ランダムフォレストと欠損値
Random Forest and Missing Values
非常に興味深い実用的な修正があります
オンラインで見つけられるある種の過剰にクリーン化されたデータセットを除いて、欠損値はどこにでも存在します。実際、データセットが複雑かつ大規模であるほど、欠損値が存在する可能性が高くなります。欠損値は統計的研究の興味深い分野ですが、実際にはしばしば迷惑な存在です。
あなたがp-次元の共変量X = (X_1,…,X_p)から変数Yを予測したい予測問題を扱っていて、X に欠損値がある場合、木ベースの手法には興味深い解決策があります。この方法は実際にはかなり古いですが、さまざまなデータセットで驚くほどうまく機能するようです。それは「欠損値が属性に組み込まれた基準」(MIA; [1])と呼ばれます。欠損値に関する多くの良い記事があるにもかかわらず、この強力なアプローチはあまり利用されていないようです。特に、欠損値を補完したり、削除したり、予測したりする必要はありません。代わりに、観測されたデータが完全であるかのように予測を実行できます。
この方法がどのように機能するかを簡単に説明し、ここで説明されている分布的ランダムフォレスト(DRF)の例を示します。DRFを選んだ理由は、ランダムフォレストの非常に一般的なバージョンであること(特に、ランダムベクトルYを予測するためにも使用できること)と、私がやや偏っているためです。MIAは、一般化ランダムフォレスト(GRF)に実装されており、広範なフォレスト実装をカバーしています。特に、CRAN上のDRFの実装がGRFに基づいているため、わずかな修正の後、MIAメソッドを使用することができます。
もちろん、これは理論的な保証がないクイックフィックスであることに注意してください。欠損メカニズムによっては、分析に重大なバイアスをもたらす可能性があります。一方、欠損値を処理するために最も一般的に使用される方法の多くは、理論的な保証がなく、分析にバイアスをもたらすことが明らかであり、少なくとも経験的には、MIAはうまく機能するようです。
仕組み
RFでは、分割は次の形式のもので構成されます:X_j < S または X_j ≥ S、ただし、j=1,…,pの次元に対して。この分割値Sを見つけるには、Yのいくつかの基準(たとえばCART基準)を最適化します。したがって、観測値はXに依存する決定ルールに従って連続的に分割されます。

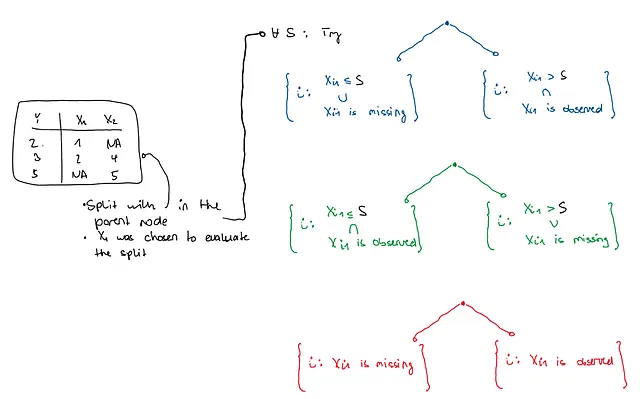
元の論文はやや混乱して説明していますが、MIAがどのように機能するかは次のとおりです。サンプル(Y_1, X_1),…,(Y_n, X_n)を考えてみましょう。ここで、X_i=(X_i1,…,X_ip)’です。
欠損値がない場合の分割は、以前と同じように値Sを見つけて、X_ij < Sの場合はすべてのY_iをノード1に、X_ij ≥ Sの場合はすべてのY_iをノード2に投げます。各値SについてCARTなどの目標基準を計算し、最適なものを選択できます。欠損値の場合、候補の分割値Sごとに3つのオプションがあります。
- X_ijが観測されている場合、すべての観測値iに通常のルールを使用し、X_ijが欠落している場合はノード1に送信する。
- X_ijが観測されている場合、すべての観測値iに通常のルールを使用し、X_ijが欠落している場合はノード2に送信する。
- 通常のルールを無視し、X_ijが欠落している場合はノード1に送信し、観測されている場合はノード2に送信する。
これらのルールのうち、どのルールを適用するかは、使用するY_iの基準によって決定されます。
小さな例
この時点でCRANのdrfパッケージは最新の手法で更新されていないことに注意する必要があります。将来的には、これら全てがCRANの1つのパッケージに実装される時が来るでしょう!しかし、現時点では、2つのバージョンがあります。
欠損値を持つfast drf implementation (信頼区間なし)を使用したい場合は、この記事の最後に添付された「drfown」関数を使用することができます。このコードは、
lorismichel/drf: Distributional Random Forests (Cevid et al.、2020) (github.com)
から適応されたものです。
一方、パラメータと一緒に信頼区間を使用したい場合は、(遅い)このコードを使用してください
drfinference/drf-foo.R at main · JeffNaef/drfinference (github.com)
特に、drf-foo.Rには、後者の場合に必要なすべてが含まれています。
私たちは、この記事で説明されているように、信頼区間のある遅いコードに焦点を当て、同じ例を考慮します:
set.seed(2)n<-2000beta1<-1beta2<--1.8# Model SimulationX<-mvrnorm(n = n, mu=c(0,0), Sigma=matrix(c(1,0.7,0.7,1), nrow=2,ncol=2))u<-rnorm(n=n, sd = sqrt(exp(X[,1])))Y<- matrix(beta1*X[,1] + beta2*X[,2] + u, ncol=1)ここで、X_1の分散がX_1の値に依存するp=2の異質な線形モデルがあることに注意してください。また、Missing at Random (MAR)の方法でX_1に欠損値を追加します:
prob_na <- 0.3X[, 1] <- ifelse(X[, 2] <= -0.2 & runif(n) < prob_na, NA, X[, 1]) これは、X_2が-0.2より小さい値を持つ場合、X_1が0.3の確率で欠損していることを意味します。つまり、X_1が欠落している確率は、X_2に依存するため、「Missing at Random(MAR)」と呼ばれます。これはすでに複雑な状況であり、欠損値のパターンを見ることで情報を得ることができます。つまり、欠損は「Missing Completely at Random (MCAR)」ではなく、X_1の欠落はX_2の値に依存するため、X_1が欠落しているかどうかに応じて描画するX_2の分布が異なります。これは特に、欠損値を持つ行を削除すると、分析が深刻にバイアスすることを意味します。
次に、X = xが与えられた場合、条件付き期待値と分散を正確に前の記事と同様に推定します。
# Choose an x that is not too far outx<-matrix(c(1,1),ncol=2)# Choose alpha for CIsalpha<-0.05その後、DRFを適合させ、テストポイントxの重みを予測します(xに対応するY| X = xの条件付き分布を予測することに相当します):
## Fit the new DRF frameworkdrf_fit <- drfCI(X=X, Y=Y, min.node.size = 5, splitting.rule='FourierMMD', num.features=10, B=100)## predict weightsDRF = predictdrf(drf_fit, x=x)weights <- DRF$weights[1,]例1:条件付き期待値
まず、 X = x におけるYの条件付き期待値を推定します。
# Estimate the conditional expectation at x:condexpest<- sum(weights*Y)# Use the distribution of weights, see belowdistofcondexpest<-unlist(lapply(DRF$weightsb, function(wb) sum(wb[1,]*Y) ))# Can either use the above directly to build confidence interval, or can use the normal approximation.# We will use the lattervarest<-var(distofcondexpest-condexpest)# build 95%-CIlower<-condexpest - qnorm(1-alpha/2)*sqrt(varest)upper<-condexpest + qnorm(1-alpha/2)*sqrt(varest)round(c(lower, condexpest, upper),2)# without NAs: (-1.00, -0.69 -0.37)# with NAs: (-1.15, -0.67, -0.19)驚くべきことに、欠損値を考慮した場合の値は、前の記事で欠損値を考慮しなかった場合の値に非常に近くなります!これは、欠損値のメカニズムが扱いにくいため、本当に驚くべきことです。興味深いことに、推定された推定量の分散も、欠損値がない場合の約0.025から、欠損値がある場合の約0.06に倍増します。
真値は以下のように与えられます:

そのため、わずかな誤差がありますが、信頼区間には真値が含まれているため、正しい結果です。
条件付き分散など、より複雑なターゲットについても結果は同様になります。
# Estimate the conditional expectation at x:condvarest<- sum(weights*Y^2) - condexpest^2distofcondvarest<-unlist(lapply(DRF$weightsb, function(wb) { sum(wb[1,]*Y^2) - sum(wb[1,]*Y)^2} ))# Can either use the above directly to build confidence interval, or can use the normal approximation.# We will use the lattervarest<-var(distofcondvarest-condvarest)# build 95%-CIlower<-condvarest - qnorm(1-alpha/2)*sqrt(varest)upper<-condvarest + qnorm(1-alpha/2)*sqrt(varest)c(lower, condvarest, upper)# without NAs: (1.89, 2.65, 3.42)# with NAs: (1.79, 2.74, 3.69)ここでは、推定値の差は少し大きくなっています。真値は以下のように与えられます:

欠損値を考慮した推定値の方が、さらに正確になっています(もちろん、これはたまたまのことである可能性があります)。また、(分散の)推定量の分散も、欠損値がある場合は0.15(欠損値がない場合)から0.23に増加します。
結論
本稿では、欠損値を扱うためのランダムフォレストの分割方法の適応であるMIAについて説明しました。GRFとDRFで実装されているため、広く使用することができ、少しの例では、非常にうまく機能することが示されました。
ただし、非常に多数のデータポイントがあっても、一貫性や信頼区間が意味を持つ理論的な保証はありません。欠損値の理由は多岐にわたり、この問題に対する不注意な取り扱いによって分析がバイアスを受けることに注意する必要があります。MIA法は、この問題の修正策としてよく理解されているわけではありません。しかし、データの欠損パターンをいくらか利用できるように見える現時点での合理的なクイックフィックスのように思えます。より詳細なシミュレーション分析を行っている方がいれば、その結果について興味があると思います。
コード
require(drf) drfown <- function(X, Y, num.trees = 500, splitting.rule = "FourierMMD", num.features = 10, bandwidth = NULL, response.scaling = TRUE, node.scaling = FALSE, sample.weights = NULL, sample.fraction = 0.5, mtry = min(ceiling(sqrt(ncol(X)) + 20), ncol(X)), min.node.size = 15, honesty = TRUE, honesty.fraction = 0.5, honesty.prune.leaves = TRUE, alpha = 0.05, imbalance.penalty = 0, compute.oob.predictions = TRUE, num.threads = NULL, seed = stats::runif(1, 0, .Machine$integer.max), compute.variable.importance = FALSE) { # XとYの初期チェック if (is.data.frame(X)) { if (is.null(names(X))) { stop("the regressor should be named if provided under data.frame format.") } if (any(apply(X, 2, class) %in% c("factor", "character"))) { any.factor.or.character <- TRUE X.mat <- as.matrix(fastDummies::dummy_cols(X, remove_selected_columns = TRUE)) } else { any.factor.or.character <- FALSE X.mat <- as.matrix(X) } mat.col.names.df <- names(X) mat.col.names <- colnames(X.mat) } else { X.mat <- X mat.col.names <- NULL mat.col.names.df <- NULL any.factor.or.character <- FALSE } if (is.data.frame(Y)) { if (any(apply(Y, 2, class) %in% c("factor",
引用
[1] Twala, B. E. T. H., M. C. Jones, and David J. Hand. Good methods for coping with missing data in decision trees. Pattern Recognition Letters 29 ,2008.
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
