「PyTorchモデルのパフォーマンス分析と最適化—パート6」
PyTorchモデルのパフォーマンス分析と最適化—パート6
PyTorch Profiler、PyTorch Hooks、およびTensorBoardを使用して、逆伝播の性能問題を特定および分析する方法
これは、PyTorch ProfilerとTensorBoardを使用してPyTorchモデルの分析と最適化のトピックに関する私たちの投稿シリーズの6番目のパートです。この投稿では、特に分析が困難なパフォーマンスの問題の1つであるトレーニングステップの逆伝播パスのボトルネックに取り組みます。このタイプのボトルネックが特に難しいのは何かを説明し、トレーニングステップの異なる部分にフックをアタッチするためのPyTorchの組み込みサポートを使用してそれを分析する1つの方法を提案します。この投稿へのYitzhak Levi氏の貢献に感謝します。
おもちゃのモデル
ディスカッションを容易にするために、人気のあるtimm Pythonモジュール(バージョン0.9.7)を使用して、シンプルなVision Transformer(ViT)ベースの分類モデルを定義します。パッチのドロップ率フラグを0.5に設定したモデルを定義し、モデルは各トレーニングステップでランダムにパッチの半分をドロップするようになります。トレーニングスクリプトは、torch.use_deterministic_algorithms関数とcuBLAS環境変数CUBLAS_WORKSPACE_CONFIGを使用して、非決定性を最小限に抑えるようにプログラムされています。完全なモデル定義については、以下のコードブロックをご覧ください:
import torch, time, osimport torch.optimimport torch.profilerimport torch.utils.datafrom timm.models.vision_transformer import VisionTransformerfrom torch.utils.data import Dataset# GPUを使用するdevice = torch.device("cuda:0")# リプロダシブルアルゴリズムを使用するようにPyTorchを設定torch.manual_seed(0)os.environ[ "CUBLAS_WORKSPACE_CONFIG" ] = ":4096:8"torch.use_deterministic_algorithms(True)# ViTベースの分類モデルを定義するmodel = VisionTransformer(patch_drop_rate=0.5).cuda(device)# 損失関数を定義するloss_fn = torch.nn.CrossEntropyLoss()# トレーニングオプティマイザを定義するoptimizer = torch.optim.SGD(model.parameters(), lr=0.001, momentum=0.9)# ランダムデータを使用するclass FakeDataset(Dataset): def __len__(self): return 1000000 def __getitem__(self, index): rand_image = torch.randn([3, 224, 224], dtype=torch.float32) label = torch.tensor(data=[index % 1000], dtype=torch.int64) return rand_image, labeltrain_set = FakeDataset()train_loader = torch.utils.data.DataLoader(train_set, batch_size=128, num_workers=8, pin_memory=True)t0 = time.perf_counter()summ = 0count = 0model.train()# プロファイラオブジェクトでラップされたトレーニングループwith torch.profiler.profile( schedule=torch.profiler.schedule(wait=1, warmup=4, active=3, repeat=1), on_trace_ready=torch.profiler.tensorboard_trace_handler('/tmp/perf')) as prof: for step, data in enumerate(train_loader): inputs = data[0].to(device=device, non_blocking=True) label = data[1].squeeze(-1).to(device=device, non_blocking=True) with torch.profiler.record_function('forward'): outputs = model(inputs) loss = loss_fn(outputs, label) optimizer.zero_grad(set_to_none=True) with torch.profiler.record_function('backward'): loss.backward() with torch.profiler.record_function('optimizer_step'): optimizer.step() prof.step() batch_time = time.perf_counter() - t0 if step > 1: # 最初のステップはスキップ summ += batch_time count += 1 t0 = time.perf_counter() if step > 500: break print(f'average step time: {summ/count}')私たちは、Amazon EC2 g5.2xlargeインスタンス(NVIDIA A10G GPUと8つのvCPUを搭載)で実験を実行し、公式のAWS PyTorch 2.0 Dockerイメージを使用します。
初期パフォーマンス結果
以下の画像は、TensorBoardプラグインのTrace Viewに表示されるパフォーマンス結果をキャプチャしたものです:
- 機械学習の革新により、コンピュータの電力使用量が削減されています
- StableSRをご紹介します:事前トレーニング済み拡散モデルの力を活用した新たなAIスーパーレゾリューション手法
- 「11/9から17/9までの週のトップ重要なコンピュータビジョンの論文」
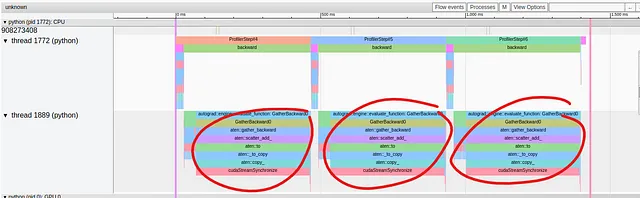
トレーニングステップのフォワードパスでは、操作が上のスレッドにまとめられていますが、バックワードパスではパフォーマンスの問題が発生しているようです。下のスレッドでは、1つの操作である「GatherBackward」がトレースの大部分を占めていることがわかります。詳しく見てみると、基本的な操作には「to」、「copy_」、「cudaStreamSynchronize」などが含まれていることがわかります。シリーズの第2部で見たように、これらの操作は通常、データがホストからデバイスにコピーされていることを示しています。トレーニングステップの途中でこれを避けたいです。
この時点では、自然に次のような疑問がわきます: なぜこれが起こっているのか?そして、どのモデル定義の部分が原因なのか? GatherBackwardのトレースは、torch.gather操作が関与している可能性があることを示唆していますが、それはどこから来ていて、なぜ同期イベントを引き起こしているのでしょうか?
以前の投稿(例えば、こちら)では、torch.profiler.record_functionコンテキストマネージャを使用してパフォーマンスの問題の原因を特定することを提唱しました。問題は、パフォーマンスの問題がバックワードパスで発生することで、私たち自身が制御できないことです!特に、バックワードパスの個々の操作をコンテキストマネージャでラップする能力がありません。理論的には、トレースビューで各セグメントを前方パスの対応する操作と一致させることによって、問題のあるモデル操作を特定することができます。しかし、これは非常に手間がかかるだけでなく、モデルトレーニングステップの低レベルなすべての操作についての詳細な知識を必要とします。torch.profiler.record_functionのラベルを使用する利点は、モデルの問題のある部分に簡単に注目できることでした。理想的には、バックワードパスでのパフォーマンスの問題の場合でも、同じ機能を保持できると良いです。次のセクションでは、PyTorchフックを使用してこれを実現する方法について説明します。
PyTorchバックワードフックによるパフォーマンス分析
PyTorchは個々のバックワードパス操作をラップすることはできませんが、フックサポートを使用してカスタム機能を前後に追加することはできます。PyTorchは、torch.Tensorsとtorch.nn.Modulesの両方にフックを登録することができます。この投稿で提案するテクニックは、モジュールにバックワードフックを登録することに依存しますが、テンソルフックの登録はモジュールベースの方法を置換または拡張するために同様に使用できます。
以下のコードブロックでは、モジュールを受け取り、full_backward_hookとfull_backward_pre_hookの両方を登録するラッパー関数を定義しています(実際には1つだけで十分です)。各フックは、torch.profiler.record_function関数を使用してプロファイリングトレースにメッセージを追加するだけです。backward_pre_hookは「before」メッセージを出力し、backward_hookは「after」メッセージを出力するようにプログラムされています。オプションのdetails文字列は、同じモジュールタイプの複数のインスタンスを区別するために追加されます。
def backward_hook_wrapper(module, details=None): # register_full_backward_pre_hook functionを定義 def bwd_pre_hook_print(self, output): message = f'{module.__class__.__qualname__}のbackward前' if details: message = f'{message}: {details}' with torch.profiler.record_function(message): return output # register_full_backward_hook functionを定義 def bwd_hook_print(self, input, output): message = f'{module.__class__.__qualname__}のbackward後' if details: message = f'{message}: {details}' with torch.profiler.record_function(message): return input # hooksを登録 module.register_full_backward_pre_hook(bwd_pre_hook_print) module.register_full_backward_hook(bwd_hook_print) return modulebackward_hook_wrapper関数を使用することで、パフォーマンスの問題の原因を特定する作業を開始できます。以下のコードブロックのように、モデルと損失関数をラップすることから始めます:
model = backward_hook_wrapper(model)loss_fn = backward_hook_wrapper(loss_fn)TensorBoardプラグインのトレースビューの検索ボックスを使用して、「before」と「after」のメッセージの場所を特定し、モデルと損失の逆伝播の開始と終了の場所を推測することができます。これにより、パフォーマンスの問題がモデルのバックワードパスで発生することがわかります。次のステップは、Vision Tranformerの内部モジュールをbackward_hook_wrapper関数でラップすることです:
model.patch_embed = backward_hook_wrapper(model.patch_embed)model.pos_drop = backward_hook_wrapper(model.pos_drop)model.patch_drop = backward_hook_wrapper(model.patch_drop)model.norm_pre = backward_hook_wrapper(model.norm_pre)model.blocks = backward_hook_wrapper(model.blocks)model.norm = backward_hook_wrapper(model.norm)model.fc_norm = backward_hook_wrapper(model.fc_norm)model.head_drop = backward_hook_wrapper(model.head_drop)上記のコードブロックでは、各内部モジュールを指定しました。モデルの最初のレベルのモジュールをすべてラップする別の方法は、そのnamed_childrenを繰り返し処理することです:
for submodule in model.named_children(): submodule = backward_hook_wrapper(submodule)以下の画像キャプチャでは、問題のあるGatherBackward操作の直前に「PatchDropoutの後方ボード操作」というメッセージが表示されています:

プロファイリング分析により、性能の問題の原因はPathDropoutモジュールであることが示されました。モジュールのforward関数を調べると、確かにtorch.gatherの呼び出しがあることがわかります。
おもちゃのモデルの場合、パフォーマンスの問題の原因を特定するために2回の分析が必要でした。実際には、この方法の追加の反復が必要な場合もあります。
ただし、PyTorchにはtorch.nn.modules.module.register_module_full_backward_hook関数が含まれており、トレーニングステップのすべてのモジュールにフックを追加するために1回の呼び出しだけで済む場合があります。これは単純な場合(おもちゃの例など)では十分かもしれませんが、同じモジュールタイプの異なるインスタンスを区別することはできません。
パフォーマンスの問題の原因がわかったので、修正を試みることができます。
最適化提案:可能な限りtorch.gatherの代わりにインデックスを使用する
問題の原因がDropPatchesモジュールのtorch.gather操作にあることを知ったので、ホストとデバイスの同期イベントのトリガーとなる可能性のあるものを調査することができます。調査は、torch.use_deterministic_algorithms関数のドキュメントに戻り、その関数が勾配を必要とするCUDAテンソルで呼び出された場合、torch.gatherはtorch.use_deterministic_algorithmsをmodeをTrueに設定して呼び出さない限り、非決定論的な動作を示すことを教えてくれます。言い換えれば、スクリプトを決定論的なアルゴリズムを使用するように構成することで、torch.gatherのバックワードパスのデフォルトの動作が変更されました。実際、この変更が同期イベントの必要性を引き起こすのです!問題が解消されることは確かですが、アルゴリズムの決定論性を維持しながらパフォーマンスのペナルティを支払う必要があるかどうか、という問題があります。
以下のコードブロックでは、torch.gatherの代わりにtorch.Tensorのインデックスを使用して同じ出力を生成するPathDropoutモジュールのforward関数の代替実装を提案しています。変更されたコードの行が強調されています。
from timm.layers import PatchDropoutclass MyPatchDropout(PatchDropout): def forward(self, x): prefix_tokens = x[:, :self.num_prefix_tokens] x = x[:, self.num_prefix_tokens:] B = x.shape[0] L = x.shape[1] num_keep = max(1, int(L * (1. - self.prob))) keep_indices = torch.argsort(torch.randn(B, L, device=x.device), dim=-1)[:, :num_keep] # 以下の3行は、元のコードから変更され、torch.gatherの代わりにPyTorchのインデックスを使用しています stride = L * torch.unsqueeze(torch.arange(B, device=x.device), 1) keep_indices = (stride + keep_indices).flatten() x = x.reshape(B * L, -1)[keep_indices].view(B, num_keep, -1) x = torch.cat((prefix_tokens, x), dim=1) return xmodel.patch_drop = MyPatchDropout( prob = model.patch_drop.prob, num_prefix_tokens = model.patch_drop.num_prefix_tokens)以下の画像では、上記の変更後のトレースビューをキャプチャしています:
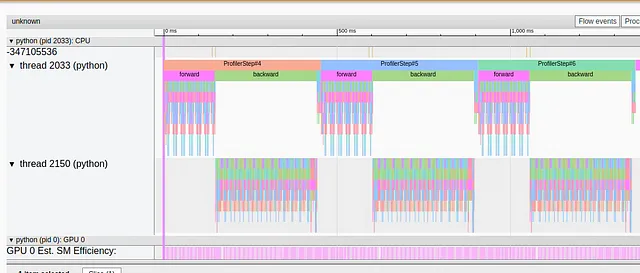
明らかに、長い同期イベントはもはや存在しません。
おもちゃのモデルの場合、torch.gather操作の使用方法がPyTorchのインデックスを使用して置き換えることができるため、幸運でした。これは常にそうではありません。torch.gatherの他の使用方法には、インデックスをベースとした同等の実装がない場合があります。
結果
以下の表では、異なるシナリオでおもちゃのモデルのトレーニングのパフォーマンス結果を比較しています:
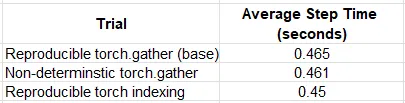
おもちゃの例では、最適化はわずかですが、計測可能な影響を持っていました – パフォーマンスが約2%向上しました。興味深いことに、再現可能モードのtorch indexingは、デフォルトの(非決定論的な)torch.gatherよりも優れたパフォーマンスを発揮しました。これらの結果に基づいて、可能な限りtorch.gatherではなくインデックスを使用するオプションを評価することが良いアイデアかもしれません。
概要
PyTorchはデバッグとトレースが容易であるという(正当な)評判にもかかわらず、torch.autogradは少し謎めいており、トレーニングステップの逆伝播の分析は非常に困難です。この課題に対処するため、PyTorchには逆伝播のさまざまな段階でフックを挿入するサポートが含まれています。この記事では、PyTorchの逆伝播フックとtorch.profiler.record_functionを使用して、逆伝播のパフォーマンス問題の原因を特定するための反復プロセスの使用方法を紹介しました。このテクニックをシンプルなViTモデルに適用し、torch.gather操作のニュアンスについて学びました。
この記事では、非常に特定のタイプのパフォーマンスボトルネックについて取り上げました。パフォーマンス分析と機械学習ワークロードのパフォーマンス最適化に関するさまざまなトピックを扱ったVoAGIの他の記事もぜひご覧ください。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- 無料でGoogle Colab上でQLoraを使用してLLAMAv2を微調整する
- 「ビデオセグメンテーションはよりコスト効果的になることができるのか?アノテーションを節約し、タスク間で一般化するための分離型ビデオセグメンテーションアプローチDEVAに会いましょう」
- 「教科書で学ぶ教師なし学習:K-Meansクラスタリングの実践」
- オーディオSRにお会いください:信じられないほどの48kHzの音質にオーディオをアップサンプリングするためのプラグ&プレイであり、ワンフォーオールのAIソリューション
- LLMs(Language Model)と知識グラフ
- 「ベイチュアン2に会おう:7Bおよび13Bのパラメータを持つ大規模な多言語言語モデルのシリーズ、2.6Tトークンでゼロからトレーニングされました」
- 「機械学習が間違いを comitte たとき、それはどういう意味ですか?」




