PythonのAsyncioをAiomultiprocessで強化しましょう:包括的なガイド
'PythonのAsyncioをAiomultiprocessで強化しましょう:ガイド'
PYTHON TOOLBOX
asyncioとmultiprocessingのパワーを利用して、アプリケーションを高速化する

この記事では、Pythonのaiomultiprocessというライブラリについて紹介します。このライブラリは、Pythonのasyncioとmultiprocessingの強力な機能を組み合わせています。
この記事では、豊富なコード例とベストプラクティスを通じて説明します。
この記事の終わりまでに、ヘッドシェフが一緒においしい料理を作るためにシェフたちをリードするように、aiomultiprocessの強力な機能を活用してPythonアプリケーションを向上させる方法を理解することができるでしょう。
はじめに
週末に同僚を招待して大きな食事をすることを想像してみてください。どのように行いますか?
- 私が通常のRDBMSをベクトルデータベースに変換して埋め込みを保存する方法
- UCLAの研究者が、最新の気候データと機械学習モデルに簡単で標準化された方法でアクセスするためのPythonライブラリ「ClimateLearn」を開発しました
- ベクトルデータベースについてのすべて – その重要性、ベクトル埋め込み、および大規模言語モデル(LLM)向けのトップベクトルデータベース
経験豊富なシェフとして、一度に1つの料理を作るわけではありません。それは遅すぎるでしょう。時間を効率的に使い、複数のタスクを同時に行います。
例えば、お湯を沸かすのを待っている間に、野菜を洗うために離れることができます。このようにして、お湯が沸騰したら野菜を鍋に投入することができます。これが並行性の魅力です。
しかし、レシピはしばしば厳しいものです。スープを作る際にはかき混ぜ続けなければならないし、野菜を洗って切らなければなりません。また、パンを焼いたり、ステーキを焼いたりする必要もあります。
多くの料理を準備する場合、圧倒されるでしょう。
幸いなことに、同僚たちはただ食べるのを待って座り込んでいるわけではありません。彼らはキッチンに入って手伝ってくれます。追加の人数ごとに追加の作業プロセスとして機能します。これが、multiprocessingと並行性の強力な組み合わせです。
コードでも同じことが言えます。Pythonアプリケーションにおいても、asyncioを使用していてもボトルネックに遭遇したことはありませんか?並行コードのパフォーマンスをさらに向上させる方法を探していませんか?それなら、aiomultiprocessが求めていた答えです。
インストール方法と基本的な使用方法
インストール
pipを使用する場合は、以下のようにインストールします:
python -m pip install aiomultiprocessAnacondaを使用している場合は、以下のようにconda-forgeからインストールします:
conda install -c conda-forge aiomultiprocess基本的な使用方法
aiomultiprocessには3つの主要なクラスがあります:
Processは他の2つのクラスの基底クラスであり、プロセスを開始し、コルーチン関数を実行するために使用されます。通常はこのクラスを使用する必要はありません。
Workerはプロセスを開始し、コルーチン関数を実行して結果を返すために使用されます。私たちはこのクラスも使用しません。
Poolは私たちが重点を置くコアクラスです。 multiprocessing.Poolと同様にプロセスプールを開始しますが、async withを使用してコンテキストを管理する必要があります。 mapとapplyの2つのメソッドを使用します。
mapメソッドはコルーチン関数とイテラブルを受け入れます。 Poolはイテラブルを反復処理し、コルーチン関数を複数のプロセスで実行します。 mapメソッドの結果は、async forを使用して非同期に反復処理することができます:
import asyncioimport randomimport aiomultiprocessasync def coro_func(value: int) -> int: await asyncio.sleep(random.randint(1, 3)) return value * 2async def main(): results = [] async with aiomultiprocess.Pool() as pool: async for result in pool.map(coro_func, [1, 2, 3]): results.append(result) print(results)if __name__ == "__main__": asyncio.run(main())applyメソッドは、コルーチン関数と関数の必要な引数のタプルを受け入れます。スケジューラのルールに従って、Poolはコルーチン関数を適切なプロセスに割り当てて実行します。
import asyncio
import random
import aiomultiprocess
async def coro_func(value: int) -> int:
await asyncio.sleep(random.randint(1, 3))
return value * 2
async def main():
tasks = []
async with aiomultiprocess.Pool() as pool:
tasks.append(pool.apply(coro_func, (1,)))
tasks.append(pool.apply(coro_func, (2,)))
tasks.append(pool.apply(coro_func, (3,)))
results = await asyncio.gather(*tasks)
print(results) # 出力: [2, 4, 6]
if __name__ == "__main__":
asyncio.run(main())実装原理と実際の例
aiomultiprocess.Poolの実装原理
以前の記事で、複数のCPUコアに対してasyncioタスクを分散する方法を説明しました。
一般的なアプローチは、loop.run_in_executorを使用してメインプロセスでプロセスプールを起動することです。それから、プロセスプール内の各プロセスでasyncioイベントループが作成され、コルーチン関数がそれぞれのループで実行されます。概略は以下の通りです:
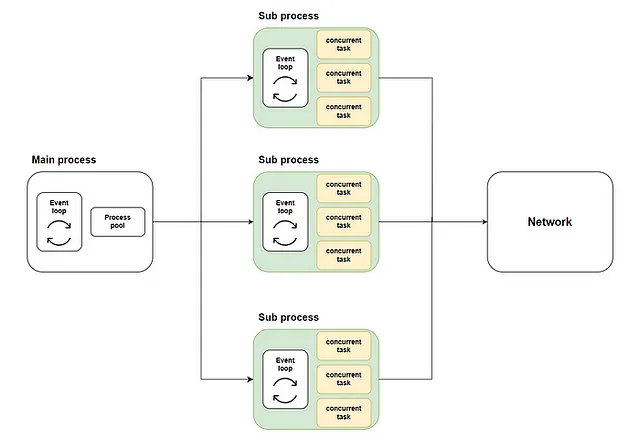
aiomultiprocess.Poolの実装は同様です。それはscheduler、queue、processの3つのコンポーネントで構成されています。
schedulerは、ヘッドシェフのようなもので、各シェフに適切な方法でタスクを割り当てる責任を持ちます。もちろん、ニーズに合ったヘッドシェフ(実装)を雇うこともできます。queueは、キッチンの組み立てラインのようなものです。厳密に言えば、注文ラインと配送ラインを含みます。ヘッドシェフはメニューを注文ラインを介してシェフに渡し、シェフは完成した料理を配送ラインを介して返します。processは、レストランのシェフのようなものです。それぞれが割り当てに従っていくつかの料理を並行して処理します。料理が完成するたびに、割り当てられた順序で手渡されます。
全体の概略は以下の通りです:
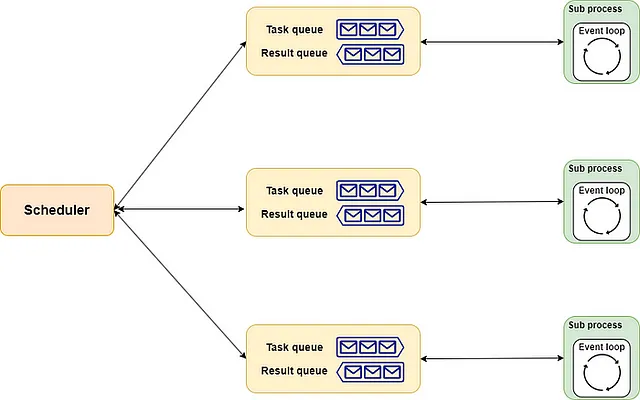
実世界の例
前述の説明に基づいて、aiomultiprocessの使用方法を理解したはずです。そのパワーを体験するために、実世界の例に潜り込みましょう。
まず、リモート呼び出しとループ計算を使用して、現実のデータ取得と処理のプロセスをシミュレートします。この方法は、IOバウンドタスクとCPUバウンドタスクがしばしば混在しており、その境界がはっきりしないことを示しています。
import asyncio
import random
import time
from aiohttp import ClientSession
from aiomultiprocess import Pool
def cpu_bound(n: int) -> int:
result = 0
for i in range(n*100_000):
result += 1
return result
async def invoke_remote(url: str) -> int:
await asyncio.sleep(random.uniform(0.2, 0.7))
async with ClientSession() as session:
async with session.get(url) as response:
status = response.status
result = cpu_bound(status)
return result次に、基準としてこのタスクを30回呼び出すために、従来のasyncioアプローチを使用しましょう:
async def main():
start = time.monotonic()
tasks = [asyncio.create_task(invoke_remote("https://www.example.com"))
for _ in range(30)]
await asyncio.gather(*tasks)
print(f"All jobs done in {time.monotonic() - start} seconds")
if __name__ == "__main__":
asyncio.run(main())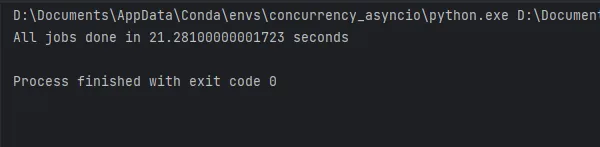
コードの実行結果は図に表示され、約21秒かかります。では、aiomultiprocessがこれをどれだけ改善するか見てみましょう。
aiomultiprocessの使用は簡単です。元々の並行コードを修正する必要はありません。メインメソッド内のコードをPoolで実行するように調整するだけです:
async def main(): start = time.monotonic() async with Pool() as pool: tasks = [pool.apply(invoke_remote, ("https://www.example.com",)) for _ in range(30)] await asyncio.gather(*tasks) print(f"All jobs done in {time.monotonic() - start} seconds")if __name__ == "__main__": asyncio.run(main())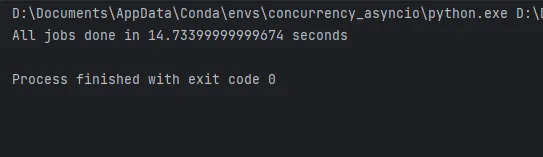
ご覧のように、aiomultiprocessを使用したコードは私のラップトップ上でわずか14秒で完了します。よりパワフルなコンピュータでは、性能向上はさらに大きくなるでしょう。
詳細なベストプラクティス
最後に、私の経験に基づいて、さらに実用的なベストプラクティスを共有します。
プールのみを使用する
aiomultiprocessはProcessおよびWorkerクラスも提供していますが、プロセスの作成にかかるリソース消費の大幅な削減を確保するために常にPoolクラスを使用するべきです。
キューの使用方法
以前の記事では、リソースとパフォーマンスのバランスを取るためにasyncio.Queueを使用してプロデューサー・コンシューマーパターンを実装する方法を説明しました。 aiomultiprocessでは、キューも使用できます。ただし、プロセスプール内にいるため、asyncio.Queueは使用できません。同時に、プロセスプール内ではmultiprocessing.Queueを直接使用することはできません。この場合、以下のコードでキューを作成するためにmultiprocessing.Manager().Queue()を使用する必要があります:
import randomimport asynciofrom multiprocessing import Managerfrom multiprocessing.queues import Queuefrom aiomultiprocess import Poolasync def worker(name: str, queue: Queue): while True: item = queue.get() if not item: print(f"worker: {name} got the end signal, and will stop running.") queue.put(item) break await asyncio.sleep(random.uniform(0.2, 0.7)) print(f"worker: {name} begin to process value {item}", flush=True)async def producer(queue: Queue): for i in range(20): await asyncio.sleep(random.uniform(0.2, 0.7)) queue.put(random.randint(1, 3)) queue.put(None)async def main(): queue: Queue = Manager().Queue() producer_task = asyncio.create_task(producer(queue)) async with Pool() as pool: c_tasks = [pool.apply(worker, args=(f"worker-{i}", queue)) for i in range(5)] await asyncio.gather(*c_tasks) await producer_taskif __name__ == "__main__": asyncio.run(main())initializerを使用してリソースを初期化する
コルーチンメソッドで<aiohttpセッションやデータベース接続プールを使用する必要がある場合、これらのオブジェクトはピクル化できないため、メインプロセスでタスクを作成する際に引数を渡すことはできません。
代替案として、グローバルオブジェクトと初期化メソッドを定義することができます。この初期化メソッドでは、グローバルオブジェクトにアクセスして初期化を実行します。
multiprocessing.Pool と同様に、 aiomultiprocess.Pool は初期化時に初期化メソッドと対応する初期化パラメータを受け入れることができます。このメソッドは、各プロセスが開始されるときに初期化を完了するために呼び出されます:
import asynciofrom aiomultiprocess import Poolimport aiohttpfrom aiohttp import ClientSession, ClientTimeoutsession: ClientSession | None = Nonedef init_session(timeout: ClientTimeout = None): global session session = aiohttp.ClientSession(timeout=timeout)async def get_status(url: str) -> int: global session async with session.get(url) as response: status_code = response.status return status_codeasync def main(): url = "https://httpbin.org/get" timeout = ClientTimeout(2) async with Pool(initializer=init_session, initargs=(timeout,)) as pool: tasks = [asyncio.create_task(pool.apply(get_status, (url,))) for i in range(3)] status = await asyncio.gather(*tasks) print(status)if __name__ == "__main__": asyncio.run(main())
例外処理とリトライ
aiomultiprocess.Pool は exception_handler パラメータを提供して例外処理をサポートしていますが、さらなる柔軟性が必要な場合は、 asyncio.wait と組み合わせる必要があります。 asyncio.wait の使用法については、以前の記事を参照してください。
asyncio.wait を使用することで、例外に遭遇したタスクを取得することができます。タスクを抽出した後、いくつかの調整を行い、タスクを再実行することができます。以下のコードに示すように:
import asyncioimport randomfrom aiomultiprocess import Poolasync def worker(): await asyncio.sleep(0.2) result = random.random() if result > 0.5: print("エラーが発生します") raise Exception("何かエラーが発生しました") return resultasync def main(): pending, results = set(), [] async with Pool() as pool: for i in range(7): pending.add(asyncio.create_task(pool.apply(worker))) while len(pending) > 0: done, pending = await asyncio.wait(pending, return_when=asyncio.FIRST_EXCEPTION) print(f"done、pendingの数は{len(done)}, {len(pending)}です") for result in done: if result.exception(): pending.add(asyncio.create_task(pool.apply(worker))) else: results.append(await result) print(results)if __name__ == "__main__": asyncio.run(main())
リトライにTenacityを使用する
もちろん、例外処理とリトライにはより柔軟で強力なオプションがあります。例えば、この記事で説明した Tenacity ライブラリを使用することができます。
Tenacity を使用すると、上記のコードを大幅に簡略化することができます。コルーチンメソッドにデコレータを追加するだけで、例外がスローされた場合にメソッドが自動的にリトライされます。
import asynciofrom random import randomfrom aiomultiprocess import Poolfrom tenacity import *@retry()async def worker(name: str): await asyncio.sleep(0.3) result = random() if result > 0.6: print(f"{name} エラーが発生します") raise Exception("何か問題が発生しました") return resultasync def main(): async with Pool() as pool: tasks = pool.map(worker, [f"worker-{i}" for i in range(5)]) results = await tasks print(results)if __name__ == "__main__": asyncio.run(main())
進捗を表示するためのtqdmの使用
画面の前で待っているときにコードがどこまで実行されたかを常に教えてくれるため、 tqdm が好きです。この記事では、その使用方法も説明しています。
aiomultiprocess は、タスクの完了を待つために asyncio のAPIを使用しているため、 tqdm とも互換性があります:
import asynciofrom random import uniformfrom aiomultiprocess import Poolfrom tqdm.asyncio import tqdm_asyncioasync def worker(): delay = uniform(0.5, 5) await asyncio.sleep(delay) return delay * 10async def main(): async with Pool() as pool: tasks = [asyncio.create_task(pool.apply(worker)) for _ in range(1000)] results = await tqdm_asyncio.gather(*tasks) print(results[:10])if __name__ == "__main__": asyncio.run(main())
結論
非同期コードを実行することは、料理人が料理を作ることに似ています。異なるタスクを同時に実行することで効率を向上させることができますが、最終的にはボトルネックに遭遇するでしょう。
この時点で最も単純な解決策は、料理プロセスの並列性を高めるためにより多くの料理人を追加することです。
Aiomultiprocessは、そのような強力なPythonライブラリです。複数のプロセスで並行タスクを実行することにより、非同期処理の単一スレッド性によって引き起こされるパフォーマンスのボトルネックを完全に解消します。
この記事でのaiomultiprocessの使用とベストプラクティスは、私の経験に基づいています。興味がある方は、コメントを残してディスカッションに参加してください。
コードの実行速度とパフォーマンスを向上させるだけでなく、さまざまなツールを使用して作業効率を向上させることもパフォーマンスの向上につながります:

Peng Qian
Pythonツールボックス
リスト4つのストーリーを表示 
私の紹介リンクでVoAGIに参加する – Peng Qian
VoAGIのメンバーとして、あなたの会費の一部はあなたが読んだ作家に支払われ、すべてのストーリーに完全にアクセスできます…
qtalen.medium.com
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
