Python から Julia へ:特徴量エンジニアリングと機械学習
Python to Julia Feature Engineering and Machine Learning

不正検知モデルの構築に向けたJuliaベースのアプローチ
これは、応用データサイエンスのためのJulia入門シリーズの第2部です。第1の記事では、Juliaを使用した簡単なデータ操作や探索的データ分析の例をいくつか紹介しました。このブログでは、不正な取引を特定する不正検知モデルの構築作業を続けます。
まず、Kaggleから入手したクレジットカードの不正検知データセットを使用しました。データセットには、トランザクション時間、金額、およびPCAによって得られた28の主成分機能を含む30のフィーチャが含まれています。以下は、Juliaのデータフレームとしてロードされたデータセットの最初の5つのインスタンスのスクリーンショットです。トランザクション時間のフィーチャは、データセット内の最初のトランザクションと現在のトランザクションとの経過時間(秒単位)を記録していることに注意してください。
フィーチャエンジニアリング
不正検知モデルのトレーニングの前に、モデルが消費できるようにデータを準備しましょう。このブログの主な目的はJuliaを紹介することですので、ここではフィーチャの選択や合成は行いません。
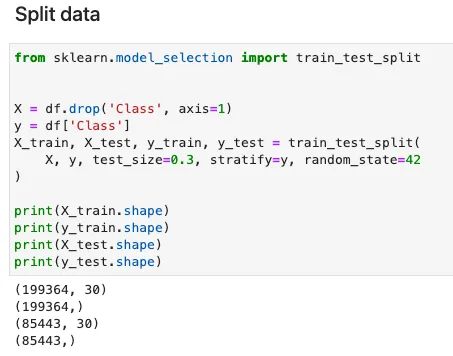
データ分割
分類モデルのトレーニング時には、通常、データは層別にトレーニングとテスト用に分割されます。主な目的は、ターゲットクラス変数に関してデータの分布をトレーニングデータとテストデータの両方で維持することです。これは、極端な不均衡を持つデータセットで作業する場合に特に必要です。JuliaのMLDataUtilsパッケージには、データ分割、ラベルエンコーディング、フィーチャ正規化などの前処理関数のシリーズが用意されています。次のコードは、MLDataUtilsのstratifiedobs関数を使用して層別サンプリングを行う方法を示しています。同じデータ分割が再現できるようにランダムシードを設定できます。
- 人間の脳血管のアトラスは、アルツハイマー病における変化を強調します
- 混乱するデータサイエンティストのためのPATH変数:管理方法
- 警察改革のためのデータ合成のイノベーションを入力し、現金を獲得してください
トレーニングとテストのデータを分割 – Juliaの実装
stratifiedobs関数の使用法は、Pythonのsklearnライブラリのtrain_test_split関数に非常に似ています。入力フィーチャXは、元のデータセットのサイズに復元するために2回転置する必要があることに注意してください。これは、私のようなJuliaの初心者にとって混乱することがあります。MLDataUtilsの作者がこのように関数を開発した理由をよく理解していません。
同等のPythonのsklearn実装は次のとおりです。
フィーチャスケーリング
機械学習において推奨される方法として、フィーチャスケーリングは、フィーチャを同じまたは類似の値または分布にもたらします。フィーチャスケーリングは、ニューラルネットワークをトレーニングする際の収束速度の向上に役立ち、トレーニング中に個々のフィーチャが支配されることを避けるのにも役立ちます。
この作業ではニューラルネットワークモデルをトレーニングしていませんが、Juliaでフィーチャスケーリングを実行する方法を調べたいと思います。残念ながら、スケーラーの適合とフィーチャの変換の両方の機能を提供するJuliaライブラリを見つけることができませんでした。MLDataUtilsパッケージで提供されるフィーチャ正規化関数は、フィーチャの平均値および標準偏差を導出することができますが、トレーニング/テストデータセットにフィーチャを変換することは容易ではありません。Juliaでフィーチャの平均値と標準偏差を簡単に計算できるため、標準スケーリングのプロセスを手動で実装できます。
次のコードは、X_trainとX_testのコピーを作成し、各フィーチャの平均値と標準偏差をループで計算します。
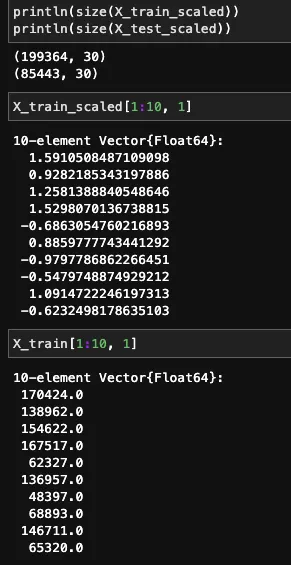
フィーチャの標準化 – Juliaの実装
変換されたフィーチャと元のフィーチャは以下のように表示されます。
Pythonでは、正規化や標準化などの特徴量スケーリングのために、sklearnでさまざまなオプションが提供されています。特徴量スケーラーを宣言することで、2行のコードでスケーリングが行われます。以下のコードは、RobustScalerを使用する例です。

オーバーサンプリング (PyCallによる)
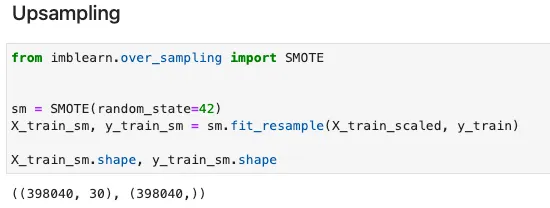
詐欺検出のデータセットは、通常、深刻な不均衡があります。たとえば、当社のデータセットの陰性例に対する陽性例の比率は500:1を超えます。データポイントをさらに取得することは不可能なため、アンダーサンプリングを行うと、多数派クラスからのデータポイントの大きな損失が発生します。この場合、オーバーサンプリングが最善の選択肢となります。ここでは、人気のあるSMOTEメソッドを使用して、陽性クラスの合成例を作成します。
現在、SMOTEの実装を提供する動作するJuliaライブラリはありません。ClassImbalanceパッケージは2年間メンテナンスされておらず、最近のJuliaバージョンとは使用できません。幸いなことに、Juliaでは、PyCallと呼ばれるラッパーライブラリを使用して、Pythonの使用準備が整っているパッケージを呼び出すことができます。
JuliaにPythonライブラリをインポートするには、PyCallをインストールし、PYTHONPATHを環境変数として指定する必要があります。ここでPythonの仮想環境を作成しようとしましたが、うまくいきませんでした。何らかの理由で、Juliaは仮想環境のPythonパスを認識できないためです。これが、システムのデフォルトのPythonパスを指定する必要がある理由です。これにより、imbalanced-learnライブラリで提供されるSMOTEのPython実装をインポートできるようになります。PyCallによって提供されるpyimport関数を使用すると、JuliaでPythonライブラリをインポートできます。次のコードは、JuliaカーネルでPyCallをアクティブ化し、Pythonからヘルプを取得する方法を示しています。
SMOTEによるトレーニングデータのアップサンプリング — Julia実装
同様のPython実装は以下の通りです。Juliaでは、fit_resample関数が同じように使用されていることがわかります。
モデルトレーニング
さて、モデルトレーニングの段階に入りました。バイナリ分類器をトレーニングすることになりますが、ロジスティック回帰、決定木、ニューラルネットワークなどのさまざまなMLアルゴリズムで行うことができます。現在、JuliaのMLリソースは複数のJuliaライブラリに分散しています。いくつかの最も人気のあるオプションと、それらの専門的なモデルセットをリストアップします。
- MLJ : 伝統的なMLアルゴリズム
- ScikitLearn : 伝統的なMLアルゴリズム
- Mocha : ニューラルネットワーク
- Flux : ニューラルネットワーク
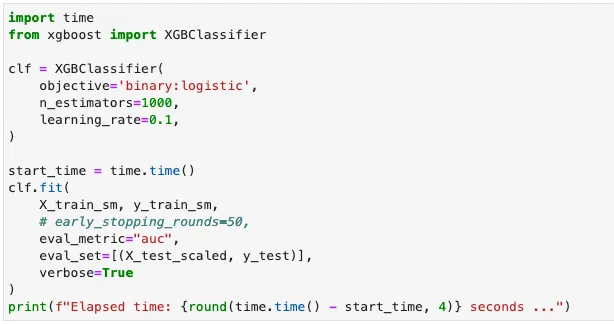
ここでは、単純さと従来の回帰および分類問題に対する優れたパフォーマンスを考慮して、XGBoostを選択することにします。JuliaでXGBoostモデルをトレーニングするプロセスは、Pythonと同じですが、構文にはわずかな違いがあります。
詐欺検出モデルをXGBoostでトレーニングする — Julia実装
同様のPython実装は以下の通りです。
モデル評価
最後に、テストデータで得られた適合率、再現率を確認して、モデルのパフォーマンスを確認しましょう。Juliaでは、適合率、再現率のメトリックをEvalMetricsライブラリを使用して計算することができます。同じ目的のために、MLJBaseという別のパッケージもあります。
予測を行い、メトリックを計算する — Julia実装
Pythonでは、sklearnを使用してメトリックを計算することができます。
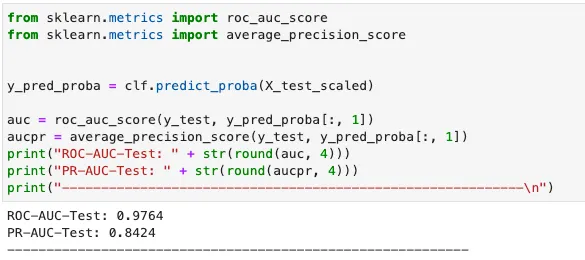
JuliaとPythonのどちらが勝者なのでしょうか? 公平な比較をするために、2つのモデルはともにデフォルトのハイパーパラメータでトレーニングされ、学習率=0.1、推定器の数=1000としました。 パフォーマンスメトリックスは、以下の表にまとめられています。
Juliaモデルは、わずかに長いトレーニング時間を要しますが、より高い精度と再現率を達成します。 Pythonモデルのトレーニングに使用されたXGBoostライブラリはC ++で記述されているのに対し、Julia XGBoostライブラリは完全にJuliaで記述されているため、JuliaはC ++と同じくらい速く実行されます。
前述のテストに使用されたハードウェア:11th Gen Intel® Core™ i7–1165G7 @ 2.80GHz — 4 cores。
このシリーズを、さまざまなデータサイエンスタスクのためのJuliaライブラリについての要約で締めくくりたいと思います。
現時点では、Juliaの使いやすさはPythonと比較できない程度にコミュニティのサポートが不足しています。 それでも、優れたパフォーマンスを持つJuliaには、将来的に大きな可能性があります。
参考文献
- Machine Learning Group of ULB (Université Libre de Bruxelles) . (no date). Credit Card Fraud Detection [Dataset]. H i i (Database Contents License (DbCL))
- Akshay Gupta. May 13, 2021. Start Machine Learning With Julia: Top Julia Libraries for Machine Learning . https://www.analyticsvidhya.com/blog/2021/05/top-julia-machine-learning-libraries/
GithubでJupyterノートブックを見つけることができます。
Takeways
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
