人材分析のための R ツールキット:ヘッドカウントのストーリーを伝える
Rツールキット:人材分析のためのヘッドカウントストーリー
Rを使用して解決される人事分析の一般的な課題
人事分析を行うと、会社の人数と会社が現在の状態に進化する経緯のストーリーを伝えるように頻繁に求められます。これは、ウォーターフォールチャートとして提示されることがよくありますが、年々の変化を非技術的な聴衆に共有しようとすると、やや曖昧になります。
このニーズに対応するために、各年を強調した反復プロットを作成し、各年ごとにPowerPointに追加したり、一緒にアニメーション化してgifとして作成することができます。一緒に作りましょう!
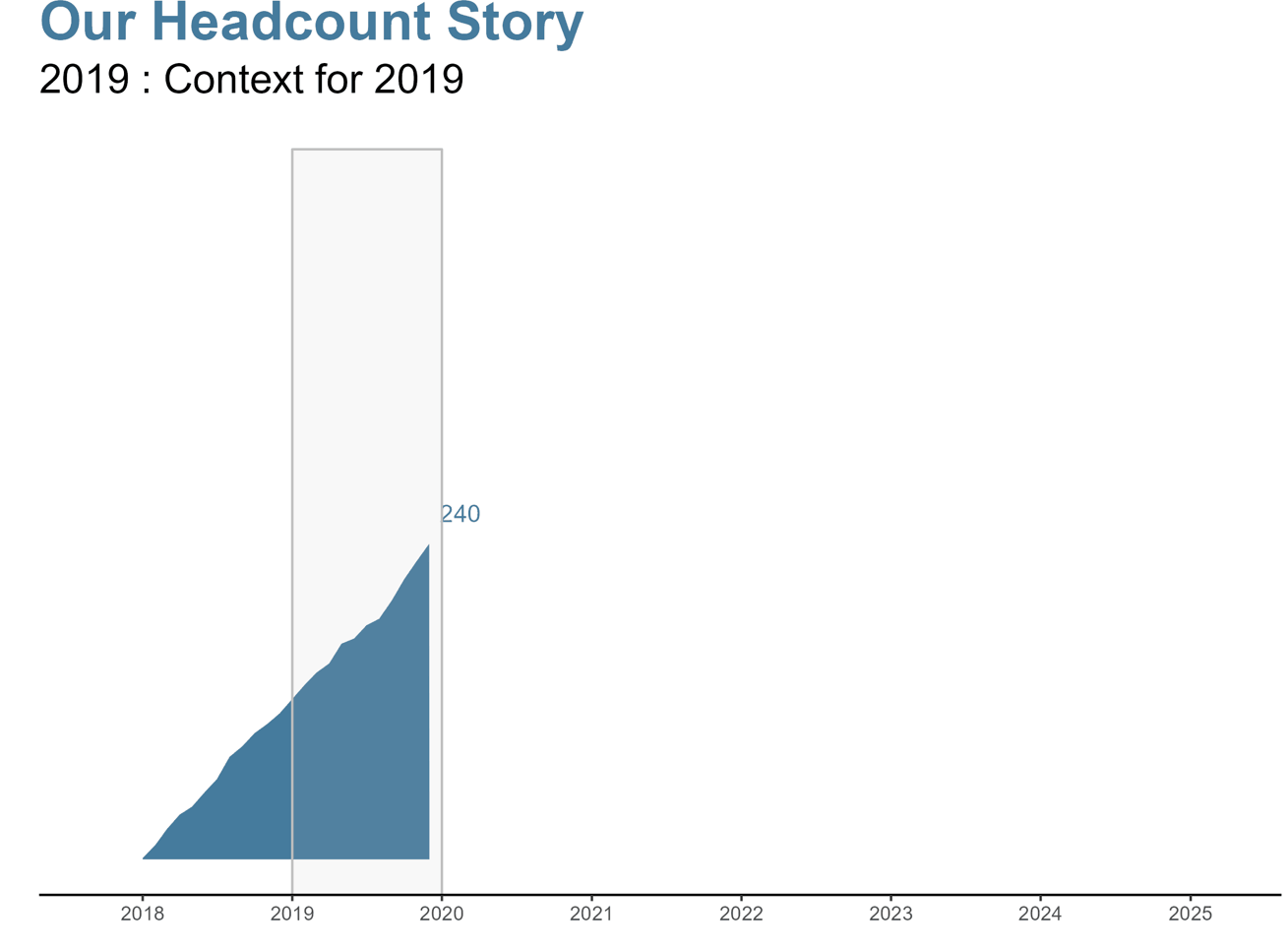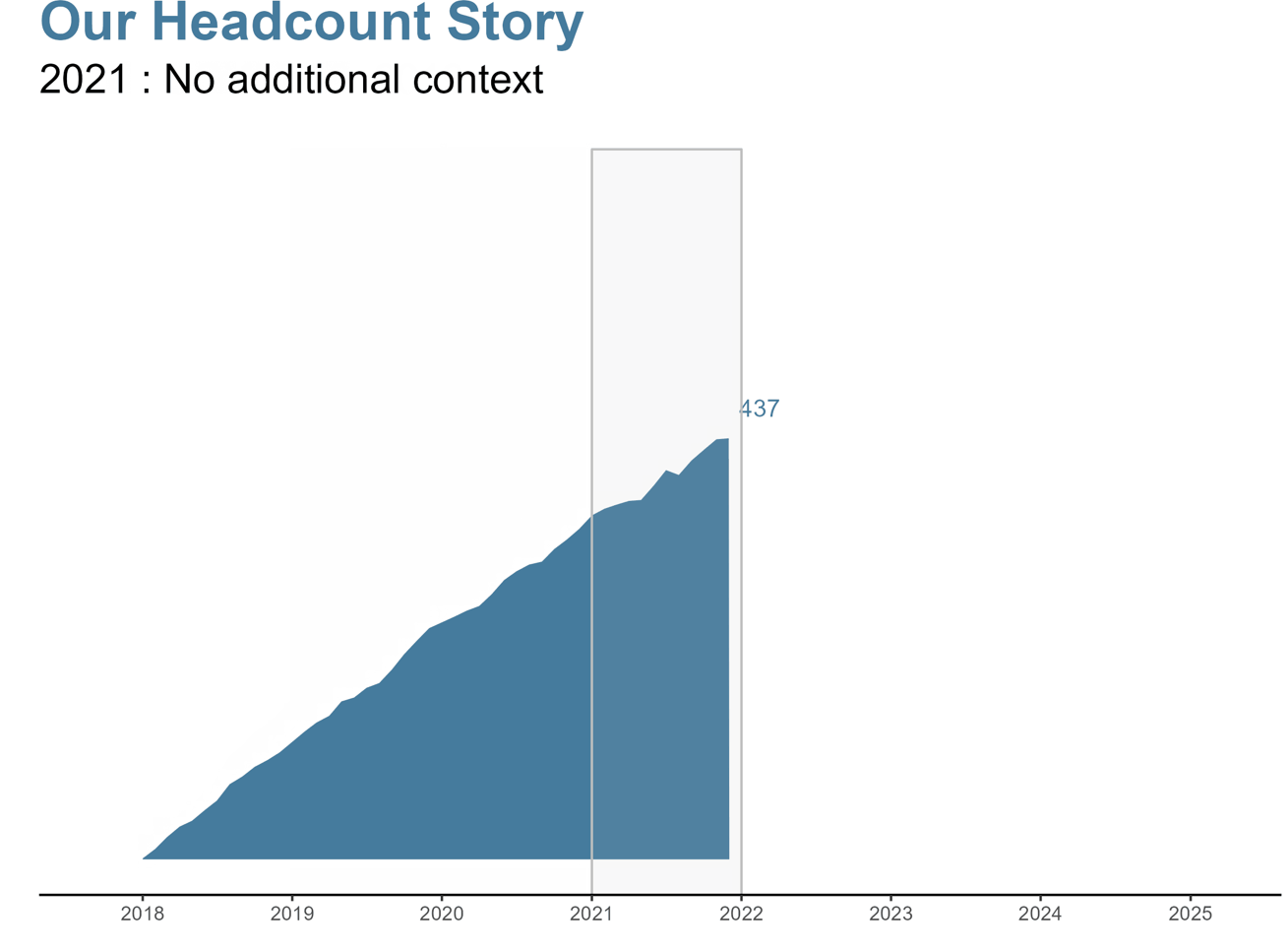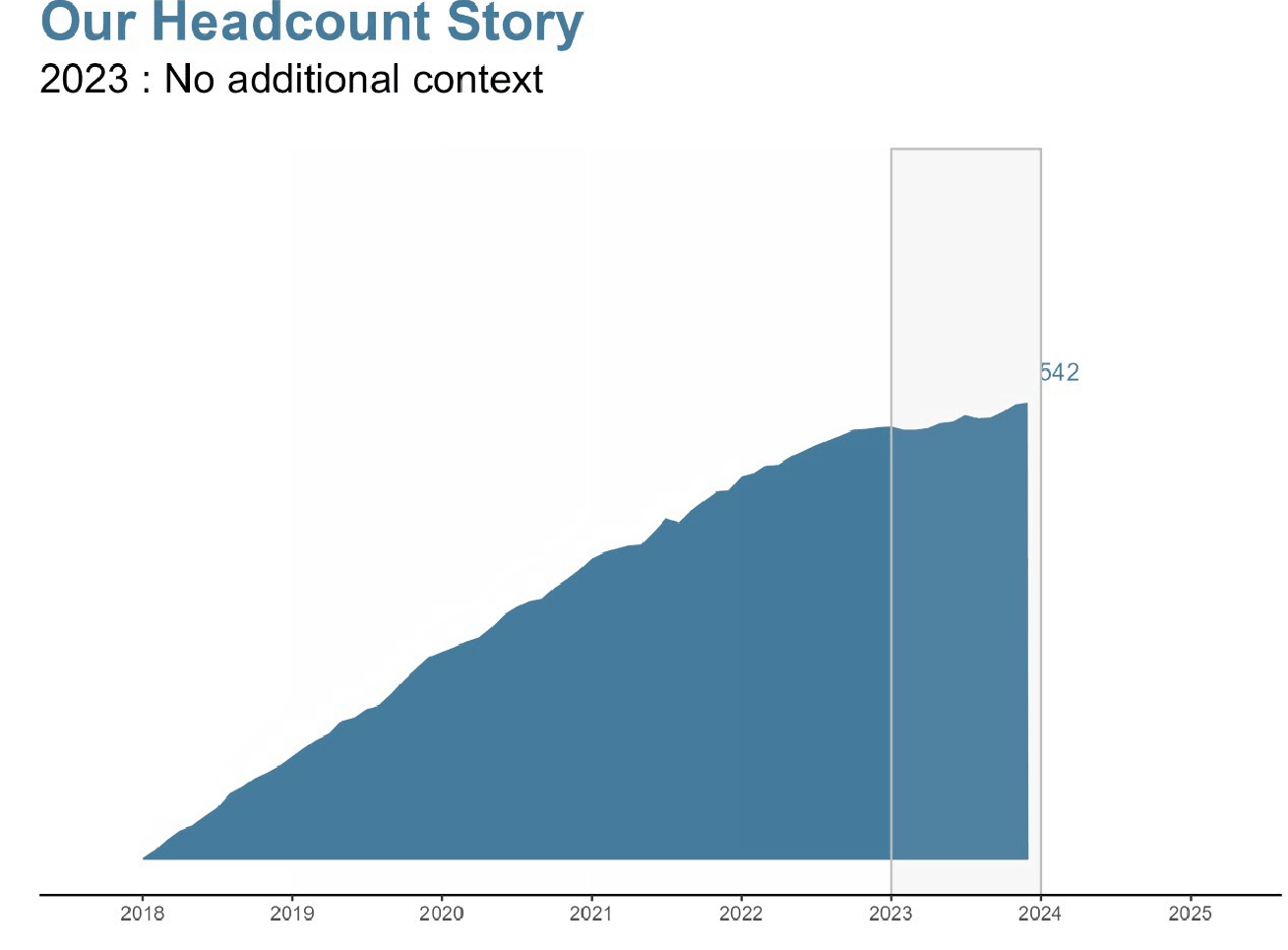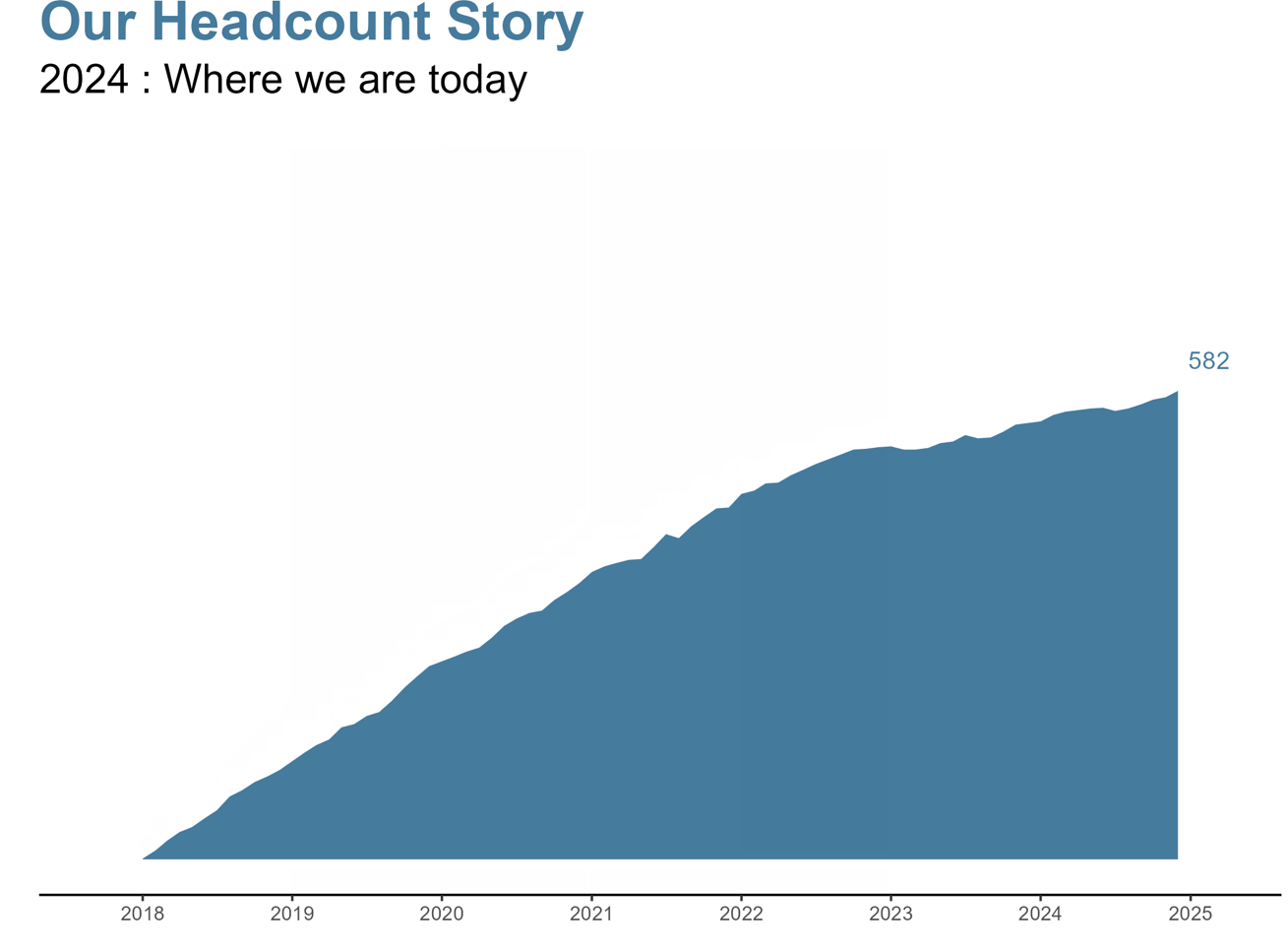
課題:年々のヘッドカウントの変化を現在の状態にどのように伝えるか。
手順:1. 必要なパッケージとデータの読み込み 2. 月次のヘッドカウントの計算 3. 各年の関連コンテキストの追加 4. プロットの作成 5. 各年のプロットを自動的に作成するための設定 6. テーマとプロットの書式設定の調整
- 自分の脳の季節性を活用した、1年間のデータサイエンスの自己学習プランの作成方法
- 探索的データ解析:データセットの中に隠されたストーリーを解き明かす
- NumpyとPandasを超えて:知られざるPythonライブラリの潜在能力の解放
1. 必要なパッケージとデータの読み込み
この課題では、次のパッケージが必要です:- tidyverse – hrbrthemes(プロットを美しくするため)
視覚化するために、ユニークな識別子(例:従業員ID)、雇用日、終了日を含むファイルが必要です。この例では、モックデータを使用します(ステップバイステップで進める場合は、モックデータの作成に使用したコードも最後に含めました)。
# パッケージの読み込み
library(tidyverse)
library(hrbrthemes)
# データの読み込み
employee_data <- mock_data # または、employee_data <- read.csv("input.csv")ちなみに、通常はデータの読み込み時に変数に割り当て、将来の操作に使用する新しい変数を作成します。これは必ずしも必要ではありませんが、大規模なデータセットで作業する場合には、コードを変更するたびにデータを再読み込みする必要がないため、処理が高速になります。
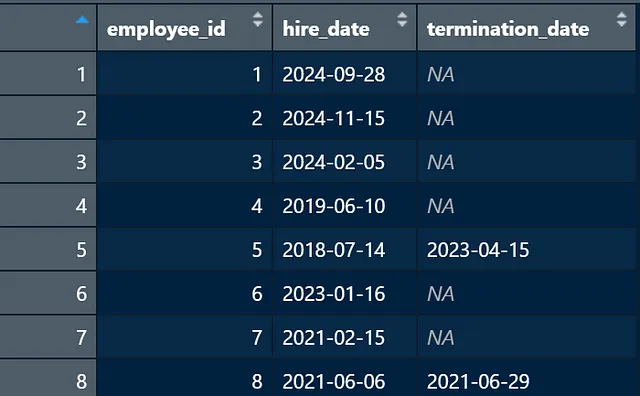
正しく計算するためには、Rが雇用日と終了日が実際に日付であることを認識する必要があります。一般的に、Rで日付を扱うことは本当に面倒ですが、この課題の目的のために、日付の列を日付としてフォーマットし、NAがないことを確認する必要があります。
df %
mutate(Hire.Date = as.Date(Hire.Date, format = "%m/%d/%Y"),
Termination.Date = as.Date(Termination.Date, format = "%m/%d/%Y"))私の入力ファイルでは、まだ活動中の従業員は終了日の欄が空白になっています。もちろん、まだ終了していないためです。日付の列にブランクがあると、Rはごちゃごちゃとなる可能性があるため、終了日の欄に、将来の日付を割り当てるコードを追加します。
df %
mutate(Hire.Date = as.Date(Hire.Date, format = "%m/%d/%Y"),
Termination.Date = as.Date(Termination.Date, format = "%m/%d/%Y")) %>%
mutate(Termination.Date = if_else(is.na(Termination.Date),
as.Date("2100-12-31"), Termination.Date))最後の行は、終了日の列にNA/空白がある場所に、将来の日付を割り当てることを意味しています。この場合、2100年12月31日です。みんなが私がまだ働いていることを願っています。
2. 月次の人数を計算する
このステップは簡単に見えるかもしれませんが、私自身がそれを理解するのに苦労しましたので、自分自身に対して辛抱強くしてください。
まず、各月ごとに日付を持つシーケンスを作成し、次に月次の人数を保持するためのデータフレームを設定し、最後に各月の人数を計算するためにsapply関数を使用します。では、始めましょう!
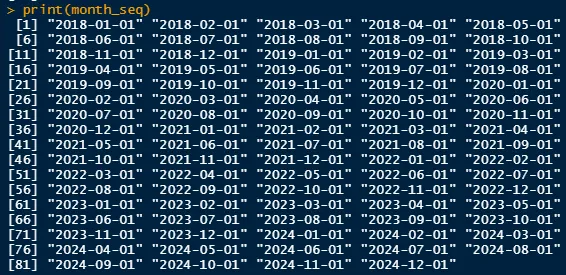
各月の日付のためのシーケンスを作成します(例:1/1/2023、1/2/2023、など):
month_seq <- seq(from = min(df$hire_date), to = max(df$hire_date), by = "1 month")これは、最小の採用日から最大の採用日までを月単位でシーケンス化することを意味しています。これにより、データ内の各月に1つの値が残ります。以下は、その様子です:
次に、このシーケンスを使用して月次の人数を追加できるスターターデータフレームを作成します。
headcount_data <- data.frame(Date = month_seq)さて、ここで難しい部分です。headcount_dataデータフレーム内の各日付におけるアクティブな従業員の数を計算します。つまり、1/1/2018、2/2/2018などでアクティブな従業員の数を求めます。
たとえば、1/1/2018の計算を行いたいとします。採用日が1/1/2018以下であり、退職日が1/1/2018よりも大きい従業員の数を求める必要があります。つまり、既に採用されており、まだ退職していない従業員の数です。
そこで、headcount_dataの各日付に対してsapplyを使用します。
headcount_data <- headcount_data %>% mutate(Active.Employees = sapply(Date, function(x) { sum(x >= df$hire_date & (is.na(df$termination_date) | x < df$termination_date)) })) まだついてきていますか?これまでのすべてをうまく動作させることができた場合、自分自身に大いに拍手を送ってください!問題に直面している場合は、自分自身にこの遠くまで進んだことに大いに拍手を送り、コードに不整合があるかどうかを確認するためにこちらの完全なコードに移動してみてください。
3. 関連するコンテキストを追加する
ここでは、ストーリーテリングの部分が重要になります。組織に対する経験や熟知度に応じて、主題の専門家や経験豊富な従業員とのインタビューが必要な場合もあります。基本的には、ヘッドカウントの増減を説明するのに役立つ重要なコンテキストを追加したいということです。
私は年ごとのコンテキストを追加したいので(月ごとにすることもできます)、headcount_dataに年の列を追加します。
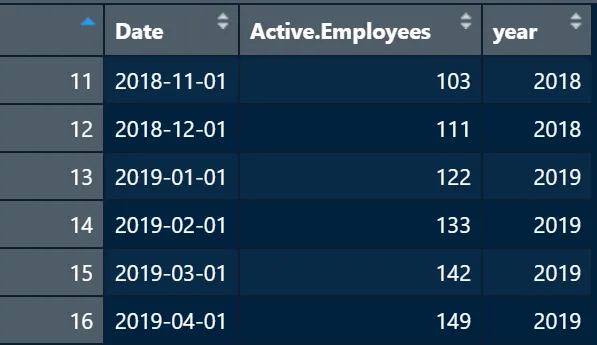
headcount_data <- headcount_data %>% mutate(year = as.integer(year(Date))これにより、各日付に年の列が追加されます:
さて、各年にコンテキストを追加します。たとえば、2020年には「COVID-19」というコンテキストを追加し、2020年の各月に表示したいとします。
これを行うには、case_whenを使用して年に基づいて「context」という列を追加します。
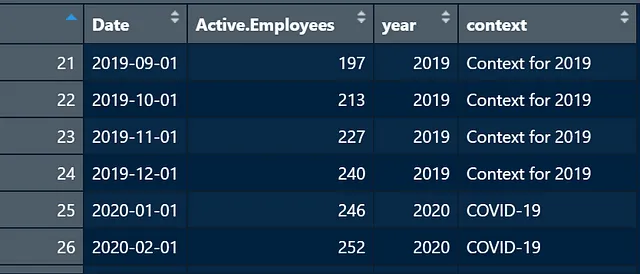
headcount_data <- headcount_data %>% mutate(context = case_when( year == 2018 ~ "2018年のコンテキスト", year == 2019 ~ "2019年のコンテキスト", year == 2020 ~ "COVID-19", TRUE ~ "追加のコンテキストなし"))上記のコードでは、年が2018年の各行について、コンテキスト列を「2018年のコンテキスト」とするように指定しています。興味のある各年にコンテキストを追加し、TRUE句で上記で指定されていない年のコンテキストを指定することができます。
この時点で、headcount_dataは次のようになります:
さて、楽しい部分に入ります!プロットを始めます。
4. プロットを作成する
まず最初に、ggplotを使用してすべてのデータを使用した基本的な面グラフを作成します。x軸には日付、y軸にはActive.Employeesを使用して、ヘッドカウントの推移を表示します。
headcount_data %>% ggplot(aes(x = Date, y = Active.Employees)) + geom_area()これにより、次の基本的なプロットが表示されます:
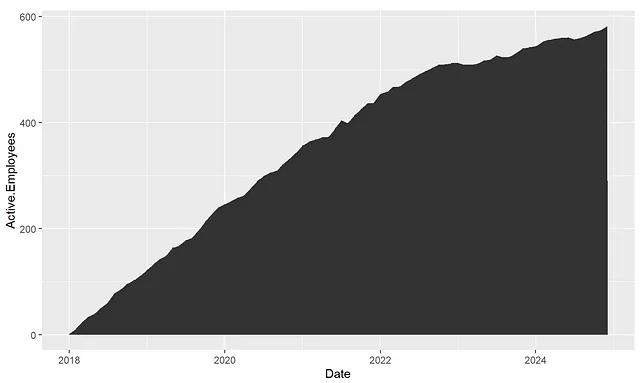
次に、いくつかの基本的な調整を行った後、より高度な調整に移ります:1. 注釈の追加 2. タイトルとサブタイトルの追加
年末のヘッドカウントと年を注釈として追加します(これは各年のプロットを作成する際により関連性が高まります)。まず、各年の更新を容易にするためにそれらを変数に割り当ててみましょう:
# 注釈annotation_ending_year <- max(headcount_data$year)annotation_ending_headcount <- max(headcount_data$Active.Employees)# タイトルとサブタイトルlabels_title <- "私たちのヘッドカウントストーリー"labels_subtitle <- last(headcount_data$context)次に、基本プロットにこれらを追加します:
headcount_data %>% ggplot(aes(x = Date, y = Active.Employees)) + geom_area() + labs(title = labels_title, subtitle = labels_subtitle) + annotate("text", x = max(headcount_data$Date), y = max(headcount_data$Active.Employees), label = annotation_ending_headcount, hjust = -.25)これにより、追加のコンテキストを持つ基本プロットが表示されます:
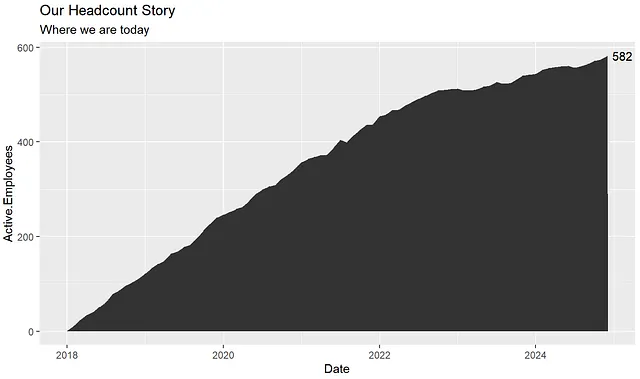
基本プロットが作成されたので、各年ごとに自動的に加算プロットを作成したいと思います。したがって、2018年から2018年の終わり、2018年から2019年の終わり、2018年から2020年の終わりなど、各年にプロットが表示されます。
5. 各年のプロットを自動的に作成する
データセットごとにプロットを作成するために、forループを使用します。
基本的には、データセット内の各ユニークな年を「years」というベクトルに取得します。次に、「years」の各年について、データのサブセットを作成し、そのサブセットのプロットを作成します。これは少し複雑に聞こえるかもしれませんが、コードを見れば理解しやすくなるでしょう。
まず、いくつかのセットアップを行います:
# ユニークな年のためのベクトルを作成しますyears <- unique(headcount_data$year)# プロットを格納するための空のリストplots <- list()では、ループです!見た目は圧倒的かもしれませんが、一歩ずつ進めましょう:
# yearsの各年についてループし、プロットを作成しますfor (i in 2:length(years)) { # 1年ずつ追加したサブセットを作成 subset_df <- headcount_data %>% filter(year <= years[i]) # 注釈の計算 annotation_ending_year <- max(subset_df$Date) annotation_ending_active <- subset_df %>% filter(Date == ending_year) %>% select(Active.Employees) %>% as.numeric() # サブセットを使用してプロット(p)を作成 p <- subset_df %>% ggplot(aes(x = Date, y = Active.Employees)) + geom_area() + labs(title = labels_title, subtitle = labels_subtitle) + annotate("text", x = max(subset_df$Date), y = max(subset_df$Active.Employees), label = ending_active, hjust = -.25) # 各プロットを保存 ggsave(p, file = paste("example_plot_", years[i], ".png"), height = 6, width = 8, units = "in")}あなたは今、作業ディレクトリに「example_plot_year」という名前の各年のプロットが保存されているはずです。私は各年ごとに別々のプロットを持っているのが好きです。質問があるときにはスライドにそれぞれを入れて一時停止できます。または、プロットをまとめてアニメーション化してgifを作成するか、ScreenToGifのような画面録画ソフトを使用して次のようなものを作成することもできます:
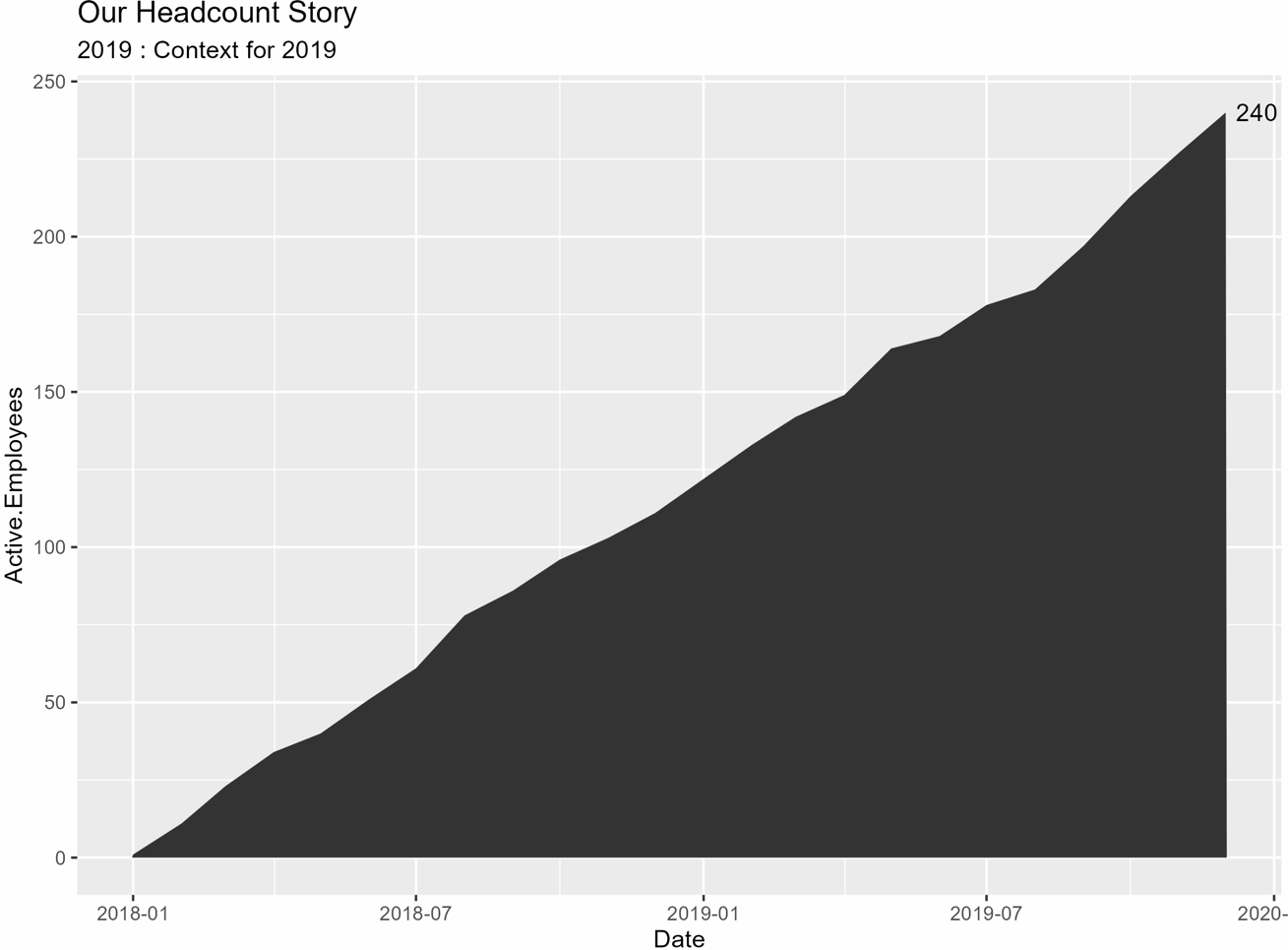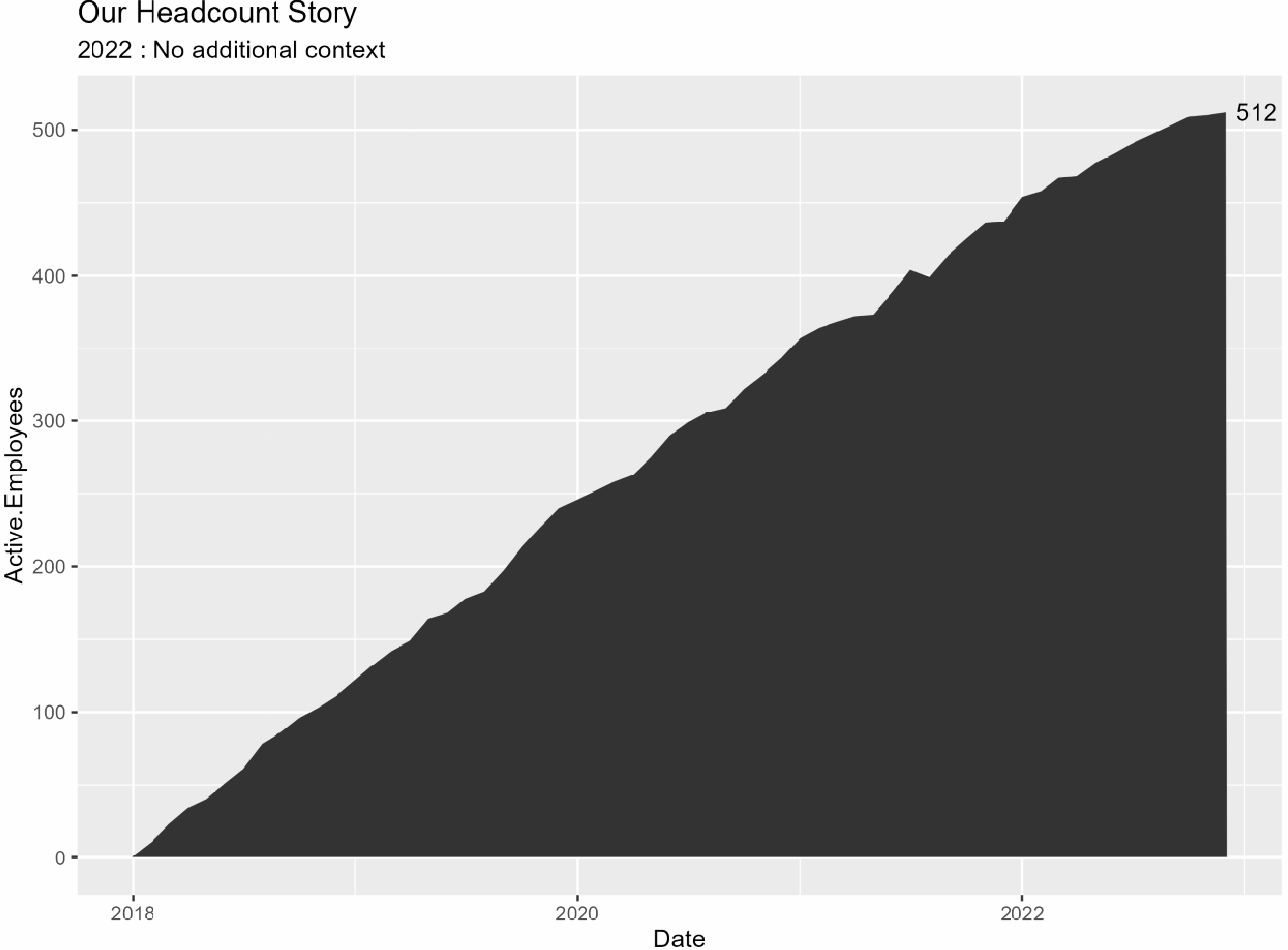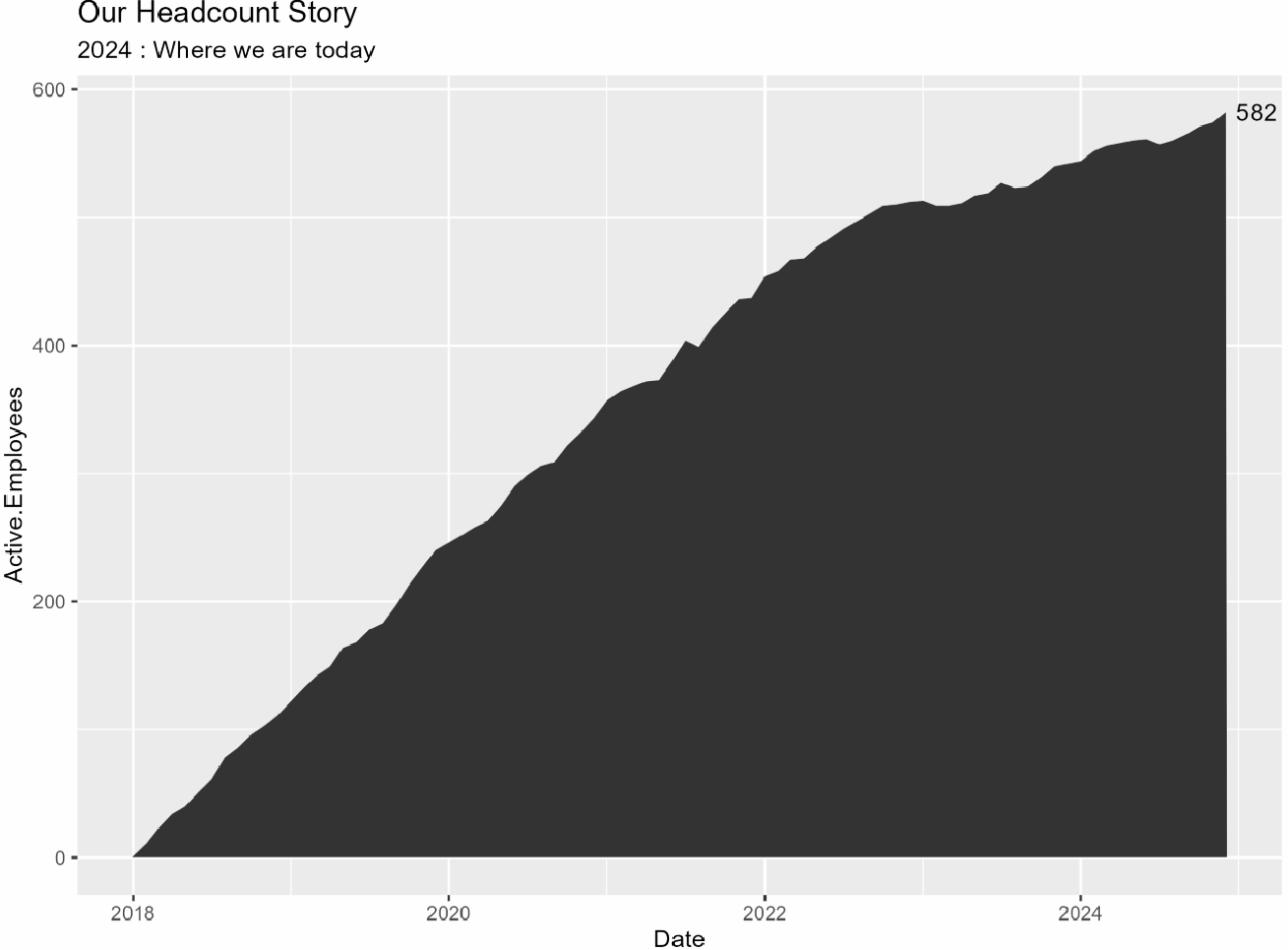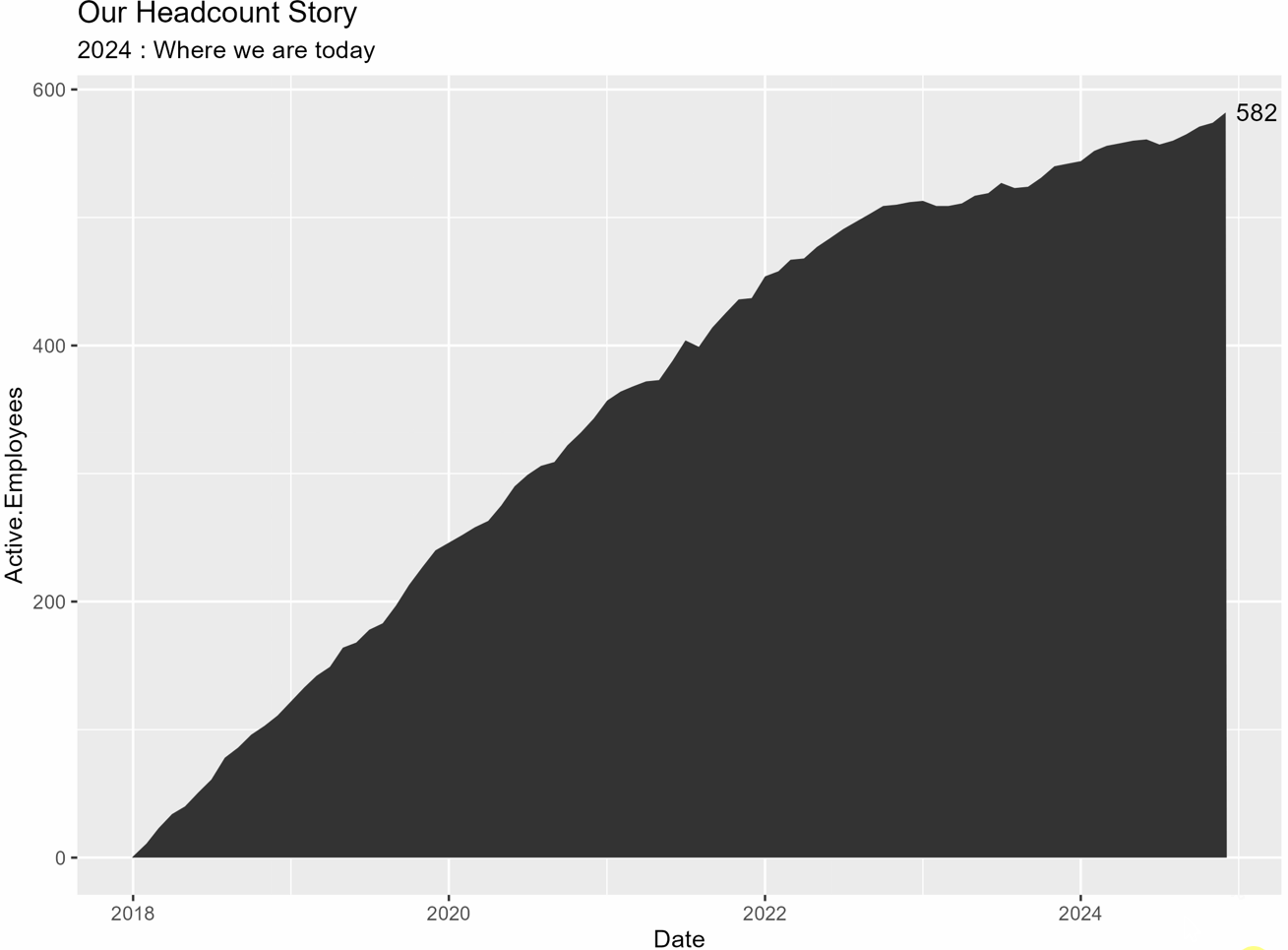
やりました!!!残るはプロットをブランドに合わせてスタイリングし、最新の年をハイライトするための矩形を追加することだけです。
6. テーマとプロットの書式設定を調整する
最初にやりたいことは、最新の年をハイライトするための矩形を追加することです。これにより、視聴者が焦点を合わせる場所がわかりやすくなり、各プロットで1年ごとに見ることができます。
これは、次のようなものになるでしょう:
annotate("rect", xmin = , xmax = , ymin = , ymax = )これもしばらくかかりましたが、ここで重要なのは:
X軸:矩形を与えられた年(データのサブセット内の最大年)の最初の(つまり床)日から始め、与えられた年(データのサブセット内の最大年)の最後の(つまり天井)日で終わるようにしたいです。したがって、2019年のプロットでは、矩形は2019年1月1日から2019年12月1日までになります。
annotate("rect", xmin = floor_date(max(subset_df$Date), "year"), xmax = ceiling_date(max(subset_df$Date), "year")Y軸:矩形をy軸から始め、その年の最終人数よりも上方(+300)で終わるようにしたいです。再び2019年を見てみると、矩形はy軸のちょうど右から始まり、240の最終人数よりも上方に終わります。
annotate("rect", xmin = floor_date(max(subset_df$Date), "year"), xmax = ceiling_date(max(subset_df$Date), "year"), ymin = -Inf, ymax = ending_active + 300)スタイル:最後に、ボックスの色をグレーにし、透明度を0.1に変更して、透明度がかなり高く、エリアチャートの下にあることがわかるようにします:
annotate("rect", xmin = floor_date(max(subset_df$Date), "year"), xmax = ceiling_date(max(subset_df$Date), "year"), ymin = -Inf, ymax = ending_active + 300, alpha = .1, color = "gray", fill = "gray")軸の制限:遷移をスムーズにするために、x軸とy軸に制限を設けて、各プロットが同じようにスケーリングされるようにします。
scale_x_date(breaks = "1 year", date_labels = "%Y", expand = c(.1,.1), limits = c(min(headcount_data$Date), max(headcount_data$Date)))わー!もうすぐです。今、テーマにいくつかの変更を加えて、ワインを注ぎます。自分自身のアイデアを加える時間です。私のものは次のようになりました:
以下は、最終的なループのコードです:
# 各年ごとにループし、プロットを作成するfor (i in 2:length(years)) { # 1つの年ずつ追加してサブセットを作成 subset_df <- headcount_data %>% filter(year <= years[i]) # 注釈の計算 ending_year <- max(subset_df$Date) ending_active <- subset_df %>% filter(Date == ending_year) %>% select(Active.Employees) %>% as.numeric() # サブセットを使用してプロットを作成 p <- subset_df %>% ggplot(aes(x = Date, y = Active.Employees)) + geom_area(fill = "#457b9d") + labs(title = "私たちの人数推移", subtitle = paste(years[i],":", last(subset_df$context)), x = "", y = "") + scale_x_date(breaks = "1 year", date_labels = "%Y", expand = c(.1,.1), limits = c(min(headcount_data$Date), max(headcount_data$Date))) + theme_classic(base_family = "Arial") + theme(plot.title = element_text(size = 24, face = "bold", color = "#457b9d"), plot.subtitle = element_text(size = 18), panel.grid.major = element_blank(), panel.grid.minor = element_blank(), axis.ticks.y = element_blank(), axis.text.y = element_blank(), axis.line.y = element_blank()) + annotate("text", x = ending_year, y = ending_active, label = ending_active, vjust = -1.25, hjust = -.25, color = "#457b9d") + annotate("rect", xmin = floor_date(max(subset_df$Date), "year"), xmax = ceiling_date(max(subset_df$Date), "year"), ymin = -Inf, ymax = ending_active + 300, alpha = .1, color = "gray", fill = "gray") # 各プロットを保存 ggsave(p, file = paste("example_plot_final", years[i], ".png"), height = 6, width = 8, units = "in") }全ーーーー部終了しました!
追加のコンテキストを持つサブタイトルで、従業員数の変化を時間経過でダイナミックに表示できるようになりました。将来のバージョンに向けたいくつかのアイデア: gganimateを使用したプロットの作成、各年の従業員数の%変化の追加、従業員数が増加または減少した場合のグラフの色の変更、成長トレンドラインの予測の追加など、可能性は無限です!
作成してみましたか?もしそうなら、どんなものができたかを見せていただけると嬉しいです!
Githubでの完全なコードは、こちらから。
もっと一般的なPeople Analyticsのリソースが必要ですか?
People Analyticsを始めるための12以上の無料リソース
People Analyticsでキャリアを始めたい人におすすめの無料リソース。
jeagleson.medium.com
このようなリソースやこのサイト全体の素晴らしいコンテンツにアクセスしたい場合は、1ヶ月5ドルのサブスクリプションにサインアップするために私のリンクを使用できます(追加費用はかかりません)。
私の紹介リンクでVoAGIに参加する – Jenna Eagleson
Jenna Eagleson(およびVoAGIの他の数千人の作家のすべてのストーリー)を読む。会員費は直接サポートになります…
jeagleson.medium.com
Jenna Eagleson 私のバックグラウンドは産業心理学であり、私はPeople Analyticsの中で自分の居場所を見つけました。データビジュアライゼーションが私の仕事を生き生きとさせています。Power BI、R、Tableauなど、学びながら開発するのが楽しいです。あなたの旅についてもっと聞きたいです!LinkedinまたはTwitterで連絡してください。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
