PyTorch FSDPを使用してLlama 2 70Bのファインチューニング
PyTorch FSDPを使用してLlama 2 70Bのファインチューニング
はじめに
このブログ記事では、PyTorch FSDPと関連するベストプラクティスを使用して、Llama 2 70Bを微調整する方法について説明します。Hugging Face Transformers、Accelerate、およびTRLを活用します。また、AccelerateをSLURMと一緒に使用する方法も学びます。
Fully Sharded Data Parallelism(FSDP)は、オプティマイザの状態、勾配、およびパラメータをデバイス間でシャードするパラダイムです。フォワードパスでは、各FSDPユニットが完全な重みを取得するための全ギャザー操作を実行し、計算が行われた後に他のデバイスからのシャードを破棄します。フォワードパスの後、ロスが計算され、バックワードパスが行われます。バックワードパスでは、各FSDPユニットが完全な重みを取得するための全ギャザー操作を実行し、ローカルな勾配を取得するための計算が行われます。これらのローカルな勾配は平均化され、リダクション-スキャッタ操作を介してデバイス間でシャードされるため、各デバイスは自身のシャードのパラメータを更新することができます。PyTorch FSDPの詳細については、次のブログ記事を参照してください:PyTorch Fully Sharded Data Parallelを使用した大規模モデルトレーニングの加速。

(出典: リンク)
使用されたハードウェア
ノード数:2。最小要件は1です。ノードあたりのGPU数:8。GPUタイプ:A100。GPUメモリ:80GB。ノード内接続:NVLink。ノードあたりのRAM:1TB。ノードあたりのCPUコア数:96。ノード間接続:Elastic Fabric Adapter。
LLaMa 70Bの微調整における課題
FSDPを使用してLLaMa 70Bを微調整しようとする際に、3つの主な課題に直面しました:
-
FSDPは、事前学習済みモデルをロードした後にモデルをラップします。もし各プロセス/ランクがノード内でLlama-70Bモデルをロードする場合、70*4*8 GB〜2TBのCPU RAMが必要となります。ここで、4はパラメータごとのバイト数、8は各ノードのGPU数です。これにより、CPU RAMがメモリ不足になり、プロセスが終了する可能性があります。
-
CPUオフロードを使用して
FULL_STATE_DICTを使った中間チェックポイントの保存は、時間がかかり、放送中に無期限のハングアップによるNCCLタイムアウトエラーが発生することがよくあります。ただし、トレーニングの最後には、FSDPとのみ互換性のあるシャード状態辞書ではなく、完全なモデルの状態辞書が必要です。 -
スピードを改善し、VRAMの使用量を減らして、より高速にトレーニングし、計算コストを節約する必要があります。
上記の課題を解決して、70Bモデルを微調整する方法について見てみましょう!
はじめる前に、再現可能な結果を再現するために必要なすべてのリソースを以下に示します:
-
コードベース:https://github.com/pacman100/DHS-LLM-Workshop/tree/main/chat_assistant/training(flash-attn V2 monkey patchを使用)
-
FSDPの設定:https://github.com/pacman100/DHS-LLM-Workshop/blob/main/chat_assistant/training/configs/fsdp_config.yaml
-
SLURMスクリプト
launch.slurm:https://gist.github.com/pacman100/1cb1f17b2f1b3139a63b764263e70b25 -
モデル:
meta-llama/Llama-2-70b-chat-hf -
データセット:smangrul/code-chat-assistant-v1(LIMA+GUANACOのミックスで、トレーニング用の適切なフォーマットで提供されています)
前提条件
最初に、以下の手順に従ってFlash Attention V2をインストールしてください:Dao-AILab/flash-attention: Fast and memory-efficient exact attention (github.com)。最新のPyTorch NightliesをCUDA ≥11.8とともにインストールしてください。DHS-LLM-Workshop/code_assistant/training/requirements.txtに従って、残りの要件をインストールしてください。ここでは、🤗 Accelerateと🤗 Transformersをメインブランチからインストールします。
微調整
課題1の解決
PRs huggingface/transformers#25107 と huggingface/accelerate#1777 は最初の課題を解決し、ユーザー側でのコード変更は不要です。以下のことを実行します:
metaデバイスを使用してすべてのランクで重みのないモデルを作成します。- ランク==0 の場合にのみステートディクトを読み込み、ランク0のモデルの重みをそのステートディクトで設定します。
- 他のすべてのランクでは、
metaデバイス上のすべてのパラメータに対してtorch.empty(*param.size(), dtype=dtype)を実行します。 - したがって、ランク==0 は正しいステートディクトでモデルを読み込みますが、他のすべてのランクはランダムな重みを持ちます。
sync_module_states=Trueを設定して、トレーニング開始前に FSDP オブジェクトがそれらをすべてのランクにブロードキャストするようにします。
以下は、2つのGPU上の7Bモデルでメモリ使用量とモデルパラメータを測定した際の出力スニペットです。プリトレーニングモデルの読み込み時、ランク0とランク1のCPUのピークメモリ使用量はそれぞれ 32744 MB と 1506 MB です。したがって、CPU RAMの効率的な使用のために、プリトレーニングモデルの読み込みはランク0のみが行っています。詳細なログはこちらで確認できます。
accelerator.process_index=0 ロード前のGPUメモリ : 0
accelerator.process_index=0 ロード終了時のGPUメモリ消費量 (end-begin): 0
accelerator.process_index=0 ロード中のGPUピークメモリ消費量 (max-begin): 0
accelerator.process_index=0 ロード中のGPUトータルピークメモリ消費量 (max): 0
accelerator.process_index=0 ロード前のCPUメモリ : 926
accelerator.process_index=0 ロード終了時のCPUメモリ消費量 (end-begin): 26415
accelerator.process_index=0 ロード中のCPUピークメモリ消費量 (max-begin): 31818
accelerator.process_index=0 ロード中のCPUトータルピークメモリ消費量 (max): 32744
accelerator.process_index=1 ロード前のGPUメモリ : 0
accelerator.process_index=1 ロード終了時のGPUメモリ消費量 (end-begin): 0
accelerator.process_index=1 ロード中のGPUピークメモリ消費量 (max-begin): 0
accelerator.process_index=1 ロード中のGPUトータルピークメモリ消費量 (max): 0
accelerator.process_index=1 ロード前のCPUメモリ : 933
accelerator.process_index=1 ロード終了時のCPUメモリ消費量 (end-begin): 10
accelerator.process_index=1 ロード中のCPUピークメモリ消費量 (max-begin): 573
accelerator.process_index=1 ロード中のCPUトータルピークメモリ消費量 (max): 1506課題2の解決
これは、FSDP構成を作成する際に SHARDED_STATE_DICT ステートディクトタイプを選択することで解決されます。 SHARDED_STATE_DICT は、各GPUごとにシャードを個別に保存するため、中間チェックポイントからのトレーニングの保存や再開が高速になります。 FULL_STATE_DICT を使用する場合、最初のプロセス(ランク0)がCPU上でモデル全体を収集し、それを標準形式で保存します。
以下のコマンドでアクセラレート構成を作成しましょう:
accelerate config --config_file "fsdp_config.yaml"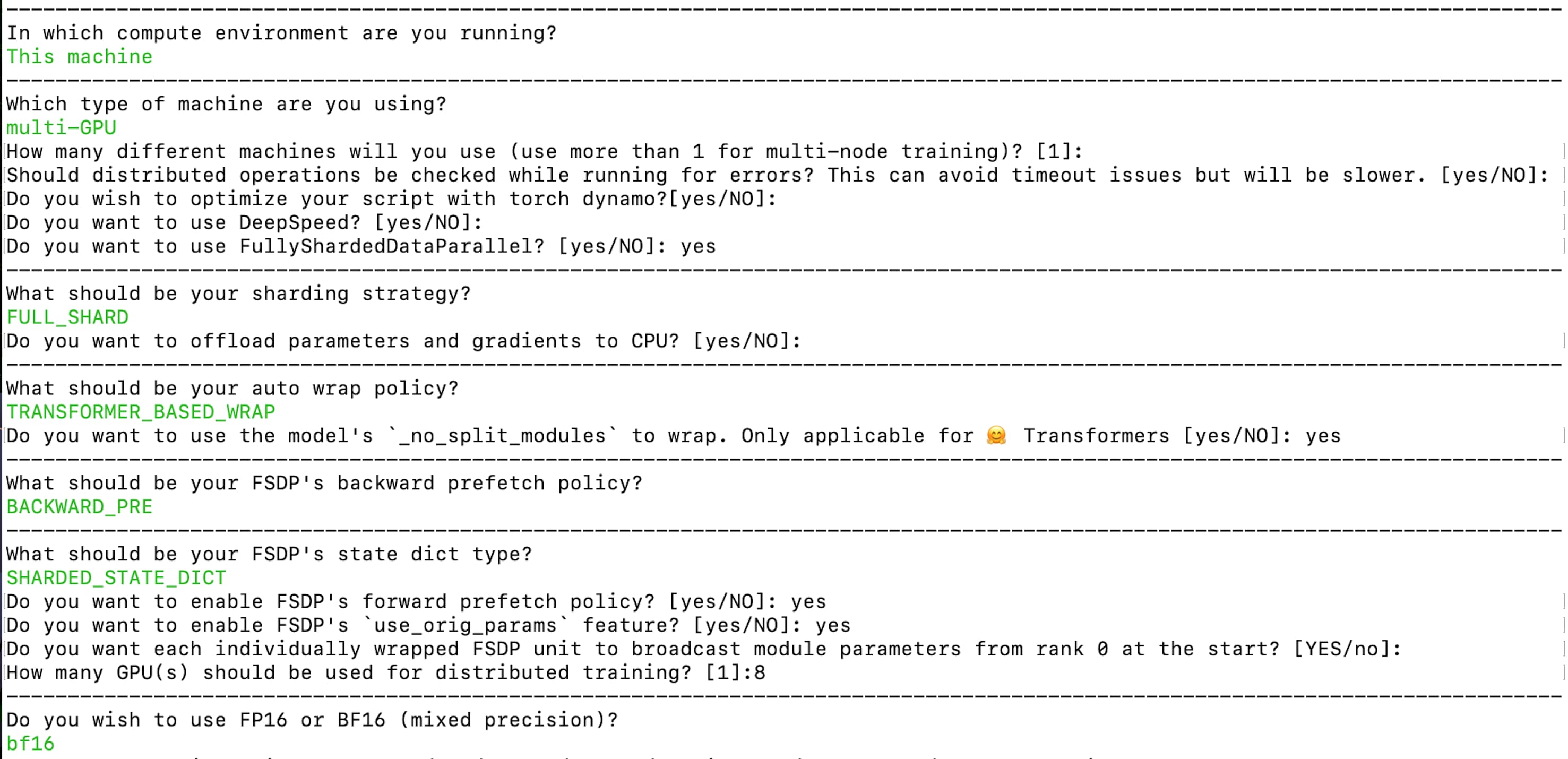
作成された構成はこちらでご覧いただけます:fsdp_config.yaml。ここでは、シャーディング戦略には FULL_SHARD を使用しています。自動ラップポリシーには TRANSFORMER_BASED_WRAP を使用し、ネストされたFSDP自動ラップのために _no_split_module を使用してTransformerブロックの名前を見つけます。中間チェックポイントとオプティマイザのステートを、PyTorchチームが推奨するこの形式で保存するために SHARDED_STATE_DICT を使用しています。課題1の解決に関する前述の段落で、ランク0からモジュールパラメータをブロードキャストするように設定することを忘れないでください。また、bf16 の混合精度トレーニングを有効にしています。
最終的なチェックポイントが全モデルステートディクトである場合、以下のコードスニペットが使用されます:
if trainer.is_fsdp_enabled:
trainer.accelerator.state.fsdp_plugin.set_state_dict_type("FULL_STATE_DICT")
trainer.save_model(script_args.output_dir) # または、trainer.push_to_hub() 50GB未満の場合は、全体の ckpt が LFS の制限(ファイルごとに 50GB)を下回る課題3の対処
高速なトレーニングと VRAM の使用量の削減には、Flash Attention と勾配チェックポイントの有効化が必要です。これにより、ファインチューニングとコンピュートコストの節約が可能になります。現在のコードベースでは、モンキーパッチを使用しており、実装は chat_assistant/training/llama_flash_attn_monkey_patch.py にあります。
FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness は、ハードウェア/GPU のメモリ階層の知識を活用して、高速かつメモリ効率の良い厳密なアテンションを計算する方法を紹介しています。メモリの帯域幅/スピードが高いほど、容量は小さくなり、より高価になるためです。
ブログ「Making Deep Learning Go Brrrr From First Principles」に従えば、現在のハードウェア上の Attention モジュールは、メモリバウンド/帯域幅バウンド であることがわかります。その理由は、アテンションは主に要素ごとの演算からなるためです。以下の左側の図に示すように、マスキング、ソフトマックス、ドロップアウトの演算が時間の大部分を占め、行列の乗算は FLOP の大部分を占めていることがわかります。
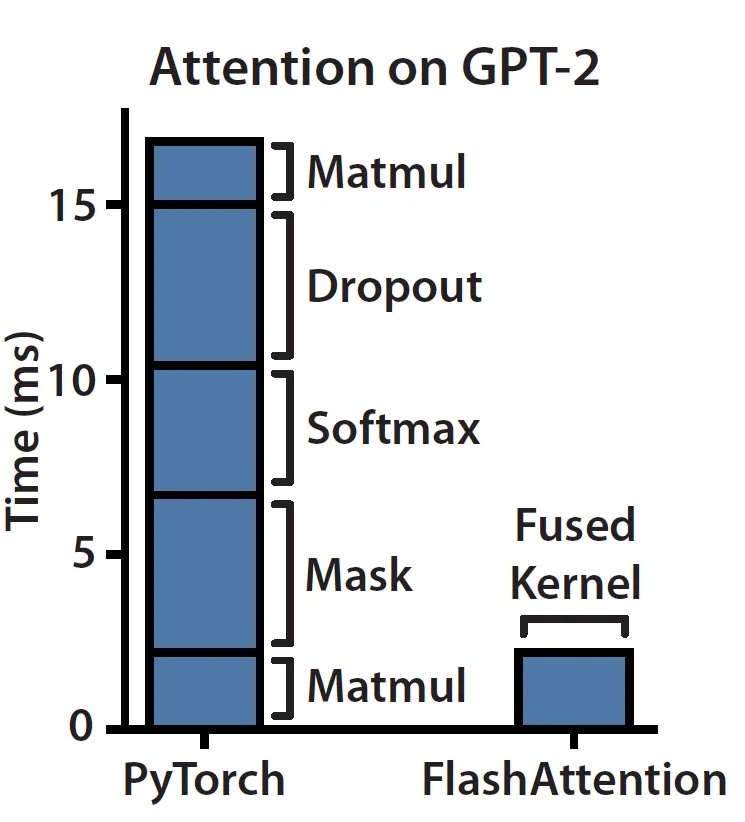
(出典: リンク)
これが Flash Attention が解決する問題です。アイデアは、不要な HBM の読み書きを削除することです。これは、すべてを SRAM に保持し、すべての中間ステップを実行してから最終結果を HBM に書き込む、つまりカーネルフュージョンとも呼ばれる方法です。以下は、これがメモリバウンドのボトルネックを克服する方法のイラストです。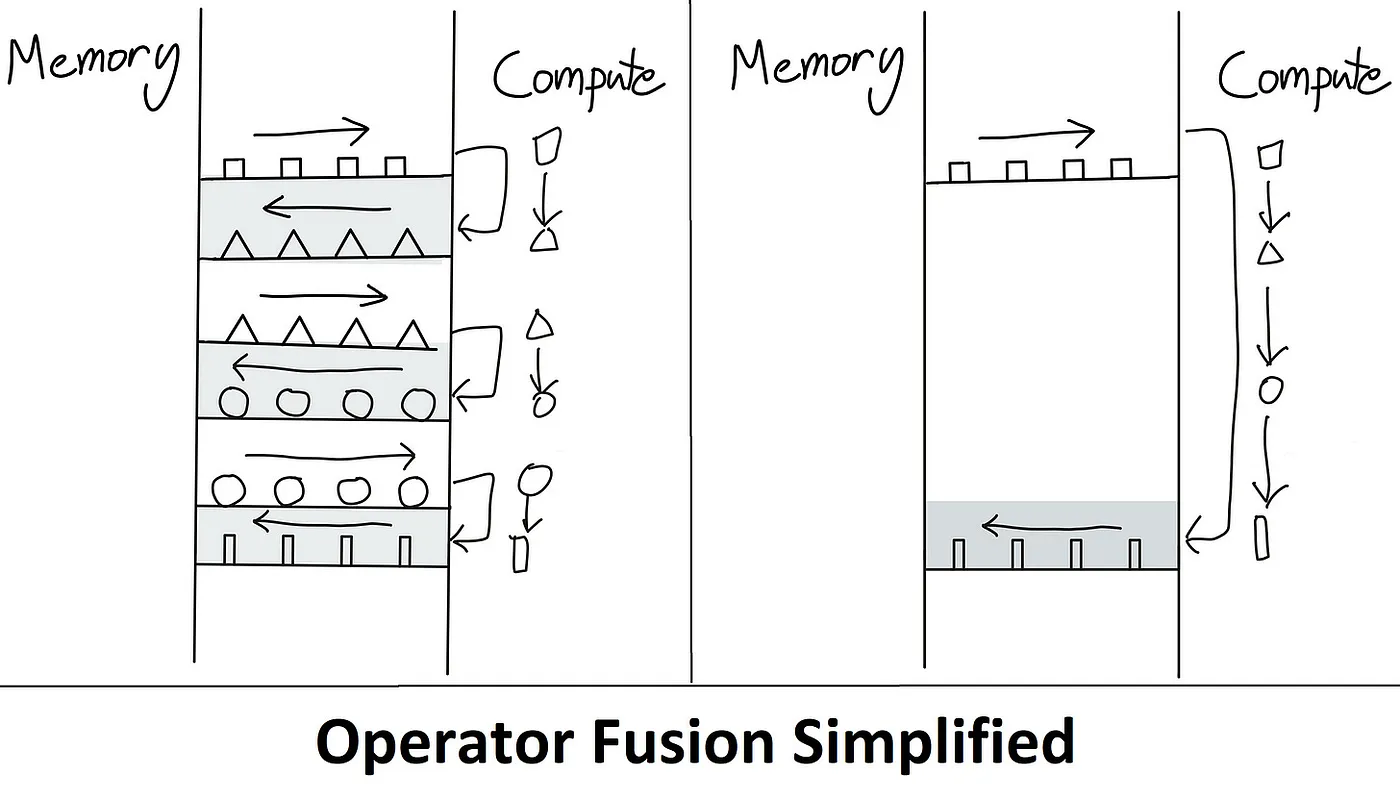
(出典: リンク)
タイリングは、順方向および逆方向のパスで使用され、NxN ソフトマックス/スコアの計算をブロックに分割して SRAM メモリサイズの制限を克服します。タイリングを有効にするためには、オンラインソフトマックスアルゴリズムが使用されます。逆方向のパスでは再計算が使用され、順方向のパスで NxN ソフトマックス/スコア行列全体を保存する必要がありません。これにより、メモリ消費量が大幅に削減されます。
Flash Attention の簡略化された詳細な理解については、ブログ記事 ELI5: FlashAttention と Making Deep Learning Go Brrrr From First Principles および元の論文 FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness を参照してください。
すべてをまとめる
Accelerate ランチャーを使用して SLURM でトレーニングを実行するには、この gist launch.slurm を参照してください。以下は、Accelerate ランチャーを使用してトレーニングを実行する方法を示す同等のコマンドです。ここで注目すべきもう一つの重要なポイントは、ストレージがすべてのノード間で共有されていることです。
accelerate launch \
--config_file configs/fsdp_config.yaml \
--main_process_ip $MASTER_ADDR \
--main_process_port $MASTER_PORT \
--machine_rank \$MACHINE_RANK \
--num_processes 16 \
--num_machines 2 \
train.py \
--model_name "meta-llama/Llama-2-70b-chat-hf" \
--dataset_name "smangrul/code-chat-assistant-v1" \
--max_seq_len 2048 \
--max_steps 500 \
--logging_steps 25 \
--eval_steps 100 \
--save_steps 250 \
--bf16 True \
--packing True \
--output_dir "/shared_storage/sourab/experiments/full-finetune-llama-chat-asst" \
--per_device_train_batch_size 1 \
--gradient_accumulation_steps 1 \
--dataset_text_field "content" \
--use_gradient_checkpointing True \
--learning_rate 5e-5 \
--lr_scheduler_type "cosine" \
--weight_decay 0.01 \
--warmup_ratio 0.03 \
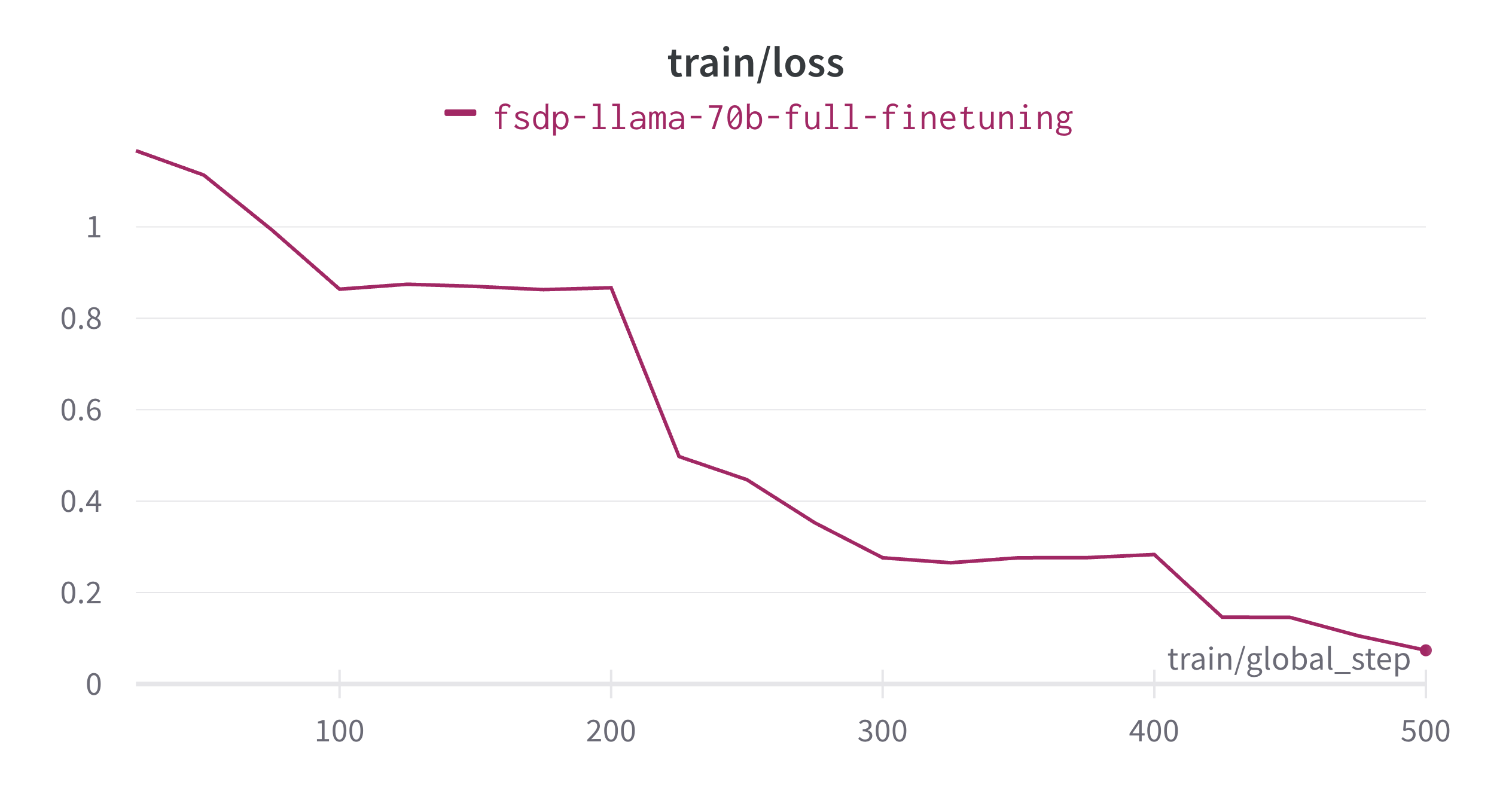
--use_flash_attn Trueファインチューニングは約13.5時間で完了し、以下はトレーニング損失のプロットです。トレーニングランのモデルFlops利用率(MFU)を計算しましょう。
- A100 GPUは秒間約3.12e14 FLOPS(float32またはbfloat16で)を実行します
- 上記の実験でトレーニングされたトークンの数 = シーケンス長 * バッチサイズ * トレーニングステップの数 = (2048 * 16 *
- = 16,384,000 = 1.64e7
- 上記の実験の近似計算 = 6 * P(num_params)* D(num_tokens)= 6 * 7e10 * 1.64e7 = 6.89e18 FLOPS
- トレーニングの秒間FLOPS = 近似計算 / トレーニング時間 = 6.89e17 /(13.5 * 3600)= 6.89e18 / 4.86e4 = 1.42e14 FLOPS/秒
- MFU = トレーニングの秒間FLOPS / Peak A100パフォーマンス = 1.42e14 / 3.12e14 = 0.4551 = ピークパフォーマンスの45.51%
以下は上記のモデルを使用した例の会話です:
システムプロンプト:あなたは親切で礼儀正しく正直なアシスタントです。常に安全にできるだけ役に立つ回答をしてください。あなたの回答には有害、不道徳、人種差別、性差別、有毒、危険、または違法な内容は含めないでください。あなたの回答が社会的に偏見のないものであり、前向きな性質を持っていることを確認してください。
もし質問が意味をなさない場合、または事実に矛盾したものである場合、正確な回答ではなくなぜそれが正しくないのかを説明してください。質問の答えがわからない場合は、虚偽の情報を共有しないでください。
- 人間:ディープラーニングとは何ですか?海賊のように説明してください。
+ アシスタント:ハーッ、グルメ!ディープラーニングのちゃんとした説明を探しているのか?
+ よし、それなら、よく聞け、船員たちよ!ディープラーニングは、データを分析するために人工ニューラルネットワークを使用する機械学習の一種だ。
+ ああ、聞こえたかい、仲間たちよ!人工ニューラルネットワークは、ニューロンを使わずに情報を処理するための相互に接続されたノードまたは「人工ニューロン」を使うんだ。
+ これらのノードは一緒になってデータの大量に学んで、パターンを認識し、独自の判断を下す能力を高めていくんだ。
+ だから、冒険のために帆を揚げて、ディープラーニングの世界に航海しよう、仲間たちよ!それは発見されるのを待ち望んでいる知識の宝庫だ。
+ 順風満帆、そして追い風を!
- 人間:では、シェフのように説明してください。
+ アシスタント:もちろんです!ここでは、料理の観点からディープラーニングの説明をします:
+ レシピを、生の材料を美味しい料理に変えるための手順の連続と考えてみてください。
+ 同様に、ディープラーニングでは、複数の「材料」(または特徴)の層があり、それらが組み合わさり、さまざまな操作を通じて最終的な出力や予測を生成します。
+ 各層は前の層に基づいて構築され、入力データの表現を洗練し、向上させながら、目的の結果に達するまで進化します。
+ 食材によって味が引き立つように、各層はモデルが入力の理解を深め、より正確な予測をするために深みと複雑さを加えます。
+ そして、シェフがレシピの塩分、砂糖、その他の調味料の量を注意深く調整するように、ディープラーニングのトレーニングプロセスでは、ネットワークの重みとバイアスを調整して正確さと効率の完璧なバランスを実現します。
+ 十分な練習と実験を積めば、誰でも料理の名人...いや、ディープラーニングの名人になれるでしょう!いただきます!全体の会話は以下のようにフォーマットされています:
<|system|> システムメッセージ <|endoftext|> <|prompter|> Q1 <|endoftext|> <|assistant|> A1 <|endoftext|> ...結論
私たちは、PyTorch FSDPを使用してマルチノードマルチGPUの環境で70B Llamaモデルを成功裏にファインチューニングしました。FSDPを使用する際にCPUのRAMがメモリ不足になる問題を解決するために、🤗 Transformersと🤗 Acceleratesが効率的な大規模モデルの初期化をサポートする方法を確認しました。これに続いて、中間チェックポイントの保存/ロード方法と最終モデルの保存方法についての推奨事項を説明しました。より高速なトレーニングとGPUメモリの使用量を削減するために、Flash AttentionとGradient Checkpointingの重要性を示しました。全体として、🤗 Accelerateを使用した単純な設定によって、マルチノードマルチGPUの環境でこのような大規模なモデルのファインチューニングが可能であることがわかります。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles






