PyTorch LSTM — 入力、隠れ状態、セル状態、および出力の形状
PyTorch LSTMの形状:入力、隠れ状態、セル状態、および出力
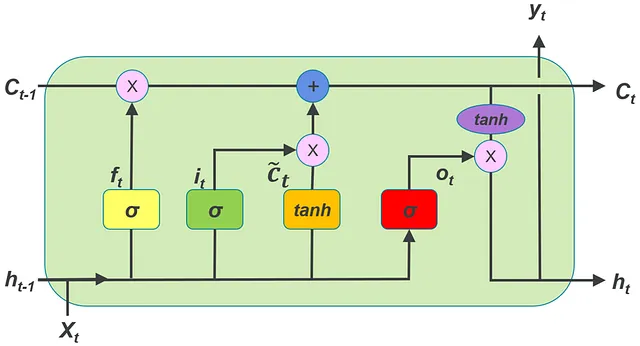
Pytorchでは、nn.LSTM()を使用してLSTMを使用するために、入力時系列、隠れ状態ベクトル、セル状態ベクトルを表すテンソルの形状を理解する必要があります。この記事では、多変量時系列で作業していると仮定します。データセット内の各多変量時系列には、複数の単変量時系列が含まれています。
次に、次のリンクで説明されているpytorchのLSTMCellとの違いです:
Pytorch LSTMCell — 入力、隠れ状態、セル状態の形状
Pytorchでは、LSTMCellを使用するには、入力時系列、隠れ状態を表すテンソルの形状を理解する必要があります。
VoAGI.com
- 『3Dディープラーニングへの道:Pythonでの人工ニューラルネットワーク』
- 「Google AIの新しいパラダイムは、多段階の機械学習MLアルゴリズムの組成コストを削減して、強化されたユーティリティを実現する方法は何ですか」
- 大規模言語モデル(LLM)と潜在ディリクレ配分(LDA)アルゴリズムを用いたドキュメントのトピック抽出
- nn.LSTMを使用すると、LSTMの複数の層を積み重ねて重ねたLSTMを作成できます。2番目のLSTMは、最初のLSTMの出力を入力として受け取り、以降同様です。
2. nn.LSTMクラスにはドロップアウトを追加することができます。
3. nn.LSTMにはバッチ処理されていない入力を与えることができます。
後でこの記事でさらに議論されるもう1つの重要な違いがあります。
この記事では、以下の用語を使用します。
バッチ = データセット内の複数の多変量時系列の数
input_features = 1つの多変量時系列内の単変量時系列の数
タイムステップ = 各多変量時系列のタイムステップの数
LSTMに入力する多変量時系列のバッチは、形状が(time_steps, batch, input_features)のテンソルである必要があります
以下の図は、この形状を理解するためのものです。

しかし、LSTMでは、入力の形状を変える別の方法もあります。これは以下で説明されています。
LSTMオブジェクトの初期化時には、input_featuresとhidden_sizeという引数を指定する必要があります。
ここで、
input_features = 1つの多変量時系列内の単変量時系列の数(上記のinput_featuresと同じ値)
hidden_size = 隠れ状態ベクトルの次元数
LSTMクラスが受け取る他の引数:
num_layers = 重ねられたLSTMの数。複数の層が重ねられると、それはstacked LSTMと呼ばれます。デフォルトでは、層の数は1です
dropout = 非ゼロの場合、各LSTM層の出力にドロップアウト層が追加されます。ドロップアウト確率はこの値に等しくなります。デフォルトでは、この値は0であり、ドロップアウトはありません。
batch_first = Trueの場合、入力と出力のテンソルは(バッチ、タイムステップ、input_features)の次元を持つようになります。デフォルトでは、これはFalseです。
proj_size = プロジェクションサイズ。proj_size > 0の場合、プロジェクションを使用したLSTMが使用されます。
時系列と初期の隠れ状態、初期のセル状態は、LSTMを通じた前方伝播の入力として与えられる必要があります。
入力、初期の隠れ状態、初期のセル状態の前方伝播は、以下の形式で行います:
LSTM(input_time_series, (h_0, c_0))
前方伝播前に、LSTMに渡すための隠れ状態ベクトルとセル状態ベクトルの形状を見てみましょう。
h_0 — (num_layers, batch, h_out)。ここで、h_out = proj_size if proj_size > 0 else hidden_size
c_0 — (num_layers, batch, hidden_size)
以下の図は、隠れたベクトルの形状を理解するのに役立ちます。

セルの状態ベクトルにも同様の図が適用されます。
図から、すべてのレイヤーの隠れた状態とセルの状態の次元は同じであることがわかります。
次のコードスニペットを考えてみましょう:
import torchimport torch.nn as nn lstm_0 = nn.LSTM(10, 20, 2) # (input_features, hidden_size, num_layers)inp = torch.randn(4, 3, 10) # (time_steps, batch, input_features) -> input time seriesh0 = torch.randn(2, 3, 20) # (num_layers, batch, hidden_size) -> initial value of hidden statec0 = torch.randn(2, 3, 20) # (num_layers, batch, hidden_size) -> initial value of cell stateoutput, (hn, cn) = lstm_0(input, (h0, c0)) # forward pass of input through LSTMnn.LSTM()を呼び出すと、__init__() ダンダーマジックメソッドが呼び出され、LSTMオブジェクトが作成されます。上記のコードでは、このオブジェクトはlstm_0として参照されます。
一般的なRNN(LSTMはRNNの一種)では、入力時系列の各time_stepはRNNによって順次処理されるため、シーケンスの順序でRNNに1つずつ渡す必要があります。
LSTMを使用してバッチで多変量時系列を処理するには、バッチ内のすべてのMTSの各time_stepを順次LSTMに通過させる必要があります。
LSTMのforward passの単一の呼び出しは、各time_stepを順次処理することで、シリーズ全体を処理します。これは、LSTMCellでは単一の呼び出しが1つのtime_stepのみを処理し、シリーズ全体を処理しない点と異なります。
上記のコードの出力は次のとおりです:
tensor([[[ 3.8995e-02, 1.1831e-01, 1.1922e-01, 1.3734e-01, 1.6157e-02, 3.3094e-02, 2.8738e-01, -6.9250e-02, -1.8313e-01, -1.2594e-01, 1.4951e-01, -3.2489e-01, 2.1723e-01, -1.1722e-01, -2.5523e-01, -6.5740e-02, -5.2556e-02, -2.7092e-01, 3.0432e-01, 1.4228e-01], [ 9.2476e-02, 1.1557e-02, -9.3600e-03, -5.2662e-02, 5.5299e-03, -6.2017e-02, -1.9826e-01, -2.7072e-01, -5.5575e-02, -2.3024e-03, -2.6832e-01, -5この出力には、4つの時間ステップに対応する4つの配列があります。これらのtime_stepsのそれぞれには、バッチ内の3つのMTSに対応する3つの配列が含まれています。これらの3つの配列のそれぞれには、20の要素が含まれています -> これが隠れ状態です。したがって、各MTSの各time_stepの各x_tベクトルには、隠れ状態が出力されます。これらは、スタックされたLSTMの最後のレイヤーの隠れ状態です。
出力:(output_multivariate_time_series, (h_n, c_n))
上記のコードにあるhnを出力すると、以下のような出力が得られます:
tensor([[[-0.3046, -0.1601, -0.0024, -0.0138, -0.1810, -0.1406, -0.1181, 0.0634, 0.0936, -0.1094, -0.2822, -0.2263, -0.1090, 0.2933, 0.0760, -0.1877, -0.0877, -0.0813, 0.0848, 0.0121], [ 0.0349, -0.2068, 0.1353, 0.1121, 0.1940, -0.0663, -0.0031, -0.2047, -0.0008, -0.0439, -0.0249, 0.0679, -0.0530, 0.1078, -0.0631, 0.0430, 0.0873, -0.1087, 0.3161, -0.1618], [-0.0528, -0.2693, 0.1001, -0.1097, 0.0097, -0.0677, -0.0048, 0.0509, 0.0655, 0.0075, -0.1127, -0.0641, 0.0050, 0.1991, 0.0370, -0.0923, 0.0629, 0.0122, 0.0688, -0.2374]], [[ 0.0273, -0.1082, 0.0243, -0.0924, 0.0077, 0.0359, 0.1209, 0.0545, -0.0838, 0.0139, 0.0086, -0.2110, 0.0880, -0.1371, -0.0171, 0.0332, 0.0509, -0.1481, 0.2044, -0.1747], [ 0.0087, -0.0943, 0.0111, -0.0618, -0.0376, -0.1297, 0.0497, 0.0071, -0.0905, 0.0700, -0.1282, -0.2104, 0.1350, -0.1672, 0.0697, 0.0679, 0.0512, 0.0183, 0.1531, -0.2602], [-0.0705, -0.1263, 0.0099, -0.0797, -0.1074, -0.0752, 0.1020, 0.0254, -0.1382, -0.0007, -0.0787, -0.1934, 0.1283, -0.0721, 0.1132, 0.0252, 0.0765, 0.0238, 0.1846, -0.2379]]], grad_fn=<StackBackward0>)
これには、スタックされたLSTMの最後のtime_stepの各3 MTSの中の隠れ状態ベクトルが含まれています。注意してください、2番目のレイヤー(最後のレイヤー)の隠れ状態は、前述の出力の最後の時間ステップの隠れ状態と同じです。
したがって、出力のMTS次元は(time_steps, batch, hidden_size)です。
この出力の次元は、以下の図から理解できます:
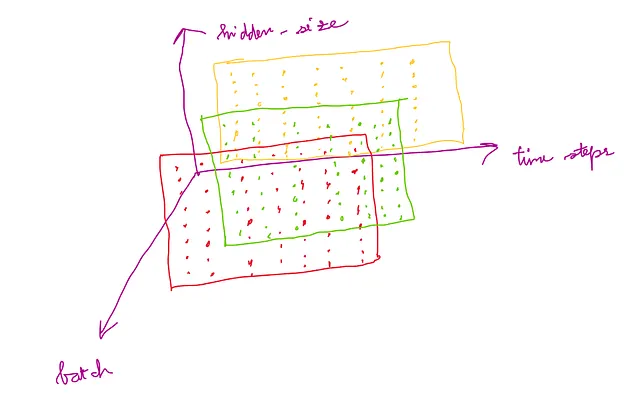
h_nの次元: (num_layers, batch, h_out)
c_nの次元: (num_layers, batch, hidden_size)
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles





