PyTorchを使用してx86 CPU上で推論速度を最大9倍高速化する方法
PyTorchを使ってx86 CPU上で推論速度を最大9倍高速化する方法
数行のコードで印象的な結果を実現するための完全ガイド!

トップのML論文、求人情報、実際の経験からのMLのヒント、研究者や開発者からのMLストーリーなど、このような深い洞察を得るには、こちらのニュースレターに参加してください。
量子化:何かとなぜか
ディープラーニングにおける量子化とは、モデルの重みとバイアスを表すビット数を減らすプロセスを指します。これは、モデルを圧縮し、特にモバイル電話、エッジデバイス、組み込みシステムなどのリソース制約のあるデバイスでの展開を効率化するための技術です。
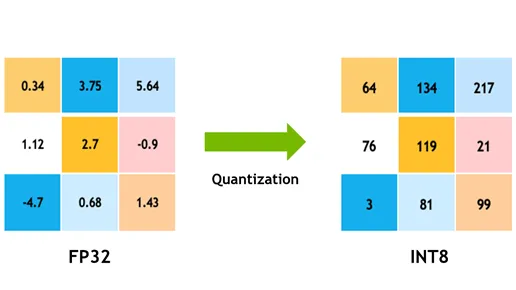
動作原理
- 重みの量子化:ニューラルネットワークの重みの連続値を離散値のセットにマッピングします。たとえば、重みを表すために32ビット浮動小数点数ではなく、8ビット整数を使用することがあります。これにより、各重みを保存するために必要なメモリが4分の1に減少します。
- 活性化の量子化:重みと同様に、活性化(層の出力)も量子化することができます。これは重要です。推論中には、中間の活性化を保存する必要があり、低い精度を使用することでメモリを節約することができます。
- 量子化レベル:量子化は、バイナリ(1ビット)から三値(2ビット)およびより一般的には8ビットまでのさまざまな精度レベルで行うことができます。精度の選択は、モデルのサイズ、計算効率、精度の間のトレードオフです。
- 量子化によるトレーニング:事前にトレーニングされたモデルを直接量子化することもできますが、通常は量子化を考慮してモデルを微調整またはトレーニングする方が良いです。これは、量子化意識トレーニング(QAT)として知られています。QAT中、モデルは量子化プロセスを認識し、重みを調整して精度の損失を最小化することができます。
なぜ必要なのか
- モデルサイズの削減:量子化されたモデルはより少ないメモリを必要とします。…
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles






