供するため、私たちはラムダアーキテクチャを採用し、列車の収容力が変化した場合に私たちの予測を更新するようにしました。
Spark Structured Streamingを使用した最初の実装は期待通りのパフォーマンスを発揮せず、Azure Event Hubs、Azure Functions、Azure Stream Analytics、Azure Cosmos DBを使用したサーバーレスアーキテクチャに切り替えました。
このアプローチの主な利点は次のとおりです:
- 開発者は制御できます:パフォーマンスが低下するパーツや最も高いコストが発生するパーツが明確です。
- Spark Structured Streamingとは異なり、Azure Functionsの純粋なPythonコードは読みやすく、保守性があり表現力があります。
- Azure Functionsは状態を持たない操作においては安価です。
- Azure Stream Analyticsは最もコストのかかる部分であり、重要な場面でのみ使用する必要があります(状態を持つ操作や時間ウィンドウの操作)。
- 新しいソリューションにより、クラウドインフラコストを大幅に削減しました。
主なデメリット:
- Azure FunctionsやAzure Cosmos DBなどの分離されたコンポーネントの使用は、デザインが十分に考慮されていない場合に競合状態を引き起こす可能性があります。
- インフラストラクチャの多くのビットと小さなコード片を管理する必要があります。ロジックは一箇所に集中されず、より広範なテストが必要となります。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles






