遺伝的アルゴリズムを使用したPythonによるTV番組スケジューリングの最適化
PythonによるTV番組スケジューリングの最適化
遺伝的アルゴリズムを使用してPythonでTV番組のスケジュールを最適化する方法を実践的に解説するチュートリアル
VoAGIで新しい投稿を書いたのは久しぶりです。私は2年間、伝統的なメディアセクターにおいて機械学習やディープラーニングを通じてどのような改善ができるか研究してきました。その中の一つが最適化技術です。どの産業においても最適化は欠かせませんが、メディアにおいても同様です。そこで、この記事では進化的アルゴリズムである遺伝的アルゴリズムを活用してTV番組の計画を共有したいと思います。ただし、これは単純な実装ですので、実際の現場はこの単純さを超えています。
最適化とは何か、そしてなぜ必要なのか
最適化とは何でしょうか。まずこの問いから始めたいと思います。最適化とは、与えられた目的関数を最小化または最大化する値を探索することです。目的関数とは何でしょうか。目的関数は、最大化または最小化しようとしている性能指標の数学的表現です。問題が最小化問題であれば、それをコスト関数と呼ぶことができます。最大化問題であれば、それを適応度関数と呼ぶことができます。
この説明を例とともに豊かにしてみましょう。一つのレストランを経営していることを想像してください。私たちは、メニュー(メニューとはメニューに載っている料理のことを指します)を変更することで利益を最大化しようとします。まず思い浮かぶのは、より安価な材料を使用する方法です。材料の品質を下げることでより多くの利益を得ることができます。しかし、現実の世界ではそうはいきません。製品の品質を下げると、顧客は品質の低い材料を使用した料理への需要を減らします。したがって、目標を達成することはできません。
お分かりいただけるように、レストランオーナーにとってはメニューを作成して利益を最大化することが最適化の問題です。例えば、レストランオーナーはどの料理がいつ売れているのかを分析し、ロードマップを作成することができます。最適化技術を用いることで、レストランオーナーはデータに基づいた意思決定を行い、最良の結果を得ることができます。
- 「MACTAに会いましょう:キャッシュタイミング攻撃と検出のためのオープンソースのマルチエージェント強化学習手法」
- 「クラスタリング解放:K-Meansクラスタリングの理解」
- 「夢を先に見て、後で学ぶ:DECKARDは強化学習(RL)エージェントのトレーニングにLLMsを使用するAIアプローチです」
さて、テレビ局の番組プランナーとして働いていると想像してください。競合他社は強力ですが、それでも競争できる番組があります。決定しなければならない主な問題は、どの番組を何時に放送するかです。簡単そうに見えますが、本当にそうでしょうか?
テレビ番組の計画は簡単に見えるかもしれませんが、さまざまな要素の関与により非常に複雑になります。以下はその一部です:
視聴者の好み: 視聴者はどのようなテレビコンテンツのジャンルが好きですか?
放送時間帯: 視聴者はどのような期間にどのような番組を好むのでしょうか?
リードインとリードアウトの番組: 一部の番組は放送期間中に収集した観客を次の番組に引き継ぎます。
競合チャンネルの番組の好み: 競合チャンネルは何時にどの番組を放送していますか?
休日、特別なイベント、季節のトレンド: 視聴者の好みはどのように変化していますか?既存のトレンドはありますか?
新しいコンテンツと古いコンテンツ: 放送される番組は新鮮ですか?それともリピート放送ですか?
ストーリーラインとクリフハンガー: 番組にはストーリーラインがありますか?それともクリフハンガーですか?
これはほんの一部です。TV番組の計画には数十もの要素が影響を与えることに気づいたかもしれません。したがって、このような問題を解決するための最適化アルゴリズムは適しています。
評価と遺伝的アルゴリズムとは何ですか?
この部分では、評価と遺伝的アルゴリズムについて簡単に説明します。進化的アルゴリズム(EAs)は、特定の問題構造についての具体的な知識を必要とせずに、多くの困難な最適化問題を解決することができる最適化技術です。進化的アルゴリズム(EAs)は、線形および非線形の目的関数を扱うことができ、問題の構造についての情報を必要としません。一方、遺伝的アルゴリズムは探索アルゴリズムの一種であり、進化の原理を利用しています。繁殖と自然選択のプロセスを実装することで、高品質の解を生成することができます。遺伝的アルゴリズムは最適化問題を解決するために非常に効果的な技術です。
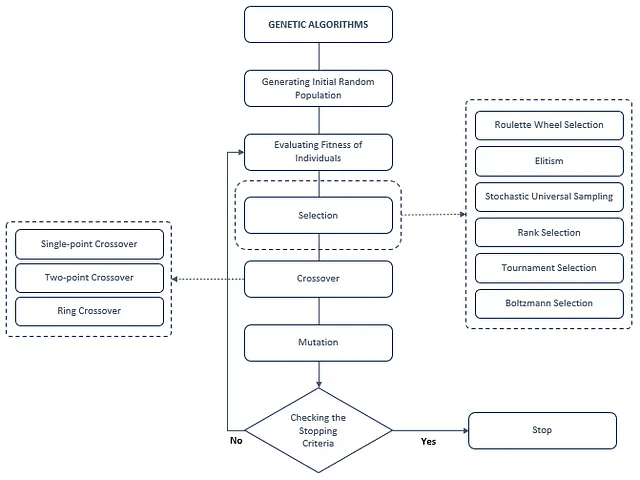
以下に簡単なGAフローチャートが表示されます。最初のステップは、初期集団を作成することです。初期集団にはランダムに選択された染色体(より明確には、初期集団は染色体の集合です)が含まれます。集団が作成された後、各個体の適応度関数の値が計算されます。遺伝アルゴリズムでは、各個体を表すために染色体を使用します。各個体の適応度値は他の個体とは独立しています。このように、複数の計算を同時に行うことができます。適応度値が計算された後、GAの3つの異なるフェーズ(選択、交叉、突然変異)が関与します。選択フェーズは、集団から染色体を選択する責任があります。目的は、より良い世代を作成することです。交叉プロセスは、選択された個体から新しい子孫を開発する責任があります。通常、このプロセスは、2つの選択された個体を取り、それぞれの染色体の一部を交換して子孫を表す2つの新しい染色体を作成することで行われます。最後に、突然変異フェーズでは、1つ以上の遺伝子を変更します。この変更の確率は非常に低いです。突然変異フェーズの最も重要な特徴は、システムが局所的な最小値に陥るのを防ぐことです。
実装
遺伝アルゴリズムについて簡単な情報を提供しました。これからPythonを使用して遺伝アルゴリズムをステップバイステップで説明します。タイトルでわかるように、私たちの問題はどのプログラムをいつ放送するかです。まず、強調すべき重要な点があります。すぐに実装する問題は単純な例です。前述したように、多くの要素が問題の実装に影響を与えます。このため、問題の特定フェーズが最も時間がかかる部分です。
ステップ
まず、データセットを定義して始めます。前述のように、以下のセットは単純な例です。データセットは、18時間(06:00〜24:00)にわたるさまざまな番組の評価を示しています。実際の生活では、異なる時間帯でプログラムの評価スコアを測定するために各時間帯で放送する必要があります。
# 各時間帯のサンプル評価プログラムデータセット。ratings = { 'news': [0.1, 0.1, 0.4, 0.3, 0.5, 0.4, 0.3, 0.2, 0.1, 0.2, 0.3, 0.5, 0.5, 0.4, 0.3, 0.2, 0.1, 0.2], 'live_soccer': [0.0, 0.0, 0.0, 0.2, 0.1, 0.3, 0.2, 0.1, 0.4, 0.3, 0.4, 0.5, 0.4, 0.6, 0.4, 0.3, 0.4, 0.3], 'movie_a': [0.1, 0.1, 0.2, 0.4, 0.3, 0.2, 0.1, 0.2, 0.3, 0.4, 0.5, 0.4, 0.3, 0.4, 0.3, 0.5, 0.3, 0.4], 'movie_b': [0.2, 0.1, 0.1, 0.3, 0.2, 0.1, 0.2, 0.3, 0.4, 0.5, 0.4, 0.3, 0.4, 0.5, 0.4, 0.3, 0.4, 0.5], 'reality_show': [0.3, 0.4, 0.3, 0.4, 0.4, 0.5, 0.3, 0.4, 0.5, 0.4, 0.3, 0.2, 0.1, 0.2, 0.3, 0.2, 0.2, 0.3], 'tv_series_a': [0.2, 0.3, 0.2, 0.1, 0.1, 0.2, 0.2, 0.4, 0.4, 0.3, 0.3, 0.3, 0.5, 0.6, 0.4, 0.5, 0.4, 0.3], 'tv_series_b': [0.1, 0.2, 0.3, 0.3, 0.2, 0.3, 0.3, 0.1, 0.4, 0.3, 0.4, 0.3, 0.5, 0.3, 0.4, 0.6, 0.4, 0.3], 'music_program': [0.3, 0.3, 0.3, 0.2, 0.2, 0.1, 0.2, 0.4, 0.3, 0.3, 0.3, 0.3, 0.2, 0.3, 0.2, 0.3, 0.5, 0.3], 'documentary': [0.3, 0.3, 0.4, 0.3, 0.2, 0.2, 0.3, 0.4, 0.4, 0.3, 0.2, 0.2, 0.2, 0.1, 0.1, 0.3, 0.3, 0.2], 'Boxing': [0.4, 0.3, 0.3, 0.2, 0.2, 0.1, 0.1, 0.1, 0.1, 0.3, 0.3, 0.3, 0.2, 0.3, 0.4, 0.3, 0.4, 0.6]}以下に、他の変数をご覧いただけます。これらの変数は遺伝的アルゴリズムで使用するハイパーパラメータです。また、後で使用するために2つの異なるリストも作成しました。
GEN = 100POP = 50CO_R = 0.8MUT_R = 0.2EL_S = 2all_programs = list(ratings.keys()) # すべてのプログラムall_time_slots = list(range(6, 24)) # 時間スロット当社の記事で述べたように、最初の仕事は人口を初期化することです。この目的のために作成した関数は以下の通りです。ご覧のように、この関数には2つの入力リストが必要です。プログラムのリストと時間スロットのリストはすでに上で定義されています。この関数はすべての潜在スケジュールを生成します。
def initialize_pop(programs, time_slots): if not programs: return [[]] all_schedules = [] for i in range(len(programs)): for schedule in initialize_pop(programs[:i] + programs[i + 1:], time_slots): all_schedules.append([programs[i]] + schedule) return all_schedules次に、フィットネス関数を定義します。フィットネス関数は各スケジュールの品質を測定する責任があります。スケジュールを入力として受け取り、総合評価スコアを返します。(スケジュールとは、テレビ番組からなる放送スケジュールと呼ぶリストのことです)
def fitness_function(schedule): total_rating = 0 for time_slot, program in enumerate(schedule): total_rating += ratings[program][time_slot] return total_ratingフィットネス関数を定義した後は、選択フェーズに進むことができます。選択フェーズは最適なスケジュールを見つけることを目的としています。これには以下の関数を使用します。この関数は各スケジュールのフィットネス値をチェックし、最も高い値を持つスケジュールを選択します。
def finding_best_schedule(all_schedules): best_schedule = [] max_ratings = 0 for schedule in all_schedules: total_ratings = fitness_function(schedule) if total_ratings > max_ratings: max_ratings = total_ratings best_schedule = schedule return best_schedule選択フェーズの後には、交叉フェーズが続きます。交叉フェーズでは、GAの助けを借りて2つの親解を組み合わせて新しい子孫を形成します。テレビ番組のスケジュール問題では、このプロセスは2つの解に存在するプログラム(遺伝子)を変更します。このプロセスはさまざまなテレビ番組の組み合わせを作成します。以下に交叉関数をご覧いただけます。
def crossover(schedule1, schedule2): crossover_point = random.randint(1, len(schedule1) - 2) child1 = schedule1[:crossover_point] + schedule2[crossover_point:] child2 = schedule2[:crossover_point] + schedule1[crossover_point:] return child1, child2最後のフェーズは突然変異フェーズです。前述のように、突然変異フェーズでは染色体の遺伝子材料を変化させることで新しい子孫が形成されます。テレビ番組の最適化問題では、プログラムをランダムに変更すると考えることができます。突然変異の確率は非常に低いことを覚えておいてください。また、この可能性をハイパーパラメータとして割り当てることもできます。
def mutate(schedule): mutation_point = random.randint(0, len(schedule) - 1) new_program = random.choice(all_programs) schedule[mutation_point] = new_program return schedule今すべての関数を定義したので、フィットネス関数を実行することができます。
# フィットネス関数の呼び出しdef evaluate_fitness(schedule): return fitness_function(schedule)遺伝的アルゴリズムに必要なデータが準備できました。これからアルゴリズムを定義します。このアルゴリズムにはinitial_schedule、generations、population_size、crossover_rate、mutation_rate、elitism_sizeが使用されます。これらは前に説明しました。ハイパーパラメータであるため、変更することもできますが、必要はありません。関数はまず、提供された初期スケジュールで初期人口を作成し、その後ランダムなスケジュールを追加します。その後、指定された世代数のループを実行し、各世代ごとに選択、交叉、突然変異の操作を使用して新しい人口を生成します。エリート主義は、適応度スコアに基づいて前の世代から最も成功した個体を保護するのに役立ちます。人口が更新されると、それが次の世代の現在の人口となります。その後、関数は前の世代から最良のスケジュールを返します。
def genetic_algorithm(initial_schedule, generations=GEN, population_size=POP, crossover_rate=CO_R, mutation_rate=MUT_R, elitism_size=EL_S): population = [initial_schedule] for _ in range(population_size - 1): random_schedule = initial_schedule.copy() random.shuffle(random_schedule) population.append(random_schedule) for generation in range(generations): new_population = [] # エリート主義 population.sort(key=lambda schedule: fitness_function(schedule), reverse=True) new_population.extend(population[:elitism_size]) while len(new_population) < population_size: parent1, parent2 = random.choices(population, k=2) if random.random() < crossover_rate: child1, child2 = crossover(parent1, parent2) else: child1, child2 = parent1.copy(), parent2.copy() if random.random() < mutation_rate: child1 = mutate(child1) if random.random() < mutation_rate: child2 = mutate(child2) new_population.extend([child1, child2]) population = new_population return population[0]結果を取得する準備が整いました。
initial_best_schedule = finding_best_schedule(all_possible_schedules)rem_t_slots = len(all_time_slots) - len(initial_best_schedule)genetic_schedule = genetic_algorithm(initial_best_schedule, generations=GEN, population_size=POP, elitism_size=EL_S)final_schedule = initial_best_schedule + genetic_schedule[:rem_t_slots]print("\n最終的な最適なスケジュール:")for time_slot, program in enumerate(final_schedule): print(f"時間帯 {all_time_slots[time_slot]:02d}:00 - プログラム {program}")print("総合評価:", fitness_function(final_schedule))遺伝的アルゴリズムが実行された後、初期のベストスケジュールと遺伝的スケジュールを組み合わせて最終的な最適なスケジュールを作成します。最後に、最適なスケジュールと割り当てられたプログラムを表示し、時間帯、対応するプログラム、および最終的な最適なスケジュールで達成された総合評価を表示します。

結論
番組企画は競争が激しい伝統的なメディア部門のテレビチャンネルにとって重要です。このケースでは、視聴者の評価を最大化するのに役立つ強力なツールである遺伝的アルゴリズムを利用して、TV番組のスケジューリングを改善する方法を示しました。TV番組のスケジューリングなどのスケジュール最適化の問題に遺伝的アルゴリズムを使用することを検討してください。その強力な機能を活用して、視聴者の関与と評価を最大化するスケジュールを作成することができます。
今後の記事では、競争的共進化型(CCQGA)や量子(QGA)などのさまざまな遺伝的アルゴリズムを探求する予定です。また、その間に追加のコンテンツも含めるかもしれません。
この記事をお読みいただき、ありがとうございました。ご興味があれば、LinkedInで私とつながることもお気軽にどうぞ。
https://www.linkedin.com/in/esersaygin/
参考文献
Pythonによる遺伝的アルゴリズムの実践:実世界の深層学習および人工知能の問題を解決するための遺伝的アルゴリズムの適用 著者:Eyal Wirsansky
Pythonを使用したエンジニア向け適用進化的アルゴリズム第1版 著者:Leonardo Azevedo Scardua
完全なコード
import random##################################### パラメータとデータセットの定義 ################################################################# 各時間帯のプログラムの評価データセットratings = { 'news': [0.1, 0.1, 0.4, 0.3, 0.5, 0.4, 0.3, 0.2, 0.1, 0.2, 0.3, 0.5, 0.5, 0.4, 0.3, 0.2, 0.1, 0.2], 'live_soccer': [0.0, 0.0, 0.0, 0.2, 0.1, 0.3, 0.2, 0.1, 0.4, 0.3, 0.4, 0.5, 0.4, 0.6, 0.4, 0.3, 0.4, 0.3], 'movie_a': [0.1, 0.1, 0.2, 0.4, 0.3, 0.2, 0.1, 0.2, 0.3, 0.4, 0.5, 0.4, 0.3, 0.4, 0.3, 0.5, 0.3, 0.4], 'movie_b': [0.2, 0.1, 0.1, 0.3, 0.2, 0.1, 0.2, 0.3, 0.4, 0.5, 0.4, 0.3, 0.4, 0.5, 0.4, 0.3, 0.4, 0.5], 'reality_show': [0.3, 0.4, 0.3, 0.4, 0.4, 0.5, 0.3, 0.4, 0.5, 0.4, 0.3, 0.2, 0.1, 0.2, 0.3, 0.2, 0.2, 0.3], 'tv_series_a': [0.2, 0.3, 0.2, 0.1, 0.1, 0.2, 0.2, 0.4, 0.4, 0.3, 0.3, 0.3, 0.5, 0.6, 0.4, 0.5, 0.4, 0.3], 'tv_series_b': [0.1, 0.2, 0.3, 0.3, 0.2, 0.3, 0.3, 0.1, 0.4, 0.3, 0.4, 0.3, 0.5, 0.3, 0.4, 0.6, 0.4, 0.3], 'music_program': [0.3, 0.3, 0.3, 0.2, 0.2, 0.1, 0.2, 0.4, 0
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
-
「トランスフォーマベースのLLMがパラメータから知識を抽出する方法」
-
「TR0Nに会ってください:事前学習済み生成モデルに任意のコンディショニングを追加するためのシンプルで効率的な方法」
-
「合成キャプションはマルチモーダルトレーニングに役立つのか?このAI論文は、合成キャプションがマルチモーダルトレーニングにおけるキャプションの品質向上に効果的であることを示しています」
-
「もしも、視覚のみのモデルを、わずかな未ラベル化画像を使って線形層のみを訓練することで、ビジョン言語モデル(VLM)に変換できたらどうでしょうか? テキストから概念へ(そしてその逆)のクロスモデルアラインメントによる、Text-to-Conceptの紹介」
-
「LogAIとお会いしましょう:ログ分析と知能のために設計されたオープンソースライブラリ」
-
「最も適応能力の高い生存者 コンパクトな生成型AIモデルは、コスト効率の高い大規模AIの未来です」
-
「17/7から23/7までのトップコンピュータビジョン論文」