PythonからJuliaへ:基本的なデータ操作とEDA
Python to Julia Basic Data Operations and EDA
統計計算において新興のプログラミング言語であるJuliaは、近年ますます注目を集めています。Juliaを他のプログラミング言語よりも優れたものにする2つの特徴があります。
- JuliaはPythonと同様の高水準言語です。したがって、学習と使用が容易です。
- Juliaは、C/C++と同じくらい高速になるように設計されたコンパイル言語です。
私が最初にJuliaを知ったとき、その計算速度に魅了されました。そこで、私はJuliaを試して、日常の仕事で実用的に使用できるかどうかを確認することにしました。
データサイエンスの実践者として、私はPythonを使ってさまざまな目的のためにプロトタイプMLモデルを開発しています。Juliaを素早く学ぶために、PythonとJuliaの両方で簡単なMLモデルを構築するプロセスを模倣することにします。PythonとJuliaのコードを並べて比較することで、2つの言語の構文の違いを簡単に把握できます。このブログは、以下のセクションで説明されています。
セットアップ
まず始めに、ワークステーションにJuliaをインストールする必要があります。Juliaのインストールには、以下の2つのステップが必要です。
- 公式ウェブサイトからインストーラーファイルをダウンロードします。
- インストーラーファイルを解凍し、Juliaのバイナリファイルにシンボリックリンクを作成します。
以下のブログでは、Juliaのインストールに関する詳細なガイドラインが提供されています。
UbuntuにJuliaをインストールする
UbuntuにJuliaをインストールしてJupyterにカーネルを追加する方法についてのクイックチュートリアル
VoAGI.com
データセット
Kaggleから取得したクレジットカード詐欺検出データセットを使用する予定です。データセットには、284,807件の取引のうち492件が詐欺です。PCAで得られたトランザクション時間、金額、28の主成分を含む30の特徴があります。トランザクションの「クラス」は、詐欺であるかどうかを示す予測対象変数であることに注意してください。
Pythonと同様に、Juliaコミュニティは、Juliaユーザーのニーズをサポートするためにさまざまなパッケージを開発しています。これらのパッケージは、Pythonのpipに相当するJuliaのパッケージマネージャーであるPkgを使用してインストールできます。
私が使用する詐欺検出データは、一般的な.csv形式です。Juliaでデータフレームとしてcsvデータをロードするには、CSVとDataFrameパッケージの両方をインポートする必要があります。DataFrameパッケージは、JuliaでのPandasに相当します。
データフレームとして構造化データをロードする – Juliaの実装
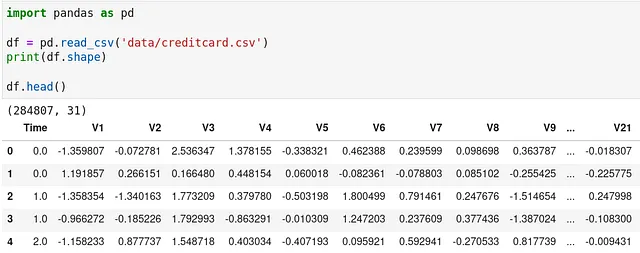
以下は、インポートされたデータの見た目です。

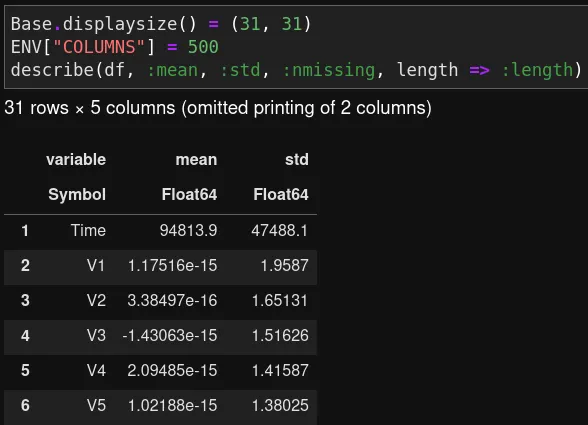
Jupyterでは、上記の画像に示すように、ロードされたデータセットを表示できます。より多くの列を表示する場合は、環境変数ENV["COLUMNS"]を指定することができます。そうしない場合、10列未満しか表示されません。
同様のPythonの実装は以下の通りです。
探索的データ分析(EDA)
探索的分析により、データの品質を調べ、特徴間のパターンを発見することができます。これは、特徴エンジニアリングやMLモデルのトレーニングに非常に有用です。
基本統計量
平均値、標準偏差など、特徴のいくつかの単純な統計量を計算することから始めることができます。PythonのPandasと同様に、JuliaのDataFrameパッケージは、この目的のためにdescribe関数を提供しています。
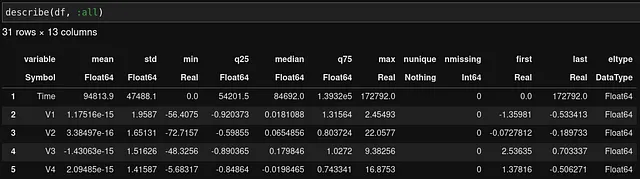
describe関数を使うと、12種類の基本統計量を生成することができます。例えば、describe(df, :mean, :std)のように:all引数を変更することで、どの統計量を生成するかを選択できます。ただし、表示可能な列数の上限が設定されていても、describe関数は:allを指定しない場合には統計量の表示を省略し続けるため、少し面倒です。これは、Juliaコミュニティが将来取り組むべき課題です。
クラスバランス
不正検知データセットは通常、極端なクラスの不均衡の問題に直面しています。したがって、2つのクラスの間のデータの分布を調べたいと思います。Juliaでは、「split-apply-combine」関数を適用することでこれを行うことができます。これは、PythonのPandasの「groupby-aggregate」関数に相当します。
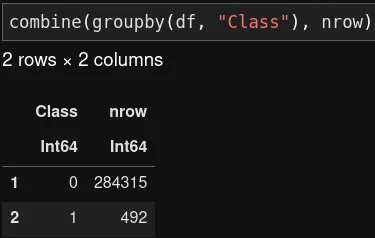
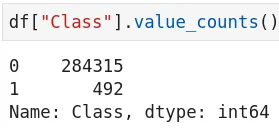
Pythonでは、value_counts()関数を使用して同じ目的を達成できます。
単変量解析
次に、ヒストグラムを使用して特徴量の分布を調べてみましょう。特に、データセット内で唯一解釈可能な特徴量であるトランザクション金額と時間を例に取ります。
Juliaには、ヒストグラム、棒グラフ、箱ひげ図など、さまざまな一般的に使用される統計グラフをプロットすることができる便利なライブラリのStatsPlotsがあります。
以下のコードは、トランザクション金額と時間のヒストグラムを2つのサブプロットにプロットします。トランザクション金額は高度に歪んでいることが観察されます。ほとんどのトランザクションの金額は100未満です。トランザクション時間は双峰分布に従います。
トランザクション時間とトランザクション金額の分布をプロットする — Julia実装
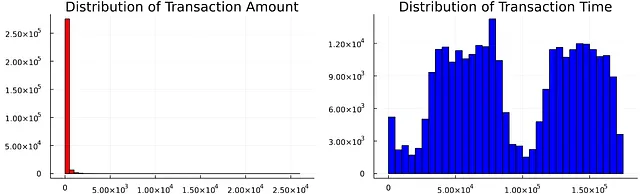
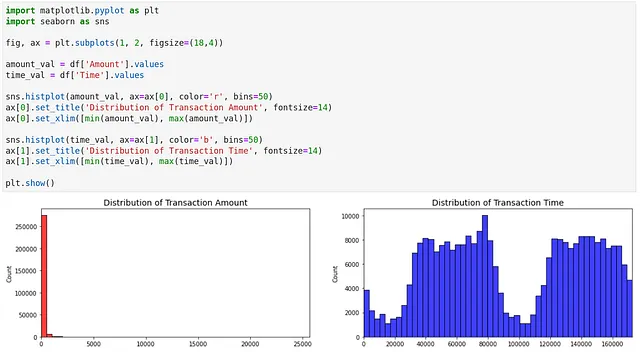
Pythonでは、matplotlibとseabornを使用して、同じグラフを作成することができます。
双変量解析
上記の単変量解析では、トランザクション金額と時間の一般的なパターンを示していますが、予測する不正フラグとの関係を示していません。特徴量とターゲット変数の関係について、クイックな概要を得るために、相関行列を作成し、ヒートマップで可視化することができます。
相関行列を作成する前に、私たちのデータが極端に不均衡であることに注意する必要があります。相関をより良く捉えるために、データの不均衡による特徴の影響を薄めないように、データをダウンサンプリングする必要があります。この演習には、データフレームのスライスと連結が必要です。以下のコードは、Juliaにおけるダウンサンプリングの実装を示しています。
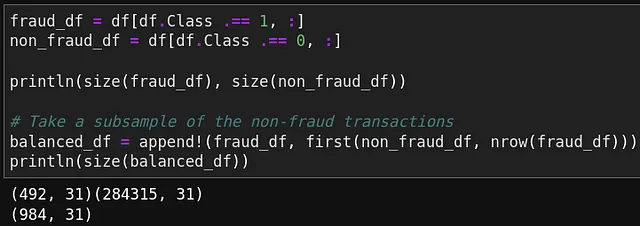
上記のコードは、不正取引の数を数え、同じ数の非不正取引と不正取引を組み合わせます。次に、相関行列を視覚化するためにヒートマップを作成できます。
相関行列を視覚化するためにヒートマップをプロットする — Julia実装
以下は、結果のヒートマップです。
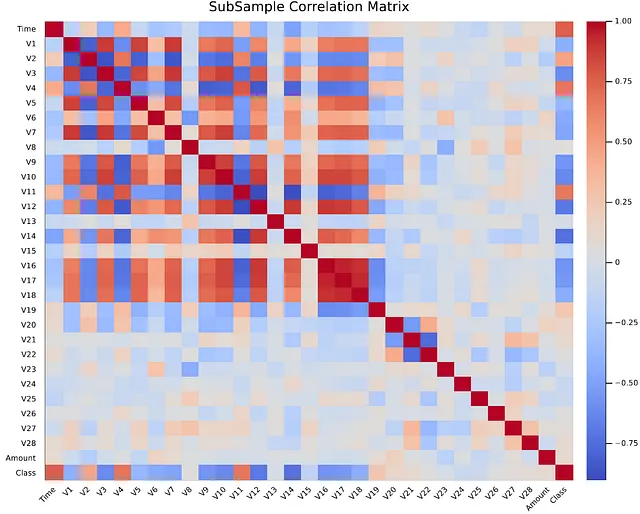
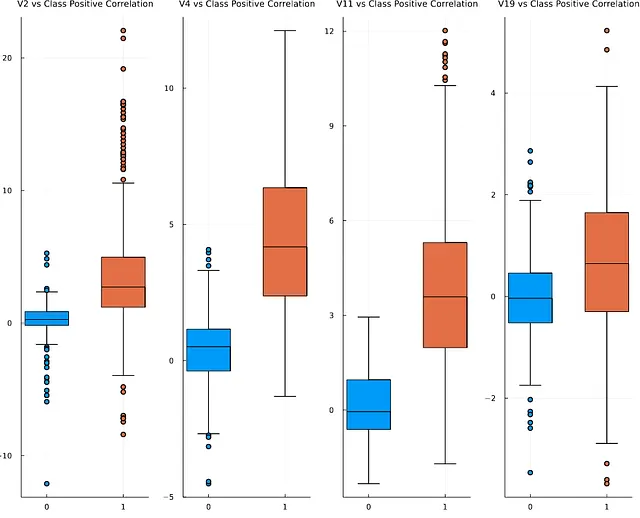
特徴の相関関係の概要を把握した後、ターゲット変数である「Class」と有意な相関関係を持つ特徴にズームインしたいと思います。ヒートマップから、次のPCA変換された特徴が「Class」と正の関係を持つことが観察されます:V2、V4、V11、V19、一方、負の関係を持つ特徴には、V10、V12、V14、V17が含まれます。これらのハイライトされた特徴の影響をターゲット変数に調べるために、ボックスプロットを使用できます。
Juliaでは、前述のStatsPlotsパッケージを使用してボックスプロットを作成できます。ここでは、「Class」と正の相関を持つ4つの特徴を例にして、ボックスプロットの作成方法を説明します。
ターゲットデータセット、すなわちbalanced_df上でボックスプロットを作成することを示すマクロとして@dfがここで使用されています。結果のプロットは以下の通りです。
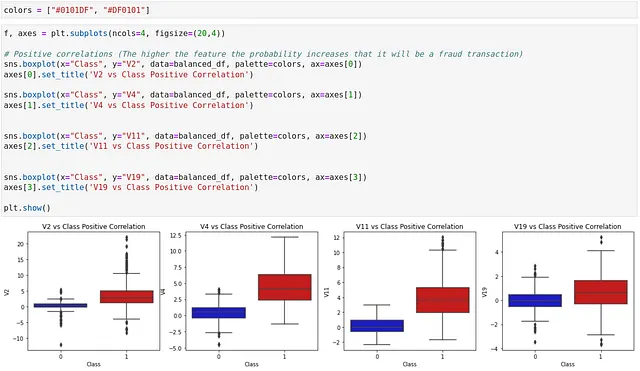
以下のコードは、同じボックスプロットをPythonで作成するために使用できます。
中間
ここで、私がJuliaを使って得た「ユーザーエクスペリエンス」についての簡単なコメントを休止します。言語構文に関しては、JuliaはPythonとRの間のどこかに位置しているようです。 Juliaパッケージには、データ操作やEDAのさまざまなニーズに包括的なサポートを提供するものもあります。しかし、Juliaの開発はまだ初期段階であり、プログラミング言語にはまだリソースやコミュニティのサポートが不足しています。リストのようなデータフレーム列のunnestingなど、特定のデータ操作演習のJulia実装を検索するのに多くの時間がかかる場合があります。さらに、Juliaの構文はPython 3のように安定化することはまだまだです。この時点では、私は大企業や企業にとってJuliaが良いプログラミング言語の選択肢だとは言えません。
詐欺検出モデルの構築はまだ終わっていません。次のブログでも続けますのでお楽しみに!
JupyterノートブックはGithubで入手できます。
参考文献
- ULB(ブリュッセル自由大学)の機械学習グループ。 (日付不明)。 クレジットカード詐欺検出[データセット]。 https://www.kaggle.com/datasets/mlg-ulb/creditcardfraud
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
