「読むアバター:リアルな感情制御可能な音声駆動のアバター」
Reading Avatar Emotionally Controllable Voice-Driven Avatar
音声駆動型ディープフェイクへの感情制御の追加
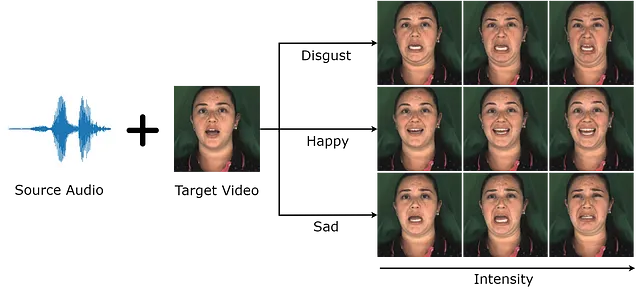
既存の音声駆動型ディープフェイクの重要な制限の一つは、スタイル属性をより制御できる能力が必要であることです。理想的には、生成されたビデオを嬉しいか悲しいかのように変えたり、特定の俳優の話し方を使用したりすることができるようにしたいです。READ Avatarsは、既存の高品質な個人特定モデルを変更し、スタイルに対して直接制御を行うことで、まさにこれを実現しようとしています。
過去にディープフェイクモデルに関するいくつかのブログ投稿を書いてきましたが、この投稿は特別な意味を持っています、なぜならこれは私自身のものだからです。この論文は今年のBMVCに受け入れられたばかりで、私の初めての受け入れられた論文です!この記事では、この研究の動機、直感、および方法論について説明します。
スタイルとは何ですか?
スタイルの制御を考える際に最初に考えるべき場所は、スタイルとは具体的に何を意味するのかを尋ねることです。私が通常答えるのは、少し手抜きかもしれませんが、「スタイルとは、データの中でコンテンツとは見なされないもの全て」ということです。これは単に定義を一つの単語から別の単語に変えるだけのように思えるかもしれませんが、これによりタスクが容易になります。音声駆動型ディープフェイクの文脈では、コンテンツとは音声自体、オーディオに合わせた口の動き、および顔の外見のことを指します。
つまり、スタイルは、同じ人物のままでリップシンクを維持しながらビデオを変更するものです。
私の研究の場合、私は通常、2つの特定のスタイル形式を見ます:感情的なスタイルと個性的なスタイルです。感情的なスタイルは単に顔で表現される感情であり、個性的なスタイルは個々の人々の表現の違いを指します。たとえば、私の顔での笑顔の見え方とあなたの顔での笑顔の見え方は、個性的なスタイルの例です。これらは唯一のスタイルではありませんが、実証しやすく取り扱いやすいものです。この研究では、個人特定モデルに対して感情のスタイルのみを使用しました。
感情のスタイルの表現
READ Avatarsは、音声駆動型ビデオ生成において感情のスタイルを変えることを考えた最初の論文ではありません。ただし、以前の方法では感情をワンホットベクトルまたは抽象的な潜在表現として表現していました(EVPやEAMMなどの例をチェックしてください)。前者は細かい感情の制御に十分な精度を持っておらず、後者は意味を持たないため、私たちは感情の異なる表現方法を使用することにしました。
N個の異なる感情を表すために、私たちはN次元ベクトルを使用し、各次元が1つの感情を表し、0から1の実数値を持つようにします。それぞれの感情の最大表現は1とします。すべてのゼロのベクトルは、感情の欠如(中立)を表します。
基準となるモデル
最高の視覚品質を実現するために、私たちは以前の研究の3DMMベースのアプローチを基にモデルを構築しています。興味があれば、以前の記事でこれらについて説明しています!特に、私たちはユニークな画像対画像のUNETと共に、uvベースの多チャンネルテクスチャをトレーニングするニューラルテクスチャアプローチを使用しています。

感情を扱いたいので、口の領域だけでなく、全体の顔を生成する必要があります。これを実現するためには、上記の画像で見ることができるように、口のマスクを顔全体のマスクに変更するだけです。
単純なアプローチは、オーディオから表情へのネットワークを、先ほど定義した感情コードに依存させることです(オーディオから表情へのネットワークについての詳細は、私の過去の投稿をご覧ください)。しかし、これは期待通りにはうまく機能しません。この理由には、基礎となる3DMMの詳細の不足と、回帰損失による過度の平滑化効果が考えられます。
3DMMの詳細の不足
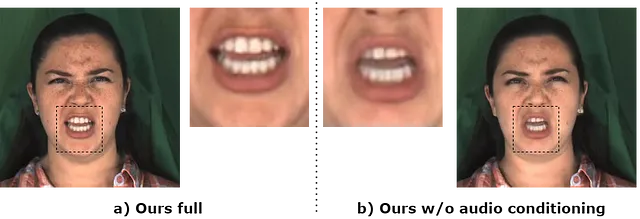
最初の問題は、3DMMが顔の幾何学を表現できないことに関係しています。問題は二重のものです。まず、3DMMは唇の「O」の形状を捉えるのに苦労します。これは下の図で見ることができます。しかし、もっと重要なのは、歯や舌を含む口の内部の表現がまったく存在しないことです。

これにより、画像から画像へのネットワークに渡される描画に曖昧さが生じる可能性があります。たとえば、舌がない場合、音声「UH」と「L」は同じように表現されます。この場合、ネットワークは口の中に何を生成するかをどのように知るのでしょうか?
この問題を解決するために、オーディオをビデオ生成プロセスに直接追加します。これを行うために、オーディオをニューラルテクスチャに条件付けます。Wav2Vec2の中間層を特徴抽出器として使用し、そのオーディオを潜在表現にエンコードします。これを使用して、2D位置符号化を使用するSIRENネットワークを条件付けし、オーディオに変動する16チャンネルのニューラルテクスチャを出力します(下記参照)。アーキテクチャの詳細については、論文のarXivバージョンをご覧ください。

この追加により、画像から画像へのネットワークには、このような曖昧さを解決するための十分な情報が得られるようになります。
回帰損失からの滑らかさ
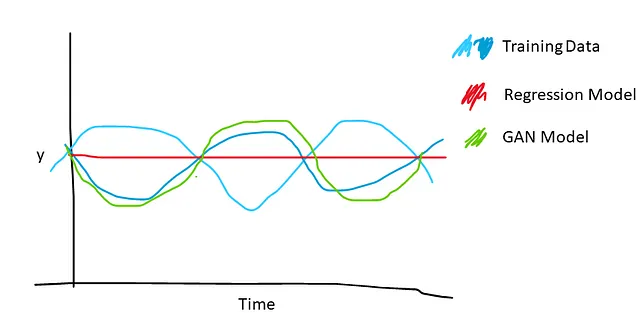
既存の音声から表情へのモデルは、通常L1またはL2の回帰損失で訓練されています。これには、顔のアニメーションには目立つ欠点があります:非常に滑らかな動きが生じます。特定のオーディオに対して有効な2つのシーケンスがある場合、回帰ベースのモデルはその2つの平均を選択し、動きのピークを平均化してミュートな動きを生み出します。これは特に感情表現の生成に重要であり、オーディオと相関しない顔の部分(たとえば、眉毛)はいつでも動く可能性があるため、多くの平滑化と感情の悪い表現につながります。
GANベースのモデルはこれを緩和します。識別器は、滑らかな動きを偽物としてラベル付けすることを学び、したがって、ジェネレータは現実的で生き生きとした動きを生成するように強制されます。
結果
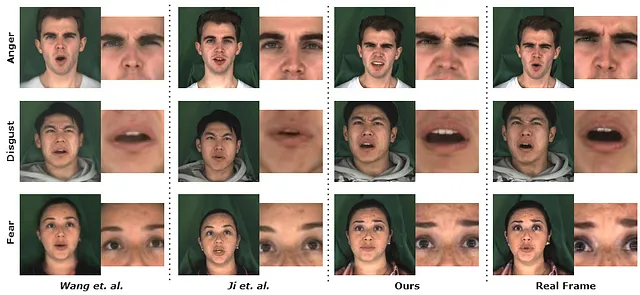
実際に、私たちが提案した修正は結果の改善につながりました。現在の最先端よりも優れた結果を出すことができました。
結論と今後の課題
READ Avatarsは、感情のスタイルを含めた超高品質な3DMMベースのモデルの拡張を可能にするいくつかの重要な修正を行いました。この作業は興味深い結果を生み出します!しかし、明らかな欠点もあります。リップシンクは既存の感情モデルよりも優れていますが、まだ完全な正確さには程遠いです。これは、wav2lipで使用されている専門の判別器の追加や、Imitatorなどのより良い音声から表現へのモデルの使用によって改善できると考えています。
将来的には、個別のスタイルなど、さまざまなスタイルを修正することが有益です。例えば、ジョー・バイデンがドナルド・トランプの口の動きで話すようにすることができます。これは興味深いです!これには、一般化されたニューラルテクスチャモデルを構築する必要があり、これは興味深い研究方向であり、将来の課題となります。
全体的に、これは非常に興味深いプロジェクトであり、私は初めての公開論文を手に入れることに興奮しています。この作業から進む研究に期待しています。いつものように、ご質問やフィードバックがあれば、コメントでお知らせください!
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- デシは、コード生成のためのオープンソース1Bパラメータの大規模言語モデル「DeciCoder」を紹介します
- モデルの精度向上:Spotifyでの機械学習論文で学んだテクニック(+コードスニペット)
- 「勾配降下法アルゴリズムとその直感的な考え方」
- ハギングフェイスがIDEFICSを導入:視覚言語モデルを活用した先駆的なオープンマルチモーダル対話AI
- 画像認識におけるディープラーニング:技術と課題
- 『見て学ぶ小さなロボット:このAIアプローチは、人間のビデオデモンストレーションを使用して、ロボットに汎用的な操作方法を教える』
- 「AudioLDM 2をご紹介します:音声、音楽、効果音を融合した独自の音声生成AIフレームワーク」





