Pythonを使用したデータのスケーリング
'Pythonによるデータのスケーリング'

機械学習プロセスにおいて、データのスケーリングはデータの前処理または特徴エンジニアリングの一環です。モデル構築の前にデータをスケーリングすることにより、以下のことが実現できます:
- スケーリングにより、特徴量の値を同じ範囲に保つことができます
- スケーリングにより、モデル構築に使用する特徴量が無次元になります
- スケーリングは外れ値の検出に使用することができます
データのスケーリングにはいくつかの方法があります。最も重要なスケーリング技術は正規化と標準化です。
正規化を使用したデータのスケーリング
データを正規化してスケーリングする場合、変換されたデータは以下の式を使って計算できます:
- Metaphy LabsのAIエバンジェリストに会いましょう
- 今日、開発者の70%がAIを受け入れています:現在のテックの環境での大型言語モデル、LangChain、およびベクトルデータベースの台頭について探求する
- マイクロソフトの研究者たちは、ラベル付きトレーニングデータを使用せずにパレート最適な自己監督を用いたLLMキャリブレーションの新しいフレームワークを提案しています
ここで
正規化のPython実装
正規化を使用してスケーリングするには、以下のコードを使用します:
from sklearn.preprocessing import Normalizer
norm = Normalizer()
X_norm = norm.fit_transform(data)与えられたデータ X が
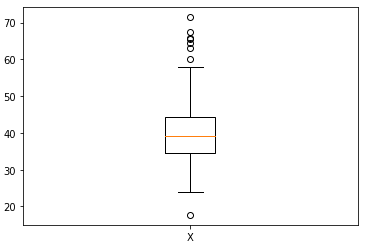
正規化された X は以下の図に示されています:
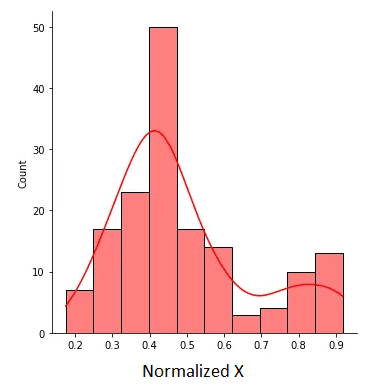 図2. 値が0から1の範囲にある正規化された X。作者による画像。
図2. 値が0から1の範囲にある正規化された X。作者による画像。
標準化を使用したデータのスケーリング
理想的には、データが正規分布またはガウシアン分布に従っている場合に標準化を使用するべきです。標準化されたデータは以下のように計算できます:
ここで、 はデータの平均であり、
は標準偏差です。標準化された値は通常、[-2, 2] の範囲にあるべきであり、これは95%信頼区間を表します。-2未満または2より大きい標準化された値は外れ値と見なすことができます。したがって、標準化は外れ値の検出に使用することができます。
標準化のPython実装
標準化を使用してスケーリングするには、以下のコードを使用します:
from sklearn.preprocessing import StandardScaler
stdsc = StandardScaler()
X_std = stdsc.fit_transform(data)上記のデータを使用して、標準化されたデータは以下のようになります:
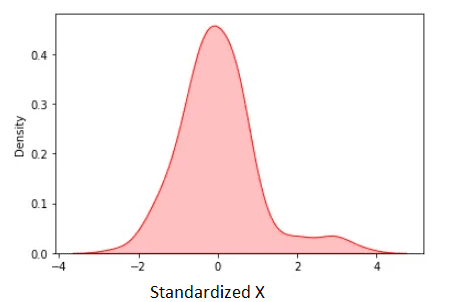 図3. 標準化された X。作者による画像。
図3. 標準化された X。作者による画像。
標準化された平均はゼロです。上記の図から、一部の外れ値を除いて、ほとんどの標準化されたデータが[-2, 2] の範囲にあることがわかります。
結論
まとめると、特徴量のスケーリングには、標準化と正規化という2つの最も人気のある方法があります。正規化されたデータは範囲[0, 1]にあり、標準化されたデータは通常範囲[-2, 2]にあります。標準化の利点は、外れ値の検出に使用できることです。ベンジャミン・O・タヨは、物理学者、データサイエンス教育者、作家であり、DataScienceHubのオーナーでもあります。以前、ベンジャミンはCentral Oklahoma大学、Grand Canyon大学、Pittsburgh State大学で工学と物理学を教えていました。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
