ReAct、Reasoning and Actingは、LLMをツールで拡張します!
ReAct, Reasoning and Acting extend LLM with tools!
はじめに
Reasoning and Actingの略であるこの論文は、LLMsのパフォーマンスを向上させる新しい概念を紹介し、より説明可能性と解釈可能性を提供します。
AGIの目標は、人類の文明が達成する最も重要な目標の一つかもしれません。多くの問題に一般化できる人工知能を作り出すことを想像してみてください。AGIとは何か、それを達成したと言うのはいつなのかについては、さまざまな解釈があります。
- コンピュータビジョンの革新:進歩、課題、そして将来の方向性
- DSPyの内部:知っておく必要のある新しい言語モデルプログラミングフレームワーク
- 「WavJourney:オーディオストーリーライン生成の世界への旅」
ここ数十年で最も有望なAGIの手法は、強化学習のパスであり、具体的にはDeepMindがハードなタスクで達成したAlphaGo、AlphaStarなどのブレイクスルーがありました。
しかし、ReActは、1つまたは2つの文脈に沿った例文だけで促されるにも関わらず、模倣や強化学習の手法を34%と10%上回る絶対的な成功率を示しています。
このような結果を持つLLMsの潜在能力は無視できなくなりました(もちろん、データ漏洩がなく、論文で提供された評価方法を信頼できる場合)。
論文の動機
この論文は、これまでのLLMsが言語理解において印象的である一方で、問題解決のためにCoT(思考の連鎖)を生成するために使用され、また行動と計画生成にも使用されてきたことから始まります。
これらの2つは別々に研究されてきましたが、論文では推論と行動を交互に組み合わせてLLMのパフォーマンスを向上させることを目指しています。
このアイデアの背後にある理由は、人間がどのように行動してタスクを実行するかを考えてみるとわかります。
最初のステップは、「内部の言語」を使用するか、何らかの方法で自分自身とコミュニケーションを取ることです。「タスクXを実行するにはどうすればいいか?ステップ1を実行してからステップ2を実行する必要があります」などと言います。
具体的には、キッチンで料理を作る場合、ReActのようなことができます。「すべての材料を切ったので、鍋の水を熱します」といった具体的な指示を行い、例外を処理したり状況に応じて計画を調整したりすることができます(「塩がないので、しょうゆと胡椒を使います」)。「生地の準備方法はどうしたらいい?インターネットで検索してみましょう」といった外部情報が必要な場合も認識できます。
また、推論をサポートし、質問に答えるために行動することもできます(レシピを読むために料理の本を開く、冷蔵庫を開けて材料を確認するなど)。
このような推論と行動の組み合わせによって、人間は以前に見たことのない状況や情報の不確実性に直面しても学び、タスクを達成することができます。
推論のみのアプローチ
以前の研究では、LLMsの推論能力が示されており、Chain of Thought Promptingでは、モデルが算術、常識、記号論理の質問に答えるための計画を立てることができることが示されています。
しかし、ここでのモデルはまだ「静的なブラックボックス」であり、これらの質問に答えるために内部の言語表現を使用しており、この表現が常に正確で最新であるとは限らず、事実の幻覚(自分自身の想像から事実を作り出す)やエラーの伝播(思考の連鎖の中の1つのエラーが間違った答えに伝播する)が起こる可能性があります。
何らかの行動を起こして知識を更新する能力がない限り、モデルは制約されます。
行動のみのアプローチ
言語に基づいて行動するためにLLMsを使用した研究もあります。これらの研究では、マルチモーダルな入力(音声、テキスト、画像)を受け取り、それらをテキストに変換し、モデルを使用してドメイン内の行動を生成し、その後、コントローラを使用してこれらの行動を行います。
計画を立てる能力や何をすべきかについての推論を持たない場合、モデルは単に間違った行動を出力します。
両方をReActに組み合わせる
この論文の提案は、上記の両方の手法を組み合わせることです。ReActは、LLMsに対してタスクに関連する言語的推論トレースと行動の両方を交互に生成するように促し、モデルが動的な推論を行い、行動のための高レベルな計画を作成、維持、調整することを可能にします(行動するための推論)。
以下の図に示されています:
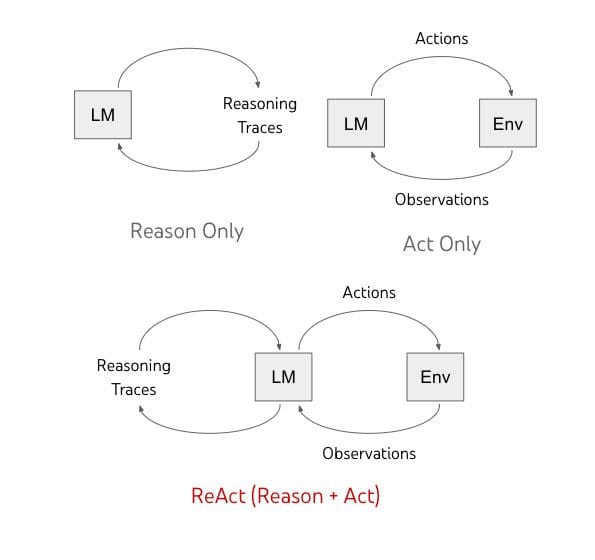
アクションスペース
理論的なプロンプトを改善するために、彼らはアクションスペースを設計しました。これは、モデルが質問に答える際に使用できる3つのアクションを意味します。
これは、次のものを提供するWikipedia APIを介して行われます:
- search[entity]:関連するエンティティのウィキペディアページから最初の5つの文を返し、存在しない場合はウィキペディア検索エンジンからトップ5の類似エンティティを提案します
- lookup[string]:ブラウザ上のCtrl+F機能をシミュレートし、文字列を含むページの次の文を返します
- finish[answer]:現在のタスクを回答で終了します
ここでは、上記で説明したツールよりもはるかに強力な情報検索ツールがあるというのは普通ではありません。
これによって、人間の振る舞いやウィキペディアとの対話など、人間が答えを見つけるためにどのように推論するかをシミュレートすることが目的とされています。
プロンプト
提供されたツールに加えて、LLMに適切にプロンプトを与え、推論を提供しアクションを適切に連鎖させる必要があります。
このため、彼らは質問を分解する思考の組み合わせ(「xを検索して、yを見つけて、zを見つける必要があります」といったもの)、ウィキペディアの観察結果から情報を抽出する(「xは1844年に始まりました」、「段落にはxの情報がありません」)、常識(「xはyではないので、zは代わりに…でなければならない」)、算術的推論(「1844 < 1989」)、検索の再構築をガイドする(「代わりにxを検索/調べることができるかもしれません」)、最終的な答えを合成する(「…したがって、答えはxです」)などを使用します。
最後に、結果は次のようなものになります:

結果
評価のために選ばれたデータセットは以下の通りです:
HotPotQA:1つまたは2つのウィキペディアページを理論的に処理するための質問応答データセットです。
FEVER:各主張がウィキペディアのパッセージを検証するかどうかに基づいて、「SUPPORTS」、「REFUTES」、「NOT ENOUGH INFO」のいずれかに注釈が付けられるファクト検証ベンチマークです。
ALFWorld:高レベルの目標を達成するためにエージェントが実行する必要のある6つのタスクが含まれるテキストベースのゲームです。
例えば、「テーブルランプの下の紙を調べる」というタスクは、テキストアクションを介してシミュレートされた家庭内をナビゲートし、相互作用することで実行されます(例:コーヒーテーブル1に移動し、紙2を取り、デスクランプ1を使用する)
WebShop:1.18Mの実世界の製品と12kの人間の指示が含まれるオンラインショッピングウェブサイトの環境で、さらに多様性と複雑さがあります。
このデータセットでは、ユーザーの指示に基づいて商品を購入する必要があります。例えば、「引き出し付きのナイトスタンドを探しています。ニッケル仕上げで、$140以下で価格が設定されている必要があります」といった指示に従って商品を購入する必要があります。
したがって、結果はReActが常にActを上回ることを示しており、推論部分がアクションを強化するために非常に重要であることがわかります。
一方、ReActはFeverでCoTを上回り(60.9対56.3)、HotpotQAではCoTにわずかに遅れます(27.4対29.4)。したがって、FEVERデータセットでは、最新の知識を得るためのアクションが正しいSUPPORTまたはREFUTEの決定をするために必要なブーストを提供していることが示されています。
HotpotQAでのCoT vs ReActの比較と、パフォーマンスが類似している理由については、以下の主な観察結果が見つかりました:
- CoTにとって幻想は深刻な問題です 。したがって、知識を更新する方法がないため、CoTは想像し幻想する必要がありますが、これは大きなハードルです。
- 推論、アクション、観察ステップを交互に行うことで、ReActの基盤と信頼性が向上しますが、そのような構造的制約は推論ステップの形成において柔軟性を減らします。ReActは、単にCoTを行うだけで十分な場合でも、LLMにアクションを強制する場合があります。
- ReActにとって、検索を介した情報の取得が成功することが重要です。検索が間違った情報を取得すると、その間違った情報に基づく推論は自動的に間違ってしまいますので、正しい情報を取得することが重要です。

この記事がこの論文を理解するのに役立つことを願っています。こちらで確認することができます https://arxiv.org/pdf/2210.03629.pdf
ReActの実装は、既にこちらとこちらで存在しています。
Mohamed Aziz Belaweidさんは、SoundCloudの機械学習/データエンジニアです。彼は研究とエンジニアリングの両方に興味を持っています。彼は論文を読むことが好きで、そのイノベーションを実際に生み出すことに取り組んでいます。彼は特定のドメインへの言語モデルトレーニング、テキストからの情報抽出、マルチモーダル検索システム、画像分類と検出などに取り組んできました。また、モデルの展開、再現性、スケーリング、推論などの運用面でも活動しています。
オリジナル。許可を得て再掲載されました。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- 「ChatGPTをより優れたソフトウェア開発者にする:SoTaNaはソフトウェア開発のためのオープンソースAIアシスタントです」
- 「第一の汎用ビジュアルと言語のAI LLaVA」
- 機械学習なしで最初の自動修正を作成する
- 効率的なディープラーニング:モデルの圧縮のパワーを解き放つ
- このAI論文では、Complexity-Impacted Reasoning Score(CIRS)を紹介していますこれは、大規模な言語モデルの推論能力を向上させるためのコードの複雑さの役割を評価するものです
- 「脳に触発された学習アルゴリズムにより、人工およびスパイキングニューラルネットワークにメタプラスティシティを可能にする」
- メタAIのコンピュータビジョンにおける公平性のための2つの新しい取り組み:DINOv2のためのライセンス導入とFACETのリリースの紹介





