「セマンティックカーネルへのPythonistaのイントロ」
Pythonista's Intro to Semantic Kernel
ChatGPTのリリース以来、大規模言語モデル(LLM)は産業界やメディアの両方で非常に注目されており、ほとんどあり得ないあらゆる文脈でLLMを活用しようとする前例のない需要が生まれています。
Semantic Kernelは、Microsoftが元々開発したオープンソースのSDKであり、Microsoft 365 CopilotやBingなどの製品を支えるために設計されています。このSDKはLLMをアプリケーションに統合することを容易にし、自然言語のクエリやコマンドに基づいてワークフローを編成するためにLLMを活用することができます。また、このモデルが完了に必要な追加機能を提供する外部サービスとこれらのモデルを接続することができます。
Microsoftのエコシステムを念頭に置いて作成されたため、現在利用可能な複雑な例の多くはC#で書かれており、Python SDKに焦点を当てたリソースは少ないです。このブログ記事では、Pythonを使用してSemantic Kernelを使い始める方法を紹介し、主要なコンポーネントを紹介し、これらを使用してさまざまなタスクを実行する方法を探ります。
この記事でカバーする内容は以下の通りです:
- 「PyTorchのネステロフモーメンタムの実装は間違っていますか?」
- 「ニューラルネットワークの多様性の力を解き放つ:適応ニューロンが画像分類と非線形回帰で均一性を上回る方法」
- 「本番環境での機械学習モデルのモニタリング:なぜ必要であり、どのように行うか?」
- カーネル
- コネクタ
- セマンティック関数- セマンティック関数の設定の作成- カスタムコネクタの作成
- チャットサービスの使用- シンプルなチャットボットの作成
- メモリ- テキスト埋め込みサービスの使用- コンテキストにメモリを統合する
- プラグイン- 既製のプラグインの使用- カスタムプラグインの作成- 複数のプラグインの連鎖
- プランナーを使用したワークフローの編成
免責事項:Semantic Kernelは、LLMに関連するすべてのものと同様に非常に迅速に進化しています。そのため、インターフェースは時間の経過とともにわずかに変更される場合があります。可能な限り、この記事を最新の情報に保つように努めます。
私はMicrosoftで働いていますが、Semantic Kernelをどのような形で宣伝するよう求められたり、報酬を受け取ったりすることはありません。産業ソリューションエンジニアリング(ISE)では、状況や取り組んでいる顧客に応じて最適なツールを使用することに誇りを持っています。Microsoft製品を使用しない場合、製品チームに対して使用しない理由や不足している領域、改善できる点について詳細なフィードバックを提供します。このフィードバックループは通常、Microsoft製品が私たちのニーズに適していることを示す結果となります。
ここでは、いくつかの粗削りな箇所があるにもかかわらず、Semantic Kernelは非常に有望であり、他のいくつかの解決策と比較して、Semantic Kernelのデザイン選択肢を好むため、Semantic Kernelの宣伝を選択しています。
執筆時点で使用されているパッケージは次のとおりです:
dependencies: - python=3.10.1.0 - pip: - semantic-kernel==0.3.10.dev - timm==0.9.5 - transformers==4.32.0 - sentence-transformers==2.2.2 - curated-transformers==1.1.0Tl;dr:直接使用できる実行可能な動作するコードを見たい場合は、この記事を複製するために必要なすべてのコードがこちらのノートブックとして利用可能です。
謝辞
私は同僚のKarol Zakに感謝します。Semantic Kernelを最大限に活用する方法について共同で研究し、この記事のいくつかの例にインスピレーションを与えたコードを提供してくれました!
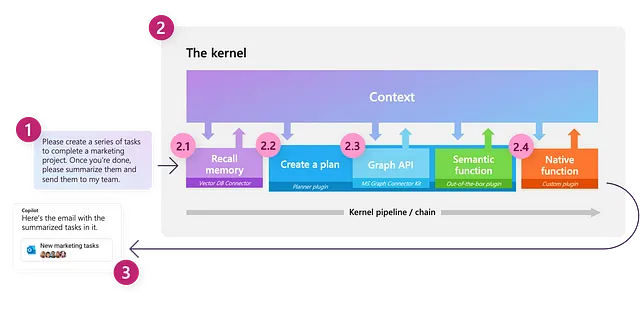
さて、ライブラリの中心的なコンポーネントから始めましょう。
カーネル
カーネル:「オブジェクトやシステムの核、中心、または本質」— ウィクショナリー
Semantic Kernelの中で重要な概念の1つは、カーネル自体です。これは、LLMベースのワークフローを編成するために使用する主要なオブジェクトであり、非常に限定的な機能しか持っていません。すべての機能は、主に接続する外部コンポーネントによって提供されます。カーネルは、要求を実行するために適切なコンポーネントを呼び出すことによってタスクを完了します。
以下にカーネルの作成方法を示します:
import semantic_kernel as skkernel = sk.Kernel()コネクター
私たちのカーネルを有用にするためには、1つ以上のAIモデルを接続する必要があります。これにより、カーネルを使用して自然言語を理解し、生成することができます。これはコネクターを使用して行われます。Semantic Kernelには、OpenAI、Azure OpenAI、Hugging Faceなど、さまざまなソースからAIモデルを追加するのが簡単になる予め用意されたコネクターがあります。これらのモデルは、カーネルにサービスを提供するために使用されます。
執筆時点では、以下のサービスがサポートされています:
- テキスト補完サービス:自然言語の生成に使用されます
- チャットサービス:会話の体験を作成するために使用されます
- テキスト埋め込み生成サービス:自然言語を埋め込みにエンコードするために使用されます
各種サービスは、同時に複数のソースから複数のモデルをサポートすることができます。これにより、タスクやユーザーの好みに応じて異なるモデル間を切り替えることが可能です。特定のサービスやモデルが指定されていない場合、カーネルは最初に定義されたサービスとモデルをデフォルトとして使用します。
現在登録されているすべてのサービスは、次のメソッドを使用して確認することができます:
def print_ai_services(kernel): print(f"テキスト補完サービス: {kernel.all_text_completion_services()}") print(f"チャットサービス: {kernel.all_chat_services()}") print( f"テキスト埋め込み生成サービス: {kernel.all_text_embedding_generation_services()}" )
予想通り、現在接続されているサービスはありません!それを変えましょう。
ここでは、AzureのサブスクリプションでAzure OpenAIサービスを使用して展開したGPT3.5-turboモデルにアクセスして開始します。
このモデルはテキスト補完とチャットの両方に使用できるため、両方のサービスを使用して登録します。
from semantic_kernel.connectors.ai.open_ai import ( AzureChatCompletion, AzureTextCompletion,)kernel.add_text_completion_service( service_id="azure_gpt35_text_completion", service=AzureTextCompletion( OPENAI_DEPLOYMENT_NAME, OPENAI_ENDPOINT, OPENAI_API_KEY ),)gpt35_chat_service = AzureChatCompletion( deployment_name=OPENAI_DEPLOYMENT_NAME, endpoint=OPENAI_ENDPOINT, api_key=OPENAI_API_KEY,)kernel.add_chat_service("azure_gpt35_chat_completion", gpt35_chat_service)これで、チャットサービスがテキスト補完サービスとチャットサービスの両方として登録されました。

非Azure OpenAI APIを使用する場合、変更する必要があるのは、Azureのクラスの代わりにOpenAITextCompletionとOpenAIChatCompletionのコネクターを使用することです。OpenAIモデルにアクセスできない場合でも心配しないでください。後ほどオープンソースモデルに接続する方法を見ていきます。モデルの選択は、次の手順には影響しません。
いくつかのサービスを登録したので、それらとの対話方法を探ってみましょう!
セマンティック関数
Semantic Kernelを介してLLMと対話する方法は、セマンティック関数を作成することです。セマンティック関数は自然言語の入力を想定し、LLMを使用して要求された内容を解釈し、適切な応答を返すために動作します。例えば、テキスト生成、要約、感情分析、質問応答などのタスクにセマンティック関数を使用することができます。
Semantic Kernelでは、セマンティック関数は2つのコンポーネントで構成されます:
- プロンプトテンプレート:LLMに送信される自然言語のクエリまたはコマンド
- 設定オブジェクト:セマンティック関数の設定やオプションを含みます。たとえば、使用するサービス、期待されるパラメータ、関数の説明など。
最も簡単な方法は、カーネルのcreate_semantic_functionメソッドを使用することです。このメソッドは通常LLMが必要とするtemperatureやmax_tokensなどの固定引数を受け入れ、それらを使用して設定を構築します。
これを説明するために、簡単なプロンプトを作成しましょう:
prompt = """{{$input}}はの首都です。"""generate_capital_city_text = kernel.create_semantic_function( prompt, max_tokens=100, temperature=0, top_p=0)ここでは、{{$}}構文を使用して、プロンプトに注入される引数を表します。この投稿全体でこれに関するさらなる例を見ることができますが、テンプレート構文の包括的なガイドはドキュメントで見つけることができます。
以下に、セマンティック関数の詳細を調べることができます:

ここでは、説明が一般的なものとされていることがわかります。
では、この関数を呼び出すだけで使用することができます:
response = generate_capital_city_text("パリ")また、カーネルのほとんどのメソッドはAsyncioを使用した非同期呼び出しもサポートしています。接続されたサービスの多くが外部APIを呼び出しているため、イベントループ上で実行されるアプリケーションでセマンティック関数を使用する場合、非同期呼び出しはパフォーマンスの向上に役立ちます。
以下のように行うことができます。
response = await generate_capital_city_text.invoke_async("パリ")レスポンスオブジェクトには、エラーが発生したかどうかやその内容など、関数呼び出しに関する貴重な情報が含まれています。すべてが予想通りに動作した場合、結果にはresponse.resultを使用してアクセスできます。

レスポンスを出力すると、結果にアクセスできます。
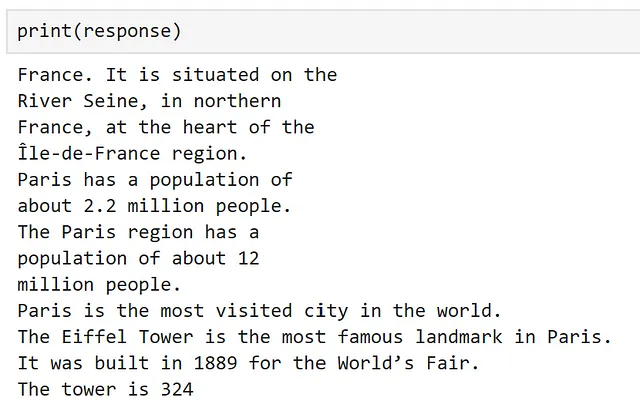
ここでは、関数が動作していることがわかります!
注意すべきことは、静かな失敗です。セマンティックカーネルの動作方法は、関数間でコンテキストオブジェクトを渡すことで行われます。このコンテキストオブジェクトは常に更新されます。

つまり、1つの関数が失敗すると、入力が返されることがあります。これは、パラメータを不正に設定することでデモンストレーションできます。
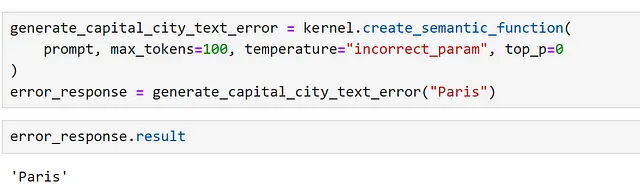
ここでは、以下のようにエラーを明示的にチェックすることができます。

これは、レスポンスを出力すると明確ですが、適切なチェックがないと、結果へのアクセス時に混乱した結果になる可能性があります!

セマンティック関数の設定の作成
create_semantic_functionは初めに使うのに便利ですが、より複雑なケースに必要なオプションを多く公開していません。たとえば、使用するモデルを指定したり、必要なカスタム引数を指定したりする場合などです。
これを説明するために、別のテキスト補完サービスを登録し、新しいサービスを使用するように設定できる設定を作成しましょう。2番目の補完サービスとして、Hugging Face transformersライブラリからモデルを使用します。これには、HuggingFaceTextCompletionコネクタを使用します。
ここでは、モデルをローカルで実行するため、GPTモデルファミリの古いメンバーであるGPT2を選択しました。これはほとんどのハードウェア上で簡単に高速に実行できるはずです。
from semantic_kernel.connectors.ai.hugging_face import HuggingFaceTextCompletionhf_model = HuggingFaceTextCompletion("gpt2", task="text-generation")kernel.add_text_completion_service("hf_gpt2_text_completion", hf_model)さあ、設定オブジェクトを作成しましょう。これを行う最も簡単な方法は、辞書を作成し、この辞書から設定をロードすることです。この方法であれば、必要に応じて設定をJSONファイルに保存することもできます。
以下の形式を使ってこれを行うことができます:
hf_config_dict = { "schema": 1, # プロンプトの種類 "type": "completion", # セマンティック関数の説明 "description": "GPT2モデルを使用して、入力された首都の情報を提供します", # 使用するモデルサービスを指定します "default_services": ["hf_gpt2_text_completion"], # コネクタとモデルサービスに渡されるパラメータ "completion": { "temperature": 0.01, "top_p": 1, "max_tokens": 256, "number_of_responses": 1, }, # プロンプト内で使用される変数を定義します "input": { "parameters": [ { "name": "input", "description": "首都の名前", "defaultValue": "ロンドン", } ] },}これで、PromptTemplateConfigオブジェクトに設定を直接ロードすることができます。
from semantic_kernel import PromptTemplateConfigprompt_template_config = PromptTemplateConfig.from_dict(hf_config_dict)これで、プロンプトの設定ができました。以前は文字列を使用していましたが、Semantic Kernelはこれをより構造化するためのテンプレートクラスを提供しています。
from semantic_kernel import PromptTemplateprompt_template = sk.PromptTemplate( template="{{$input}}は、の首都です", prompt_config=prompt_template_config, template_engine=kernel.prompt_template_engine,)最後に、プロンプトとその設定を同じオブジェクトにまとめるためのセマンティック関数設定を作成します。
from semantic_kernel import SemanticFunctionConfigfunction_config = SemanticFunctionConfig(prompt_template_config, prompt_template)ここではいくつかのステップが必要ですので、便宜上これらを関数にまとめましょう。
from semantic_kernel import PromptTemplateConfig, SemanticFunctionConfig, PromptTemplatedef create_semantic_function_config(prompt_template, prompt_config_dict, kernel): prompt_template_config = PromptTemplateConfig.from_dict(prompt_config_dict) prompt_template = sk.PromptTemplate( template=prompt_template, prompt_config=prompt_template_config, template_engine=kernel.prompt_template_engine, ) return SemanticFunctionConfig(prompt_template_config, prompt_template)これで、定義した設定を使用してセマンティック関数を登録することができます。以下に示すように、セマンティック関数の呼び出しも行えます。
gpt2_complete = kernel.register_semantic_function( skill_name="GPT2Complete", function_name="gpt2_complete", function_config=create_semantic_function_config( "{{$input}}は、の首都です", hf_config_dict, kernel ),)以前と同様に、関数を呼び出すことができます。
response = gpt2_complete("パリ")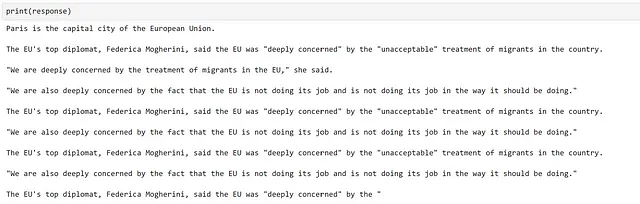
生成はうまくいったようですが、情報が不正確であまり良くありません。これはGPT2などの古いモデルを使用する場合によくあることであり、リリース以来、この分野がどれだけ進歩したかを示しています。
カスタムコネクタの作成
これまで、セマンティック関数を作成し、関数に使用するサービスを指定する方法を見てきました。ただし、ここまで使用したすべてのサービスは、既存のコネクタに依存しています。場合によっては、現在サポートされていない別のライブラリのモデルを使用したい場合があり、その場合はカスタムコネクタが必要になります。これを行う方法を見てみましょう。
例として、curated transformersライブラリからトランスフォーマーモデルを使用します。
カスタムコネクタを作成するには、TextCompletionClientBaseをサブクラス化する必要があります。これは、モデルを包む薄いラッパーとして機能します。以下に、これを行う簡単な例を示します。
from typing import List, Optional, Unionimport torchfrom curated_transformers.generation import ( AutoGenerator, SampleGeneratorConfig,)from semantic_kernel.connectors.ai.ai_exception import AIExceptionfrom semantic_kernel.connectors.ai.complete_request_settings import ( CompleteRequestSettings,)from semantic_kernel.connectors.ai.text_completion_client_base import ( TextCompletionClientBase,)class CuratedTransformersCompletion(TextCompletionClientBase): def __init__( self, model_name: str, device: Optional[int] = -1, ) -> None: """ キュレーションされたトランスフォーマーモデルをテキスト補完に使用します。 引数: model_name {str} device_idx {Optional[int]} -- モデルを実行するデバイス。CPUの場合は-1、GPUの場合は0以上。 このモデルはHugging Faceのモデルハブからダウンロードされます。 """ self.model_name = model_name self.device = ( "cuda:" + str(device) if device >= 0 and torch.cuda.is_available() else "cpu" ) self.generator = AutoGenerator.from_hf_hub( name=model_name, device=torch.device(self.device) ) async def complete_async( self, prompt: str, request_settings: CompleteRequestSettings ) -> Union[str, List[str]]: generator_config = SampleGeneratorConfig( temperature=request_settings.temperature, top_p=request_settings.top_p, ) try: with torch.no_grad(): result = self.generator([prompt], generator_config) return result[0] except Exception as e: raise AIException("CuratedTransformer completion failed", e) async def complete_stream_async( self, prompt: str, request_settings: CompleteRequestSettings ): raise NotImplementedError( "Streaming is not supported for CuratedTransformersCompletion." )今、私たちはコネクタを登録し、以前に示したようにセマンティック関数を作成することができます。ここでは、Falcon-7Bモデルを使用していますが、このモデルは合理的な時間で実行するためにGPUが必要です。私はAzure仮想マシン上のNvidia A100を使用しており、ローカルで実行すると遅すぎるためです。
kernel.add_text_completion_service( "falcon-7b_text_completion", CuratedTransformersCompletion(model_name="tiiuae/falcon-7b", device=0),)config_dict = { "schema": 1, # プロンプトのタイプ "type": "completion", # セマンティック関数の説明 "description": "Falcon-7Bモデルを使用して入力された首都の情報を提供します", # 使用するモデルサービスを指定します "default_services": ["falcon-7b_text_completion"], # コネクタとモデルサービスに渡されるパラメータを指定します "completion": { "temperature": 0.01, "top_p": 1, }, # プロンプト内で使用される変数を定義します "input": { "parameters": [ { "name": "input", "description": "首都の名前", "defaultValue": "ロンドン", } ] },}falcon_complete = kernel.register_semantic_function( skill_name="Falcon7BComplete", function_name="falcon7b_complete", function_config=create_semantic_function_config( "{{$input}}はの首都です", config_dict, kernel ),)
再び、生成が機能していることがわかりますが、私たちの質問に答えた後、すぐに繰り返しに陥ります。
これの理由の1つは、選択したモデルです。通常、自己回帰型トランスフォーマーモデルは大量のテキストコーパスで次の単語を予測するようにトレーニングされており、基本的には強力なオートコンプリートマシンです!ここでは、質問を「完了しよう」と試み、結果としてテキストを生成し続けることになり、私たちには役に立ちません。
チャットサービスの使用
一部のLLMモデルは、より対話的に使用するために追加のトレーニングを受けています。このプロセスの例については、OpenAIのInstructGPTの論文で詳しく説明されています。
大まかに言えば、これは通常、ランダムな非構造化テキストの代わりに、質問応答や要約などのタスクの選別された例でモデルをトレーニングする1つ以上の教師あり微調整ステップを追加することを意味します。これらのモデルは通常、インストラクション調整モデルまたはチャットモデルとして知られています。
既にベースのLLMが必要以上のテキストを生成することを観察しましたので、チャットモデルが異なるパフォーマンスを発揮するかどうか調査してみましょう。チャットモデルを使用するために、適切なサービスを指定するためにconfigを更新し、新しい関数を作成する必要があります。この場合、azure_gpt35_chat_completionを使用します。
chat_config_dict = { "schema": 1, # プロンプトのタイプ "type": "completion", # セマンティック関数の説明 "description": "GPT3.5モデルを使用して入力された首都の情報を提供します", # 使用するモデルサービスを指定します "default_services": ["azure_gpt35_chat_completion"], # コネクタとモデルサービスに渡されるパラメータを指定します "completion": { "temperature": 0.0, "top_p": 1, "max_tokens": 256, "number_of_responses": 1, "presence_penalty": 0, "frequency_penalty": 0, }, # プロンプト内で使用される変数を定義します "input": { "parameters": [ { "name": "input", "description": "首都の名前", "defaultValue": "ロンドン", } ] },}capital_city_chat = kernel.register_semantic_function( skill_name="CapitalCityChat", function_name="capital_city_chat", function_config=create_semantic_function_config( "{{$input}}はの首都です", chat_config_dict, kernel ),)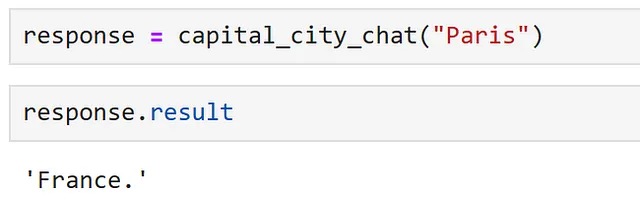
素晴らしいですね、チャットモデルがより簡潔な回答を提供してくれました!
以前は、テキスト補完モデルを使用していたため、モデルが完成するためにプロンプトを文としてフォーマットしていました。しかし、チューニングされたモデルは質問を理解できるはずなので、プロンプトを少し柔軟に変更できるかもしれません。どのようにプロンプトを調整して、私たちが訪れたい場所に関する情報を提供するようなチャットボットのようにモデルと対話できるか見てみましょう。
まず、プロンプトをより一般的なものにするために、関数の設定を調整しましょう。
chatbot = kernel.register_semantic_function( skill_name="チャットボット", function_name="チャットボット", function_config=create_semantic_function_config( "{{$input}}", chat_config_dict, kernel ),)ここでは、ユーザーの入力のみを渡していることがわかりますので、入力を質問形式にする必要があります。これを試してみましょう。

素晴らしい、うまくいったようですね。フォローアップの質問をしてみましょう。
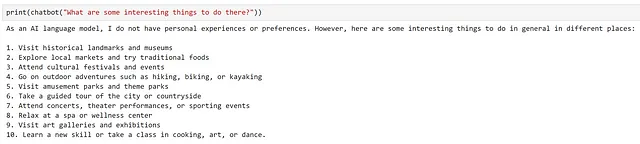
モデルは非常に一般的な回答を提供していることがわかりますが、前の質問を全く考慮していません。これは予想されることであり、モデルが受け取ったプロンプトは"What are some interesting things to do there?"であり、’there’がどこかに関する文脈を提供していませんでした。
次のセクションでは、このアプローチを拡張してシンプルなチャットボットを作成する方法を見てみましょう。
シンプルなチャットボットの作成
チャットサービスの使用方法を見てきたので、シンプルなチャットボットを作成する方法を探ってみましょう。
私たちのチャットボットは以下の3つのことができるようにする必要があります:
- 目的を知り、それを伝えること
- 現在の会話の文脈を理解すること
- 私たちの質問に答えること
これを反映するために、プロンプトを調整しましょう。
chatbot_prompt = """"You are a chatbot to provide information about different cities and countries. For other questions not related to places, you should politely decline to answer the question, stating your purpose" +++++{{$history}}User: {{$input}}ChatBot: """注意してください、historyという変数を追加しました。これは以前の文脈をチャットボットに提供するために使用されます。これはかなり単純なアプローチですが、長い会話ではプロンプトがモデルの最大文脈長に達することがすぐに起こるため、私たちの目的には適しています。
これまで、単一の変数を使用したプロンプトのみを使用してきました。複数の変数を使用するには、以下に示すように設定を調整する必要があります。
chat_config_dict = { "schema": 1, # プロンプトのタイプ "type": "completion", # セマンティック関数の説明 "description": "都市や国に関する情報を提供するチャットボット", # 使用するモデルサービスを指定 "default_services": ["azure_gpt35_chat_completion"], # コネクタとモデルサービスに渡されるパラメータを指定 "completion": { "temperature": 0.0, "top_p": 1, "max_tokens": 256, "number_of_responses": 1, "presence_penalty": 0, "frequency_penalty": 0, }, # プロンプト内で使用される変数を定義 "input": { "parameters": [ { "name": "input", "description": "ユーザーが入力したもの", "defaultValue": "", }, { "name": "history", "description": "ユーザーとチャットボットの以前の対話", "defaultValue": "", }, ] },}さて、この更新された設定とプロンプトを使用して、チャットボットを作成しましょう
function_config = create_semantic_function_config( chatbot_prompt, chat_config_dict, kernel)chatbot = kernel.register_semantic_function( skill_name="シンプルなチャットボット", function_name="シンプルなチャットボット", function_config=function_config,)複数の変数をセマンティック関数に渡すためには、変数の状態を保存するContextオブジェクトを作成する必要があります。以下に示すように、これを作成し、history変数を初期化することができます。
context = kernel.create_new_context()context["history"] = ""inputは特別な変数なので、これは自動的に処理されます。ただし、例えば{{$user_input}}のように名前を変更する場合は、同じ方法で初期化する必要があります。
さて、各インタラクションの後にコンテキストを更新するための簡単なチャット関数を作成しましょう。
async def chat(input_text, context, verbose=True): # 新しいメッセージをコンテキスト変数に保存 context["input"] = input_text if verbose: # 各インタラクションの前に完全なプロンプトを表示 print("プロンプト:") print("-----") # 変数をプロンプトに組み込む print(await function_config.prompt_template.render_async(context)) print("-----") # ユーザーメッセージを処理して回答を取得 answer = await chatbot.invoke_async(context=context) # 応答を表示 print(f"ChatBot: {answer}") # 新しいインタラクションをチャット履歴に追加 context["history"] += f"\nUser: {input_text}\nChatBot: {answer}\n"試してみましょう!
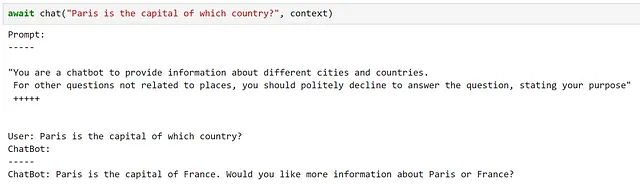
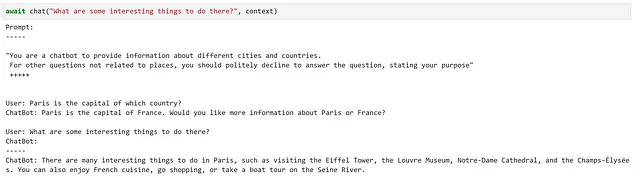
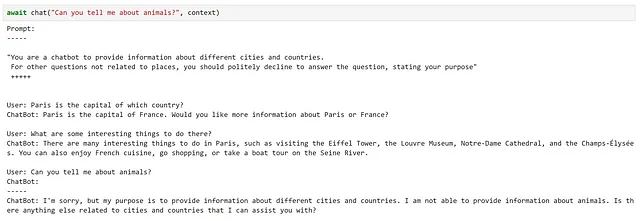
ここでは、要件を非常にうまく満たしていることがわかります!
ただし、各インタラクションの後にコンテキストを手動で更新するなど、注意する必要があるいくつかの細かい詳細がありました。
ChatPromptTemplateの使用
標準のプロンプトテンプレートを使用してシンプルなチャットボットを作成する方法を見てきましたが、Semantic Kernelは、前のインタラクションを追跡するためのChatPromptTemplateを提供しています。
このクラスを使用して、セマンティック関数の設定を作成するために使用した関数を更新しましょう。
from semantic_kernel import ( ChatPromptTemplate, SemanticFunctionConfig, PromptTemplateConfig,)def create_semantic_function_chat_config(prompt_template, prompt_config_dict, kernel): chat_system_message = ( prompt_config_dict.pop("system_prompt") if "system_prompt" in prompt_config_dict else None ) prompt_template_config = PromptTemplateConfig.from_dict(prompt_config_dict) prompt_template_config.completion.token_selection_biases = ( {} ) # required for https://github.com/microsoft/semantic-kernel/issues/2564 prompt_template = ChatPromptTemplate( template=prompt_template, prompt_config=prompt_template_config, template_engine=kernel.prompt_template_engine, ) if chat_system_message is not None: prompt_template.add_system_message(chat_system_message) return SemanticFunctionConfig(prompt_template_config, prompt_template)ご覧の通り、ChatPromptTemplateは、インタラクションの開始時にシステムメッセージを設定するオプションを提供しており、プロンプトに含める必要はありません。すべてを同じ場所に保つために、システムプロンプトを設定辞書に追加しましょう。これは定義されたスキーマに含まれていないため、設定を使用してPromptTemplateConfigを作成する前にこれを削除する必要があります。
chat_config_dict = { "schema": 1, # プロンプトのタイプ "type": "completion", # セマンティック関数の説明 "description": "都市や国に関する情報を提供するチャットボット", # 使用するモデルサービスを指定 "default_services": ["azure_gpt35_chat_completion"], # コネクタとモデルサービスに渡されるパラメータ "completion": { "temperature": 0.0, "top_p": 1, "max_tokens": 500, "number_of_responses": 1, "presence_penalty": 0, "frequency_penalty": 0, }, # プロンプト内で使用される変数を定義 "input": { "parameters": [ { "name": "input", "description": "ユーザーによって与えられた入力", "defaultValue": "", }, ] }, # スキーマ外の変数 "system_prompt": "異なる都市や国に関する情報を提供するチャットボットです。場所に関連しないその他の質問に対しては、目的を明示して丁寧に回答しないようにしてください。",}chatbot = kernel.register_semantic_function( skill_name="Chatbot", function_name="chatbot", function_config=create_semantic_function_chat_config( "{{$input}}", chat_config_dict, kernel ),)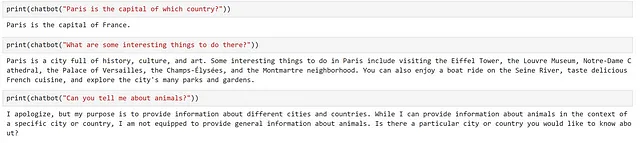
メモリ
チャットボットとの対話中、便利なインタラクションを提供するための重要な要素の1つは、チャットボットが以前の質問のコンテキストを保持できることです。これは、ChatPromptTemplateを利用してチャットボットにメモリへのアクセス権限を与えることによって実現しました。
シンプルなユースケースではこれで十分機能しましたが、すべての会話履歴はシステムのRAMに格納され、どこにも永続化されませんでした。システムをシャットダウンすると、これらの情報は永遠に失われます。より賢いアプリケーションでは、モデルがアクセスできる短期および長期のメモリを構築および永続化することが有用です。
また、この例では、すべての以前の対話をプロンプトに入力していました。モデルは通常、固定サイズのコンテキストウィンドウを持っており、これはプロンプトの長さを決定します。対話が長くなると、すぐに問題が発生する可能性があります。この問題を回避する方法の1つは、メモリを別々の「チャンク」として保存し、関連性がある可能性のある情報のみをプロンプトに読み込むことです。
Semantic Kernelは、アプリケーションにメモリを組み込む方法に関する機能を提供しているため、これを活用する方法を探ってみましょう。
例として、チャットボットにメモリに格納されている情報にアクセスできるように拡張してみましょう。
まず、チャットボットに関連する情報が必要です。関連する情報を手動で調査して収集することもできますが、モデルに生成させる方が速いです!ロンドン市に関するいくつかの事実をモデルに生成させてみましょう。次のように行います。
response = chatbot( """ロンドンですることの包括的な概要を提供してください。次の5つのパラグラフに基づいて回答を構造化してください:- 概要- 観光名所- 歴史- 文化- 食べ物各パラグラフは100トークンであり、`概要:`や`食べ物:`などのタイトルを回答のパラグラフに追加しないでください。質問に対して「確かに、ロンドンですることの包括的な概要はこちらです」といったステートメントで応答したり、クローズメントのコメントを提供したりしないでください。""")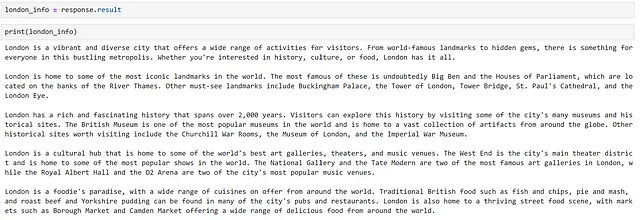
これでテキストが生成されましたので、モデルが必要な部分のみにアクセスできるように、これをチャンクに分割しましょう。Semantic kernelには、これを行うための機能がいくつか提供されています。text_chunkerモジュールを使用して次のように行います。
from semantic_kernel.text import text_chunker as tcchunks = tc.split_plaintext_paragraph([london_info], max_tokens=100)
テキストが8つのチャンクに分割されたことがわかります。テキストによっては、各チャンクに指定された最大トークン数を調整する必要があります。
テキスト埋め込みサービスの使用
データをチャンク分割したので、テキスト間の関連性を計算できるように各チャンクの表現を作成する必要があります。これを埋め込みとして表現することができます。
埋め込みを生成するには、カーネルにテキスト埋め込みサービスを追加する必要があります。前と同様に、基になるモデルのソースに応じてさまざまなコネクタを使用できます。
まず、Azure OpenAIサービスに展開されたtext-embedding-ada-002モデルを使用しましょう。このモデルはOpenAIによってトレーニングされ、詳細については彼らのローンチブログ記事で確認できます。
from semantic_kernel.connectors.ai.open_ai import AzureTextEmbeddingkernel.add_text_embedding_generation_service( "azure_openai_embedding", AzureTextEmbedding( deployment_name=OPENAI_EMBEDDING_DEPLOYMENT_NAME, endpoint=OPENAI_ENDPOINT, api_key=OPENAI_API_KEY, ),)埋め込みを生成できるモデルにアクセスできるようになったので、これを保存する場所が必要です。Semantic Kernelでは、さまざまな永続性プロバイダへのインターフェースであるMemoryStoreの概念を提供しています。
本番システムでは、永続性のためにデータベースを使用することが望ましいでしょうが、例を簡単にするために、メモリ内のストレージを使用します。メモリを使用するには、カーネルにメモリストアを登録する必要があります。
memory_store = sk.memory.VolatileMemoryStore()kernel.register_memory_store(memory_store=memory_store)例を簡単にするために、メモリ内のメモリストアを使用しましたが、より複雑なシステムを構築する際には、永続性のためにデータベースを使用することが望ましいでしょう。Semantic Kernelは、CosmosDB、Redis、Postgresなどの人気のあるストレージソリューションへのコネクタを提供しています。メモリストアは共通のインターフェースを持っているため、必要なのは使用するコネクタを変更するだけであり、プロバイダ間の切り替えが容易になります。
以下のように、情報をメモリストアに保存することができます。
for i, chunk in enumerate(chunks): await kernel.memory.save_information_async( collection="London", id="chunk" + str(i), text=chunk )ここでは、類似したドキュメントをグループ化するために、新しいコレクションを作成しました。
次に、次の方法でこのコレクションをクエリできます。
results = await kernel.memory.search_async( "London", "ロンドンで何を食べればいいですか?", limit=2)
結果を見ると、関連情報が返されていることがわかります。これは、高い関連性スコアに反映されています。
ただし、これは非常に簡単な例であり、質問された内容に関連する情報が直接的に存在し、非常に類似した言語が使用されているため、これは容易でした。より微妙なクエリを試してみましょう。
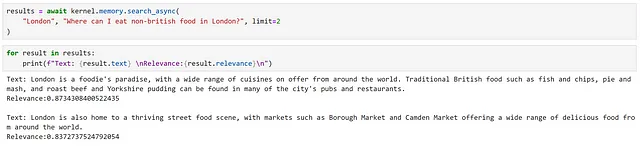
ここでは、まったく同じ結果が返されていることがわかります。ただし、2番目の結果には明示的に「世界中の食べ物」という言及がありますので、これがより適切な一致と考えます。これは、意味的な検索アプローチの潜在的な制約のいくつかを示しています。
オープンソースモデルの使用
興味深いので、この文脈でのオープンソースモデルとOpenAIサービスの比較を見てみましょう。以下に示すように、Hugging Faceのセンテンストランスフォーマーモデルを登録することができます。
from semantic_kernel.connectors.ai.hugging_face import HuggingFaceTextEmbeddinghf_embedding_service = HuggingFaceTextEmbedding( "sentence-transformers/all-MiniLM-L6-v2", device=-1)kernel.add_text_embedding_generation_service( "hf_embedding_service", hf_embedding_service,)メモリストアを切り替えるには、次のメソッドを使用できます。
kernel.use_memory(storage=memory_store, embeddings_generator=hf_embedding_service)use_memoryメソッドは、kernel.register_memory(SemanticTextMemory(storage, embeddings_generator))を呼び出すのと同等の便利なメソッドです。SemanticTextMemoryには、埋め込みの生成とそのストレージの管理のロジックが含まれています。
これで、以前と同じ方法でこれらをクエリできます。
for i, chunk in enumerate(chunks): await kernel.memory.save_information_async( "hf_London", id="chunk" + str(i), text=chunk )hf_results = await kernel.memory.search_async( "hf_London", "ロンドンで何を食べればいいですか?", limit=2, min_relevance_score=0)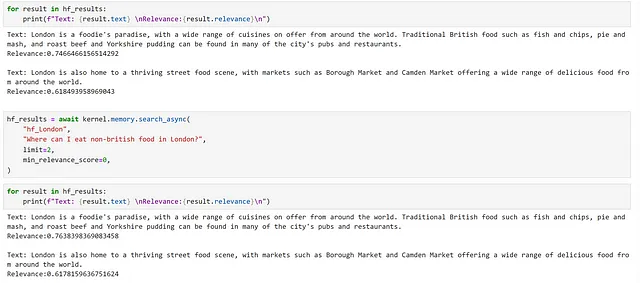
同じチャンクが返されていますが、関連性スコアが異なることがわかります。また、異なるモデルによって生成される埋め込みの次元の違いも観察できます。

メモリをコンテキストに統合する
前の例では、埋め込み検索に基づいて広く関連性のある情報を特定できましたが、より微妙なクエリでは最も関連性の高い結果を受け取ることができませんでした。これを改善できるかどうかを探ってみましょう。
この問題に取り組む方法の一つは、関連情報をチャットボットに提供し、モデルが最も関連性の高い部分を決定することです。再度、適切な設定を定義しましょう。
chat_config_dict = { "schema": 1, # プロンプトのタイプ "type": "completion", # セマンティック関数の説明 "description": "都市と国に関する情報を提供するチャットボット", # 使用するモデルサービスを指定 "default_services": ["azure_gpt35_chat_completion"], # コネクタとモデルサービスに渡されるパラメータ "completion": { "temperature": 0.0, "top_p": 1, "max_tokens": 500, "number_of_responses": 1, "presence_penalty": 0, "frequency_penalty": 0, }, # プロンプト内で使用される変数を定義 "input": { "parameters": [ { "name": "question", "description": "ユーザーが与えた質問", "defaultValue": "", }, { "name": "context", "description": "質問に答えるために使用する情報を含むコンテキスト", "defaultValue": "", }, ] }, # スキーマ外の変数 "system_prompt": "異なる都市や国に関する情報を提供するチャットボットです。 ",}次に、モデルにコンテキストに基づいて質問に答えるよう指示するプロンプトを作成し、セマンティック関数を登録しましょう。
prompt_with_context = """ 以下のコンテキストの情報を使用してユーザーの質問に答えてください。このコンテキスト以外の情報を参照しないでください。質問の回答に必要な情報がコンテキストに提供されていない場合は、"わかりません"と言って答えをでっち上げないでください。 ---------------- コンテキスト: {{$context}} ---------------- ユーザーの質問: {{$question}} ---------------- 回答:"""chatbot_with_context = kernel.register_semantic_function( skill_name="ChatbotWithContext", function_name="chatbot_with_context", function_config=create_semantic_function_chat_config( prompt_with_context, chat_config_dict, kernel ),)これで、より微妙な質問に答えるためにこの関数を使用できます。まず、コンテキストオブジェクトを作成し、質問を追加します。
question = "ロンドンで英国料理以外の食事をする場所はどこですか?"context = kernel.create_new_context()context["question"] = question次に、埋め込み検索を手動で実行し、取得した情報をコンテキストに追加できます。
results = await kernel.memory.search_async("hf_London", question, limit=2)context["context"] = "\n".join([result.text for result in results])最後に、関数を実行できます。ここでは、直接呼び出す代わりにカーネルを使用して関数を実行しています。これは、複数の関数を順次実行したい場合に便利です。
answer = await kernel.run_async(chatbot_with_context, input_vars=context.variables)
プラグイン
注意: 以前のバージョンのSemantic Kernelでは、プラグインは「スキル」として知られていましたが、BingとOpenAIとの一貫性のために名前が変更されました。したがって、多くのコードリファレンスとドキュメントは「スキル」を参照しています。
Semantic Kernelのプラグインは、AIアプリやサービスに公開されるためにカーネルにロードされる関数のグループです。プラグイン内の関数は、カーネルによってタスクを実行するために組み合わせられます。
ドキュメントでは、プラグインをSemantic Kernelの「ビルディングブロック」として説明しており、複雑なワークフローを作成するためにそれらを連鎖させることができます。OpenAIサービス、Bing、Microsoft 365向けに作成されたプラグインは、Semantic Kernelで使用することができます。
Semantic Kernelには、次のようないくつかのプラグインがデフォルトで用意されています:
- ConversationSummarySkill: 会話の要約
- HttpSkill: APIの呼び出し
- TextMemorySkill: テキストの保存と取得
- TimeSkill: 昼夜の時間やその他の時間情報の取得
まず、事前定義されたプラグインの使用方法を探求し、その後、カスタムプラグインの作成方法を調査することから始めましょう。
既製のプラグインの使用
Semantic Kernelに含まれるプラグインの1つであるTextMemorySkillは、メモリから情報を保存および呼び出す機能を提供します。このプラグインを使用して、以前の例でプロンプトのコンテキストをメモリから取得する方法を簡略化できるか見てみましょう。
まず、以下に示すようにプラグインをインポートする必要があります。

ここでは、このプラグインにはrecallとsaveという2つのセマンティック関数が含まれていることがわかります。
では、プロンプトを変更しましょう:
prompt_with_context_plugin = """ユーザーの質問に回答するために、以下のコンテキスト情報を使用してください。このコンテキストの外部の情報を参照しないでください。質問に回答するために必要な情報がコンテキストに提供されていない場合は、"わかりません"と答えるだけで、答えをでっち上げないでください。 ---------------- コンテキスト:{{recall $question}} ---------------- ユーザーの質問:{{$question}} ---------------- 答え:"""recall関数を使用するためには、この関数をプロンプト内で参照することができることがわかります。それでは、設定と関数の登録を作成しましょう。
chat_config_dict = { "schema": 1, # プロンプトのタイプ "type": "completion", # セマンティック関数の説明 "description": "都市や国に関する情報を提供するチャットボット", # 使用するモデルサービスを指定 "default_services": ["azure_gpt35_chat_completion"], # コネクタおよびモデルサービスに渡されるパラメータ "completion": { "temperature": 0.0, "top_p": 1, "max_tokens": 500, "number_of_responses": 1, "presence_penalty": 0, "frequency_penalty": 0, }, # プロンプト内で使用される変数を定義 "input": { "parameters": [ { "name": "question", "description": "ユーザーが与えた質問", "defaultValue": "", }, ] }, # スキーマ外の変数 "system_prompt": "異なる都市や国に関する情報を提供するチャットボットです。 ",}chatbot_with_context_plugin = kernel.register_semantic_function( skill_name="ChatbotWithContextPlugin", function_name="chatbot_with_context_plugin", function_config=create_semantic_function_chat_config( prompt_with_context_plugin, chat_config_dict, kernel ),)手動の例では、返される結果の数や検索するコレクションなどの側面を制御することができました。TextMemorySkillを使用する場合、これらをコンテキストに追加することで設定できます。関数を試してみましょう。
question = "ロンドンでイギリス料理以外の食事ができる場所はどこですか?"context = kernel.create_new_context()context["question"] = questioncontext[sk.core_skills.TextMemorySkill.COLLECTION_PARAM] = "hf_London"context[sk.core_skills.TextMemorySkill.RELEVANCE_PARAM] = 0.2context[sk.core_skills.TextMemorySkill.LIMIT_PARAM] = 2answer = await kernel.run_async( chatbot_with_context_plugin, input_vars=context.variables)
これは手動のアプローチと同等であることがわかります。
カスタムプラグインの作成
セマンティック関数の作成方法とプラグインの使用方法を理解したので、自分自身のプラグインを作成するために必要なものがすべて揃っています!
プラグインには2種類の関数が含まれることがあります:
- セマンティック関数:自然言語を使用してアクションを実行する
- ネイティブ関数:Pythonコードを使用してアクションを実行する
これらは単一のプラグイン内で組み合わせることができます。
セマンティック関数とネイティブ関数のどちらを使用するかは、実行するタスクに依存します。言語の理解や生成を含むタスクでは、セマンティック関数が明らかな選択肢です。しかし、数学の演算、データのダウンロード、時間のアクセスなどのより決定論的なタスクでは、ネイティブ関数が適しています。
それぞれのタイプを作成する方法を探ってみましょう。まず、プラグインを保存するためのフォルダを作成しましょう。
from pathlib import Pathplugins_path = Path("Plugins")plugins_path.mkdir(exist_ok=True)ポエム生成プラグインの作成
例として、詩を生成するプラグインを作成しましょう。セマンティックな関数を使用するのが自然な選択です。このプラグインのためのフォルダをディレクトリに作成します。
poem_gen_plugin_path = plugins_path / "PoemGeneratorPlugin"poem_gen_plugin_path.mkdir(exist_ok=True)プラグインは関数の集まりであることを思い出し、セマンティックな関数を作成しているので、次のパートは非常に馴染み深いものになるでしょう。違いは、promptとconfigをインラインで定義する代わりに、個別のファイルを作成してこれらを保存することです。これにより、読み込みが容易になります。
セマンティックな関数のフォルダを作成しましょう。ここで、write_poemと呼ぶことにします。
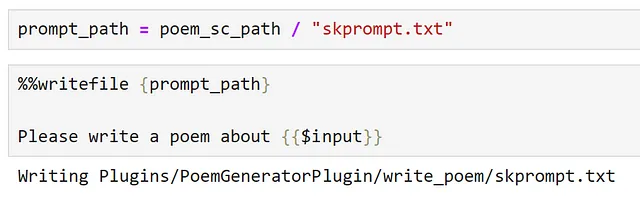
poem_sc_path = poem_gen_plugin_path / "write_poem"poem_sc_path.mkdir(exist_ok=True)次に、promptを作成し、skprompt.txtとして保存します。
さて、configを作成し、jsonファイルに保存しましょう。
configに意味のある説明を設定するのは常に良い実践ですが、これはプラグインを定義する際にはさらに重要になります。プラグインは、動作方法、入力と出力の内容、および副作用について明確な説明を提供する必要があります。これは、カーネルによって提示されるインターフェースであり、LLMを使用してタスクを管理するためには、カーネルがプラグインの機能と呼び出し方法を理解し、適切な関数を選択できるようにする必要があります。
config_path = poem_sc_path / "config.json"
%%writefile {config_path}{ "schema": 1, "type": "completion", "description": "ユーザーの入力に基づいて短い詩を生成する詩生成プラグイン", "default_services": ["azure_gpt35_chat_completion"], "completion": { "temperature": 0.0, "top_p": 1, "max_tokens": 250, "number_of_responses": 1, "presence_penalty": 0, "frequency_penalty": 0 }, "input": { "parameters": [{ "name": "input", "description": "詩の対象となるトピック", "defaultValue": "" }] }}JSONファイルとしてconfigを保存するため、コメントを削除する必要があることに注意してください。
これで、プラグインをインポートすることができます。
poem_gen_plugin = kernel.import_semantic_skill_from_directory( plugins_path, "PoemGeneratorPlugin")プラグインを調査すると、write_poemセマンティックな関数が公開されていることがわかります。

セマンティックな関数を直接呼び出すこともできます。
result = poem_gen_plugin["write_poem"]("Munich")
または、別のセマンティックな関数で使用することもできます。
chat_config_dict = { "schema": 1, # プロンプトのタイプ "type": "completion", # セマンティックな関数の説明 "description": "プラグインをラップして詩を書く", # 使用するモデルサービスを指定 "default_services": ["azure_gpt35_chat_completion"], # コネクタとモデルサービスに渡されるパラメータ "completion": { "temperature": 0.0, "top_p": 1, "max_tokens": 500, "number_of_responses": 1, "presence_penalty": 0, "frequency_penalty": 0, }, # プロンプト内で使用される変数を定義 "input": { "parameters": [ { "name": "input", "description": "ユーザーによって与えられた入力", "defaultValue": "", }, ] },}prompt = """{{PoemGeneratorPlugin.write_poem $input}}"""write_poem_wrapper = kernel.register_semantic_function( skill_name="PoemWrapper", function_name="poem_wrapper", function_config=create_semantic_function_chat_config( prompt, chat_config_dict, kernel ),)result = write_poem_wrapper("Munich")
画像分類プラグインの作成
プラグイン内でセマンティック関数を使用する方法を見てみたので、ネイティブ関数の使用方法を見てみましょう。
ここでは、画像のURLを受け取り、画像をダウンロードして分類するプラグインを作成しましょう。まず、新しいプラグイン用のフォルダを作成しましょう。
image_classifier_plugin_path = plugins_path / "ImageClassifierPlugin"image_classifier_plugin_path.mkdir(exist_ok=True)download_image_sc_path = image_classifier_plugin_path / "download_image.py"download_image_sc_path.mkdir(exist_ok=True)これで、Pythonモジュールを作成できます。モジュール内では、かなり柔軟になることができます。ここでは、2つのメソッドを持つクラスを作成しました。重要なステップは、プラグインの一部として公開するメソッドを指定するためにsk_functionデコレータを使用することです。
この例では、関数は単一の入力のみを必要とします。複数の入力が必要な関数では、ドキュメントで示されているようにsk_function_context_parameterを使用することができます。
import requestsfrom PIL import Imageimport timmfrom timm.data.imagenet_info import ImageNetInfofrom semantic_kernel.skill_definition import ( sk_function,)from semantic_kernel.orchestration.sk_context import SKContextclass ImageClassifierPlugin: def __init__(self): self.model = timm.create_model("convnext_tiny.in12k_ft_in1k", pretrained=True) self.model.eval() data_config = timm.data.resolve_model_data_config(self.model) self.transforms = timm.data.create_transform(**data_config, is_training=False) self.imagenet_info = ImageNetInfo() @sk_function( description="URLを入力として受け取り、画像を分類します", name="classify_image", input_description="分類する画像のURL", ) def classify_image(self, url: str) -> str: image = self.download_image(url) pred = self.model(self.transforms(image)[None]) return self.imagenet_info.index_to_description(pred.argmax()) def download_image(self, url): return Image.open(requests.get(url, stream=True).raw).convert("RGB")この例では、優れたPytorch Image Modelsライブラリを使用して分類器を提供しました。このライブラリの動作についての詳細は、このブログ記事を参照してください。
これで、以下のようにプラグインをインポートするだけで済みます。
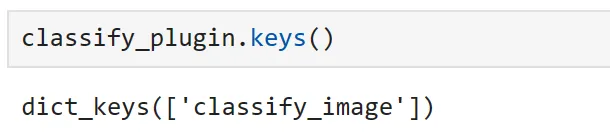
image_classifier = ImageClassifierPlugin()classify_plugin = kernel.import_skill(image_classifier, skill_name="classify_image")プラグインを検査すると、デコレートされた関数のみが公開されていることがわかります。
猫の画像を使用してプラグインが正常に動作するかを確認することができます。

url = "https://cdn.pixabay.com/photo/2016/02/10/16/37/cat-1192026_1280.jpg"response = classify_plugin["classify_image"](url)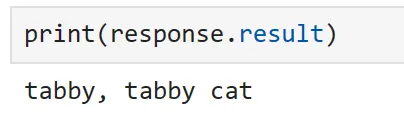
手動で関数を呼び出すことで、画像が正しく分類されたことがわかります!前と同じように、この関数をプロンプトから直接参照することもできます。ただし、これは既にデモンストレーション済みなので、次のセクションでは少し違った方法を試してみましょう。
複数のプラグインを連結する
カーネルを使用して複数のプラグインを連結することもできます。以下に示すように。
context = kernel.create_new_context()context["input"] = urlanswer = await kernel.run_async( classify_plugin["classify_image"], poem_gen_plugin["write_poem"], input_context=context,)
使用している両方のプラグインを順番に使用することで、画像を分類し、それについての詩を書きました!
プランナーを使ったワークフローのオーケストレーション
この時点で、意味的な機能を詳しく調べ、関数をグループ化してプラグインの一部として使用する方法、そして手動でプラグインを連鎖させる方法を見てきました。さて、LLMを使用してワークフローを作成し、オーケストレーションする方法を探ってみましょう。これを行うために、Semantic KernelはPlannerオブジェクトを提供しており、目標を達成するために関数のチェーンを動的に作成することができます。
プランナーは、ユーザープロンプトとカーネルを受け取り、カーネルのサービスを使用してタスクを実行する方法の計画を作成します。プラグインがこれらの計画の主要な構成要素であるため、プランナーは提供された説明に大いに依存します。プラグインや関数が明確な説明を持たない場合、プランナーはそれらを正しく使用することができません。さらに、プランナーはさまざまな方法で関数を組み合わせることができるため、プランナーが使用する関数のみを公開することが重要です。
プランナーは計画を生成するためにモデルに依存しているため、エラーが発生することがあります。これらは通常、プランナーが関数の使用方法を正しく理解していない場合に発生します。このような場合、入力と出力の説明、および入力が必要かどうかなど、明示的な指示を提供することで、より良い結果を得ることがわかっています。また、基本モデルよりも調整されたモデルを使用すると、より良い結果が得られることもわかっています。基本テキスト補完モデルは存在しない関数を幻視したり、複数の計画を作成したりする傾向があります。これらの制限にもかかわらず、すべてが正しく動作する場合、プランナーは非常に強力なものになります!
早速、以前作成したプラグインを使用して、画像についての詩を書くための計画を作成できるかどうかを探ってみましょう。不要な関数を多く定義したため、どの関数を公開するかを制御できるように、新しいカーネルを作成しましょう。
kernel = sk.Kernel()計画を作成するために、OpenAIのチャットサービスを使用しましょう。
kernel.add_chat_service( service_id="azure_gpt35_chat_completion", service=AzureChatCompletion( OPENAI_DEPLOYMENT_NAME, OPENAI_ENDPOINT, OPENAI_API_KEY ),)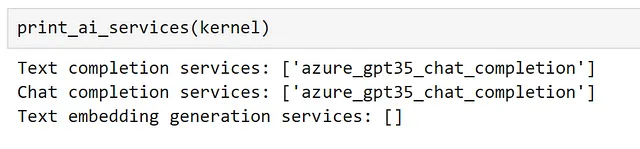
登録されたサービスを調べると、当サービスはテキスト補完とチャット補完の両方に使用できることがわかります。
それでは、プラグインをインポートしましょう。
classify_plugin = kernel.import_skill( ImageClassifierPlugin(), skill_name="classify_image")poem_gen_plugin = kernel.import_semantic_skill_from_directory( plugins_path, "PoemGeneratorPlugin")以下のように、カーネルがアクセスできる関数を確認することができます。

次に、プランナーオブジェクトをインポートしましょう。
from semantic_kernel.planning.basic_planner import BasicPlannerplanner = BasicPlanner()プランナーを使用するためには、プロンプトが必要です。生成される計画に応じて、これを微調整する必要がある場合があります。ここでは、必要な入力についてできるだけ明確にしようとしました。
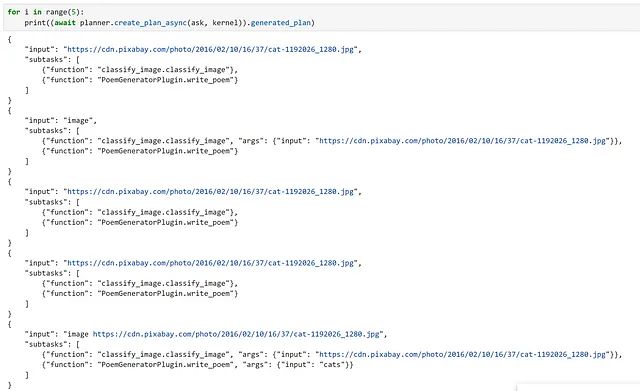
ask = f"""この画像に含まれているものについての詩を書いてもらいたいです。このURLを使用してください:{url}。このURLは入力として使用されるべきです。"""次に、プランナーを使用してタスクを解決するための計画を作成します。
plan = await planner.create_plan_async(ask, kernel)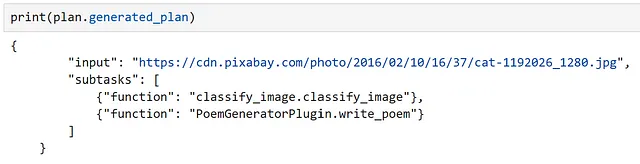
作成した計画を調べると、モデルが正しく入力と適切な関数を特定していることがわかります!
最後に、私たちの計画を実行するだけです。
poem = await planner.execute_plan_async(plan, kernel)
すごい、うまくいきました!次の単語を予測するためにトレーニングされたモデルとしては、かなり強力です!
警告として、この例を作成する際には、生成された計画が最初の試行で機能したという幸運がありました。ただし、同じプロンプトで複数回実行すると、常に同じ結果になるわけではないので、実行する前に計画を再確認することが重要です!個人的には、本番システムでは、LLMに任せるのではなく、手動でワークフローを作成して実行する方が、より安心感があります。技術の進歩が続く中で、特に現在のペースで、この推奨事項は時代遅れになることを願っています!
結論
これがSemantic Kernelの良い導入になり、それを自分のユースケースに活用することにインスピレーションを与えたことを願っています。
この投稿を再現するために必要なすべてのコードは、こちらのノートブックで利用できます。
Chris HughesはLinkedInにいます
参考文献
- ChatGPTを紹介する (openai.com)
- microsoft/semantic-kernel: 最新のLLMテクノロジーをアプリに迅速かつ簡単に統合する (github.com)
- 私たちの存在 — Microsoft Solutions Playbook
- kernel — ウィクショナリー、フリー辞書
- 概要 — OpenAI API
- Azure OpenAIサービス — 高度な言語モデル | Microsoft Azure
- Hugging Face Hubドキュメント
- Azure OpenAIサービスモデル — Azure OpenAI | Microsoft Learn
- Azureの無料アカウントを今すぐ作成 | Microsoft Azure
- Semantic Kernelでプロンプトテンプレート言語を使用する方法 | Microsoft Learn
- asyncio — 非同期I/O — Python 3.11.5 ドキュメント
- 🤗 Transformers (huggingface.co)
- gpt2 · Hugging Face
- explosion/curated-transformers: 🤖 キュレートされたTransformerモデルとその組み合わせ可能なコンポーネントのPyTorchライブラリ (github.com)
- tiiuae/falcon-7b · Hugging Face
- ND A100 v4シリーズ — Azure仮想マシン | Microsoft Learn
- [2203.02155] 訓練された言語モデルが指示に従う方法 (arxiv.org)
- Azure OpenAIサービスモデル — Azure OpenAI | Microsoft Learn
- 新しく改良された埋め込みモデル (openai.com)
- 導入 — Azure Cosmos DB | Microsoft Learn
- PostgreSQL: 世界で最も先進的なオープンソースデータベース
- sentence-transformers/all-MiniLM-L6-v2 · Hugging Face
- Semantic Kernelおよびそれ以降のAIプラグインの理解 | Microsoft Learn
- Semantic Kernelで利用可能な準備済みプラグイン | Microsoft Learn
- ネイティブコードをSemantic KernelにAIアプリに追加する方法 | Microsoft Learn
- huggingface/pytorch-image-models: PyTorchイメージモデル、スクリプト、事前学習済みの重み — ResNet、ResNeXT、EfficientNet、NFNet、Vision Transformer(ViT)、MobileNet-V3/V2、RegNet、DPN、CSPNet、Swin Transformer、MaxViT、CoAtNet、ConvNeXtなど (github.com)
- PyTorchイメージモデル(timm)の始め方:実践者向けガイド | Chris Hughes | Towards Data Science
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles






