「Pythonによるデータクリーニングの技術をマスターする」
『Pythonを使ったデータクリーニングの技術を習得する』

データのクリーニングは、データ分析プロセスの重要な部分です。これは、エラーを削除し、欠損値を処理し、データが扱える形式になるようにする手順です。適切にクリーニングされていないデータセットでは、後続の分析が歪んでいるか正しくない場合があります。
本記事では、pandas、numpy、seaborn、matplotlibなどの強力なライブラリを使用して、Pythonにおけるデータクリーニングのいくつかの重要なテクニックを紹介します。
データクリーニングの重要性を理解する
データクリーニングのメカニクスに入る前に、その重要性を理解しましょう。実世界のデータはしばしば乱雑です。重複したエントリ、正しくないまたは一貫性のないデータ型、欠損値、関連のない特徴、外れ値が含まれることがあります。これらの要素は、データを分析する際に誤った結論につながる可能性があります。そのため、データクリーニングはデータサイエンスのライフサイクルにおいて不可欠な部分です。
次のデータクリーニングタスクをカバーします。 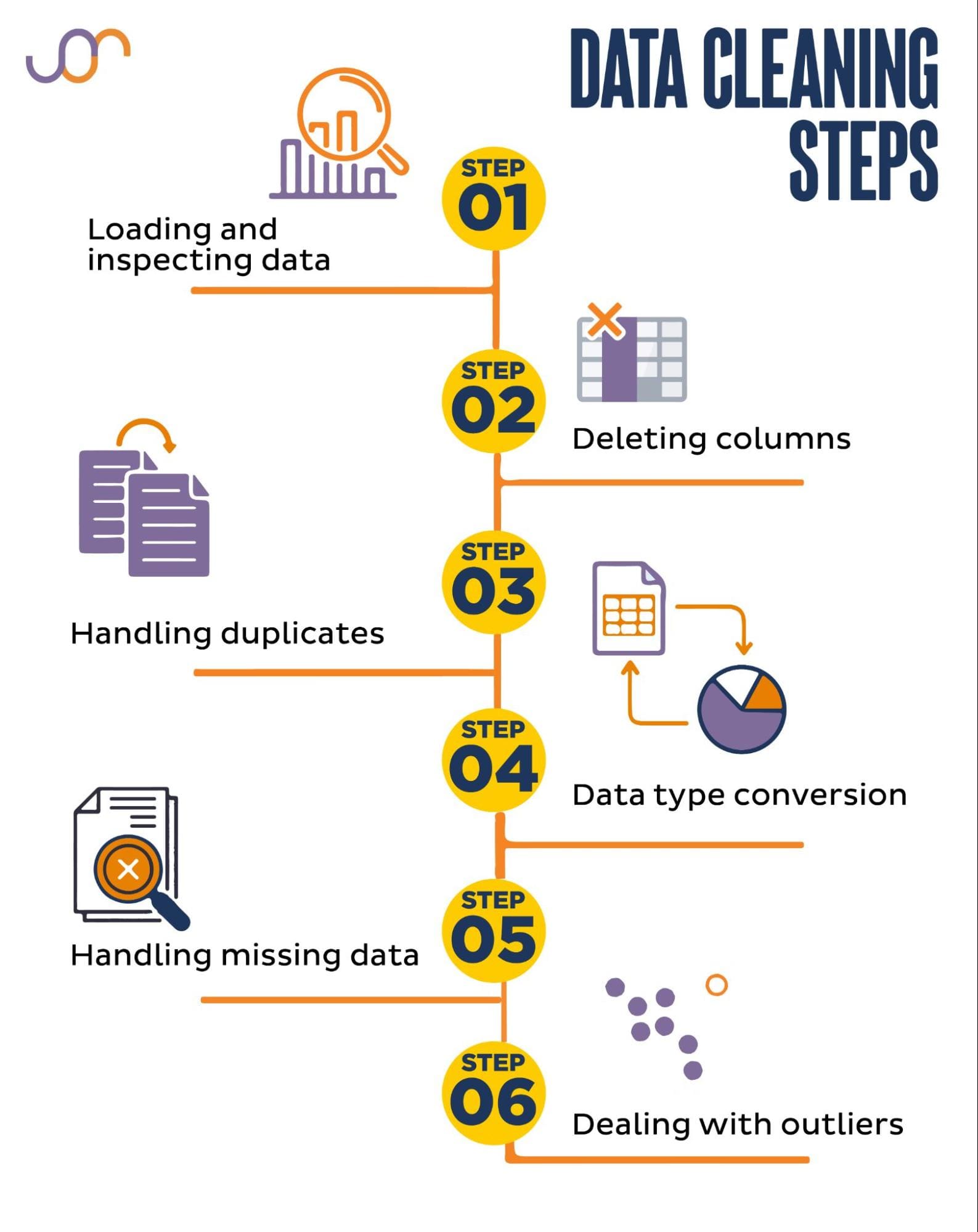
Pythonでのデータクリーニングのセットアップ
はじめに、必要なライブラリをインポートしましょう。データ操作にはpandasを使用し、可視化にはseabornとmatplotlibを使用します。
また、日付を操作するためにdatetime Pythonモジュールもインポートします。
import pandas as pd
import seaborn as sns
import datetime as dt
import matplotlib.pyplot as plt
import matplotlib.ticker as tickerデータの読み込みと確認
まず、データを読み込む必要があります。この例では、pandasを使用してCSVファイルを読み込みます。区切り文字の引数も追加しています。
df = pd.read_csv('F:\\VoAGI\\KDN Mastering the Art of Data Cleaning in Python\\property.csv', delimiter= ';')次に、データを確認してその構造や使用している変数の種類、欠損値があるかどうかを理解することが重要です。インポートしたデータが huge ではないため、データセット全体を見てみましょう。
# Look at all the rows of the dataframedisplay(df)データセットの見た目は次のようになります。
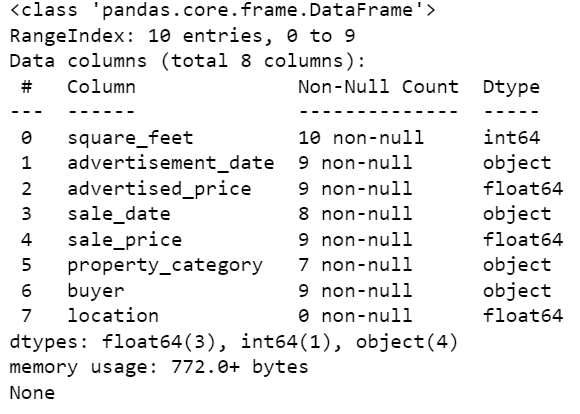
すぐにいくつかの欠損値があることがわかります。また、日付の形式も一貫していません。
次に、info()メソッドを使用してDataFrameの概要を確認することが重要です。
# Get a concise summary of the dataframeprint(df.info())以下は、コードの出力例です。
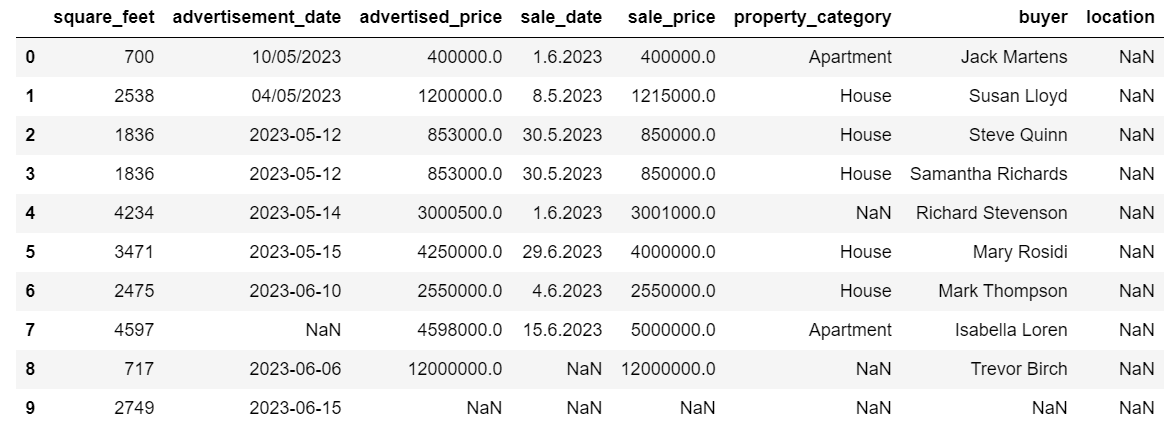
square_feet列以外はNULL値がないことがわかりますので、どうにか対処する必要があります。また、advertisement_date、sale_dateの列はオブジェクトデータ型であり、これは日付であるはずです。
location列は完全に空です。必要ですか?
これらの問題の対処方法を説明します。まず、不要な列を削除する方法を学びましょう。
不要な列の削除
データセットには、データ分析に必要のない2つの列がありますので、これらを削除します。
最初の列は buyer です。これは分析に影響を与えないため、不要です。
削除するために、指定した列名を使用して drop()メソッドを使用します。axisを1に設定し、列の削除を指定します。また、inplace引数をTrueに設定して、削除する列がない新しいDataFrameを作成せずに既存のDataFrameを変更します。
df.drop('buyer', axis = 1, inplace = True)2番目に削除する列はlocationです。この情報を持つことは役に立つかもしれませんが、これは完全に空の列なので、削除しましょう。
最初の列と同じ方法を取ります。
df.drop('location', axis = 1, inplace = True)
もちろん、この2つの列を同時に削除することもできます。
df = df.drop(['buyer', 'location'], axis=1)
両方の方法は以下のデータフレームを返します。
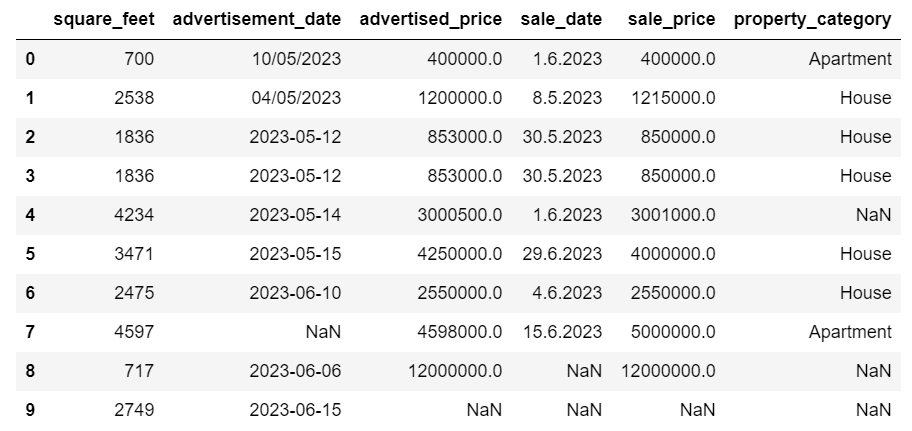
重複データの処理
さまざまな理由で重複データがデータセットに含まれることがあり、分析結果を歪める可能性があります。
データセット内の重複を検出します。以下にその方法を示します。
以下のコードでは、duplicated()メソッドを使用してデータセット全体の重複を考慮しています。デフォルト設定では、値の最初の出現を一意とみなし、その後の出現を重複とみなします。この動作はkeepパラメータを使用して変更できます。例えば、df.duplicated(keep=False) は最初の出現を含むすべての重複をTrueとします。
# 重複の検出duplicates = df[df.duplicated()]duplicates
以下は出力です。

インデックス3の行は、同じ値を持つ行2が最初の出現であるため、重複としてマークされています。
次に、重複を削除する必要があります。以下のコードで行います。
# 重複の検出duplicates = df[df.duplicated()]duplicates
drop_duplicates()関数は、重複を識別する際にすべての列を考慮します。特定の列のみを考慮する場合は、リストとして渡すこともできます。例えば、df.drop_duplicates(subset=[‘column1’, ‘column2’]) のように指定します。
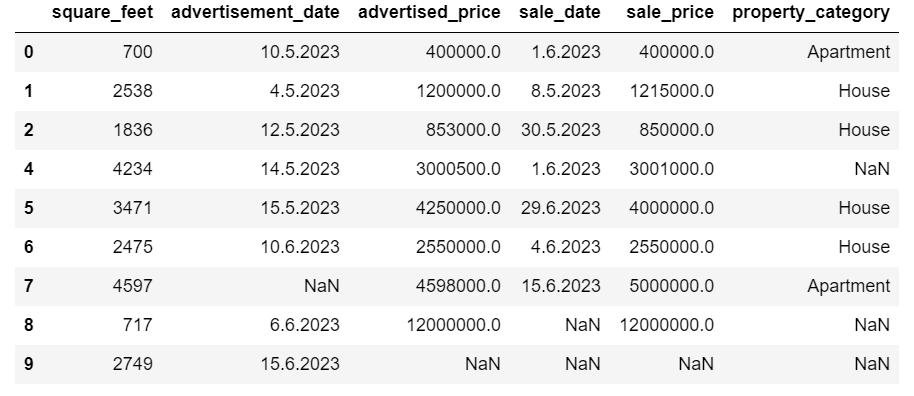
重複した行が削除されたことがわかります。ただし、インデックスは同じままで、インデックス3が欠けています。これを整理するために、インデックスをリセットします。
df = df.reset_index(drop=True)
このタスクは、reset_index()関数を使用して実行されます。drop=True引数を使用すると、元のインデックスは破棄されます。この引数を指定しない場合、古いインデックスは新しい列としてDataFrameに追加されます。drop=Trueを設定することで、古いインデックスを忘れてデフォルトの整数インデックスにリセットするようにpandasに指示します。
練習として、このMicrosoftのデータセットから重複を削除してみてください。
データ型の変換
データ型が正しく設定されていない場合、例えば日付列が文字列として解釈される場合があります。これらを適切な型に変換する必要があります。
データセットでは、advertisement_date列とsale_date列を変換します。これらの列はオブジェクトデータ型として表示されています。また、行ごとに日付の形式も異なります。これを一貫性のある形式に修正し、日付に変換する必要があります。
最も簡単な方法は、to_datetime()メソッドを使用することです。再び、以下のように列ごとに行います。
日付が最初に日を示す場合、dayfirst引数をTrueに設定します。
# advertisement_date列を日付に変換df['advertisement_date'] = pd.to_datetime(df['advertisement_date'], dayfirst = True)# sale_date列を日付に変換df['sale_date'] = pd.to_datetime(df['sale_date'], dayfirst = True)
apply()メソッドとto_datetime()を使用して、両方の列を同時に変換することもできます。
# advertisement_dateとsale_date列を日付に変換df[['advertisement_date', 'sale_date']] = df[['advertisement_date', 'sale_date']].apply(pd.to_datetime, dayfirst = True)
両方のアプローチは同じ結果を与えます。
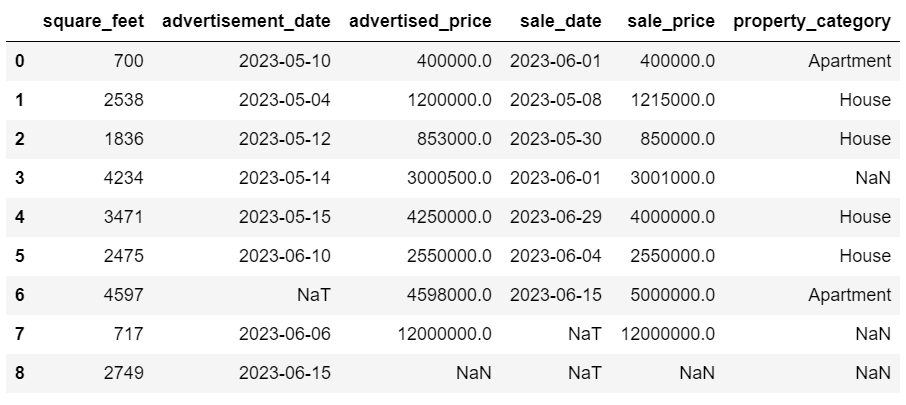
今、日付は一貫した形式になっています。すべてのデータが変換されているわけではありません。advertisement_dateには1つのNaT値があり、sale_dateには2つのNaT値があります。これは日付が欠落していることを意味します。
info()メソッドを使用して、列が日付に変換されているかどうかをチェックしましょう。
# データフレームの簡潔な要約を取得print(df.info())
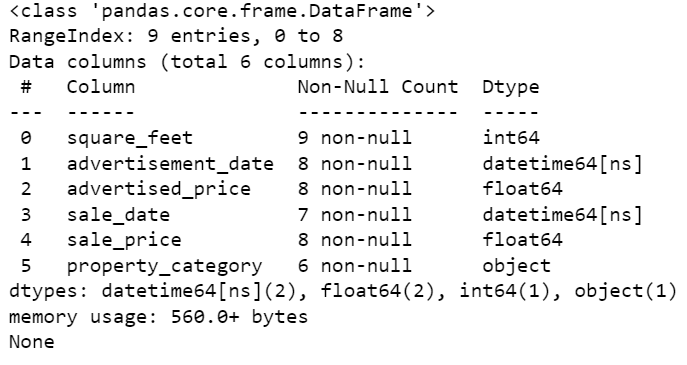
上記のように、両方の列がdatetime64[ns]形式ではありません。
では、このAirbnbデータセットでデータをテキストから数値に変換してみましょう。
欠損データの取り扱い
実世界のデータセットにはしばしば欠損値があります。欠損データの取り扱いは重要であり、一部のアルゴリズムはそのような値を扱えません。
この例でもいくつかの欠損値がありますので、欠損データの取り扱いの2つの一般的なアプローチを見てみましょう。
欠損値を持つ行の削除
欠損データを持つ行の数が全体の観測数に比べて無視できる場合、これらの行を削除することを検討するかもしれません。
この例では、最後の行には平方フィートと広告日付以外の値がありません。このようなデータは使用できませんので、この行を削除しましょう。
以下に行のインデックスを指定するコードを示します。
df = df.drop(8)
DataFrameは以下のようになります。
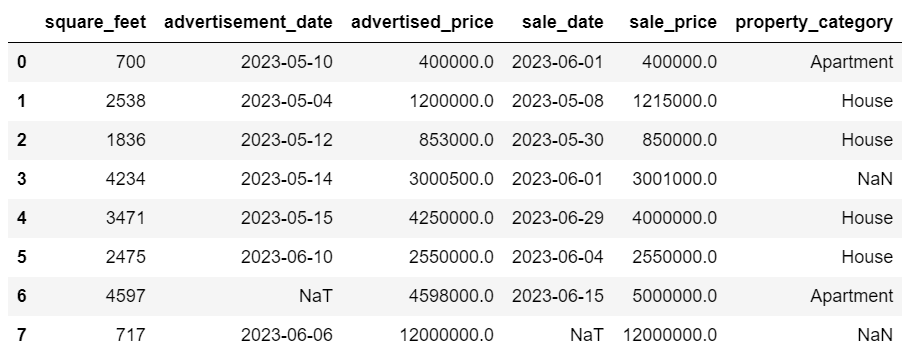
最後の行が削除され、DataFrameは見た目が良くなりました。ただし、まだいくつかの欠損データがあり、別のアプローチで取り扱います。
欠損値の補完
大量の欠損データがある場合、削除する代わりに補完するという方が良い戦略かもしれません。このプロセスは他のデータに基づいて欠損値を補完することを含みます。数値データの場合、一般的な補完方法には中心傾向(平均、中央値、最頻値)を使用することがあります。
既に変更済みのDataFrameでは、advertisement_date列とsale_date列にNaT(Not a Time)値があります。これらの欠損値を補完するために mean()メソッドを使用します。
コードでは、fillna()メソッドを使用して、欠損値を平均値で見つけて補完しています。
# 数値列の値を補完するdf['advertisement_date'] = df['advertisement_date'].fillna(df['advertisement_date'].mean())df['sale_date'] = df['sale_date'].fillna(df['sale_date'].mean())
同じことを1行のコードで行うこともできます。 lambdaを使用して定義された関数を適用するためにapply()を使用します。上記と同様、この関数は欠損値を補完するために fillna()とmean()メソッドを使用しています。
# 複数の数値列の値を補完するdf[['advertisement_date', 'sale_date']] = df[['advertisement_date', 'sale_date']].apply(lambda x: x.fillna(x.mean()))
両方の場合の出力は以下のようになります。
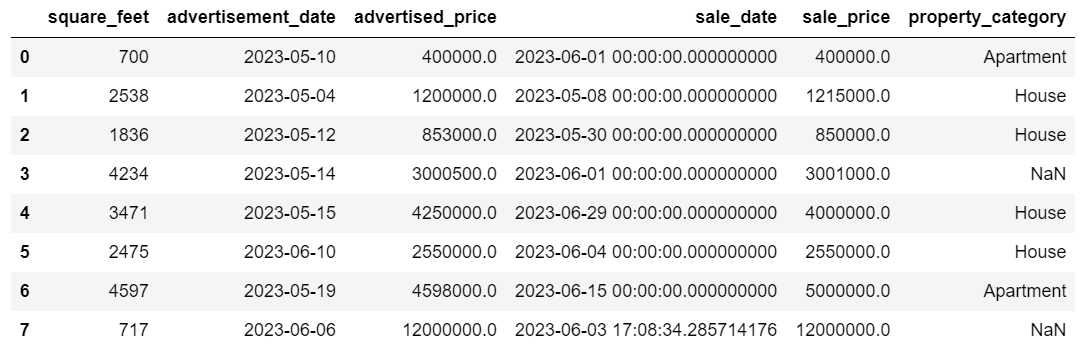
sale_date列には不要な時間情報が含まれていますので、削除しましょう。
日付を文字列表現と特定の形式に変換するために、strftime()メソッドを使用します。
df['sale_date'] = df['sale_date'].dt.strftime('%Y-%m-%d') 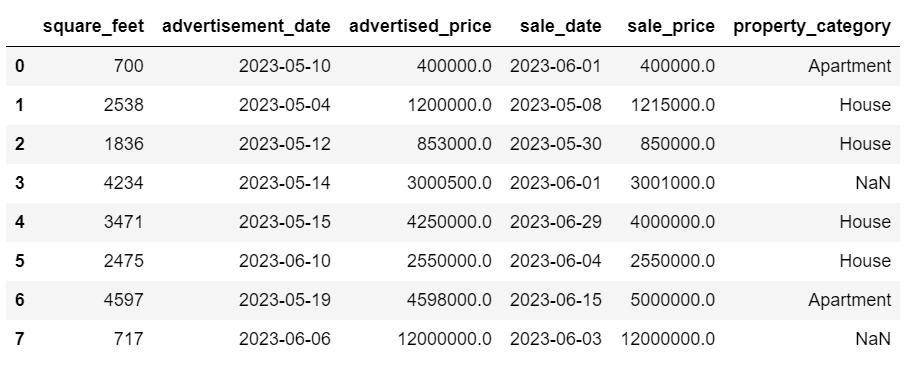
日付はすべて整然と見えます。
strftime()を複数の列に使用する場合は、以下のようにlambdaを再度使用できます。
df[['date1_formatted', 'date2_formatted']] = df[['date1', 'date2']].apply(lambda x: x.dt.strftime('%Y-%m-%d'))
さて、欠損値のカテゴリカルな値を埋める方法を見てみましょう。
カテゴリカルデータは、似た特性を持つ情報をグループ化するために使用されるデータの一種です。これらのグループのそれぞれはカテゴリです。カテゴリカルデータは数値の値を取ることができます(たとえば「1」は「男性」を示し、「2」は「女性」を示す)、しかし、これらの数値には数学的な意味がありません。例えば、それらを加算することはできません。
カテゴリカルデータは通常、2つのカテゴリに分けられます:
- 名義データ:これはカテゴリが単にラベル付けされており、特定の順序で配置することはできません。例えば、性別(男性、女性)、血液型(A、B、AB、O)、色(赤、緑、青)などがあります。
- 順序データ:これはカテゴリが順序付けやランク付けができる場合です。カテゴリ間の間隔は均等ではありませんが、カテゴリの順序には意味があります。例えば、評価スケール(映画の1から5までの評価)、教育レベル(高校、学部、大学院)、がんのステージ(ステージI、ステージII、ステージIII)などがあります。
欠損したカテゴリカルデータを埋めるためには、通常は最頻値が使用されます。この例では、column property_categoryはカテゴリカル(名義)データであり、2つの行にデータが欠損しています。
最頻値で欠損値を置き換えましょう。
# カテゴリカルな列の場合df['property_category'] = df['property_category'].fillna(df['property_category'].mode()[0])
このコードは、fillna()関数を使用してproperty_category列のすべてのNaN値を置き換えます。最頻値で置き換えます。
さらに、[0]の部分はこのSeriesから最初の値を抽出するために使用されます。複数の最頻値がある場合、これは最初の値を選択します。最頻値が1つだけの場合でもうまく動作します。
以下は出力例です。
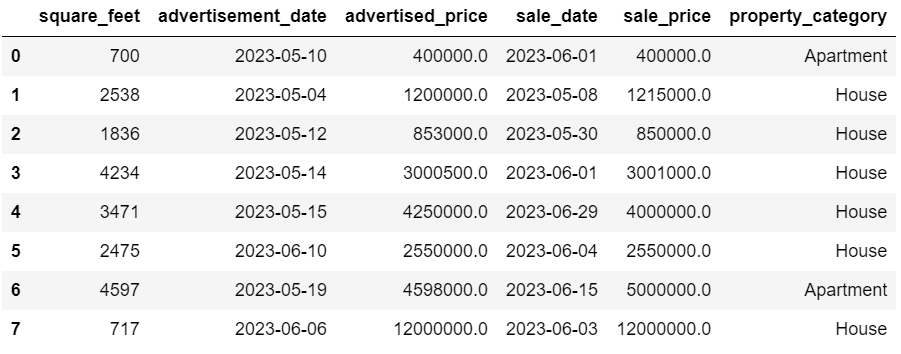
データはきれいになりました。残るは外れ値を確認することです。
NULLの処理については、このメタインタビューの質問で練習することができます。この質問では、NULLをゼロに置き換える必要があります。
外れ値の処理
外れ値は、データセット内の他の観測値から著しく異なるデータポイントです。これらの値はデータセット全体のパターンから外れた位置にあり、他の値と比べて著しく高いまたは低い値を持つため、異常と見なされます。
外れ値は、測定誤差や入力エラー、データ破損、真の統計的異常など、さまざまな理由で発生することがあります。
外れ値は、データ分析や統計モデリングの結果に重大な影響を与える可能性があります。それらは分布の歪みやバイアス、基になる統計的仮定の無効化、推定モデルの適合度の歪曲、予測モデルの予測精度の低下、誤った結論につながる可能性があります。
外れ値を検出するために一般的に使用される方法には、Zスコア、IQR(四分位範囲)、ボックスプロット、散布図、およびデータの可視化技術があります。一部の高度なケースでは、機械学習の手法も使用されます。
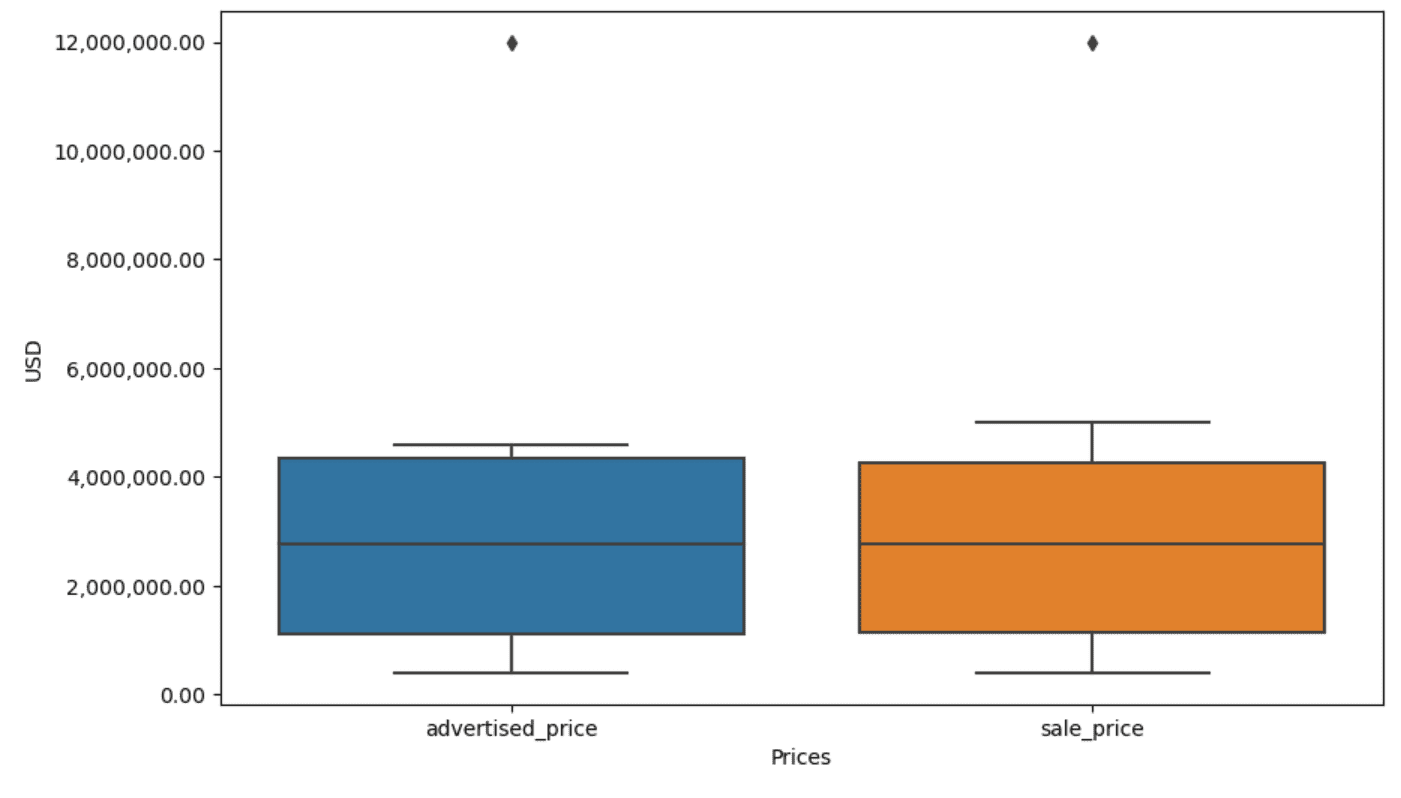
データの可視化は外れ値の識別に役立ちます。Seabornのboxplotはそのために便利です。
plt.figure(figsize=(10, 6))sns.boxplot(data=df[['advertised_price', 'sale_price']])
plt.figure()は、図の幅と高さをインチ単位で設定するために使用されます。
そして、columns advertised_priceとsale_priceのためのボックスプロットを作成します。以下のようになります。
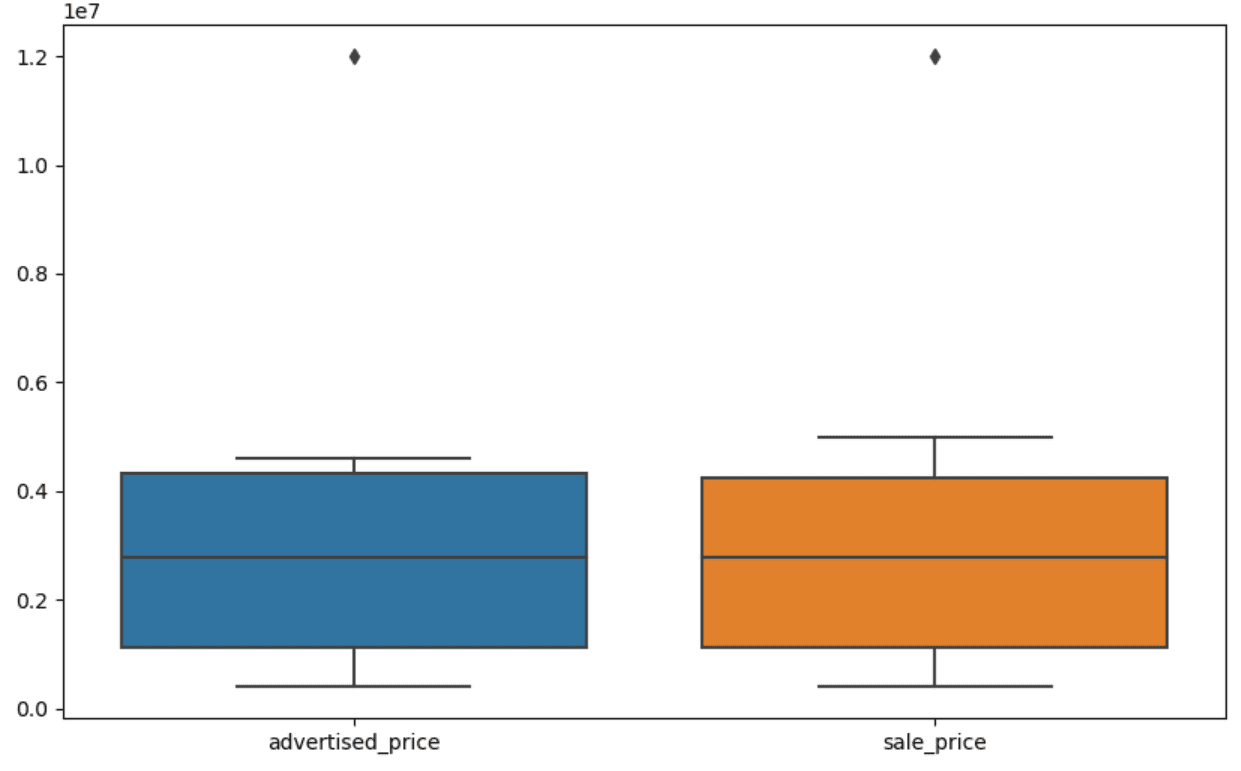
上記のコードにこれを追加することで、プロットをより使いやすく改善することができます。
plt.xlabel('価格')plt.ylabel('USD')plt.ticklabel_format(style='plain', axis='y')formatter = ticker.FuncFormatter(lambda x, p: format(x, ',.2f'))plt.gca().yaxis.set_major_formatter(formatter)
上記のコードを使用して、両軸のラベルを設定します。また、y軸の値が科学的記数法で表されているため、価格値では使用することができません。したがって、plt.ticklabel_format()関数を使用してこれをプレーンスタイルに変更します。
次に、コンマを千の区切り記号として、小数点をドット区切りとしてy軸の値を表示するフォーマッタを作成します。最後のコード行では、これを軸に適用します。
出力は以下のようになります。
さて、外れ値を特定して除去するにはどうすればいいでしょうか?
その一つの方法はIQRメソッドを使用することです。
IQR(四分位範囲)は、データセットを四分位数で分割して変動性を測定するための統計的な方法です。四分位範囲は、ランク順に並べられたデータセットを四つの等しい部分に分け、第一四分位(25パーセンタイル)と第三四分位(75パーセンタイル)の範囲内の値で構成されます。
四分位範囲はデータ中の外れ値を特定するために使用されます。以下がその動作方法です。
- まず、第一四分位(Q1)と第三四分位(Q3)を計算し、その後にIQRを決定します。IQRはQ3 – Q1で計算されます。
- Q1 – 1.5IQRより小さい値またはQ3 + 1.5IQRより大きい値は、外れ値と見なされます。
私たちのボックスプロットでは、ボックスは実際にはIQRを表しています。ボックス内の線は中央値(または第二四分位)です。ボックスプロットの「ひげ」はQ1とQ3から1.5*IQR範囲内を表しています。
これらの「ひげ」の外側のデータポイントは外れ値と見なすことができます。この場合、12,000,000ドルの値です。ボックスプロットを見ると、これがどれだけ明確に表されているかがわかり、データの可視化が外れ値の検出に重要であることが示されています。
さて、PythonコードでIQRメソッドを使用して外れ値を除去しましょう。まず、広告価格の外れ値を除去します。
Q1 = df['advertised_price'].quantile(0.25)Q3 = df['advertised_price'].quantile(0.75)IQR = Q3 - Q1df = df[~((df['advertised_price'] < (Q1 - 1.5 * IQR)) |(df['advertised_price'] > (Q3 + 1.5 * IQR)))]
最初に、quantile()関数を使用して第一四分位(または25パーセンタイル)を計算します。第三四分位または75パーセンタイルに対しても同様の操作を行います。
それらは、データの25%と75%以下の値を示しています。
次に、四分位範囲を計算します。ここまでのすべては、単にIQRの手順をPythonコードに翻訳しています。
最後のステップとして、外れ値を除去します。つまり、Q1 – 1.5 * IQR未満またはQ3 + 1.5 * IQR以上のすべてのデータです。
~演算子は条件を否定するため、外れ値ではないデータだけが残ります。
そして、同じことを販売価格でも行うことができます。
Q1 = df['sale_price'].quantile(0.25)Q3 = df['sale_price'].quantile(0.75)IQR = Q3 - Q1df = df[~((df['sale_price'] < (Q1 - 1.5 * IQR)) |(df['sale_price'] > (Q3 + 1.5 * IQR)))]
もちろん、より簡潔な方法でforループを使用することもできます。
for column in ['advertised_price', 'sale_price']: Q1 = df[column].quantile(0.25) Q3 = df[column].quantile(0.75) IQR = Q3 - Q1 df = df[~((df[column] < (Q1 - 1.5 * IQR)) |(df[column] > (Q3 + 1.5 * IQR)))]
このループは2つの列に反復処理を行います。各列に対して、IQRを計算してから、DataFrameから行を削除します。
この操作は、順番に行われることに注意してください。まず、advertised_priceのために行われ、次にsale_priceのために行われます。その結果、DataFrameは各列ごとに修正され、どちらかの列に外れ値があるため、行が削除される可能性があります。したがって、この操作では、advertised_priceとsale_priceの外れ値を独立して削除し、後から結果を組み合わせた場合よりも、行が少なくなる可能性があります。
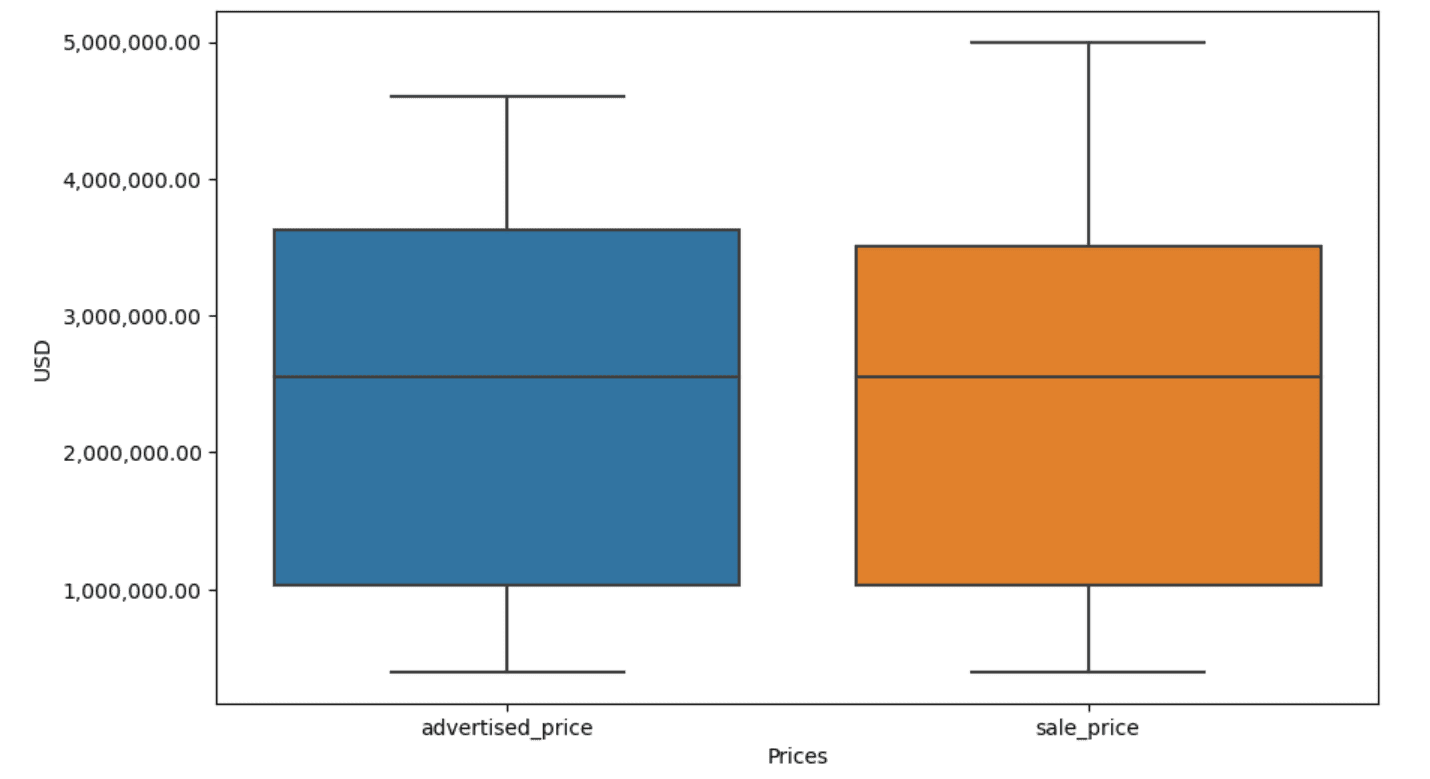
この例では、どちらの場合でも出力は同じになります。箱ひげ図がどのように変化したかを確認するには、前と同じコードを使用して再度プロットする必要があります。
plt.figure(figsize=(10, 6))sns.boxplot(data=df[['advertised_price', 'sale_price']])plt.xlabel('Prices')plt.ylabel('USD')plt.ticklabel_format(style='plain', axis='y')formatter = ticker.FuncFormatter(lambda x, p: format(x, ',.2f'))plt.gca().yaxis.set_major_formatter(formatter)
以下に結果が表示されます。
ジェネラルアセンブリーのインタビュー問題を解決することで、Pythonでパーセンタイルを計算する練習ができます。
結論
データのクリーニングは、データ分析プロセスで重要なステップです。時間がかかる場合がありますが、調査結果の正確性を確保するためには欠かせません。
幸いにも、Pythonの豊富なライブラリのエコシステムにより、このプロセスはより管理しやすくなりました。不要な行や列を削除し、データを再フォーマットし、欠損値や外れ値を処理する方法を学びました。これらはほとんどのデータに対して行わなければならない通常のステップです。ただし、2つの列を1つに結合したり、既存のデータを検証したり、ラベルを割り当てたり、余白を取り除いたりする必要がある場合もあります。
これらすべてがデータのクリーニングです。これにより、混乱した現実世界のデータを自信を持って分析できる構造化されたデータセットに変換できます。始めたデータセットと変更後のデータセットを比較してみてください。
もしもこの結果に満足を見出せず、クリーンなデータが奇妙な興奮を引き起こさないなら、データサイエンスで何をしているのでしょうか!
****[Nate Rosidi](https://twitter.com/StrataScratch)****はデータサイエンティストであり、製品戦略の分野でも活動しています。また、アナリティクスを教える非常勤講師でもあり、トップ企業の実際のインタビュー問題を使用してデータサイエンティストがインタビューに備えるのを支援するStrataScratchというプラットフォームの創設者です。彼とのつながりを築くには、Twitter:StrataScratchまたはLinkedInをご覧ください。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
