「PyTorchモデルのパフォーマンス分析と最適化 – パート3」
PyTorchモデルのパフォーマンス分析と最適化 - パート3
「Cuda Memcpy Async」イベントを減らす方法とブールマスク操作に注意すべき理由
これは、PyTorch ProfilerとTensorBoardを使用してPyTorchモデルの分析と最適化を行うトピックに関する一連の投稿の3番目の部分です。私たちの意図は、GPUベースのトレーニングワークロードのパフォーマンスプロファイリングと最適化の利点、およびそれらがトレーニングの速度とコストに与える潜在的な影響を強調することです。特に、PyTorch ProfilerやTensorBoardなどのプロファイリングツールのアクセス性を、すべてのML開発者に示したいと考えています。私たちの投稿で議論する技術を適用することで、CUDAの専門知識を持っていなくても意味のあるパフォーマンスの向上を得ることができます。
最初の投稿では、PyTorch Profiler TensorBoardプラグインの異なるビューがパフォーマンスの問題を特定するためにどのように使用されるかを示し、トレーニングの加速化のためのいくつかの人気のある技術をレビューしました。2番目の投稿では、TensorBoardプラグインのTrace ViewがCPUからGPUへ、そして逆にテンソルをコピーしているときにどのように使用されるかを示しました。このようなデータの移動は、同期ポイントを引き起こし、トレーニングの速度を遅くする可能性がありますが、これは意図せずに行われることが多く、簡単に回避できる場合もあります。この投稿のトピックは、テンソルのコピーとは関係のないGPUとCPUの同期ポイントに遭遇する状況です。テンソルのコピーと同様に、これらはトレーニングステップの停滞を引き起こし、トレーニング全体の時間を遅くする原因となります。こうした発生箇所の存在、PyTorch ProfilerとPyTorch Profiler TensorBoardプラグインのTrace Viewを使用してそれらを特定する方法、およびそのような同期イベントを最小限に抑えるようにモデルを構築することの潜在的なパフォーマンスの利点を示します。
前の投稿と同様に、トイPyTorchモデルを定義し、そのパフォーマンスを繰り返しプロファイルし、ボトルネックを特定し、修正しようとします。私たちは、Amazon EC2 g5.2xlargeインスタンス(NVIDIA A10G GPUと8つのvCPUを含む)と公式のAWS PyTorch 2.0 Dockerイメージで実験を実行します。説明する動作の一部は、PyTorchのバージョンによって異なる場合があることに注意してください。
トイの例
次のブロックでは、256×256の入力画像に対して意味セグメンテーションを行うトイPyTorchモデルを紹介します。つまり、256×256のRGB画像を受け取り、10のセマンティックカテゴリーからなるクラスの「ピクセルごと」のラベルの256×256マップを出力します。
- 「ビジョン・ランゲージの交差点でのブレイクスルー:オールシーイングプロジェクトの発表」
- 「大規模言語モデルのパディング — Llama 2を用いた例」
- 「オーディオソース分離のマスターキー:AudioSepを紹介して、あなたが説明するものを分離します」
import torchimport torch.nn as nnimport torch.nn.functional as Fimport torch.optimimport torch.profilerimport torch.utils.datafrom torch import Tensorclass Net(nn.Module): def __init__(self, num_hidden=10, num_classes=10): super().__init__() self.conv_in = nn.Conv2d(3, 10, 3, padding='same') hidden = [] for i in range(num_hidden): hidden.append(nn.Conv2d(10, 10, 3, padding='same')) hidden.append(nn.ReLU()) self.hidden = nn.Sequential(*hidden) self.conv_out = nn.Conv2d(10, num_classes, 3, padding='same') def forward(self, x): x = F.relu(self.conv_in(x)) x = self.hidden(x) x = self.conv_out(x) return xモデルをトレーニングするために、いくつかの修正を加えた標準のクロスエントロピー損失を使用します:
- 損失の計算から除外したいピクセルを示す無視値をターゲットラベルに含むと仮定します。
- セマンティックラベルの1つが画像の「背景」に属する特定のピクセルを識別すると仮定します。これらを無視ラベルとして扱うように損失関数を定義します。
- 少なくとも2つのユニークな値を含むターゲットテンソルを持つバッチに出会ったときにのみ、モデルの重みを更新します。
これらの修正は、私たちのデモの目的のために選ばれたものですが、この種の操作は一般的であり、多くの「標準的な」PyTorchモデルで見つけることができます。パフォーマンスプロファイリングについてはすでに「専門家」ですので、既に損失関数の各操作をtorch.profiler.record_functionのコンテキストマネージャーでラップしています(2番目の投稿で説明されています)。
class MaskedLoss(nn.Module): def __init__(self, ignore_val=-1, num_classes=10): super().__init__() self.ignore_val = ignore_val self.num_classes = num_classes self.loss = torch.nn.CrossEntropyLoss() def cross_entropy(self, pred: Tensor, target: Tensor) -> Tensor: # 有効なラベルのブールマスクを作成する with torch.profiler.record_function('create mask'): mask = target != self.ignore_val # ロジットをマスクするためにパーミューテーションを行う with torch.profiler.record_function('permute'): permuted_pred = torch.permute(pred, [0, 2, 3, 1]) # ターゲットとロジットにブールマスクを適用する with torch.profiler.record_function('mask'): masked_target = target[mask] masked_pred = permuted_pred[mask.unsqueeze(-1).expand(-1, -1, -1, self.num_classes)] masked_pred = masked_pred.reshape(-1, self.num_classes) # クロスエントロピー損失を計算する with torch.profiler.record_function('calc loss'): loss = self.loss(masked_pred, masked_target) return loss def ignore_background(self, target: Tensor) -> Tensor: # "background" ラベルがあるインデックスを見つける with torch.profiler.record_function('non_zero'): inds = torch.nonzero(target == self.num_classes - 1, as_tuple=True) # "background" ラベルを無視インデックスにリセットする with torch.profiler.record_function('index assignment'): target[inds] = self.ignore_val return target def forward(self, pred: Tensor, target: Tensor) -> Tensor: # 背景ラベルを無視する target = self.ignore_background(target) # ターゲット内の一意の要素のリストを取得する with torch.profiler.record_function('unique'): unique = torch.unique(target) # 一意のアイテムの数がしきい値を超えているかどうかをチェックする with torch.profiler.record_function('numel'): ignore_loss = torch.numel(unique) < 2 # クロスエントロピー損失を計算する loss = self.cross_entropy(pred, target) # 一意の要素の数がしきい値を下回る場合、損失をゼロにする if ignore_loss: loss = 0. * loss return loss私たちの損失関数はかなり無害に見えますね。しかし、以下に示すように、損失関数にはホストとデバイスの同期イベントを引き起こす操作が含まれており、これによりトレーニングの速度がかなり遅くなります。これらの操作には、テンソルのGPUへのコピーまたはGPUからのコピーは含まれていません。前回の投稿と同様に、パフォーマンスの最適化のための3つの機会を特定してみてください。
デモの目的で、以下で定義されるランダムに生成されたイメージとピクセルごとのラベルマップを使用します。
from torch.utils.data import Dataset# ランダムなイメージとラベルマップを持つデータセットclass FakeDataset(Dataset): def __init__(self, num_classes=10): super().__init__() self.num_classes = num_classes self.img_size = [256, 256] def __len__(self): return 1000000 def __getitem__(self, index): rand_image = torch.randn([3]+self.img_size, dtype=torch.float32) rand_label = torch.randint(low=-1, high=self.num_classes, size=self.img_size) return rand_image, rand_labeltrain_set = FakeDataset()train_loader = torch.utils.data.DataLoader(train_set, batch_size=256, shuffle=True, num_workers=8, pin_memory=True)最後に、PyTorch Profilerを使用して設定したトレーニングステップを定義します。
device = torch.device("cuda:0")model = Net().cuda(device)criterion = MaskedLoss().cuda(device)optimizer = torch.optim.SGD(model.parameters(), lr=0.001, momentum=0.9)model.train()# プロファイラオブジェクトでラップされたトレーニングループwith torch.profiler.profile( schedule=torch.profiler.schedule(wait=1, warmup=4, active=3, repeat=1), on_trace_ready=torch.profiler.tensorboard_trace_handler('/tmp/prof'), record_shapes=True, profile_memory=True, with_stack=True) as prof: for step, data in enumerate(train_loader): inputs = data[0].to(device=device, non_blocking=True) labels = data[1].to(device=device, non_blocking=True) if step >= (1 + 4 + 3) * 1: break outputs = model(inputs) loss = criterion(outputs, labels) optimizer.zero_grad(set_to_none=True) loss.backward() optimizer.step() prof.step()もしもこのトレーニングスクリプトを単純に実行すると、おそらくGPUの利用率が高く(約90%)、何か問題があることを知ることはありません。パフォーマンスプロファイリングによって、潜在的なパフォーマンスのボトルネックやトレーニングの高速化の機会を特定することができます。それではさっそく、モデルのパフォーマンスを見てみましょう。
初期パフォーマンスの結果
この記事では、PyTorch Profiler TensorBoardプラグインのトレースビューに焦点を当てます。その他のビューの使用方法については、プラグインがサポートする他のビューに関する以前の記事をご覧ください。
以下の画像は、トイモデルの単一のトレーニングステップのトレースビューを示しています。
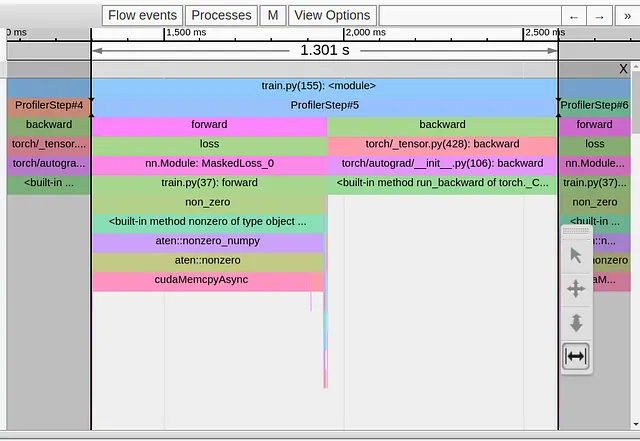
はっきりとわかるように、1.3秒のトレーニングステップは、ロス関数の最初の行のtorch.nonzero演算子に完全に支配されています。他のすべての演算は、巨大なcudaMemcpyAsynイベントの両側にまとめられています。一体どうなっているのでしょうか?!なぜ、そんなに無害な操作が目立つほどの問題を引き起こすのでしょうか。
おそらく驚くべきことではありません。torch.nonzeroのドキュメントには次のような注意書きが含まれています。「inputがCUDA上にある場合、torch.nonzero()はホストとデバイスの同期を引き起こします。」同期の必要性は、他の一般的なPyTorchの演算子とは異なり、torch.nonzeroが返すテンソルのサイズが事前に決まっていないことから生じます。CPUは入力テンソル内の非ゼロの要素の数を事前に知りません。適切なGPUメモリの割り当てと後続のPyTorch演算子の適切な準備を行うために、GPUからの同期イベントを待つ必要があります。
cudaMempyAsyncの長さは、torch.nonzero演算子の複雑さを示すものではなく、CPUがGPUが実行した前のすべてのカーネルの完了を待つために必要な時間を反映しています。たとえば、最初の呼び出しの直後に追加のtorch.nonzero呼び出しを行った場合、2番目のcudaMempyAsyncイベントは最初のものよりもはるかに短く表示されます。なぜなら、CPUとGPUはすでにほぼ「同期」しているからです。(これは非CUDAの専門家からの説明ですので、ご自身の判断にお任せします…)
最適化#1:torch.nonzero演算子の使用を減らす
ボトルネックの原因がわかったので、課題は同じロジックを実行する代替の操作のシーケンスを見つけることですが、ホストとデバイスの同期イベントをトリガーしないものです。ロス関数の場合、以下のコードブロックに示すように、torch.where演算子を使用してこれを簡単に実現できます。
def ignore_background(self, target: Tensor) -> Tensor: with torch.profiler.record_function('update background'): target = torch.where(target==self.num_classes-1, -1*torch.ones_like(target),target) return target以下の画像は、この変更後のトレースビューを示しています。
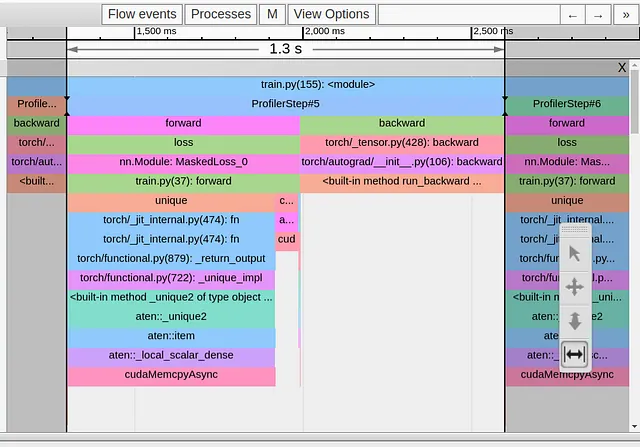
torch.nonzero演算子から来るcudaMempyAsyncを削除することに成功しましたが、代わりにtorch.unique演算子から来るcudaMempyAsyncがすぐに置き換えられ、ステップの時間は変わりませんでした。ここでは、PyTorchのドキュメントは少し厳しいですが、前の経験に基づいて、サイズが決まっていないテンソルの使用によるホストとデバイスの同期イベントに苦しんでいると推測できます。
最適化#2:torch.unique演算子の使用を減らす
torch.unique演算子を同等の代替に置き換えることは常に可能ではありません。ただし、私たちの場合、ユニークなラベルの値を知る必要は実際にはありません。ユニークなラベルの数だけを知る必要があります。これは、フラット化されたターゲットテンソルにtorch.sort演算子を適用し、その結果のステップ関数のステップ数をカウントすることで計算できます。
def forward(self, pred: Tensor, target: Tensor) -> Tensor: # バックグラウンドのラベルを無視する
target = self.ignore_background(target)
# ラベルのリストをソートする
with torch.profiler.record_function('sort'):
sorted,_ = torch.sort(target.flatten())
# 結果のステップ関数のステップを特定する
with torch.profiler.record_function('deriv'):
deriv = sorted[1:]-sorted[:-1]
# ステップの数を数える
with torch.profiler.record_function('count_nonzero'):
num_unique = torch.count_nonzero(deriv)+1
# クロスエントロピー損失を計算する
loss = self.cross_entropy(pred, target)
# ユニークな要素の数が閾値未満の場合、損失をゼロにする
with torch.profiler.record_function('where'):
loss = torch.where(num_unique<2, 0.*loss, loss)
return loss以下の画像は、2番目の最適化に続いてキャプチャしたトレースビューを示しています:
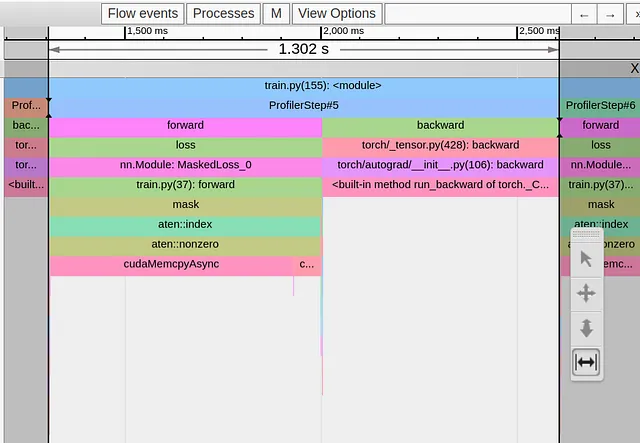
再び、1つのボトルネックを解決したばかりで、今度はブールマスクルーチンからの新たな課題に直面しています。
ブールマスキングは、必要な機械演算の総数を削減するために一般的に使用するルーチンです。私たちの場合、私たちの意図は、「無視」ピクセルを削除し、関心のあるピクセルに限定してクロスエントロピーの計算を行うことで、計算量を削減することでした。しかし、これは裏目に出ています。ブールマスクを適用すると、サイズが不明なテンソルが生成され、それによってトリガされるcudaMempyAsyncが「無視」ピクセルを除外することから得られる節約を大きく上回ってしまいます。
最適化 #3: ブールマスク操作に注意
私たちの場合、この問題を修正するのは非常に簡単です。PyTorchのCrossEntropyLossには、ignore_indexを設定するための組み込みオプションがあります。
class MaskedLoss(nn.Module): def __init__(self, ignore_val=-1, num_classes=10): super().__init__() self.ignore_val = ignore_val self.num_classes = num_classes self.loss = torch.nn.CrossEntropyLoss(ignore_index=-1) def cross_entropy(self, pred: Tensor, target: Tensor) -> Tensor: with torch.profiler.record_function('calc loss'): loss = self.loss(pred, target) return loss以下の画像は、結果のトレースビューを示しています:

すごい!!ステップ時間が5.4ミリ秒まで低下しました。最初の状態から見ると、240倍も高速化されています。わずかな関数呼び出しの変更だけで、損失関数のロジックを変更することなく、トレーニングステップのパフォーマンスを劇的に最適化することができました。
重要な注意事項: 選んだサンプル例では、cudaMempyAsyncイベントの数を減らすために取った手順がトレーニングステップの時間に明確な影響を与えています。ただし、同じ種類の変更がパフォーマンスを損なう場合もあります。たとえば、ブールマスキングの場合、マスクが非常に疎であり、元のテンソルが非常に大きい場合、マスクを適用することによる計算の節約がホストデバイスの同期のコストを上回る可能性があります。重要なことは、各最適化の影響は個別のケースごとに評価する必要があるということです。
まとめ
この記事では、ホストデバイスの同期イベントによって引き起こされるトレーニングアプリケーションのパフォーマンスの問題に焦点を当てました。PyTorchの演算子でこのようなイベントをトリガーする例をいくつか見ました。すべての共通点は、出力テンソルのサイズが入力に依存していることです。この記事では、PyTorch Profilerおよび関連するTensorBoardプラグインなどのパフォーマンス分析ツールを使用して、このようなイベントを特定する方法を示しました。
私たちのおもちゃの例では、固定サイズのテンソルを使用し、同期イベントの必要性を回避する問題の演算子に対して同等の代替案を見つけることができました。これにより、トレーニング時間が大幅に改善されました。しかし、実際のところ、このようなボトルネックを解決するのははるかに困難であり、場合によっては不可能かもしれません。場合によっては、これらを克服するためにモデルの一部を再設計する必要があるかもしれません。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- 「RBIは、規制監督のためにAIを活用するために、マッキンゼーとアクセンチュアと提携します」
- このAIの論文では、非英語の言語で事前学習されたLLMsを強化するために、言語間で意味の整合性を構築することを提案しています
- 「ステレオタイプやディスインフォメーションに対抗するAIヘイトスピーチ検出」
- 「Mozilla Common Voiceにおける音声言語認識 — 音声変換」
- スタビリティAIが日本語のStableLMアルファを発表:日本語言語モデルの飛躍的な進化
- PlayHTチームは、感情の概念を持つAIモデルをGenerative Voice AIに導入しますこれにより、特定の感情で話しの生成を制御し、指示することができるようになります
- 大規模言語モデルは、テキスト評価のタスクで人間を置き換えることができるのか? このAI論文では、テキストの品質を評価するためにLLMを使用し、人間の評価の代替手段として提案しています





