「Pythonを使用してPDFファイルからテキストを抽出する:包括的なガイド」
PythonでPDFからテキストを抽出するガイド
PDFファイルから表、画像、プレーンテキストのテキスト情報を完全に抽出するプロセス
はじめに
大規模言語モデル(LLM)とその幅広い応用において、テキストデータの重要性はこれまでにないほど高まっています。テキストの要約や翻訳から感情と財務報告のトピックに基づいた株価の予測まで、このようなテキストデータの種類は多岐にわたります。
ウェブ記事やブログ投稿から手書きの手紙や詩まで、このような非構造化情報を共有する多くのドキュメントが存在します。ただし、このテキストデータの大部分はPDF形式で保存および転送されています。具体的には、毎年Outlookで20億以上のPDFが開かれ、Google Driveとメールには73万以上の新しいPDFファイルが保存されていることがわかっています(2)。
そのため、これらのドキュメントをより体系的に処理し、情報を抽出する方法を開発することで、この膨大なテキストデータを自動化されたフローで理解し、活用することが可能になります。そして、このタスクにおいて、もちろん私たちの最良の友人はPythonです。
しかし、プロセスを開始する前に、現在のPDFの種類、特に最も頻繁に出現する3つの種類を明確にする必要があります:
- プログラムで生成されたPDF: これらのPDFは、HTML、CSS、JavascriptなどのW3C技術またはAdobe Acrobatなどの別のソフトウェアを使用してコンピュータ上で作成されます。このタイプのファイルには、画像、テキスト、リンクなどさまざまなコンポーネントが含まれており、これらはすべて検索可能で編集が容易です。
- 従来のスキャンされた文書: これらのPDFは、スキャナーマシンやモバイルアプリを通じて非電子VoAGIから作成されます。これらのファイルは、PDFファイル内に一緒に保存されたイメージのコレクションです。ただし、テキストやリンクなど、これらのイメージに表示される要素は選択または検索できません。基本的に、PDFはこれらのイメージのコンテナとして機能します。
- OCRを使用したスキャンされた文書: この場合、文書のスキャン後にOptical Character Recognition(OCR)ソフトウェアが使用され、ファイル内の各イメージ内のテキストを識別し、検索および編集可能なテキストに変換します。その後、ソフトウェアはイメージに実際のテキストを含むレイヤーを追加し、ファイルをブラウズする際に別のコンポーネントとして選択できるようにします(3)。
最近では、OCRシステムが搭載された機械が増えてきており、スキャンされた文書からテキストを識別することができますが、まだ全ページが画像形式の文書が存在します。おそらく、素晴らしい記事を読みながら文を選択しようとすると、代わりにページ全体が選択されることがあるかもしれません。これは特定のOCRマシンの制限または完全な不在の結果です。そのため、この記事の情報を見逃さないようにするために、これらのケースも考慮し、貴重で情報豊富なPDFから最大限の情報を取得できるプロセスを作成しました。
理論的なアプローチ
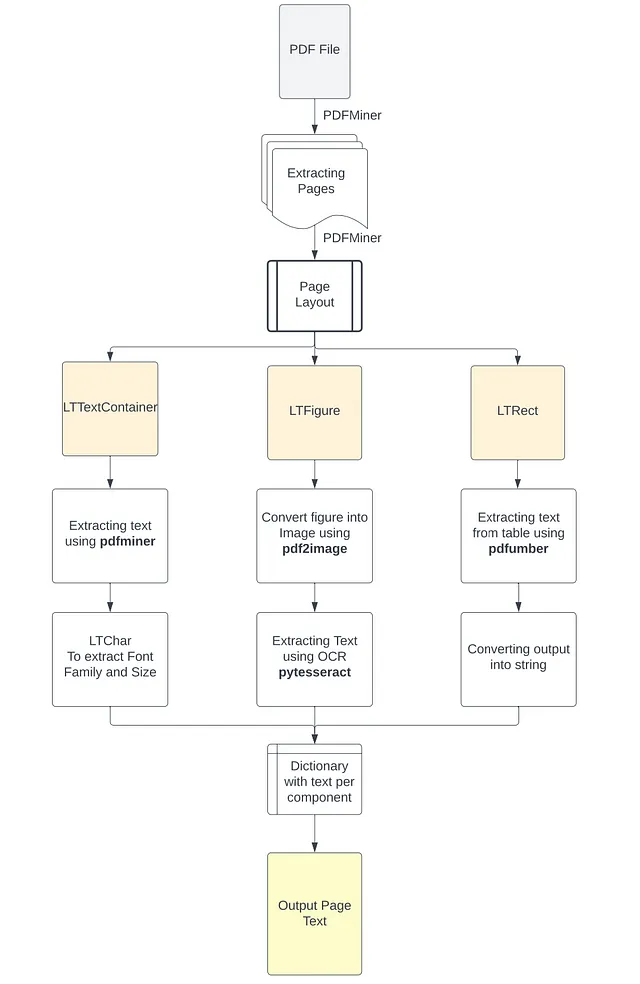
これらの異なるタイプのPDFファイルとそれらを構成するさまざまな要素を考慮しながら、PDFのレイアウトの初期分析を実施し、各コンポーネントに必要な適切なツールを特定することが重要です。具体的には、この分析の結果に基づいて、PDFからテキストを抽出するための適切な方法を適用します。つまり、コーパスブロック内でレンダリングされたテキスト、イメージ内のテキスト、およびテーブル内の構造化されたテキストなど、PDF内のテキストの抽出に対して適切なアプローチを選択します。OCRのないスキャンされたドキュメントでは、イメージからテキストを識別して抽出するアプローチが主な役割を果たします。このプロセスの出力は、PDFファイルの各ページに抽出された情報を含むPythonの辞書になります。この辞書の各キーはドキュメントのページ番号を表し、対応する値は以下の5つのネストされたリストを含むリストです:
- コーパスの各テキストブロックから抽出されたテキスト
- 各テキストブロックのテキストの形式(フォントファミリーとサイズ)
- ページ内のイメージから抽出されたテキスト
- テーブル内の構造化された形式で抽出されたテキスト
- ページの完全なテキスト内容

その方法で、ソースコンポーネントごとに抽出されたテキストをより論理的に分離することができ、特定のコンポーネント(例:ロゴ画像内の会社名)に通常表示される情報をより簡単に取得するのに役立つことがあります。さらに、テキストから抽出されたメタデータ(フォントファミリーやサイズなど)は、テキストヘッダーや重要なテキストのハイライトなどの識別に使用でき、テキストを複数の異なるチャンクにさらに分離または後処理するのに役立ちます。最後に、LLMが理解できる形式で構造化されたテーブル情報を保持することは、抽出されたデータ内の関係について行われる推論の品質を大幅に向上させます。その後、これらの結果は各ページに表示されたすべてのテキスト情報の出力として構成されます。
このアプローチのフローチャートは、以下の画像で確認できます。
必要なライブラリのインストール
このプロジェクトを開始する前に、必要なライブラリをインストールする必要があります。Python 3.10以上がマシンにインストールされていることを前提とします。それ以外の場合は、ここからインストールできます。次に、以下のライブラリをインストールしましょう:
PyPDF2: リポジトリパスからPDFファイルを読み取るために使用します。
pip install PyPDF2Pdfminer: レイアウト分析を実行し、PDFからテキストと書式を抽出するために使用します(ライブラリの.sixバージョンはPython 3をサポートしています)。
pip install pdfminer.sixPdfplumber: PDFページ内のテーブルを識別し、情報を抽出するために使用します。
pip install pdfplumberPdf2image: 切り抜かれたPDF画像をPNG画像に変換するために使用します。
pip install pdf2imagePIL: PNG画像を読み取るために使用します。
pip install PillowPytesseract: OCR技術を使用して画像からテキストを抽出するために使用します。
これは少し複雑ですが、まずGoogle Tesseract OCRをインストールする必要があります。これは、行認識と文字パターンの識別に基づいたLSTMモデルを使用したOCRマシンです。
Macユーザーの場合は、ターミナルからBrewを使用してマシンにこれをインストールし、準備完了です。
brew install tesseractWindowsユーザーの場合は、リンク先の手順に従ってインストールできます。ソフトウェアをダウンロードしてインストールする際に、コンピューターの環境変数に実行可能ファイルのパスを追加する必要があります。または、次のコードを使用してPythonスクリプトに直接パスを含めるために、次のコマンドを実行することもできます:
pytesseract.pytesseract.tesseract_cmd = r'C:\Program Files\Tesseract-OCR\tesseract.exe'その後、Pythonライブラリをインストールできます
pip install pytesseract最後に、スクリプトの最初にすべてのライブラリをインポートします。
# PDFを読み取るためのimport PyPDF2# PDFのレイアウトを分析し、テキストを抽出するためのimport pdfminer.high_level.extract_pages, extract_textfrom pdfminer.layout import LTTextContainer, LTChar, LTRect, LTFigure# PDFのテーブルからテキストを抽出するためのimport pdfplumber# PDFから画像を抽出するためのfrom PIL import Imagefrom pdf2image import convert_from_path# OCRを実行して画像からテキストを抽出するためのimport pytesseract# 作成された追加ファイルを削除するためのimport osこれで準備完了です。楽しい部分に移りましょう。
Pythonによるドキュメントのレイアウト分析

予備的な分析では、PDFMiner Pythonライブラリを使用してドキュメントオブジェクトを複数のページオブジェクトに分割し、各ページのレイアウトを分析して細かく調査しました。PDFファイルには、人間の目で見ると段落や文、単語などの構造化情報が欠けています。代わりに、PDFはページ上の個々の文字とその位置のみを理解します。PDFMinerは、ページの内容をファイル内の個々の文字とその位置に再構成しようとします。それから、その文字と他の文字との距離を比較することで、適切な単語、文、行、段落のテキストを構成します。このため、ライブラリは以下のような機能を持っています:
高レベルなextract_pages()関数を使用して、PDFファイルから個々のページを分離し、それらをLTPageオブジェクトに変換します。
次に、各LTPageオブジェクトに対して、上から下に向かって各要素を反復処理し、適切なコンポーネントを次のいずれかとして識別しようと試みます:
- ページ内の別のPDFドキュメントとして埋め込まれた図または画像を表すLTFigure
- 四角形領域内のテキスト行グループを表すLTTextContainer。これはさらにLTTextLineオブジェクトのリストによって詳細に分析されます。それぞれは、テキストの単一の文字とそのメタデータを保持するLTCharオブジェクトのリストを表します。(5)
- ページ内の画像や図をフレームするため、テーブルを作成するために使用できる2次元の四角形を表すLTRect
したがって、ページのこの再構築とその要素をLTFigure(ページの画像や図)またはLTTextContainer(ページのテキスト情報)またはLTRect(テーブルの存在を強く示す)に分類することに基づいて、適切な関数を適用して情報をより正確に抽出することができます。
for pagenum, page in enumerate(extract_pages(pdf_path)): # ページを構成する要素を反復処理 for element in page: # 要素がテキスト要素かどうかを確認 if isinstance(element, LTTextContainer): # テキストブロックからテキストを抽出する関数 pass # テキストの形式を抽出する関数 pass # 画像をチェック if isinstance(element, LTFigure): # PDFを画像に変換する関数 pass # OCRでテキストを抽出する関数 pass # テーブルをチェック if isinstance(element, LTRect): # テーブルを抽出する関数 pass # テーブルの内容を文字列に変換する関数 passしたがって、プロセスの分析部分を理解したので、各コンポーネントからテキストを抽出するために必要な関数を作成しましょう。
PDFからテキストを抽出する関数を定義する
ここからは、テキストコンテナからテキストを抽出するのは非常に簡単です。
# テキストを抽出する関数を作成するdef text_extraction(element): # インラインテキスト要素からテキストを抽出 line_text = element.get_text() # テキストの形式を検索 # テキスト行内で表示されたすべての形式をリストで初期化 line_formats = [] for text_line in element: if isinstance(text_line, LTTextContainer): # テキスト行内の各文字を反復処理 for character in text_line: if isinstance(character, LTChar): # 文字のフォント名を追加 line_formats.append(character.fontname) # 文字のフォントサイズを追加 line_formats.append(character.size) # テキスト行内の一意のフォントサイズと名前を検索 format_per_line = list(set(line_formats)) # 各行のテキストとその形式を含むタプルを返す return (line_text, format_per_line)したがって、テキストコンテナからテキストを抽出するには、単純にLTTextContainer要素のget_text()メソッドを使用します。このメソッドは、特定のコーパスボックス内の単語を構成する文字をすべて取得し、テキストデータのリストに出力を保存します。このリストの各要素は、コンテナに含まれるテキストの生の情報を表します。
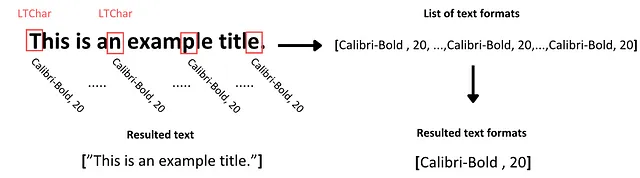
次に、このテキストの形式を識別するために、LTTextContainerオブジェクトを反復処理してこのコーパスの各テキスト行にアクセスします。各反復で、このコーパスのチャンク内のテキスト行を表す新しいLTTextLineオブジェクトが作成されます。その後、ネストされた行要素にテキストが含まれているかどうかを調べます。含まれている場合、個々の文字要素であるLTCharにアクセスし、その文字のすべてのメタデータを含みます。このメタデータから、2種類の形式を抽出し、該当するテキストに対応するように別々のリストに格納します:
- 文字のフォントファミリ、および文字が太字または斜体の形式であるかどうか
- 文字のフォントサイズ
一般的に、特定のテキストチャンク内の文字は、太字で強調表示されていない限り、一貫したフォーマットを持ちます。さらなる分析を容易にするために、テキスト内のすべての文字のテキストフォーマットの一意の値をキャプチャし、適切なリストに格納します。
画像からテキストを抽出する関数を定義する
ここがより難しい部分だと思います。
PDFに含まれる画像内のテキストの扱い方はどうすればよいでしょうか?
まず、PDFに保存されている画像要素は、JPEGやPNGなどのファイルとは異なる形式ではないことを認識する必要があります。そのため、OCRソフトウェアを適用するためには、まずこれらの要素をファイルから分離し、それから画像形式に変換する必要があります。
# PDFから画像要素を切り取る関数を作成するdef crop_image(element, pageObj): # PDFから画像を切り取るための座標を取得する [image_left, image_top, image_right, image_bottom] = [element.x0,element.y0,element.x1,element.y1] # 座標を使用してページを切り取る pageObj.mediabox.lower_left = (image_left, image_bottom) pageObj.mediabox.upper_right = (image_right, image_top) # 切り取ったページを新しいPDFに保存する cropped_pdf_writer = PyPDF2.PdfWriter() cropped_pdf_writer.add_page(pageObj) # 切り取ったPDFを新しいファイルに保存する with open('cropped_image.pdf', 'wb') as cropped_pdf_file: cropped_pdf_writer.write(cropped_pdf_file)# PDFを画像に変換する関数を作成するdef convert_to_images(input_file,): images = convert_from_path(input_file) image = images[0] output_file = "PDF_image.png" image.save(output_file, "PNG")# 画像からテキストを読み取る関数を作成するdef image_to_text(image_path): # 画像を読み込む img = Image.open(image_path) # 画像からテキストを抽出する text = pytesseract.image_to_string(img) return textこれを実現するために、以下のプロセスを実行します:
- PDFMinerで検出されたLTFigureオブジェクトのメタデータを使用して、画像の領域を切り取ります。ページのレイアウト内の座標を利用します。そして、PyPDF2ライブラリを使用して、新しいPDFとしてディレクトリに保存します。
- 次に、pdf2imageライブラリのconvert_from_file()関数を使用して、ディレクトリ内のすべてのPDFファイルを画像のリストに変換し、それらをPNG形式で保存します。
- 最後に、画像ファイルをスクリプトで読み込み、PILモジュールのImageパッケージを使用して、画像からテキストを抽出します。これにはtesseract OCRエンジンを使用するimage_to_string()関数を実装します。
このプロセスの結果、画像から抽出されたテキストが返されます。このテキストは、検査対象のページの画像から抽出されたテキスト情報を含む出力辞書内の3番目のリストに保存されます。
テーブルからテキストを抽出する関数を定義する
このセクションでは、PDFページのテーブルからより論理的に構造化されたテキストを抽出します。テキストの抽出はコーパスからのテキストの抽出よりもやや複雑なタスクです。なぜなら、テーブルで表示されるデータポイント間の情報の粒度と関係性を考慮する必要があるからです。
PDFからテーブルデータを抽出するために使用される複数のライブラリがありますが、最もよく知られているのはTabula-pyですが、その機能には制限があることが特定されています。
私たちの意見では、最も顕著な制限は、ライブラリがテーブルの異なる行をテーブルのテキスト内の改行特殊文字 \n を使用して識別する方法から来ています。これはほとんどの場合でうまく機能しますが、セル内のテキストが2行またはそれ以上に折り返される場合に正しくキャプチャできず、不要な空行が追加され、抽出されたセルの文脈が失われてしまいます。
以下の例では、tabula-pyを使用してテーブルからデータを抽出しようとしたときの結果が示されています:
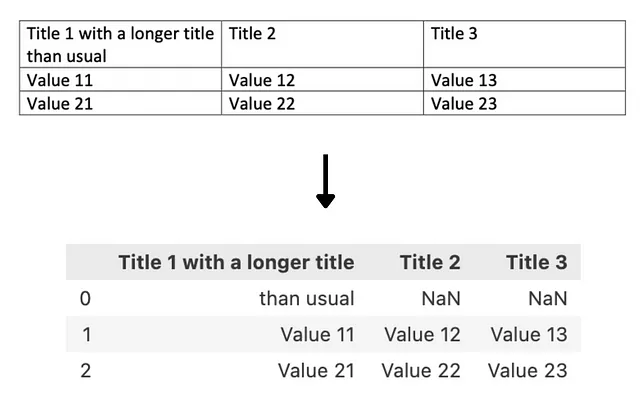
その後、抽出された情報は文字列ではなく、PandasのDataFrameに出力されます。ほとんどの場合、これは望ましい形式ですが、テキストを考慮に入れるtransformersの場合、これらの結果はモデルに送る前に変換する必要があります。
そのため、このタスクに取り組むために、さまざまな理由でpdfplumberライブラリを使用しました。まず、それは私たちの予備分析に使用したpdfminer.sixに基づいて構築されているため、似たようなオブジェクトを含んでいます。さらに、テーブルの検出方法は、テキストを含むセルとテーブル自体を構成するライン要素とその交差点に基づいています。したがって、テーブルのセルを特定した後、レンダリングする必要がある行数を気にせずにセル内のコンテンツだけを抽出することができます。そして、テーブルの内容を持っているとき、それをテーブルのような文字列にフォーマットし、適切なリストに保存します。
# PDFからテーブルを抽出する関数def extract_table(pdf_path, page_num, table_num): # PDFファイルを開く pdf = pdfplumber.open(pdf_path) # 対象ページを見つける table_page = pdf.pages[page_num] # 適切なテーブルを抽出する table = table_page.extract_tables()[table_num] return table# テーブルを適切な形式に変換する関数def table_converter(table): table_string = '' # 各行のテーブルを繰り返す for row_num in range(len(table)): row = table[row_num] # 改行記号を削除する cleaned_row = [item.replace('\n', ' ') if item is not None and '\n' in item else 'None' if item is None else item for item in row] # テーブルを文字列に変換する table_string+=('|'+'|'.join(cleaned_row)+'|'+'\n') # 最後の改行を削除する table_string = table_string[:-1] return table_stringそれを実現するために、extract_table()関数を使用してテーブルの内容をリストのリストに抽出し、table_converter()関数を使用してそれらのリストの内容をテーブルのような文字列に結合します。
extract_table()関数では:
- PDFファイルを開きます。
- PDFファイルの対象ページに移動します。
- pdfplumberが見つけたテーブルのリストから、選択したテーブルを選びます。
- テーブルの内容を抽出し、テーブルの各行を表すネストされたリストのリストで出力します。
table_converter()関数では:
- 各ネストされたリストを繰り返し、ラップされたテキストから不要な改行を清掃します。
- 行の各要素を|記号で区切って結合し、テーブルのセルの構造を作成します。
- 最後に、次の行に移動するために行末に改行を追加します。
これにより、テーブルの内容が失われることなく、テーブルのデータの細かさを保持したテキストの文字列が生成されます。
すべてをまとめる
これで、コードのすべてのコンポーネントが準備できたので、完全に機能するコードにすべてを組み合わせましょう。ここからコードをコピーするか、例と一緒にGithubリポジトリで見つけることができます。
# PDFのパスを見つけるpdf_path = 'OFFER 3.pdf'# PDFファイルオブジェクトを作成pdfFileObj = open(pdf_path, 'rb')# PDFリーダーオブジェクトを作成pdfReaded = PyPDF2.PdfReader(pdfFileObj)# 各イメージからテキストを抽出するための辞書を作成text_per_page = {}# PDFからページを抽出するfor pagenum, page in enumerate(extract_pages(pdf_path)): # ページからテキスト抽出に必要な変数を初期化 pageObj = pdfReaded.pages[pagenum] page_text = [] line_format = [] text_from_images = [] text_from_tables = [] page_content = [] # 調査するテーブルの数を初期化 table_num = 0 first_element= True table_extraction_flag= False # PDFファイルを開く pdf = pdfplumber.open(pdf_path) # 調査するページを見つける page_tables = pdf.pages[pagenum] # ページ上のテーブルの数を見つける tables = page_tables.find_tables() # すべての要素を見つける page_elements = [(element.y1, element) for element in page._objs] # ページに表示される順にすべての要素をソートする page_elements.sort(key=lambda a: a[0], reverse=True) # ページを構成する要素を見つける for i,component in enumerate(page_elements): # PDF内の要素の上側の位置を抽出 pos= component[0] # ページレイアウトの要素を抽出 element = component[1] # 要素がテキスト要素かどうかをチェック if isinstance(element, LTTextContainer): # テーブル内に表示されたテキストかどうかをチェック if table_extraction_flag == False: # テキスト要素ごとにテキストを抽出してフォーマットする関数を使用 (line_text, format_per_line) = text_extraction(element) # 各行のテキストをページテキストに追加 page_text.append(line_text) # 各行のテキストのフォーマットを追加 line_format.append(format_per_line) page_content.append(line_text) else: # テーブル内に表示されたテキストは無視 pass # 画像の要素をチェック if isinstance(element, LTFigure): # PDFから画像を切り取る crop_image(element, pageObj) # 切り取ったPDFを画像に変換する convert_to_images('cropped_image.pdf') # 画像からテキストを抽出する image_text = image_to_text('PDF_image.png') text_from_images.append(image_text) page_content.append(image_text) # テキストとフォーマットリストにプレースホルダーを追加 page_text.append('image') line_format.append('image') # テーブルの要素をチェック if isinstance(element, LTRect): # 最初の四角形要素の場合 if first_element == True and (table_num+1) <= len(tables): # テーブルの境界ボックスを見つける lower_side = page.bbox[3] - tables[table_num].bbox[3] upper_side = element.y1 # テーブルから情報を抽出する table = extract_table(pdf_path, pagenum, table_num) # テーブル情報を構造化された文字列形式に変換する table_string = table_converter(table) # テーブル文字列をリストに追加する text_from_tables.append(table_string) page_content.append(table_string) # コンテンツをもう一度取得しないようにフラグをTrueにする table_extraction_flag = True # 別の要素にするためのフラグ first_element = False # テキストとフォーマットリストにプレースホルダーを追加 page_text.append('table') line_format.append('table') # ページからすでにテーブルを抽出したかどうかをチェック if element.y0 >= lower_side and element.y1 <= upper_side: pass elif not isinstance(page_elements[i+1][1], LTRect): table_extraction
上記のスクリプトは以下のことを行います:
必要なライブラリをインポートします。
pyPDF2ライブラリを使用してPDFファイルを開きます。
PDFの各ページを抽出し、以下の手順を繰り返します。
ページにテーブルがあるかどうかを調べ、pdfplumnerを使用してそれらのリストを作成します。
ページにネストされたすべての要素を検索し、レイアウトに表示された順にソートします。
次に、各要素に対して:
テキストコンテナであるかどうかを調べ、テーブル要素に表示されない場合はtext_extraction()関数を使用してテキストとその書式を抽出します。それ以外の場合は、このテキストをパスします。
画像であるかどうかを調べ、crop_image()関数を使用してPDFから画像コンポーネントを切り抜き、convert_to_images()を使用して画像ファイルに変換し、image_to_text()関数を使用してテキストを抽出します。
四角形の要素であるかどうかを調べます。この場合、最初の四角形がページのテーブルの一部であるかどうかを調べ、次の手順に進みます:
- テーブルのバウンディングボックスを見つけ、テキスト抽出()関数でテキストを再度抽出しないようにします。
- テーブルの内容を抽出し、文字列に変換します。
- テーブルからテキストを抽出することを明確にするためのブールパラメータを追加します。
- このプロセスは、テーブルのバウンディングボックスに含まれる最後のLTRectまで続き、次の要素が四角形オブジェクトでない場合に終了します。(テーブルを構成する他のオブジェクトはすべてパスされます)
プロセスの出力は、イテレーションごとに5つのリストに保存されます。これらのリストは次のように名前が付けられます:
- page_text: PDF内のテキストコンテナから抽出されたテキストを含みます(テキストが他の要素から抽出された場合はプレースホルダーが配置されます)
- line_format: 上記で抽出されたテキストの書式を含みます(テキストが他の要素から抽出された場合はプレースホルダーが配置されます)
- text_from_images: ページから抽出された画像のテキストを含みます
- text_from_tables: テーブルの内容を含むテーブルのような文字列を含みます
- page_content: ページ上にレンダリングされたすべてのテキストを要素のリストで含みます
すべてのリストは、各回に調査されたページの番号を表すキーの下に保存されます。
その後、PDFファイルを閉じます。
その後、プロセス中に作成されたすべての追加ファイルを削除します。
最後に、page_contentリストの要素を結合してページの内容を表示できます。
結論
これは、多くのライブラリの最良の特性を使用し、さまざまなタイプのPDFやエレメントに対して強靭なプロセスを作成すると信じているアプローチです。ただし、PDFMinerを使用して重い作業のほとんどを行います。また、テキストの書式に関する情報は、テキストを単なるページごとのコンテンツではなく、異なる論理的なセクションに分割するための潜在的なタイトルの識別や、重要なテキストの特定に役立つ可能性があります。
ただし、このタスクを実行するためのより効率的な方法は常に存在し、このアプローチがより包括的であると信じていても、この問題に取り組む新しい方法や改善点についての議論を楽しみにしています。
📖 参考文献:
- https://www.techopedia.com/12-practical-large-language-model-llm-applications
- https://www.pdfa.org/wp-content/uploads/2018/06/1330_Johnson.pdf
- https://pdfpro.com/blog/guides/pdf-ocr-guide/#:~:text=OCR technology reads text from, a searchable and editable PDF.
- https://pdfminersix.readthedocs.io/en/latest/topic/converting_pdf_to_text.html#id1
- https://github.com/pdfminer/pdfminer.six
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
