PyTorch LSTMCell — 入力、隠れ状態、セル状態、および出力の形状
PyTorch LSTMCell - 入力、隠れ状態、セル状態、出力の形状
Pytorchでは、nn.LSTMCellを使用するためには、入力時系列、隠れ状態ベクトル、およびセル状態ベクトルを表すテンソルの形状を理解する必要があります。この記事では、多変量時系列で作業していると仮定します。データセットの各多変量時系列には、複数の単変量時系列が含まれています。
この記事では、次の用語を使用します。
バッチ = データセットからの単一バッチの多変量時系列の数
入力特徴量 = 1つの多変量時系列内の単変量時系列の数
タイムステップ = 各多変量時系列の時間ステップの数
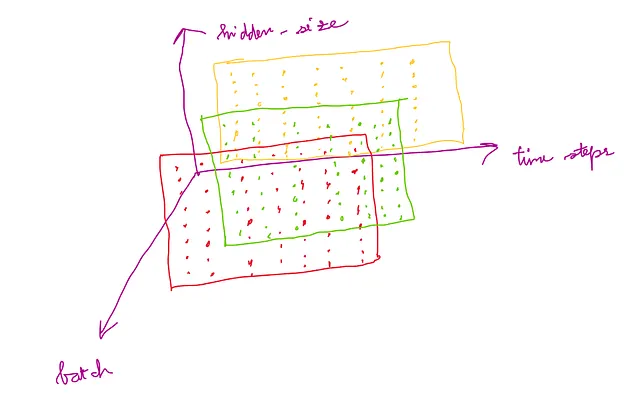
LSTMCellに与えられる多変量時系列のバッチは、形状(タイムステップ、バッチ、入力特徴量)のテンソルである必要があります。
次の図は、この入力の形状を理解するためのものです:

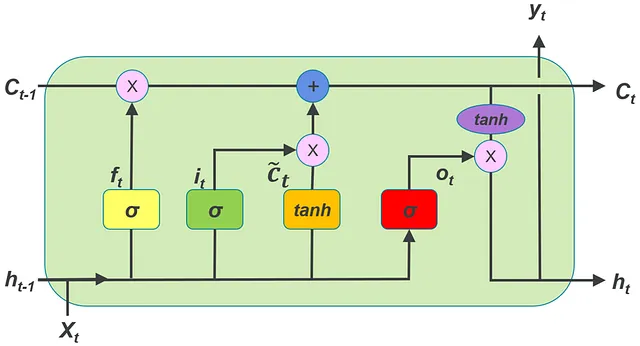
LSTMCellへの入力は、特定のタイムステップのベクトルx_tとして与えられます。単一のタイムステップのベクトルの処理には、LSTMCellには1つの隠れ状態ベクトルと1つのセル状態ベクトルが必要です。これらはh_0およびc_0として表されます。LSTMCellの出力は、次の時間インスタンスの入力ベクトルを処理する際に使用される隠れ状態とセル状態です。これらの隠れ状態とセル状態は、後続の時間ステップのh_0およびc_0として渡されるループ内でLSTMCellが呼び出されます。このコンセプトは、次のコードスニペットで説明されています。
LSTMCellオブジェクトを初期化する際には、input_featuresおよびhidden_sizeの引数を指定する必要があります。
ここで、
input_features = 1つの多変量時系列内の単変量時系列の数(上記のinput_featuresと同じ値)
hidden_size = 隠れ状態ベクトルの次元数。セル状態ベクトルの次元数にも同じサイズが使用される必要があります。
LSTMCellの初期の隠れ状態とセル状態の値は、形状(バッチ、hidden_size)で作成する必要があります。ここで、バッチは入力多変量時系列のバッチと一致する必要があります。つまり、入力バッチの各MTSには、対応するhidden_stateとcell_stateがあります。
初期の隠れ状態と初期のセル状態の時系列は、LSTMCellを通じた前方伝播のために入力として与えられる必要があります。
入力MTSの特定のタイムステップのベクトル、初期の隠れ状態、および初期のセル状態をLSTMCellオブジェクトを介して前方伝播する形式は次のとおりです:
LSTMCell(x_t, (h_0, c_0))
次の図は、隠れ状態とセル状態の形状を理解するためのものです:

以下にコードの例を示します。コードの説明は後続します。
import torchimport torch.nn as nn lstm_0 = nn.LSTMCell(10, 20) # (input_features, hidden_size)inp = torch.randn(7, 3, 10) # (time_steps, batch, input_features) -> input time serieshx = torch.randn(3, 20) # (batch, hidden_size) -> initial value of hidden statecx = torch.randn(3, 20) # (batch, hidden_size) -> initial value of cell statefor i in range(inp.size()[0]): hx, cx = lstm_0(inp[i], (hx, cx)) # forward propogation of input through LSTMCell output.append(hx)output = torch.stack(output, dim=0)nn.LSTMCell()を呼び出すと、__init__()のダンダーマジックメソッドが呼び出され、LSTMCellオブジェクトが作成されます。上記のコードでは、このオブジェクトはlstm_0として参照されています。
一般的にRNN(LSTMはRNNの一種)では、入力時系列の各タイムステップはRNN内で順序通りに1つずつ渡され、RNNによって処理される必要があります。
LSTMCellを使用してバッチで多変量時系列を処理するためには、バッチ内のすべてのMTSの各タイムステップを順番にLSTMCellに渡す必要があります。
これはforループによって実現されます。このループはMTSの各タイムステップ(inp.size()の最初の次元はタイムステップの数です)を反復処理し、バッチ内の各MTSのタイムステップのベクトルを並列にLSTMCellに渡します。LSTMCellへの単一の呼び出しは、MTS内の1つのタイムステップのベクトルのみを処理します。
forループ内のlstm_0(inp[i], (hx, cx))の呼び出しの出力は、各タイムステップの次のhidden_stateとcell stateの作成です。出力されたhidden_state(hx)とcell_state(cx)は、前のhxとcxに基づいて再帰的に計算されます。
出力:(h_1, c_1)
この出力は、バッチ全体の各時系列に対して計算されます。出力の形状は(batch, hidden_size)です。
次の図は、出力されるhidden stateとcell stateの形状を理解するためのものです:
入力バッチ内の各MTSの各タイムステップで作成される計算されたhxは、出力テンソルに追加され、0軸に沿ってスタックされます。したがって、出力の次元は(time_steps, batch, hidden_size)です。
上記のコード例の出力は次のようになります:
tensor([[[ 0.0087, 0.0365, -0.1233, -0.2641, 0.2908, -0.5075, 0.2587, 0.1057, -0.2079, -0.2327, 0.1390, 0.1023, -0.1186, 0.3302, 0.1139, 0.1591, -0.0264, -0.0499, 0.0153, 0.3881], [ 0.3585, -0.4133, -0.0259, 0.2490, -0.0936, -0.2756, -0.1941, -0.0967, 0.1501, -0.0334, -0.1904, -0.3945, -0.1036, -0.2091, 0.0545, 0.1937, -0.2338, 0.0382, 0.2344, 0.1169], [-0.2532, 0.0745, -0.0329, 0.0971, -0.1057, -0.0383, 0.1328, 0.1263, -0.1422, 0.0351, 0.3957, -0.4115, -0.2951, -0.5560, 0.1941, 0.0100, 0.3028, -0.1803, 0.0028, 0.3210]], [[ 0.1105, -0.1295, -0.0636, -0.2510, 0.1923, -0.2457, 0.2401, 0.1379, -0.1373, -0.2451, 0.0387, 0.1004, -0.0580, 0.3430, -0.0149, 0.1827, -0.0229, -0.2061, 0.1718, 0.3146], [ 0.2741, -0.2413, -0.1310, 0.1206, 0.0379, -0.1738, -0.0568, 0.0417, 0.0756, 0.1020, 0.0262, -0.3280, -0.0352, -0.1713, 0.1065, 0.0458, -0.3404, -0.0795, 0.0586, 0.0026], [-0.0112, 0.0883, -0.1755, -0.0438, 0.0193, 0.0151, 0.1010, 0.1614, -0.0524, 0.0970, 0.2092, -0.3518, -0.0715, -0.3941, 0.1422, 0.1164, 0.2946, -0.1919, 0.1493, 0.1203]]], grad_fn=<StackBackward0>)入力の各タイムステップ(入力のtime_steps = 2)ごとに配列が作成されます(2つの配列が作成されます)。これらの配列のそれぞれには、バッチ内の各MTSごとに配列が含まれます(batch_size = 3)。MTSの各タイムステップごとに、hidden_size次元(ここではhidden_size = 20)の隠れ状態ベクトル出力が得られます。したがって、各タイムステップでは、MTSの値はベクトルです。このベクトルはタイムステップごとに20次元のhidden_stateベクトルにマップされます。
次の図は、出力の多変量時系列バッチの形状を理解するためのものです:
上記のコードで1つのタイムステップ(ループ内の1回の反復)のhxを出力する場合、以下が出力されます:
tensor([[ 0.1034, -0.0192, -0.0581, -0.0772, -0.1578, -0.1450, 0.0377, -0.0013, -0.2641, -0.1821, 0.0431, -0.2262, 0.3025, 0.0952, 0.4113, -0.2968, -0.4377, 0.0794, 0.3683, -0.0021], [ 0.0309, 0.3957, 0.2143, 0.1020, 0.0640, -0.0628, 0.4390, 0.1818, 0.0373, 0.2497, -0.1768, -0.2038, -0.1249, -0.2995, 0.0786, -0.0522, -0.0080, -0.3095, -0.0815, 0.2874], [-0.2458, 0.1622, 0.2564, -0.3136, 0.0631, 0.0643, 0.4036, 0.3293, -0.1806, -0.0251, -0.4505, -0.1437, -0.1718, -0.0479, -0.1116, -0.1065, -0.3289, 0.1137, 0.1160, 0.1227]], grad_fn=<MulBackward0>)1つのタイムステップに対応する1つの配列があります。このタイムステップ内には、バッチ内の3つのMTSに対応する3つの配列があります。1つのMTSに対応するこれらの配列のそれぞれは、20次元の隠れベクトルです。したがって、1つのタイムステップの出力は(batch, hidden_size)です。
この出力サイズは、次の図を使用して理解することができます:

nn.LSTMCellの初期化引数は次のとおりです:
input_size
hidden_size
bias
device
dtype
num_layersはありません。これは単一のセルであるため、複数のLSTMレイヤーを持つことはできません。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- 「Google AIの新しいパラダイムは、多段階の機械学習MLアルゴリズムの組成コストを削減して、強化されたユーティリティを実現する方法は何ですか」
- 大規模言語モデル(LLM)と潜在ディリクレ配分(LDA)アルゴリズムを用いたドキュメントのトピック抽出
- 「機械学習チートシートのためのScikit-learn」
- 「FLM-101Bをご紹介します:1010億パラメータを持つ、オープンソースのデコーダのみのLLM」
- iOSアプリの自然言語処理:機能、Siriの使用例、およびプロセス
- 「短期予測を改善したいですか?デマンドセンシングを試してみてください」
- 「場所の言語:生成AIのジオコーディング能力の評価」