Pythonを使用した探索的データ分析(EDA)の実践ガイド
Pythonによる探索的データ分析(EDA)の実践ガイド
この記事では、データサイエンスプロジェクトのライフサイクルの中でも最も重要な部分の1つである、探索的データ分析について、ステップバイステップでコード付きで説明します。
探索的データ分析(EDA)をデモンストレーションするために、Kaggle Spaceship Titanicデータセットを使用します。
機械学習プロジェクトの最初のステップは、データの探索です。さあ、始めましょう。
いくつかの基本的なライブラリをインポートします。
import numpy as npimport pandas as pdimport matplotlib.pyplot as pltimport seaborn as snsimport warningswarnings.filterwarnings('ignore')トレーニングデータを読み込みます
- テキストのポテンシャルを引き出す:プリエンベッドテキストクリーニング方法の詳細な調査
- 「生データから洗練されたデータへ:データの前処理を通じた旅 – パート1」
- 「ソフトウェア開発におけるAIの活用:ソリューション戦略と実装」
データを読み込むために、Pandasのread_csv関数を使用します。read_csv関数は、最初の引数としてCSVファイルへのパスを取ります。
training_data = pd.read_csv('/kaggle/input/spaceship-titanic/train.csv')train = training_data.copy()train.head()
不要な特徴(PassengerIdとName)を削除します
直感的には、人の生存の結果は彼/彼女の名前や乗客IDに依存しないと言えるので、これらの2つの特徴をデータから削除します。
## 不要な特徴(PassengerIdとName)を削除するtrain.drop(columns=['PassengerId','Name'], axis=1, inplace=True)データに関する基本的な情報を見つけます
train.info()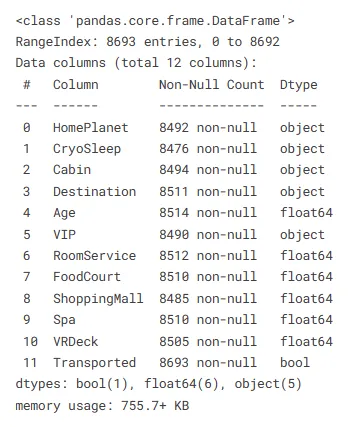
データを独立した特徴と依存した特徴に分割します
## データを独立した特徴と依存した特徴に分割するX = train.drop(['Transported'],axis=1)y = train['Transported']データの数値特徴とカテゴリ特徴の名前を取得します
## データの数値特徴とカテゴリ特徴の名前を取得するnum_feat = [feature for feature in X.columns if X[feature].dtypes != 'O' ]cat_feat = [feature for feature in X.columns if feature not in num_feat]print(f"データの数値特徴は {num_feat} です。\n")print(f"データのカテゴリ特徴は {cat_feat} です。")
‘Cabin’特徴を3つの異なる特徴に変換し、元の’Cabin’特徴を削除します
‘Cabin’特徴は、キャビンデスク、キャビン番号、およびキャビンサイドの3つの情報で構成されています。スラッシュを削除し、これらの3つの情報を分割して、それぞれの部分を含む3つの新しい特徴を作成します。また、3つの新しい特徴を作成した後、元のCabin特徴を削除します。
## Cabin特徴の値から'/'を削除するX['Cabin'] = X['Cabin'].str.replace('/','')## 元のCabin特徴を分割して3つの新しい特徴を作成するX['Cabin_deck'] = X['Cabin'].str[0]X['Cabin_num'] = X['Cabin'].str[1].apply(pd.to_numeric)X['Cabin_side'] = X['Cabin'].str[2]## 元のCabin特徴を削除するX.drop(['Cabin'], axis=1,inplace=True)キャビンの特徴変換後の新しい数値およびカテゴリ特徴の名前の確認
いくつかの新しい特徴が作成され、いくつかの古い特徴が削除されます。したがって、変換後に再び新しいカテゴリおよび数値特徴の名前を見つけましょう。
## 数値およびカテゴリ特徴の名前を再取得するnum_feat = [feature for feature in X.columns if X[feature].dtypes != 'O' ]cat_feat = [feature for feature in X.columns if feature not in num_feat]print(f"データの数値特徴は {num_feat} です。\n")print(f"データのカテゴリ特徴は {cat_feat} です。")
注意:この方法では、ブール型の特徴がある場合に適切な結果が得られません。しかし、データセットにはそのような特徴がないため、この方法を安全に使用できます。
ゼロ分散の特徴があるかどうかの確認
データの分散が高いほど、その特徴が依存特徴の予測に寄与する割合も高くなりますので、予測に寄与しない(つまり分散がゼロの)特徴を削除します。
## ゼロ分散の特徴を見つける(数値特徴用)for feature in num_feat: if X[feature].var() == 0: print(feature)このコードブロックでは、数値特徴の中に分散がゼロの特徴はありません。
## ゼロ分散の特徴を見つける(カテゴリ特徴用)for feature in cat_feat: if X[feature].nunique() == 1: print(feature)同様に、このコードブロックでもカテゴリ特徴の中に分散がゼロの特徴はありません。
カテゴリ特徴の一意の値の確認
カテゴリ特徴データの一意の値とその数を確認します。カテゴリ特徴の中に非常に多くの一意の値が存在する場合、その列を削除します。なぜなら、このような列はモデルトレーニングにほとんど寄与しない可能性が高いからです。
## 各カテゴリ特徴の一意の値を確認するfor feature in cat_feat: print(f"{feature} の一意の値は {X[feature].unique()} です(合計 {X[feature].nunique()} 個)。\n")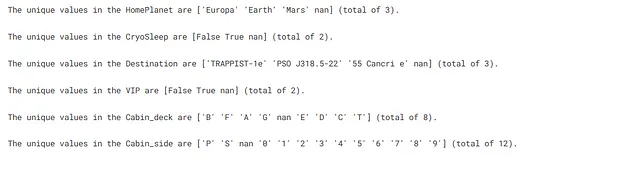
ここでは、非常に多くの一意の値を持つカテゴリ特徴は見つかりません。
独立した特徴と従属特徴の相関の確認
データの特徴間の相関を確認しましょう。これにより、以下の情報が分かります。いくつかの例を挙げます:
- 独立した特徴と従属特徴の相関。独立した特徴の中に、従属特徴と相関が非常に低いものがある場合、その特徴はモデルトレーニングにほとんど寄与しないため、削除することができます。これにより、モデルトレーニングに関連性のある特徴のみを保持し、過学習を防ぐことができます。
- 独立した特徴間の相関。2つの高い相関を持つ特徴が存在する場合、そのうちの1つをデータから簡単に削除できます。これにより、モデルをより堅牢にし、過学習も防ぐことができます。
数値的な独立した特徴と従属特徴の相関を見つける。
## 数値的な独立した特徴と従属特徴の相関を確認するfrom sklearn.preprocessing import OrdinalEncoderimport matplotlib.pyplot as pltimport seaborn as snsdf1 = pd.DataFrame(X[num_feat], columns=num_feat) # 数値特徴のデータフレームdf2 = pd.DataFrame(y, columns=['Transported']) # 従属特徴のデータフレームdf_num = pd.concat([df1, df2], axis=1) # 数値特徴と従属特徴を結合したデータフレームplt.figure(figsize=(12,8))corr = df_num.corr()mask = np.triu(np.ones_like(corr, dtype=bool))sns.heatmap(corr, annot=True, cmap='coolwarm',mask=mask)plt.tight_layout()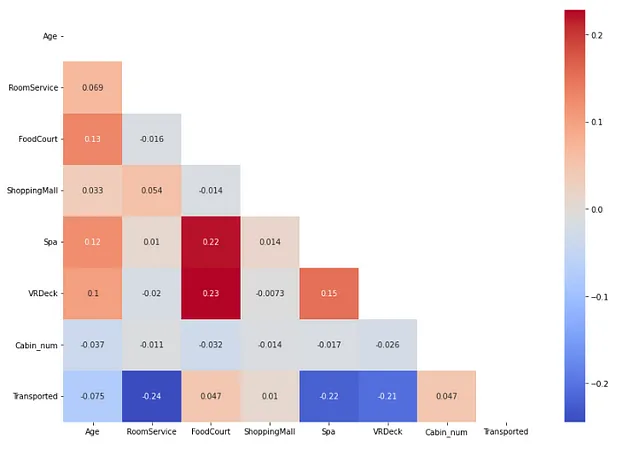
ここでは、高い相関がある二つの数値の独立した特徴を見つけることはありませんでした。
カテゴリカルな独立した特徴と従属特徴の相関を見つけるための処理。
## カテゴリカルな独立した特徴と従属特徴の相関をチェックするfrom sklearn.preprocessing import OrdinalEncoderdf1 = pd.DataFrame(OrdinalEncoder().fit_transform(X[cat_feat]), columns=cat_feat) # エンコードされたカテゴリカル特徴のデータフレームdf2 = pd.DataFrame(y, columns=['Transported']) # 従属特徴のデータフレームdf_cat = pd.concat([df1, df2], axis=1) # エンコードされたカテゴリカル特徴と従属特徴のデータフレームplt.figure(figsize=(12,8))corr = df_cat.corr()mask = np.triu(np.ones_like(corr, dtype=bool))sns.heatmap(corr, annot=True, cmap='coolwarm',mask=mask)plt.tight_layout()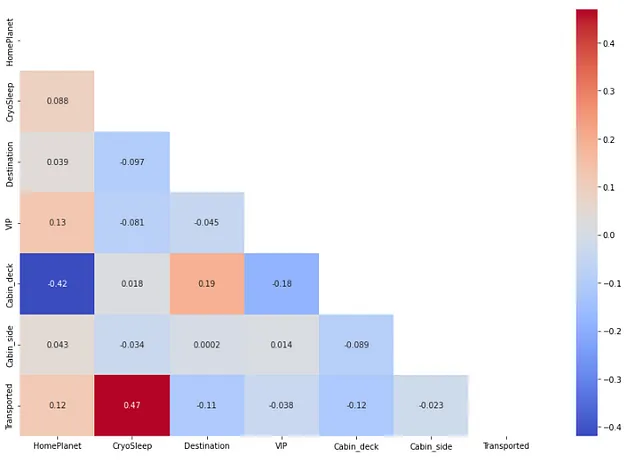
ここでも、高い相関がある二つのカテゴリカルな特徴を見つけることはありませんでした。相関関数が動作するために、カテゴリカルな特徴にエンコードを行っています。
データ中の欠損値の存在を確認する
## 各特徴の欠損値の数をチェックするmissing_values_df = pd.DataFrame()missing_values_df['Features'] = X.columnsmissing_values_df['Number_of_missing_values'] = X.isnull().sum().to_numpy()missing_values_df['Percentage_of_missing_values (%)'] = missing_values_df['Number_of_missing_values'].apply(lambda x: np.round((x/X.shape[0])*100),2)missing_values_df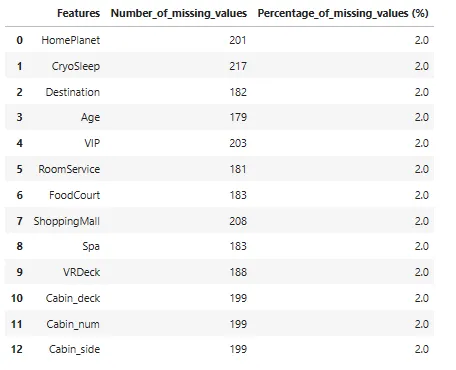
おもしろおかしく欠損値を可視化しましょう。
import missingno as msgnmsgn.matrix(X)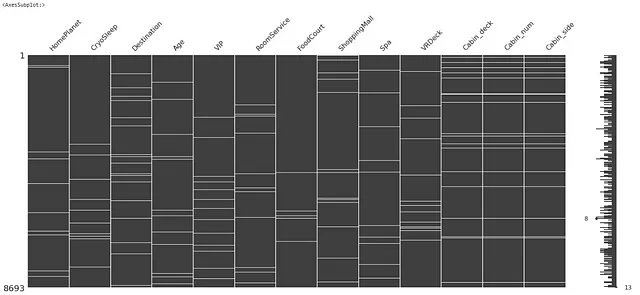
上の図では、各特徴の欠損値が白い線で表示されています。
データには非常に少量の欠損値があります(全体のデータサイズの約2%)
欠損値の処理はデータ前処理の中でも非常に重要なタスクの一つです。欠損値を削除したり、補完したりすることがよく行われます。ただし、欠損値を処理するために常に最適な選択肢とは限りません。場合によっては、データを収集する際に特定の条件が原因でデータが欠損している可能性があります。また、データが特定のパターンで欠損している場合もあります。
これを明確にするために、例を挙げてみましょう。大学生の調査を行っているとします。調査の中での質問の一つは、個人の体重を尋ねるものです。この場合、女子学生の中には調査に体重を記入することに躊躇する人がいるかもしれません(大学の女子学生は体重について男子学生よりも意識が高いという考えがあるためです。それが本当かどうかはわかりませんが、この例のためにそう仮定しましょう)。そのため、女子学生の年齢の欠損値が非常に多くなります。これは特定のパターンによる欠損値の例です。
さらに別の例を考えてみましょう。調査の中の別の質問は筋力に関するものです。この質問の場合、多くの男子学生が回答を記入することに躊躇するかもしれません(これも同様に、男子学生は自分の体格や筋力についてかなり意識しているという考えがあるためです)。そのため、男子学生の中で欠損値が多くなります。
上記の基準に基づいて、欠損値の処理方法を決定する必要があります。欠損値を置き換える際に、欠損値のパターンを維持する一つの方法は、Scikit-LearnのSimpleImputerを使用して、add_indicatorという引数を指定することです。
分布プロットとボックスプロットを使用してデータの外れ値の存在をチェックする
- 分布プロットを使用する
データの特徴の分布が歪んでいる場合、データ中に外れ値が存在することを確認することができます。
## 数値特徴量の外れ値の存在を分布プロットを使用してチェックsns.set_style('darkgrid')plt.figure(figsize=(22,13))for index, feature in enumerate(num_feat): plt.subplot(3,3,index+1) sns.distplot(X[feature],kde=True, color='b') plt.xlabel(feature) plt.ylabel('distribution') plt.title(f"{feature} distribution")plt.tight_layout()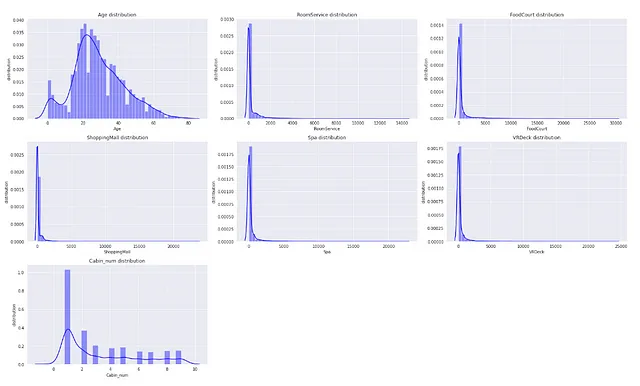
2. ボックスプロットを使用する
ボックスプロットは、データ中の外れ値を直感的に可視化する方法です。
値が (第3四分位値 + 定数 * 四分位範囲) より大きい場合、値は外れ値です
値が (第1四分位値 – 定数 * 四分位範囲) より小さい場合、値は外れ値です
通常、使用される定数の値は1.5です。ボックスプロットでは、外れ値はほとんどの場合、空の円で表されます。
## ボックスプロットを使用して外れ値を明確に可視化するX[num_feat].plot(kind='box',figsize=(15,10))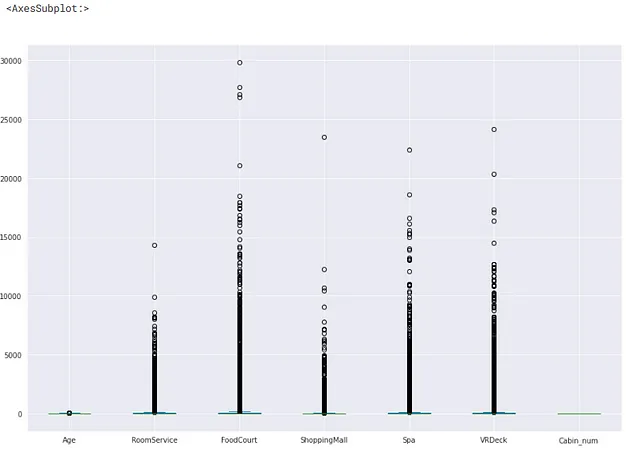
なお、この分布はデータの欠損値を処理する前のものです。データの欠損値を補完すると分布が変わる可能性があるため、データの欠損値を処理した後にデータの分布を確認することは良い方法です。
今回の問題では、目的に応じて外れ値を分析する必要があります。例えば、クレジットカードの不正検知を行っている場合、データの外れ値を検出するために外れ値を探しています。そのため、外れ値を除去することは意味がありません。しかし、一方で、外れ値はモデルの精度を低下させる可能性もあります。以下の図は、問題に応じて外れ値を分析する方法を示しています。
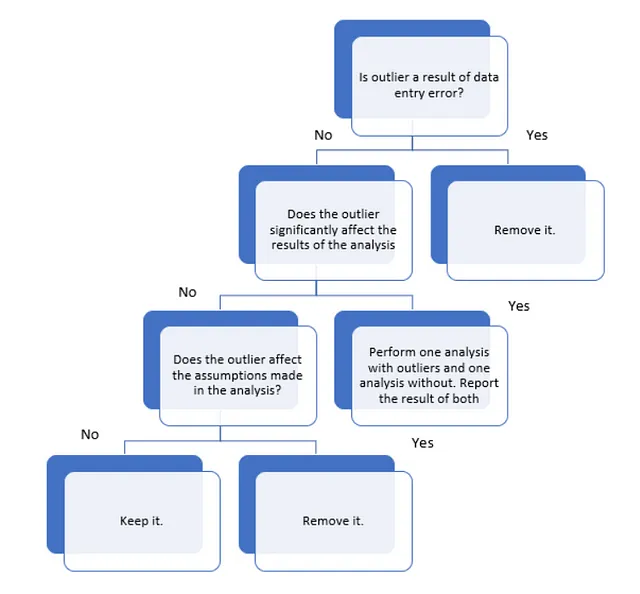
ここでは、乗客が生存したかどうかを予測するために、年齢やルームサービスにいくら費やしたかなどの情報が与えられます。したがって、私たちの問題では、非常に高齢または非常に若い人、非常に高額または非常に低額のルームサービス、フードコート、ショッピングモール、スパ、VRデッキなどが外れ値となります。
独立した特徴量間の多重共線性をチェックするために、pairplotとVIF値を使用して相関関係を確認する
分析では、2つ以上の独立した特徴量が相互に高い相関を持ち、機械学習モデルのトレーニングプロセスにユニークな情報を提供しない場合、多重共線性が発生します。これを確認するために、3つの方法があります:相関プロット(前述のものと同様)、pairplot、およびVIF値の使用です。これらのうち、VIF値は多重共線性を確認する確実な方法です。
ここでは、数値特徴量の多重共線性をチェックします。
- pairplotを使用する
2つの特徴量のプロットにパターンが表示されている場合、それらの特徴量間には多重共線性があると確信できます。
sns.pairplot(X[num_feat], corner=True,diag_kind='kde')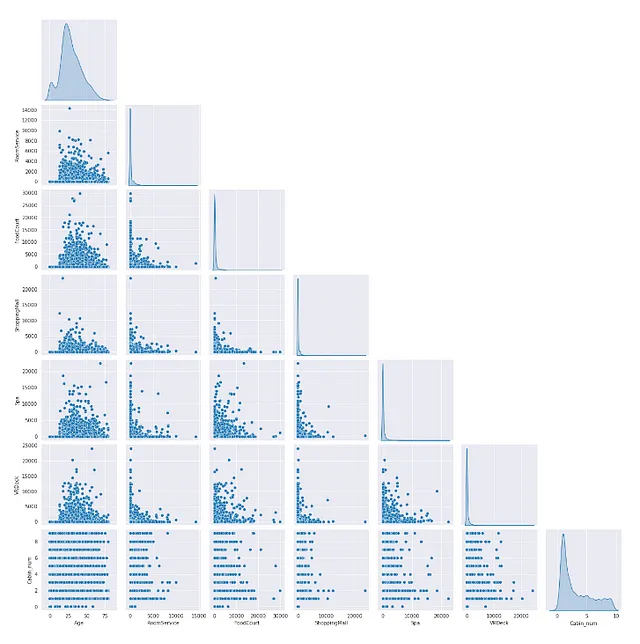
データの数値特徴量間にはあまりパターンが見られません。
2. VIF値を使用する
VIF値の解釈:
VIF = 1: モデル内の与えられた予測変数と他の予測変数との間に相関はありません。VIFが1から5の間: モデル内の与えられた予測変数と他の予測変数との間には中程度の相関があります。VIF > 5: モデル内の与えられた予測変数と他の予測変数との間には重度の相関があります。
## 数値独立変数の多重共線性を検出します。# VIF値の解釈には次の経験則を使用します。from patsy import dmatricesfrom statsmodels.stats.outliers_influence import variance_inflation_factorfrom sklearn.impute import SimpleImputer#create DataFrame to hold VIF valuesvif_df = pd.DataFrame()vif_df['Variable'] = num_feat # 各予測変数のVIFを計算します。データの欠損値は平均値で補完してから関数に渡しますnum_df = pd.DataFrame(SimpleImputer(strategy='mean').fit_transform(X[num_feat]), columns=num_feat)vif_df['VIF'] = [variance_inflation_factor(num_df.values, i) for i in range(num_df.shape[1])]def mc_check(x): if x == 1: return '低い' elif (x > 1 and x < 5): return '中程度' elif (x >= 5): return '重度'vif_df['多重共線性の有無'] = vif_df['VIF'].apply(mc_check)# 各予測変数のVIFを表示します。print(vif_df)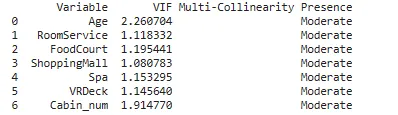
カテゴリカル特徴量の分布をチェックする
## カテゴリカル特徴量の分布をチェックしますsns.set_style('darkgrid')plt.figure(figsize=(22,7))for index, feature in enumerate(cat_feat): plt.subplot(2,3,index+1) sns.countplot(x=feature,data=X,palette='coolwarm') plt.xlabel(feature) plt.ylabel('分布') plt.title(f"{feature}の分布") plt.tight_layout()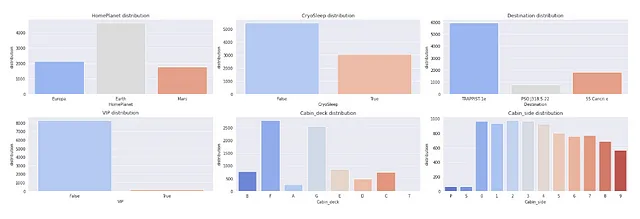
データセットが不均衡かどうかをチェックする
データセットが不均衡であるとは、依存変数のユニークな値ごとのデータポイントの数が大きく異なる場合を指します。不均衡なデータセットは、データセットをトレーニングデータと検証データに分割する際に問題を引き起こします。また、そのようなデータに基づいてトレーニングされた機械学習モデルは、新しいデータに対してうまく汎化しません。
## データセットが不均衡かどうかをチェックするtrain['Transported'].value_counts()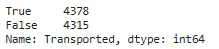
ここで、’True’と’False’の数が大きく異ならないことがわかります。したがって、データは不均衡ではないと結論づけることができます。
これは通常、探索的データ解析(EDA)が行われる方法の非常に基本的な説明です。EDAには他にも多くのステップが含まれる場合がありますが、それらは実践から来るものです。また、データ、外れ値、欠損値などを視覚化するためのさまざまな種類の興味深い直感的なグラフを作成する方法もたくさんあります。こうしたことを探求することを強くお勧めします。多くの興味深いアイデアを見つけるには、Kaggleは素晴らしい場所です。
リソース
EDAのステップの1つは、分散がゼロの特徴を見つけるために実行されました。特徴が保持する情報量に分散がどのように関連しているかを知るには、Casey Chengの次の記事を参照してください。
主成分分析(PCA)の視覚的な説明(数学なし)
主成分分析(PCA)は、データの視覚化と次元削減に欠かせないツールです…
towardsdatascience.com
ボックスプロットについては、Wikipediaを参照してください。
この記事で使用されているコードは、私のKaggleのノートブックから借用しました。以下のリンクを使用して、全体のコードをチェックしてください。
airship-titanic-4
Kaggle Notebooksを使用して機械学習コードを探索および実行する | Spaceship Titanicのデータを使用
www.kaggle.com
アウトロ
この記事がお気に入りになったことを願っています。VoAGIで私をフォローして、他の記事も読んでください。
LinkedInで私とつながってください。
ウェブサイトで私についてもっと知る。
[email protected]までメールしてください。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- 「Med-PaLM Multimodal(Med-PaLM M)をご紹介します:柔軟にエンコードし、解釈するバイオメディカルデータの大規模なマルチモーダル生成モデル」
- 「BI-LSTMを用いた次の単語予測のマスタリング:包括的なガイド」
- 「研究論文メタデータの簡単な説明」
- 「Scikit-Learnクラスを使用したカスタムトランスフォーマを作成するためのシンプルなアプローチ」
- 「多数から少数へ:機械学習における次元削減による高次元データの取り扱い」
- 「MITとスタンフォードの研究者は、効率的にロボットを制御するために機械学習の技術を開発しましたこれにより、より少ないデータでより良いパフォーマンスが得られるようになります」
- 「LG AI Researchが提案するQASA:新しいAIベンチマークデータセットと計算アプローチ」
