PythonとPandasを使用したデータ集計:地質学のリソロジーデータの分析
'PythonとPandasで地質学のリソロジーデータを集計・分析'
ノルウェー大陸棚のZechstein Group内のリトロジー変動の探索

データ集約技術を使用することで、圧倒的でほとんど理解できない数値データセットを、簡単に理解できるものに変換し、より読みやすくすることができます。データ集約のプロセスでは、複数のデータポイントをまとめて単一の指標に要約し、データの高レベルな概要を提供できるようにします。
ペトロ物理学および地球科学の中で、このプロセスを適用する方法の1つは、ウェルログ測定から解釈された地質層のリトロジー組成を要約することです。
この短いチュートリアルでは、ノルウェー大陸棚から90以上のウェルズからなる大規模なデータセットを取り、Zechstein Groupのリトロジー組成を抽出する方法について説明します。
ライブラリのインポートとデータのロード
まず、データをCSVから読み込み、集計を行うために使用するpandasライブラリをインポートする必要があります。
import pandas as pdpandasライブラリがインポートされたら、pd.read_csv()を使用してCSVファイルを読み込むことができます。
使用するデータは、ウェルログ測定からリトロジーを予測することを目的とした、XEEKとForce 2020 Machine Learning competitionの組み合わせデータです。使用するデータセットは、利用可能なトレーニングデータのすべてを表しています。このデータセットの詳細は、記事の最後に記載されています。
このCSVファイルには、カンマではなくセミコロンで区切られたデータが含まれているため、sepパラメータにセミコロンを渡す必要があります。
df = pd.read_csv('data/train.csv', sep=';')このコードを実行して読み込みプロセスを開始することができます。大規模なデータセット(1100万行以上)を使用しているため、数秒かかる場合があります。しかし、読み込みが完了すると、dfオブジェクトを呼び出すことでデータフレームを表示することができます。これにより、データフレームが返され、最初の5行と最後の5行が表示されます。
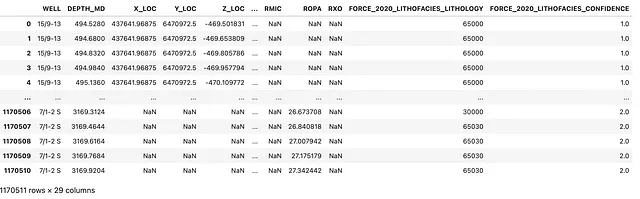
pandasの.map()を使用して数値コードをリトロジー文字列に変換する
このデータセットでは、リトロジーデータはFORCE_2020_LITHOFACIES_LITHOLOGY列に格納されています。しかし、データを詳しく見ると、リトロジーの値が数値でエンコードされていることがわかります。キーを知っていない限り、どの数値がどのリトロジーを表しているのかを解読するのは難しいでしょう。
幸いにも、このデータセットではキーがあり、キーとリトロジーペアを持つ辞書を作成することができます。
lithology_numbers = {30000: '砂岩', 65030: '砂岩/シェール', 65000: 'シェール', 80000: 'マール', 74000: 'ドロマイト', 70000: '石灰岩', 70032: 'チョーク', 88000: 'ハリート', 86000: '無水鉱石', 99000: 'タフ', 90000: '石炭', 93000: '地下室'}この辞書をデータセットに適用するために、pandasのmap()関数を使用することができます。この関数は、辞書を使用してルックアップを行い、正しいリトロジーラベルを数値値に割り当てます。
df['LITH'] = df['FORCE_2020_LITHOFACIES_LITHOLOGY'].map(lithology_numbers)これを実行すると、データフレームを再度表示して、マッピングが成功し、新しいLITH列がデータフレームの末尾に追加されたことを確認できます。
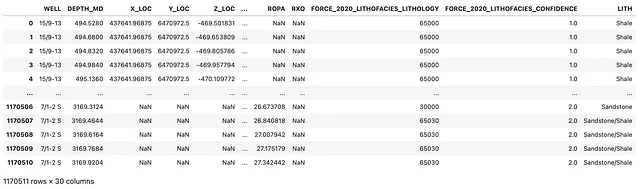
特定の地質グループに対するデータフレームのフィルタリング
11,705,511行の非常に大きなデータセットがあるため、リソロジーの組成分析に特定の地質グループに焦点を当てることが良いでしょう。
この場合、データをサブセットし、ゼッチェンシュタイングループを見てみましょう。
これを実現するには、query()メソッドを使用して簡単な文字列を渡すだけです:GROUP == "ZECHSTEIN GP."
df_zechstein = df.query('GROUP == "ZECHSTEIN GP."')df_zechstein.WELL.unique()サブセットに含まれるウェルの数を確認するために、df_zechstein.WELL.unique()を呼び出すことで、以下の配列が返されます。
array(['15/9-13', '16/1-2', '16/10-1', '16/11-1 ST3', '16/2-16', '16/2-6', '16/4-1', '17/11-1'], dtype=object)私たちは岩相に興味があるだけなので、単にウェル名と岩相の列を抽出することができます。これにより、集計を行いやすくなります。
df_zechstein_liths = df_zechstein[['WELL', 'LITH']]
チェーンされたPandas関数を使用したデータの集計
データを操作できる形式になったので、集計プロセスを開始できます。これには、Pandasの複数のメソッドを単一でチェーンする必要があります。
まず、groupby関数を使用して、WELL列を使用してデータをグループ化します。これにより、WELL列内の一意のウェル名ごとにデータフレームのサブセットが作成されます。
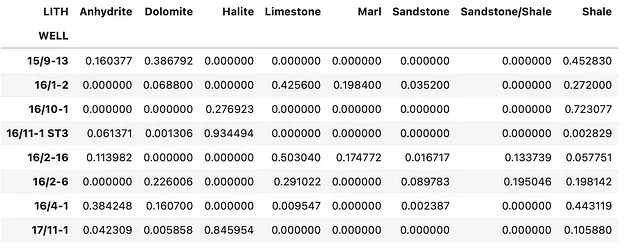
次に、各グループ内の各岩相タイプの出現回数をカウントします。 normalize=Trueの部分は、絶対件数ではなく比率(0から1の間)を返すことを意味します。たとえば、あるウェル(グループ)で「砂岩」が5回、「シェール」が15回出現する場合、この関数は「砂岩」に対して0.25、「シェール」に対して0.75を返すことになります。
最後に、結果のデータフレームを再配置して、行インデックスにウェル名を、列に岩相名を含める必要があります。あるウェルに特定の岩相のインスタンスが存在しない場合、fill_value=0によりゼロで埋められます。
summary_df = df_zechstein_liths.groupby('WELL').value_counts(normalize=True).unstack(fill_value=0)summary_df以下のようなデータフレームが返されます。これはウェルごとの各岩相の小数比率を示しています。
パーセントとして表示する場合、以下のコードを使用して表示方法を変更できます:
summary_df.style.format('{:.2%}')このコードを実行すると、以下のデータフレームが返されます。これにより、より読みやすいテーブルが提供され、レポートに組み込むことができます。
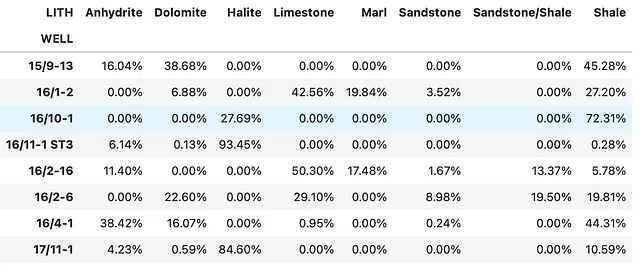
このスタイルを適用しても、実際の値は変わりません。値は引き続きそのままの小数値として格納されます。
値を永久的にパーセントに変更したい場合は、データフレームに100を乗算することで行うことができます。
summary_df = summary_df * 100summary_df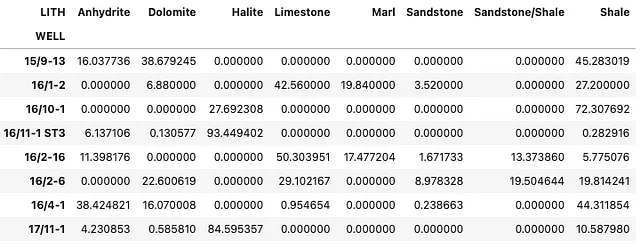
データがこの形式になったら、以下のインフォグラフィックのようなものを作成するために使用できます。これにより、各井戸のリソロジーのパーセンテージが表示されます。
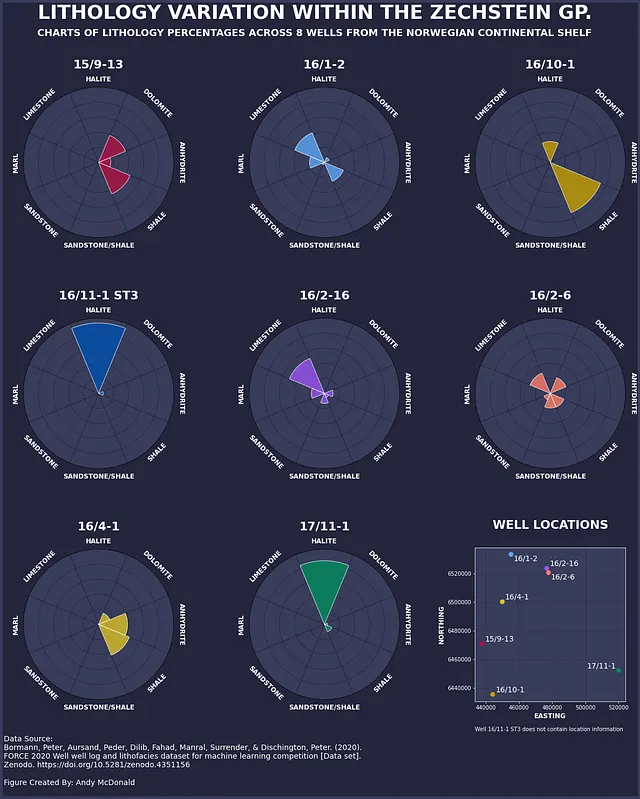
概要
この短いチュートリアルでは、90以上の井戸からなる大量のウェルログデータを取り、特定の地質グループを抽出して要約する方法を紹介しました。これにより、報告書やプレゼンテーションに組み込むことができる、読みやすく理解しやすい形式で地質グループの岩石組成を理解することができます。
このチュートリアルで使用されるデータセット
XeekおよびFORCE 2020(Bormann et al.、2020)が主催する機械学習コンテストの一環として使用されたトレーニングデータセット。このデータセットはクリエイティブ・コモンズ・ライセンス・表示4.0国際でライセンスされています。
フルデータセットは以下のリンクからアクセスできます:https://doi.org/10.5281/zenodo.4351155 。
お読みいただきありがとうございます。退去する前に、ぜひ私のコンテンツに登録して、私の記事を受け取ってください。 こちらで登録できます!
また、VoAGIのフル体験を得て、他の数千人のライターや私をサポートするために会員登録することもできます。月額5ドルで、素晴らしいVoAGIの記事に完全アクセスできるだけでなく、執筆でお金を稼ぐチャンスもあります。
私のリンクを使用して登録すると、あなたの料金の一部が私に直接サポートとして提供され、追加費用はかかりません。ご協力いただける場合は、本当にありがとうございます。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
