「Pythonによる水質EDAと水質の適性分析」
Pythonでの水質EDAと適性分析
データ分析と可視化技術の理解
十分な新鮮な飲料水を提供できることは、基本的な要件です。気候変動の議論では、十分な淡水を確保することが最も大きな課題の一つです。水質は、すべての生物種に影響を与える大きな懸念事項です。地球の水の約3%しか淡水ではありません。そのうちの1.2%しか飲料水として使用できず、残りは氷河、氷床、永久凍土に閉じ込められているか、地中に深く埋まっています。水質に影響を与える要素をデータ駆動のアプローチで評価することで、水を飲めるようにするための理解が大幅に向上する可能性があります。
水の飲用水安全性に関連する最も基本的なレベルでは、水の安全性に関するデータ技術を使用して、この目標の特徴を確認することができます。現在のレビューの範囲外の他の質問も浮かび上がります:
すべての種類の淡水を消費することはできますか?
世界の淡水の何パーセントにアクセスできますか?
- 「ChatGPTコードインタプリタを使用して、人道支援データの非構造化Excelテーブルを分析する」
- 「OpenAIとMetaが著作権侵害で訴えられる」
- 「マイクロソフトのシニアデータサイエンティストの成功ストーリー」
海面上昇とともに地下水位は上昇しましたか?
この記事では、小規模な水質データセットと共に旅をします。データから、pandasとnumpyを使用したデータ分析技術を使って隠れた洞察を見つけ出そうとします。データの可視化には、matplotlibとseabornライブラリを使用します。データ品質のさらなる明確さを提供するために、さまざまな探索的データ分析(EDA)の技術が使用されます。
各データの可視化は、データの異なる特性を強調することを目指します。また、ユーザーに他の課題に適用するためのテンプレートを提供します。
データセット
この分析では、Water QualityデータセットをKaggle¹から取得しました。
水質
飲料水の飲用可能性
www.kaggle.com
処理にはPythonコードを使用したjupyterノートブックインスタンスが使用されました。
import sysprint(sys.version) # インストールされているPythonのバージョンを表示上記のスクリプトを実行すると、Pythonのバージョン3.7.10が使用されたという出力が表示されます。以下に続く結果を再現するためには、ユーザーは作業環境でPython 3を使用することを確認する必要があります。
データの理解
まず、私たちが取り扱っているデータを理解する必要があります。ファイル形式がcsvファイルであるため、pandasのread_csvを使用して標準的なデータセットのインポートステートメントが使用されます。
# レビュー用のデータセットをインポートする
df = pd.read_csv("../input/water-potability/water_potability.csv")
# 最初の5つの観測値を確認する
df.head()データをインポートした後、コードは変数dfにpandasメソッドのDataFrame出力結果を割り当てます。
処理するデータセットのいずれかをレビューする際には、レコードのサンプルを確認することで快適さを得ることができます。DataFrameには多数の関連メソッドがあり、pandas APIは使用する素晴らしいリソースです。API内ではheadメソッドが使用できます。デフォルトでは、Output 1.1はDataFrameの最初の5行を表示します。表示する行数を増やすには、括弧内に数値が必要です。DataFrameをサンプリングするためにi) sample (df.sample())を使用してインデックスからランダムな行を選択するか、ii) tail (df.tail())を使用してインデックスから最後のn行を選択することができます。
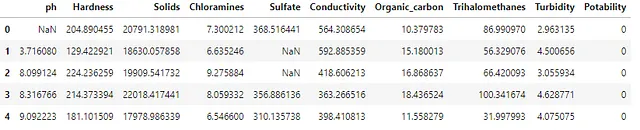
任意のメソッドを実行する際には、メソッド名の後に括弧を含めることで、Pythonのインタプリタが結果を生成できるようにします。
DataFrameのメモリを表示することは一般的なタスクであり、特にメモリ制約が関係している場合に行われます。例えば、インポートするデータセットがPythonセッションで利用可能なメモリよりも大きい可能性がある場合に該当します。pandasライブラリを使用することで、DataFrameがメモリ内で作成されるため、これらの処理ステップを実行する際に使用できるメモリを理解する必要があります。
# DataFrameに関する情報を表示する - メモリの詳細を含む
df.info(memory_usage="deep")上記のコードは、出力1.2を表示するための方法として使用できます。キーワードのmemory_usageを含めることで、Pythonインタープリターは下に表示されるメモリ使用量を理解するためにより深い検索を行うように強制されます。デフォルトのオプションでは、一般的な検索が行われますので、正確な評価が必要な場合は、上記のキーワードフレーズが適用されていることを確認してください。
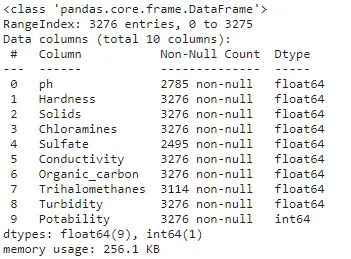
出力1.2に表示される結果から、カラム名やデータ型から始まり、変数のクラスやノンヌル値の数まで、さまざまな詳細が示されます。全体のテーブル内には3,276行が表示されていることがわかります。ただし、Sulfateというカラムでは、ノンヌル値は2,495個しか存在しません。したがって、他のカラムとの間にこれらの欠損値のパターンがあるかどうかを理解するために、欠損値の数を確認することができます。後で、パターン認識に役立つデータ可視化技術を見ていきます。
先ほどのインポート文に続いて、デフォルトのオプションが予想されるものでない場合、ユーザーはカラムのDtypeを調整することができます。上記の結果では、小数点数にはfloatのDtypeが適用され、整数はintと表示されています。また、これらの数値カラムの最大バイトメモリタイプも含まれており、潜在的な入力値の完全なカバレッジを提供しています。多くの場合、これらのDtypeが正しい値の範囲を保持しているかどうかを評価し、将来的により小さな範囲が予想される場合は、より小さなバイト値を割り当てることができます。このロジックを適用することで、DataFrameのメモリ効率が向上し、処理時のパフォーマンスが改善されます。
infoメソッドによって表示されるDataFrameの構造は、多くの他のメソッドによって確認することができる機能の1つです。このようなメタデータを使用すると、プログラマーは行数や列数などの基本的なコンポーネントを確認することができます。
# DataFrameの形状 - タプル(#行数, #列数)を表示する
print(df.shape)
# DataFrame内の行数を見つける
print(len(df))
# 形状タプルから情報を抽出する
print(f'行数: {df.shape[0]} \n列数: {df.shape[1]}')shapeのような属性をPythonで呼び出す場合、括弧は必要ありません。属性は、クラスとそのオブジェクトの両方からアクセスできるデータ結果です。先ほどはクラス内に含まれる関数であるメソッドを見てきました。Pythonのクラス文がどのように機能するかの詳細な説明は、さらなる洞察を得るために必要ですが、使用されるコードを続け、出力1.3でいくつかの値が表示されることを示します。
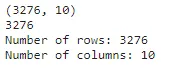
最初の行はタプルである形状の出力を示しており、カッコ内に2つの値が含まれています。上記のコードでは、このタプル内の相対位置にアクセスして、最初の位置の値と2番目の位置の値を表示することができます。Pythonは0インデックスの慣例を使用しているため、0を角括弧内に適用することで最初の値が返されます。タプルには最初の位置に行数、次に2番目の位置に列数が含まれていることがわかります。行数を見つける別の方法としては、DataFrameの長さを表示する関数lenを使用する方法があります。
サマリー統計
このセクションでは、DataFrameのカラムのサマリー詳細を確認します。数値カラムの高レベルデータ分析を実行するために、シンプルなdescribeメソッドが使用できます。DataFrameに数値カラムだけが含まれている場合、すべてのサマリープロパティが表示されます。文字列と数値のカラムが混在する場合は、関連する出力を表示するために他のキーワードパラメータを含める必要があります。
# 各変数の高レベルのサマリー詳細を確認する
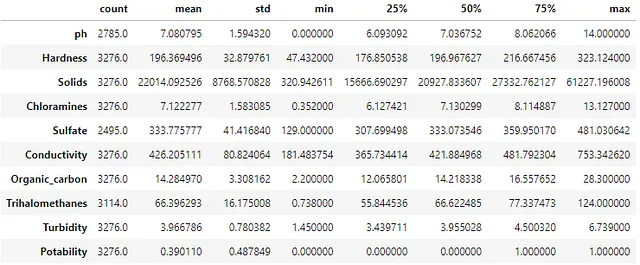
df.describe()出力1.4は、各列のデフォルトのサマリー値を示しています。countの値は、ノンヌル値の数と解釈できます。総数がDataFrameの行数よりも少ない場合、欠損値のある列が表示されます。各変数について、値の範囲が表示されています。表示されたデータに基づいてi) 平均値、ii) 分散、iii) 歪度、iv) 尖度といった4つのモーメントの方法を使用して理解することができます。
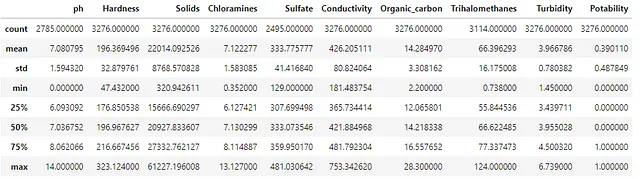
要約の詳細を確認する際に、特徴量の特性を理解するための外部の洞察力も重要です。経験的に、pH値は0から14の範囲にあるべきです。この範囲外の値がある場合、特徴量の値を見直して修正する必要があります。水質の評価に使用されるデータでは、平均値と中央値(50パーセンタイルで表示)が7に近いことが、水の中性の特性に適しています。
データフレームに多くの特徴量がある場合、前のコードブロックの出力は解釈が難しい場合があります。出力は水平に広がり、スクロールなしで表示することはできません。
# 要約の詳細を転置する - 多くの特徴量を確認しやすくするためdf.desribe().T出力を転置することは有用な方法です。上記のコードブロック内でTメソッドをチェーンすることで、以下の出力1.5が生成されます。これにより、ユーザーは行インデックスに表示される列名を見直し、要約メトリクスを列見出しとして表示することが容易になります。このdescribeメソッドの小さな調整は、多くの列を持つ場合に非常に効果的です。
describeメソッドのさらなる詳細を理解するために、jupyterノートブックのマジック関数である「?」を使用してドックストリングを解釈することができます。
# ドックストリングを表示するためのjupyterのマジック関数df.describe?このアプローチを使用することで、任意のメソッドのデフォルトパラメータの値(キーワードと位置指定)を確認するのに役立ちます。

Output 1.6は、ユーザーがメソッドの内部動作を確認するための情報を提供します。各パラメータのデフォルト値の範囲や定義など、メソッドの適用に役立ちます。プログラマの生産性を向上させるためのさまざまなjupyterのマジック関数が利用可能です。
欠損値
先ほどのメタデータと要約統計から、データフレーム内にいくつかの欠損値があることがわかりました。これが正しいかどうかを確認するために、以下のコードブロックを適用できます。
# 各列の欠損値を確認するdf.isnull().sum()このコードは、最初のisnullメソッドとsumメソッドをチェーンして、各列ごとの欠損値の数を作成します。isnullアセスメントは列内の非null値を確認します。sumメソッドはカウントを行います。出力1.7は、3つの列に欠損値があることを強調しています。

欠損値のある行の総数を持つことは素晴らしい出発点です。ただし、列内の欠損値の割合を見直すことがより良いでしょう。
# 各列ごとの欠損値の割合def isnull_prop(df): total_rows = df.shape[0] missing_val_dict = {} for col in df.columns: missing_val_dict[col] = [df[col].isnull().sum(), (df[col].isnull().sum() / total_rows)] return missing_val_dict# 欠損値メソッドを適用null_dict = isnull_prop(df)print(null_dict.items())isnull_propユーザー定義関数を作成することで、各列の値の辞書を作成することができます。この関数を使用することで、上記のカウント値を生成し、shape属性を使用して欠損値の割合を理解することができます。
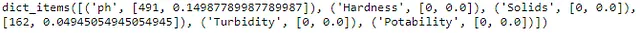
Output 1.8は視覚化が難しい出力を表示しています。最終メッセージを見逃さないようにするために、DataFrameを生成することができます。
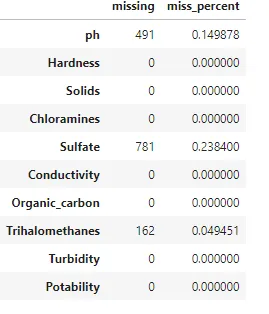
# 欠損値の情報を含むDataFrameを作成するdf_missing = pd.DataFrame.from_dict(null_dict, orient="index", columns=['missing', 'miss_percent'])df_missing辞書変数をpandas DataFrameメソッドに適用することで、各列の差異を理解しやすくすることができます。Output 1.9にはmiss_percent列が含まれています。これで、欠損値の割合が期待される範囲内にあるかどうかを評価するための閾値を適用することができます。値が高すぎる場合(たとえば、硫酸塩の値が20%を超える場合)、この列は将来の使用から除外するか、詳細に確認する必要があることを示すユーザー定義の制御が行われる可能性があります。
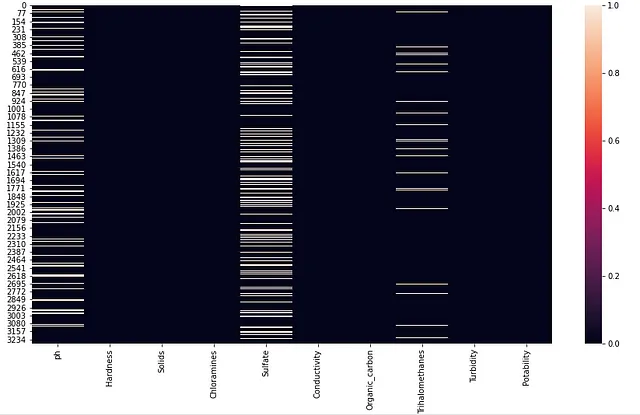
欠損値のパターンが存在するかどうかを確認するための別の方法は、seabornデータ可視化ライブラリのヒートマップメソッドを適用することです。
# 欠損値をヒートマップで表示し、パターンを理解するplt.figure(figsize=(15,8))sns.heatmap(df.isnull());上記のコードブロックを適用することで、Output 1.10が生成されます。この視覚化では、3つの変数に対して欠損値を持つ行の数がわかります。元のデータセットにデータを入力しているユーザーが一貫して欠損値を表示している場合があります。この洞察を持つことで、より効率的に欠損値の数を最小化する方法を見直すためのデータ駆動型の洞察を得ることができます。
pH変数の分布の理解
最後に、事前に外部知識を持っている変数のレビューを行うことができます。seabornライブラリを使用して、pH変数のヒストグラムを作成することができます。
# ヒストグラム、平均値、中央値を設定sns.displot(df["ph"], kde=False)plt.axvline(x=df.ph.mean(), linewidth=3, color='g', label="mean", alpha=0.5)plt.axvline(x=df.ph.median(), linewidth=3, color='y', label="median", alpha=0.5)# タイトル、凡例、ラベルを設定plt.xlabel("ph")plt.ylabel("Count")plt.title("Distribution of ph", size=14)plt.legend(["mean", "median"]);print(f'Mean pH value {df.ph.mean()} \n Median pH value {df.ph.median()} \n Min pH value {df.ph.min()} \n Max pH value {df.ph.max()}')前述のprint文と同様に、f文字列文を使用することで、平均値、中央値、最小値、最大値を追加して分布を確認しやすくすることができます。
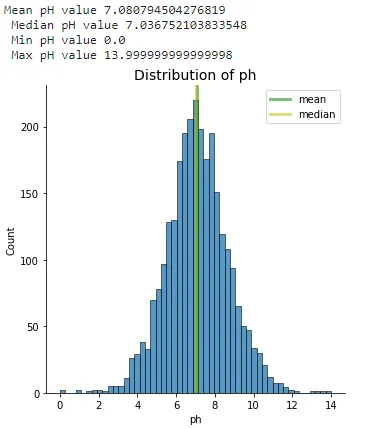
Output 1.11は、pH値の大部分が中央に近いことを示しています。正規分布に似た分布を持つため、この洞察を使用して外部ユーザーに詳細を提示する際に役立てることができます。
結論
この記事では、EDA評価の初期段階をレビューすることを目的としました。インポートされたデータのメタデータは、初期の洞察を表示するために最初にレビューされました。サマリー統計の詳細な分析により、欠損値に焦点を当てることができました。最後に、pH変数のヒストグラムを確認して、変数が外部の期待に沿っていることを確認しました。
次の記事では、水質を予測するためのモデルの開発を続け、ベースラインモデルを提供するために分類機械学習技術を使用します。
コメントを残していただき、読んでいただきありがとうございます!
お気軽にデータに関するあらゆることについてLinkedInで連絡していただけます。
SQL内で変数を宣言する
SQLコードの先頭で重要な変数を宣言することで、コードの再利用を自動化することができます。
towardsdatascience.com
高度なSQL操作
アイリッシュウェザーデータセットから追加のデータ洞察を抽出するためのより高度なSQL操作のレビュー。
towardsdatascience.com
SQLテーブルの開発
SQLテーブルを作成して開発することで、利用可能なメモリの最適な使用方法を理解することができます。
towardsdatascience.com
PythonでNLPを始める
自然言語処理の領域への旅を始める
towardsdatascience.com
[1] : Kaggleデータセット「水質」(https://www.kaggle.com/datasets/adityakadiwal/water-potability)は、https://creativecommons.org/publicdomain/zero/1.0/のライセンス契約に基づいています。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
