RAG vs ファインチューニング — LLMアプリケーションをブーストするための最適なツールはどちらですか?
RAG vs ファインチューニング — 最適なツールは?
あなたのユースケースに適した方法を選ぶための決定版ガイド
プロローグ
大規模言語モデル(LLM)への関心の波が高まる中、多くの開発者や組織がその力を利用したアプリケーションの構築に忙しいです。しかし、事前学習済みのLLMが期待通りのパフォーマンスを発揮しない場合、LLMアプリケーションのパフォーマンスを向上させる方法について疑問が生じます。そして最終的には、Retrieval-Augmented Generation(RAG)とモデルのファインチューニングのどちらを使用すべきかという点に至ります。
深く掘り下げる前に、これらの2つの方法を解説しましょう:
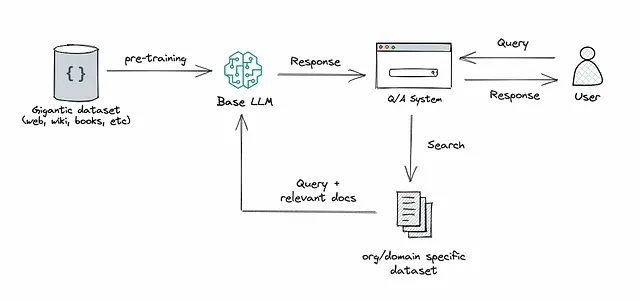
RAG:このアプローチは、検索または検索をLLMのテキスト生成に統合します。これには、大規模なコーパスから関連する文書スニペットを取得するリトリーバーシステムと、それらのスニペットの情報を使用して回答を生成するLLMが組み合わされます。要するに、RAGはモデルが外部情報を「参照」して応答を改善するのに役立ちます。
ファインチューニング:これは、事前学習済みのLLMを取り、特定のタスクに適応するかパフォーマンスを向上させるために、より小さな特定のデータセットでさらにトレーニングするプロセスです。ファインチューニングにより、データに基づいてモデルの重みを調整し、アプリケーションの独自のニーズに合わせたものにします。
- 8月14日から20日までのトップ記事:ChatGPTを使用してテキストをパワーポイントプレゼンテーションに変換する方法
- 「全てのOECDおよびG20加盟国において、インドがAIスキルと人材で1位にランクされました」
- 「サイバー攻撃により、NSF(国立科学財団)が資金提供した主要な望遠鏡が2週間以上閉鎖されました」
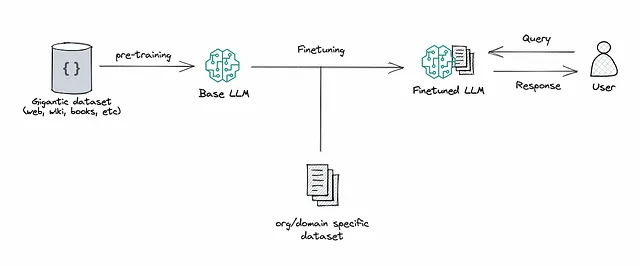
RAGとファインチューニングの両方は、LLMベースのアプリケーションのパフォーマンスを向上させる強力なツールですが、最適化プロセスの異なる側面に対処しており、これは一方を選ぶ際に重要です。
<p以前は、ファインチューニングに入る前にRAGを試してみることを組織に提案することがよくありました。これは、両方のアプローチが似たような結果を達成するが、複雑さ、コスト、品質の点で異なるという私の認識に基づいていました。私はさらにこのポイントを以下のように説明していました…
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles





