GGMLとllama.cppを使用してLlamaモデルを量子化する
Quantize Llama model using GGML and llama.cpp.
GGML vs. GPTQ vs. NF4

大規模言語モデル(LLM)の巨大なサイズのため、量子化は効率的に実行するための必須の技術となっています。重みの精度を減らすことで、メモリを節約し、推論を高速化することができますが、モデルのほとんどの性能を保持します。最近では、8ビットおよび4ビットの量子化により、LLMを一般のハードウェア上で実行する可能性が開かれました。Llamaモデルのリリースとそれらを微調整するためのパラメータ効率の良い手法(LoRA、QLoRA)と組み合わせることで、これらのローカルLLMがOpenAIのGPT-3.5とGPT-4と競合する豊かなエコシステムが生まれました。
本記事では、この記事でカバーされている素朴なアプローチに加えて、NF4、GPTQ、GGMLという3つの主要な量子化手法があります。NF4は、QLoRAが4ビット精度でモデルを読み込んで微調整を行うための静的な手法です。以前の記事では、GPTQ手法を探求し、独自のモデルを量子化して一般のGPU上で実行しました。本記事では、GGML手法を紹介し、Llamaモデルを量子化する方法、さらには最良の結果を得るためのヒントやトリックを提供します。
コードはGoogle ColabとGitHubで入手できます。
GGMLとは何ですか?
GGMLは、機械学習に特化したCライブラリです。GGというイニシャルはGeorgi Gerganovの意味です。このライブラリはテンソルなどの機械学習の基盤要素だけでなく、LLMを配布するための独自のバイナリ形式も提供しています。
- エントロピーを使用した時系列複雑性解析
- 機械学習プロジェクトのロードマップの設計方法
- 「現実的なシミュレーションを用いたデータサイエンスにおけるソフトスキルのトレーニング:ロールプレイデュアルチャットボットアプローチ」
この形式は最近GGUFに変更されました。この新しい形式は拡張性を持つように設計されており、新しい機能が既存のモデルとの互換性を壊さないようになっています。また、特殊トークン、RoPEスケーリングパラメータなど、すべてのメタデータを1つのファイルに集約しています。つまり、いくつかの歴史的な問題に対応し、将来的にも有効な形式です。詳細については、このアドレスの仕様書を参照してください。本記事では、「GGMLモデル」と呼ぶことにしますが、これはGGUFまたは以前の形式を使用しているすべてのモデルを指します。
GGMLは、Georgi Gerganovが作成したllama.cppライブラリと組み合わせて使用するように設計されました。このライブラリは、効率的なLlamaモデルの推論を行うためにC/C++で書かれています。GGMLモデルをロードし、CPU上で実行することができます。元々、これはGPTQモデルとの主な違いであり、これらはGPU上でロードおよび実行されます。ただし、llama.cppを使用することで、LLMの一部のレイヤーをGPUにオフロードすることもできます。例を挙げると、7bパラメータモデルには35のレイヤーがあります。これにより、推論が大幅に高速化され、VRAMに収まらないLLMを実行することができます。
もしコマンドラインツールがお好みであれば、llama.cppとGGUFのサポートは、oobaboogaのtext-generation-web-ui、koboldcpp、LM Studio、またはctransformersなどの多くのGUIに統合されています。これらのツールを使用してGGMLモデルを簡単にロードし、ChatGPTのような方法で対話することができます。幸いにも、多くの量子化モデルはHugging Face Hubで直接利用できます。ほとんどのモデルは、LLMコミュニティで人気のあるTheBlokeによって量子化されていることにすぐに気付くでしょう。
次のセクションでは、独自のモデルを量子化し、一般のGPU上で実行する方法について見ていきます。
GGMLでLLMを量子化する方法
TheBloke/Llama-2–13B-chat-GGMLリポジトリ内のファイルを見てみましょう。さまざまな種類の量子化に対応した14種類の異なるGGMLモデルが見られます。これらは特定の命名規則に従っています。「q」+重みを保存するために使用されるビット数(精度)+特定のバリアントです。以下は、TheBlokeによって作成されたモデルカードに基づいた、すべての可能な量子化手法とそれに対応するユースケースのリストです。
q2_k: attention.vwとfeed_forward.w2テンソルにはQ4_Kを使用し、他のテンソルにはQ2_Kを使用します。q3_k_l: attention.wv、attention.wo、およびfeed_forward.w2テンソルにはQ5_Kを使用し、それ以外の場合はQ3_Kを使用します。q3_k_m: attention.wv、attention.wo、およびfeed_forward.w2テンソルにはQ4_Kを使用し、それ以外の場合はQ3_Kを使用します。q3_k_s: すべてのテンソルにはQ3_Kを使用します。q4_0: オリジナルの量子化メソッドで、4ビットです。q4_1: q4_0よりも高い精度ですが、q5_0ほどではありません。ただし、q5モデルよりも推論が速くなります。q4_k_m: attention.wvとfeed_forward.w2テンソルの半分にはQ6_Kを使用し、それ以外の場合はQ4_Kを使用します。q4_k_s: すべてのテンソルにはQ4_Kを使用します。q5_0: 高い精度、高いリソース使用量、遅い推論です。q5_1: より高い精度、リソース使用量、遅い推論です。q5_k_m: attention.wvとfeed_forward.w2テンソルの半分にはQ6_Kを使用し、それ以外の場合はQ5_Kを使用します。q5_k_s: すべてのテンソルにはQ5_Kを使用します。q6_k: すべてのテンソルにはQ8_Kを使用します。q8_0: float16とほとんど区別がつきません。高いリソース使用量と遅さです。ほとんどのユーザーにはお勧めできません。
おおよその目安として、Q5_K_Mを使用することをお勧めします。モデルの性能の大部分を保持するためです。メモリを節約したい場合は、Q4_K_Mを使用することもできます。一般的に、K_MバージョンはK_Sバージョンよりも優れています。モデルのパフォーマンスを大幅に低下させるため、Q2またはQ3のバージョンはお勧めできません。
利用可能な量子化タイプについての詳細を知ったところで、実際のモデルにそれらを使用する方法を見てみましょう。Google Colabの無料のT4 GPUで次のコードを実行できます。最初のステップでは、llama.cppをコンパイルし、必要なライブラリをPython環境にインストールする必要があります。
# llama.cppをインストールします!git clone https://github.com/ggerganov/llama.cpp!cd llama.cpp && git pull && make clean && LLAMA_CUBLAS=1 make!pip install -r llama.cpp/requirements.txtこれでモデルをダウンロードできます。前の記事でファインチューニングしたモデル、mlabonne/EvolCodeLlama-7bを使用します。
MODEL_ID = "mlabonne/EvolCodeLlama-7b"# モデルをダウンロードします!git lfs install!git clone https://huggingface.co/{MODEL_ID}このステップには時間がかかる場合があります。完了したら、重みをGGML FP16形式に変換する必要があります。
MODEL_NAME = MODEL_ID.split('/')[-1]GGML_VERSION = "gguf"# fp16に変換fp16 = f"{MODEL_NAME}/{MODEL_NAME.lower()}.{GGML_VERSION}.fp16.bin"!python llama.cpp/convert.py {MODEL_NAME} --outtype f16 --outfile {fp16}最後に、1つまたは複数の方法を使用してモデルを量子化できます。この場合、前述のQ4_K_MおよびQ5_K_Mの方法を使用します。これは実際にGPUが必要な唯一のステップです。
QUANTIZATION_METHODS = ["q4_k_m", "q5_k_m"]for method in QUANTIZATION_METHODS: qtype = f"{MODEL_NAME}/{MODEL_NAME.lower()}.{GGML_VERSION}.{method}.bin" !./llama.cpp/quantize {fp16} {qtype} {method}2つの量子化されたモデルは推論の準備ができました。binファイルのサイズを確認して、どれだけ圧縮されたかを確認できます。FP16モデルは13.5 GBを使用し、Q4_K_Mモデルは4.08 GB(3.3倍小さい)、Q5_K_Mモデルは4.78 GB(2.8倍小さい)を使用します。
効率的に実行するために、llama.cppを使用しましょう。16 GBのVRAMを持つGPUを使用しているため、すべてのレイヤーをGPUにオフロードすることができます。この場合、35のレイヤー(7bパラメータモデル)を表しているため、-ngl 35パラメータを使用します。以下のコードブロックでは、プロンプトと使用する量子化メソッドも入力します。
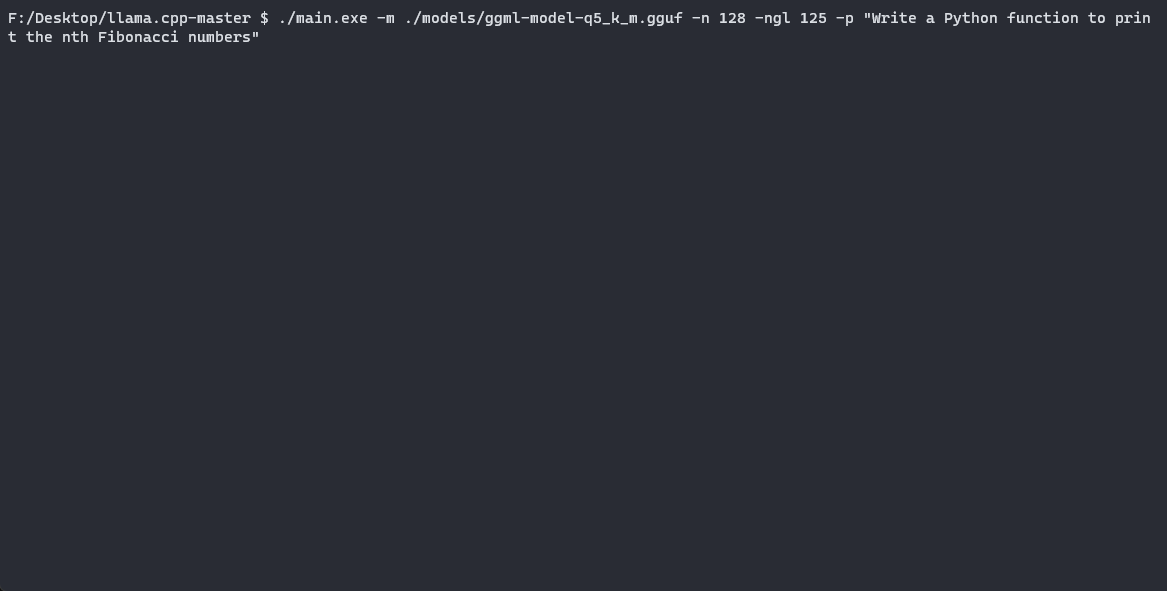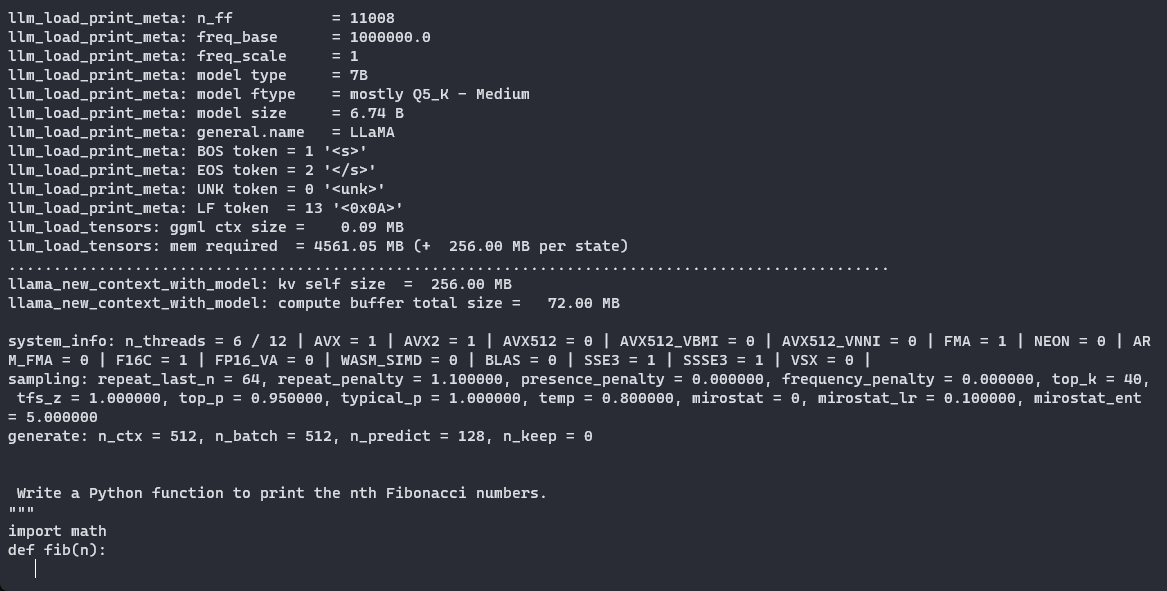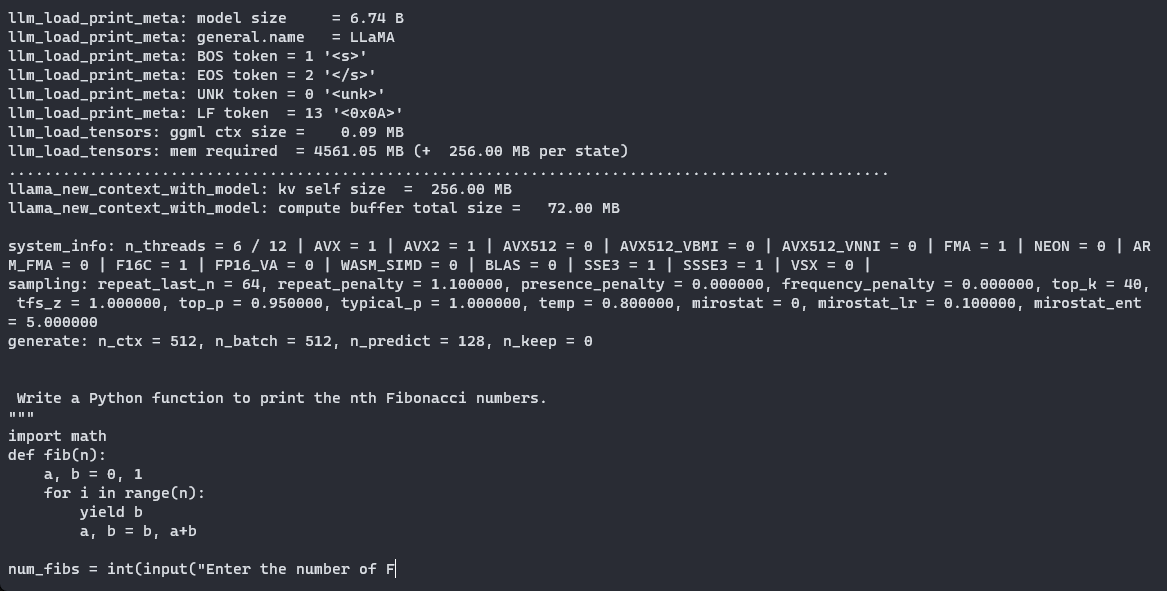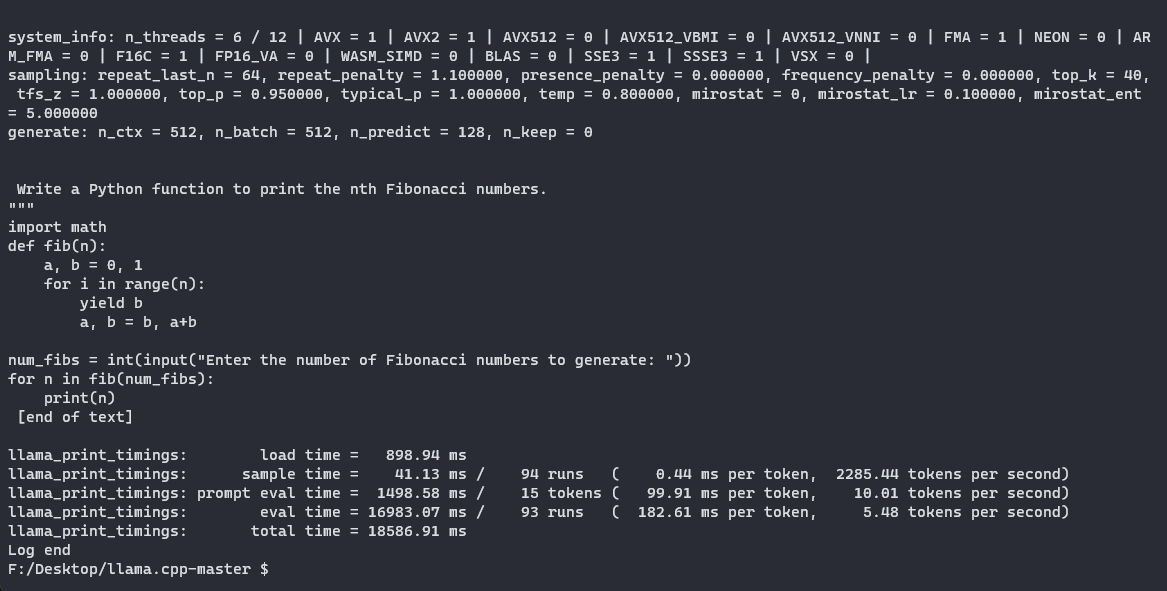
import osmodel_list = [file for file in os.listdir(MODEL_NAME) if GGML_VERSION in file]prompt = input("プロンプトを入力してください:")chosen_method = input("モデルを実行するための量子化メソッドを指定してください(オプション:" + "、".join(model_list) + "):")# 選択したメソッドがリストに含まれているか確認するif chosen_method not in model_list: print("無効なメソッドが選択されました!")else: qtype = f"{MODEL_NAME}/{MODEL_NAME.lower()}.{GGML_VERSION}.{method}.bin" !./llama.cpp/main -m {qtype} -n 128 --color -ngl 35 -p "{prompt}"モデルに「n番目のフィボナッチ数を出力するPythonの関数を書いてください」と尋ねましょう。Q5_K_Mメソッドを使用します。ログを見ると、「llm_load_tensors: offloaded 35/35 layers to GPU」という行を見ることで、レイヤーを正常にGPUにオフロードできたことを確認することができます。以下は、モデルが生成したコードです:
def fib(n): if n == 0 or n == 1: return n return fib(n - 2) + fib(n - 1)for i in range(1, 10): print(fib(i))これは非常に複雑なプロンプトではありませんが、すぐに動作するコードを生成することができました。このGGMLを使用すると、対話モード(-iフラグ)を使用してローカルのLLMをターミナルでアシスタントとして使用することができます。また、LLMを実行するための優れたオプションであるAppleのMetal Performance Shaders(MPS)を搭載したMacbookでも動作します。
最後に、量子化されたモデルをHugging Face Hubの新しいリポジトリに「-GGUF」の接尾辞を付けてプッシュすることができます。まず、ログインして以下のコードブロックをユーザー名に合わせて変更しましょう。
!pip install -q huggingface_hubusername = "mlabonne"from huggingface_hub import notebook_login, create_repo, HfApinotebook_login()これでリポジトリを作成し、モデルをアップロードすることができます。ファイルをアップロードする際には、allow_patternsパラメータを使用してアップロードするファイルをフィルタリングしますので、ディレクトリ全体をプッシュすることはありません。
api = HfApi()# リポジトリを作成create_repo( repo_id=f"{username}/{MODEL_NAME}-GGML", repo_type="model", exist_ok=True)# binモデルをアップロードapi.upload_folder( folder_path=MODEL_NAME, repo_id=f"{username}/{MODEL_NAME}-GGML", allow_patterns=f"*{GGML_VERSION}*",)GGMLモデルを量子化し、実行し、Hugging Face Hubにプッシュすることに成功しました!次のセクションでは、GGMLがこれらのモデルを実際にどのように量子化するのかを探求します。
GGMLによる量子化
GGMLが重みを量子化する方法は、GPTQのように洗練されていません。基本的には値のブロックをグループ化し、それらを下位精度に丸めるというものです。Q4_K_MやQ5_K_Mなどのいくつかの技術では、重要なレイヤーにより高い精度を実装しています。この場合、すべての重みは4ビット精度で保存されますが、attention.wvとfeed_forward.w2テンソルの半分は例外です。実験的に、このミックス精度は精度とリソース使用の間の良いトレードオフとなっています。
ggml.cファイルを見ると、ブロックがどのように定義されているかがわかります。例えば、block_q4_0構造体は以下のように定義されています:
#define QK4_0 32typedef struct { ggml_fp16_t d; // delta uint8_t qs[QK4_0 / 2]; // nibbles / quants} block_q4_0;GGMLでは、重みはブロックごとに処理され、各ブロックは32の値で構成されています。各ブロックでは、最大の重み値からスケールファクター(デルタ)が導かれます。その後、ブロック内のすべての重みはスケーリングされ、量子化され、効率的にストレージ(ニブル)にパックされます。このアプローチにより、ストレージの要件が大幅に削減され、元の重みと量子化された重みの間で比較的単純で確定的な変換が可能となります。
量子化プロセスについての知識が深まったので、NF4とGPTQの結果を比較することができます。
NF4 vs. GGML vs. GPTQ
4ビットの量子化にはどの技術がより優れているのでしょうか? この質問に答えるために、これらの量子化されたLLMを実行する異なるバックエンドを紹介する必要があります。 GGMLモデルの場合、Q4_K_Mモデルを使用したllama.cppが適しています。 GPTQモデルの場合、AutoGPTQまたはExLlamaの2つのオプションがあります。 最後に、NF4モデルはtransformersで直接--load-in-4bitフラグを使用して実行できます。
Oobaboogaは、パープレキシティ(より低いほど良い)を基準にさまざまなモデルを比較した優れたブログ記事で複数の実験を行いました。

これらの結果に基づいて、パープレキシティの観点ではGGMLモデルがわずかに優位です。その差は特に大きくないため、トークン/秒の生成速度に焦点を当てる方が良いです。最適な技術はGPUによって異なります:量子化モデル全体を収めるのに十分なVRAMがある場合、GPTQ with ExLlamaが最速です。そうでない場合は、一部のレイヤーをオフロードしてllama.cppを使用したGGMLモデルでLLMを実行できます。
結論
この記事では、GGMLライブラリと新しいGGUF形式を紹介し、これらの量子化モデルを効率的に保存するために使用しました。それを使用して、異なる形式(Q4_K_MおよびQ5_K_M)で独自のLlamaモデルを量子化しました。次に、GGMLモデルを実行し、バイナリファイルをHugging Face Hubにプッシュしました。最後に、GGMLのコードを詳しく調査して、実際に重みを量子化する方法を理解し、それをNF4とGPTQと比較しました。
量子化は、LLMの実行コストを下げることで、LLMの民主化を実現するための重要な手段です。将来的には、混合精度や他の技術により、量子化された重みを使用して達成できるパフォーマンスがさらに向上するでしょう。それまで、この記事を楽しんで新しいことを学んでいただければ幸いです。
LLMに関するさらに詳細な技術的なコンテンツに興味がある場合は、VoAGIで私をフォローしてください。
量子化に関する記事
パート1:重み量子化の紹介
8ビットの量子化による大規模言語モデルのサイズ削減
towardsdatascience.com
パート2:GPTQによる4ビットの量子化
AutoGPTQを使用して独自のLLMを量子化する
towardsdatascience.com
1クリックで機械学習のさらなる学習と私の仕事をサポートしてください – こちらでVoAGIメンバーになることができます:
私の紹介リンクを使用してVoAGIに参加する – Maxime Labonne
VoAGIメンバーとして、会費の一部はあなたが読むライターに寄付され、すべてのストーリーに完全アクセスできます…
VoAGI.com
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
